はじめに
Pythonには、デシジョンツリー(決定木)の可視化・モデル解釈のための dtreeviz というライブラリがあります。
この dtreeviz で表示されるデシジョンツリーは、もう美しいなんてもんじゃない。
こちらの記事 でも紹介させていただきましたが、「プロに頼んだの?」というくらいのビジュアルに、うっとりしてしまいます。
先日、「lightGBMでもdtreevizが描ける」と、以下のTweetで知りました。
欠損値、multiclassには今のところ非対応っぽい
— suk1yak1 (@suk1yak1) March 27, 2021
これはぜひ!!ということで、やってみたのですが、すぐにはうまく描くことができず、作者のGithub に”lightGBMに対応”とありますが、どう対応すればよいかわからず、他のサイトにも適用された例が見あたらないので、苦労しましたが、試行錯誤で何とか描くことができましたので、紹介させていただきます。
実行条件など
・Google colabで実行
・ボストン住宅価格のデータセットで実行
※手元データを読込んで実行する場合も記載していますので、簡単にできるはずです。
ボストン住宅価格のデータセットについて
データ数:506, 項目数:14のデータセットで、住宅価格を示す「MEDV」という項目と、住宅価格に関連するであろう項目が「CRIM:犯罪率」「RM:部屋数」「B:町の黒人割合」「RAD:高速のアクセス性」・・・等、13項目で構成されたデータとなっています。
これだけ項目があると、データ傾向を掴むだけでも、なかなか骨が折れるだろうと想像できますね。
ボストン住宅価格データの項目と内容
|項目|内容|
|:-----------|:------------------|
|CRIM|町ごとの一人当たり犯罪率|
|ZN|25,000平方フィート以上の住宅地の割合|
|INDUS|町ごとの非小売業の面積の割合|
|CHAS|チャールズ川のダミー変数(川に接している場合は1、そうでない場合は0)|
|NOX|窒素酸化物濃度(1,000万分の1)|
|RM|1住戸あたりの平均部屋数|
|AGE|1940年以前に建てられた持ち家の割合|
|DIS|ボストンの5つの雇用中心地までの距離の加重平均|
|RAD|高速道路(放射状)へのアクセス性を示す指標|
|TAX|10,000ドルあたりの固定資産税の税率|
|PTRATIO|町ごとの生徒数と教師数の比率|
|B|町ごとの黒人の割合|
|LSTAT|人口の下層階級の比率|
|MEDV|住宅価格の中央値(1000㌦単位)|
lightGBMのデシジョンツリーはシンプル
