2021/09/21:なぜかdtreevizが描けない時は”ココ”を確認して を追加
はじめに
Pythonには、デシジョンツリー(決定木)の可視化・モデル解釈のためのdtreevizというライブラリがあります。
このライブラリで表示されるデシジョンツリーは、もう美しいなんてもんじゃない。
「プロに頼んだの?」というくらいのビジュアルに、うっとりしたりしてしまいます。
ビジュアル先行ではあるが、このデシジョンツリーは、かなり使えるヤツでもある。
手元データを、Google colabだけで、コードコピペで描く!ことができるよう、適用の備忘も含めてまとめるものです。
デシジョンツリー(決定木)とは何だ?
「デシジョンツリー(決定木)」そのものの解説は、詳しい先にお預けし、ここでは私が持つ「デシジョンツリー(決定木)」に対する認識をお伝えできればと思う。
まず、以下はデータ分析コンペで有名なKaggleが提供する『Titanic生存者予測』をするためのデータセットで作成した「デシジョンツリー(決定木)」です。
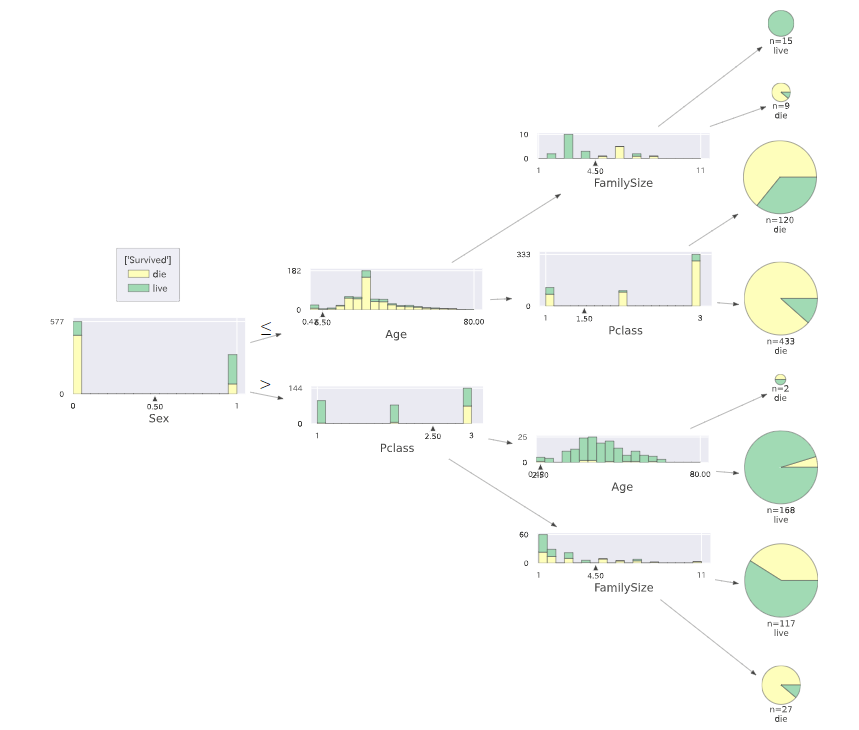
この美しさなら、見た目だけで飛びついてもよいと思いますが、「デシジョンツリー(決定木)」は、データ分析結果の可読性がとてもよいという利点があります。
この『Titanic生存者予測』のデータは、”性別・年齢・客室クラス・・・等”の「説明変数」と、”生存されたか否か?”という「目的変数」で構成されたデータなので、データ分析は回帰分析でも実行できます。
分析の結果は、例えば、
「生存されたか否かは、性別や年齢が影響してそうだ。こんな関係式で表すことができる・・・」といった感じでしょうか。
では「デシジョンツリー(決定木)」ならどうなるでしょう?