通常、デシジョンツリーの葉は、層毎にすべて分岐されます。
1層目で2つの葉に分岐し、2層目でそれぞれの葉から2つの葉に・・・というようなかたちです。
一方、lightGBMは、分岐させるべき葉を絞って分岐されます。
両者のデシジョンツリーを比較すると、剪定前と剪定後のような違いがあります。
説明だけを読んでも、よくわからないと思いますので、ボストンの住宅価格のデータセットで両者の違いを見てみましょう。
通常に描いた場合
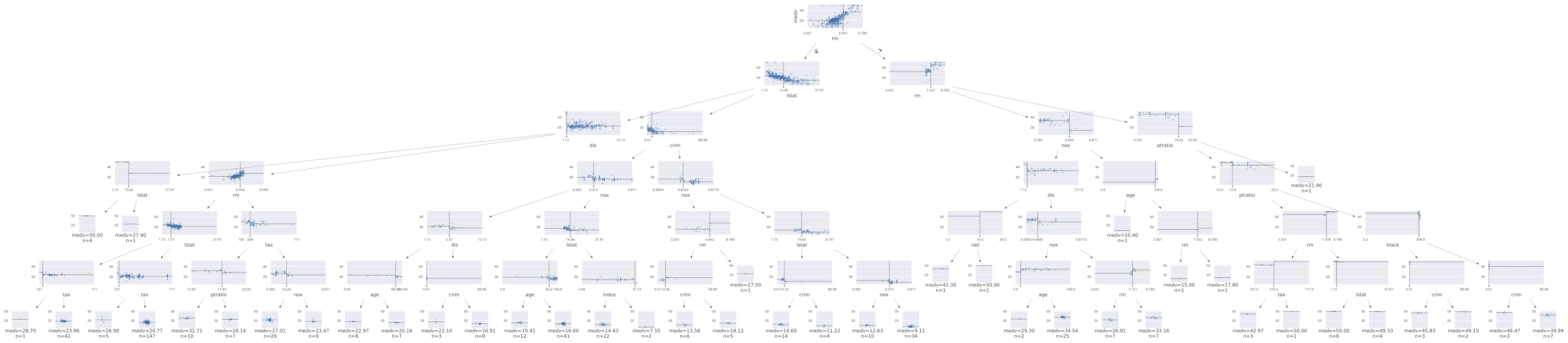
わかりやすくするために描いたはずなのに。。。という感じです。
これは6層(depth=6)です。きびしいですね。
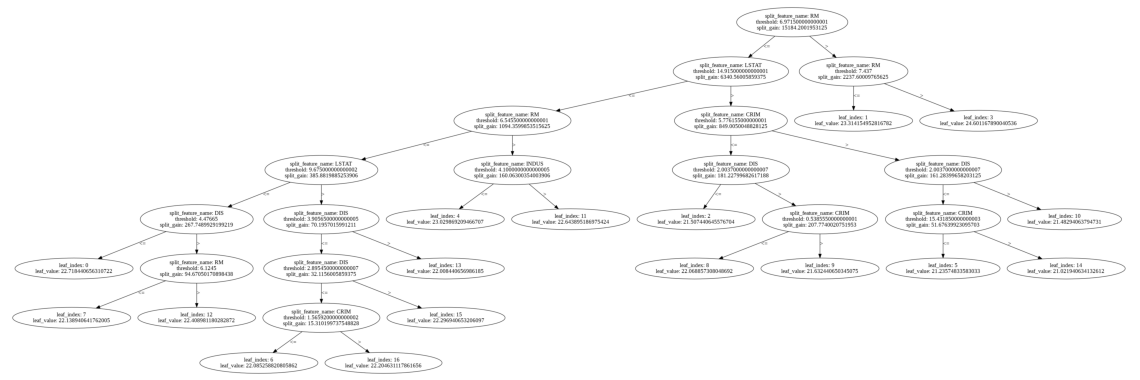
lightGBMで描いた場合
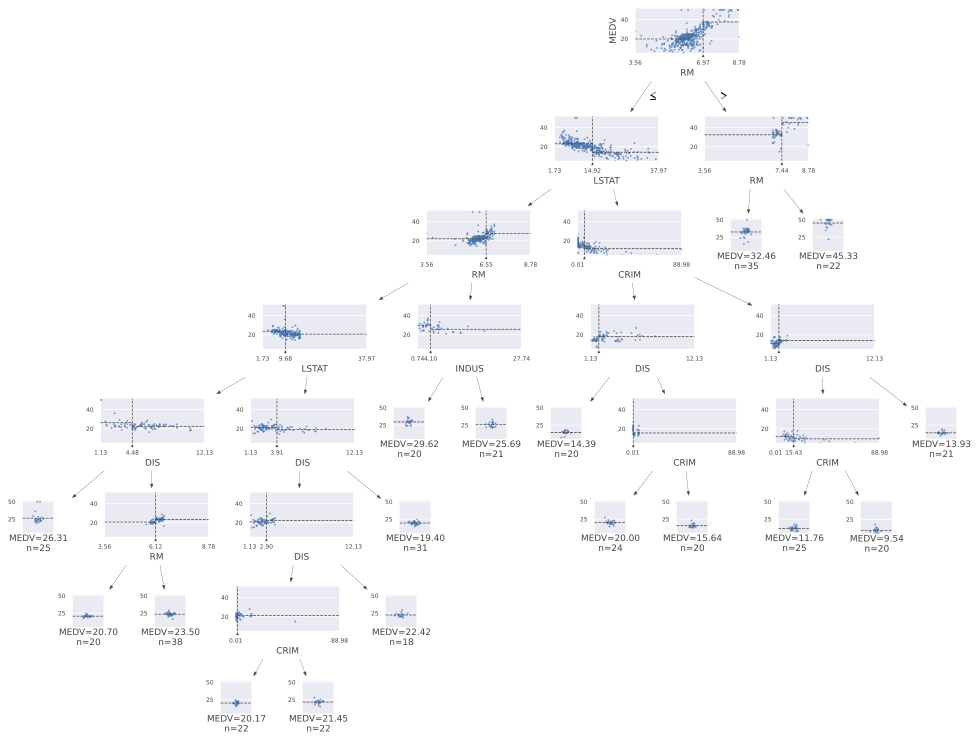
先のデシジョンツリーよりも1層多い7層ですが、分岐させるべき葉が絞られていますのでlightGBMのデシジョンツリーの方が圧倒的に見やすいです。
先のデシジョンツリーの葉の数は127枚、lightGBMのデシジョンツリーの葉の数は33枚ですから、この例ではおよそ1/4に絞られていることになります。見やすいということは可読性も高いということになりますので、これはとてもありがたいですね。
ライブラリのインストールとインポート
import pandas as pd # 基本ライブラリ
import numpy as np # 基本ライブラリ
import matplotlib.pyplot as plt # グラフ描画
import seaborn as sns; sns.set() # グラフ描画
import warnings # 警告を無視
warnings.filterwarnings('ignore')
import lightgbm as lgb #LightGBM
from sklearn.model_selection import train_test_split # データセット分割
from sklearn.metrics import accuracy_score # モデル評価(正答率)
from sklearn.metrics import log_loss # モデル評価(logloss)
from sklearn.metrics import roc_auc_score # モデル評価(auc)
from sklearn.metrics import mean_squared_error # モデル評価(平均二乗誤差)
from sklearn.metrics import r2_score # モデル評価(決定係数)
from sklearn.preprocessing import LabelEncoder
pip install dtreeviz
pip install graphviz
from sklearn import tree
import graphviz
ファイル読込み
# ボストンデータセット読込み → データフレーム格納
import sklearn.datasets as skd
boston = skd.load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target #目的変数(target)データをデータフレームにカラム名「MEDV」で追加
※以下は任意です。使用の際はコードの # は外してくださいね
# ローカルファイル読込み
# from google.colab import files
# uploaded = files.upload()
# if len(uploaded.keys()) != 1:
# print("アップロードは1ファイルにのみ限ります")
# else:
# target = list(uploaded.keys())[0]
# df = pd.read_csv(target)
# 欠損値のある行を削除(※ how ='any' は欠損がひとつでもあれば、その行を削除)
# df = df.dropna(how='any')
# 数値の列は残し、文字列だけを削除
# df = df.select_dtypes(exclude='object')
FEATURES = df.columns[:-1]
TARGET = df.columns[-1]
df_X = df.loc[:, FEATURES]
df_y = df.loc[:, TARGET]
df_X.info()
モデル構築
import lightgbm as lgb
df_X_train, df_X_test, df_y_train, df_y_test = train_test_split(df_X, df_y, test_size=0.2, random_state=4)
lgb_train = lgb.Dataset(df_X_train, df_y_train)
lgb_eval = lgb.Dataset(df_X_test, df_y_test)
# LightGBM parameters
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'regression', # 目的 : 回帰
'metric': {'rmse'}, # 評価指標 : rsme(平均二乗誤差の平方根)
# 'learning_rate': 0.1,
# 'num_leaves': 23,
# 'min_data_in_leaf': 1,
# 'num_iteration': 1000, #1000回学習
# 'verbose': 0
}
# 学習データから回帰モデルを作る
lgbm = lgb.train(params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=200,
early_stopping_rounds=20,
verbose_eval=50)
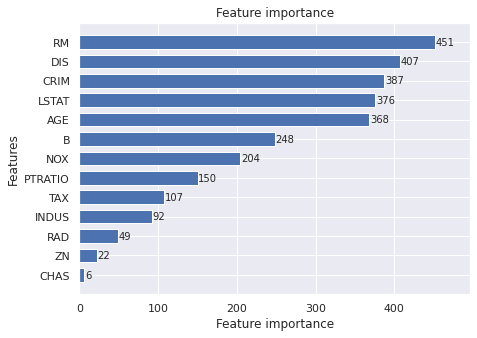
特徴量重要度
# feature importance
lgb.plot_importance(lgbm, height = 0.7, figsize = (7,5))
plt.show()
from dtreeviz.trees import *
viz = dtreeviz(lgbm,
x_data = df_X_train,
y_data = df_y_train,
target_name = TARGET,
feature_names = df_X_train.columns.tolist(),
tree_index = 0)
viz
viz.save('./lgb_tree.svg')
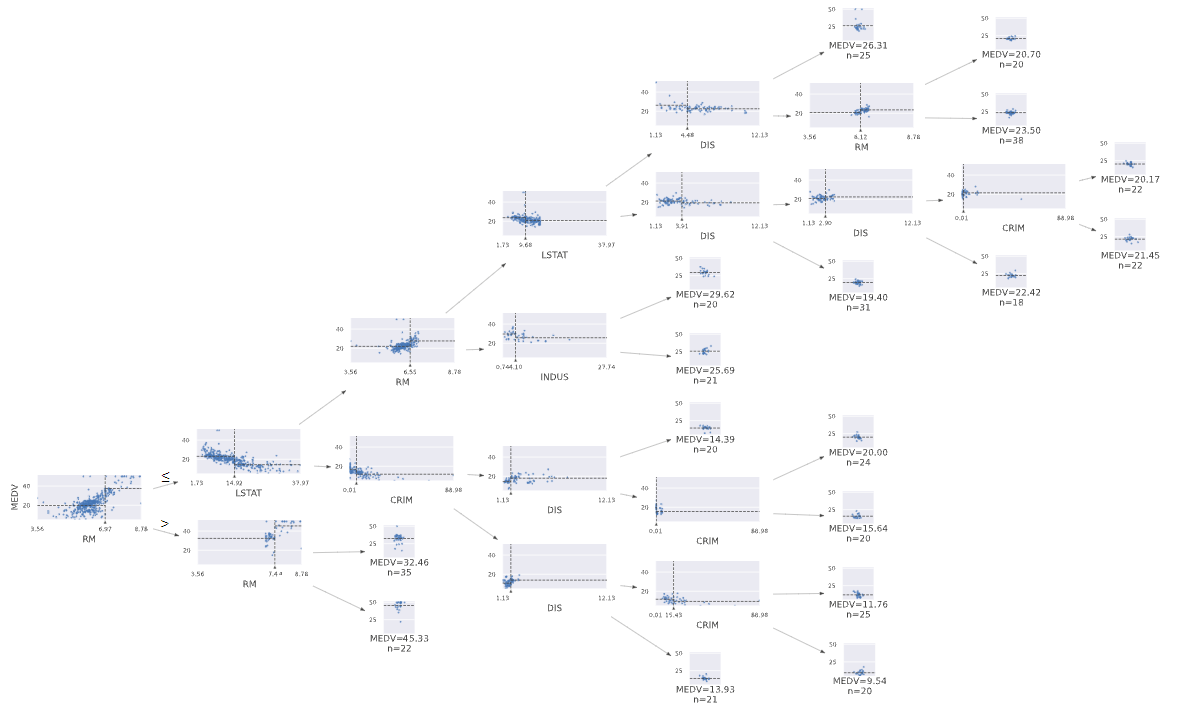
from dtreeviz.trees import *
viz = dtreeviz(lgbm,
x_data = df_X_train,
y_data = df_y_train,
target_name = TARGET,
feature_names = df_X_train.columns.tolist(),
orientation='LR',
tree_index = 0)
viz
# 決定木の分岐の可視化
ax = lgb.plot_tree(lgbm, tree_index=0, figsize=(20, 20), show_info=['split_gain'])
plt.show()
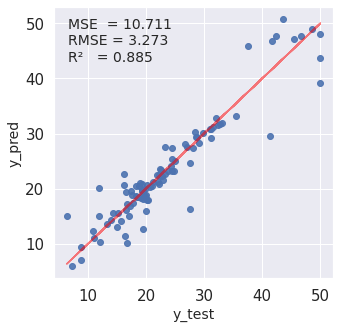
モデルの評価
# テストデータで予測精度を確認
test_pred = lgbm.predict(df_X_test)
pred_df = pd.concat([df_y_test.reset_index(drop=True), pd.Series(test_pred)], axis = 1)
pred_df.columns = ['y_test', 'y_pred']
# 予測値グラフ化
def Prediction_accuracy(pred_df):
MSE = mean_squared_error(pred_df['y_test'], pred_df['y_pred'])
RMSE = np.sqrt(mean_squared_error(pred_df['y_test'], pred_df['y_pred']))
r2 = r2_score(pred_df['y_test'], pred_df['y_pred'])
plt.figure(figsize = (5,5))
ax = plt.subplot(111)
ax.scatter('y_test', 'y_pred', data = pred_df,alpha=0.9)
ax.set_xlabel('y_test', fontsize = 14)
ax.set_ylabel('y_pred', fontsize = 14)
plt.tick_params(labelsize = 15)
ax.plot('y_test','y_test',data=pred_df,color='red',alpha =0.5)
plt.text(0.05, 0.92, 'MSE = {}'.format(str(round(MSE,3))),transform = ax.transAxes, fontsize = 14)
plt.text(0.05, 0.86, 'RMSE = {}'.format(str(round(RMSE,3))),transform = ax.transAxes, fontsize = 14)
plt.text(0.05, 0.80, 'R² = {}'.format(str(round(r2,3))),transform = ax.transAxes, fontsize = 14)
Prediction_accuracy(pred_df)
2値分類のlightGBMでも描けます
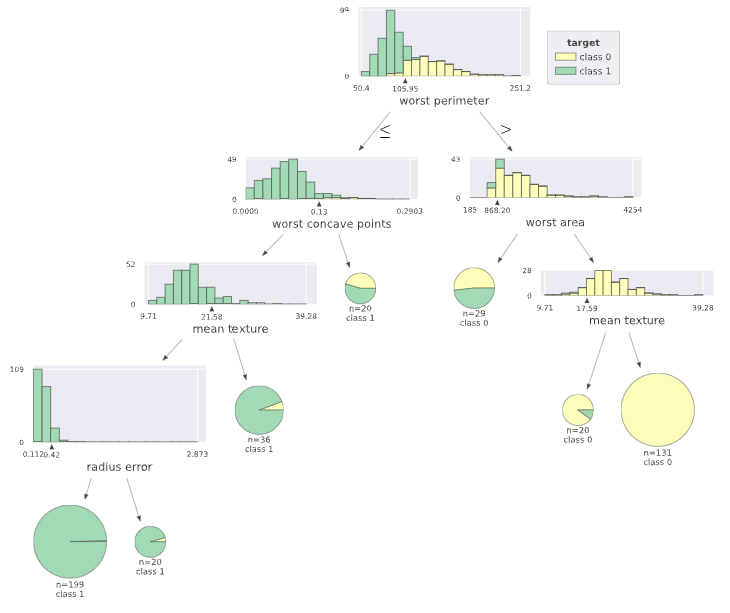
※lightGBMのパラメータは分類と回帰で異なりますが、dtreevizは同じコード実行で描けました。
最後に
dtreeviz いいなぁ。
描かれるのを待つとき、こんなにドキドキするのって他にないと思います。
作者には本当に感謝です。
参考サイト