「生存者の多くは女性である。残念ながら亡くなった女性の方はある客室クラスに集中しており、お一人か数名で乗船された方が多い傾向がある。
一方、男性は多くの方が亡くなっておられ、これらは若者層に多い傾向がある。」
といった感じだ。
名に「デシジョン」とつくだけあり、これは意思決定の助けになりそうだと直感できる。
また、この図をチマチマと作成しなければならないとなると閉口してしまうが、なんとこの結果は機械的な分類器にかけて表示してくれるし、この結果から気づきを得ることも多い。
高い精度は期待できないといわれるが、まず全体を把握したい、全体の傾向が知りたいというケースも多く、これは本当に重宝する。
テーマや分析条件
- テーマ:『Titanic生存者予測』のデータで「デシジョンツリー(決定木)」を描こう
※Kaggleでアップされている『Titanic生存者予測』の元データは、「欠損値処理」や「性別(Male/Female)」データの0/1変換などの前処置が必要ですが、前処理を行ったデータを上げておられる方がおられますので、こちらを利用させていただくことにします。
- Google colabで実行
- ライブラリのインストール・インポート ⇒ データ読込み ⇒ データ確認 ⇒ 変数設定 ⇒ ロジスティック回帰分析 ⇒ 決定木分析 の流れで進める
決定木を描こう!
ライブラリのインストール及びインポート
pip install japanize-matplotlib
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font="IPAexGothic")
from scipy.stats import norm
import sklearn
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
pip install statsmodels
データの読み込み
df_past = pd.read_csv('titanic_train_mod.csv')
df_future = pd.read_csv('titanic_test_mod.csv')
#データ確認(先頭5行)
df_past.head()
#相関係数行列(ヒートマップ)説明変数間の相関係数が高すぎるものは注意
plt.figure(figsize=(9,7))
sns.heatmap(df_past.corr(), annot=True, vmax=1, vmin=-1, center=0)
plt.show()
変数設定
説明変数Xと目的変数Yを設定します。
#カラム=変数名を確認
df_past.columns
Index(['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Embarked', 'Survived'],
dtype='object')
#X_nameに説明変数を、y_nameに目的変数を設定
X_name = ['Pclass','Sex', 'Age', 'SibSp', 'Fare']
y_name = ['Survived']
X = df_past[X_name]
y = df_past['Survived']
注意
- 'PassengerId',はただの番号、'Name','Ticket'は文字情報なので説明変数として選択しなかった。
- 'Parch','Embarked'は、この後のロジスティック回帰でP値が大きかったので選択しなかった。'Fare'のP値も大きかったがこれはあえて残した。
- 記事ではこうしていますが、説明変数は任意に変更してください。
ロジスティック回帰分析(0/1データの場合のみ)
モデル指示:線形回帰はsm.OLS()、ロジット回帰はsm.Logit()に
※有意ではない説明変数は取り除いて、再度ロジット回帰分析を行う
import statsmodels.api as sm
from sklearn.linear_model import LogisticRegression #ロジット回帰の場合、このライブラリが必要
model = sm.Logit(y,sm.add_constant(X))
result = model.fit()
result.summary()
※有意ではない説明変数は取り除いて、再度ロジット回帰分析
result.predict(sm.add_constant(df_future[X_name]))
※結果は、確率として表現される。
決定木
決定木ライブラリのインストール・インポート
pip install graphviz
pip install dtreeviz
from sklearn import tree
from dtreeviz.trees import *
import graphviz
決定木の段数設定
※決定木の段数(max_depth)を任意に指定する
dtree = tree.DecisionTreeClassifier(max_depth=2)
dtree.fit(X,y)
決定木描画(縦向き)
※class_namesは任意に設定,#orientation ⇒ orientation とすれば表示は横に
# 決定木
viz = dtreeviz(dtree,X,y,
target_name = y_name,
feature_names = X_name,
#orientation='LR',
class_names = ["bad","soso","good"])
viz
※ 日本語化は、引数で fontname='IPAexGothic' 等とすればよいとありましたが、私はうまくいきませんでした。
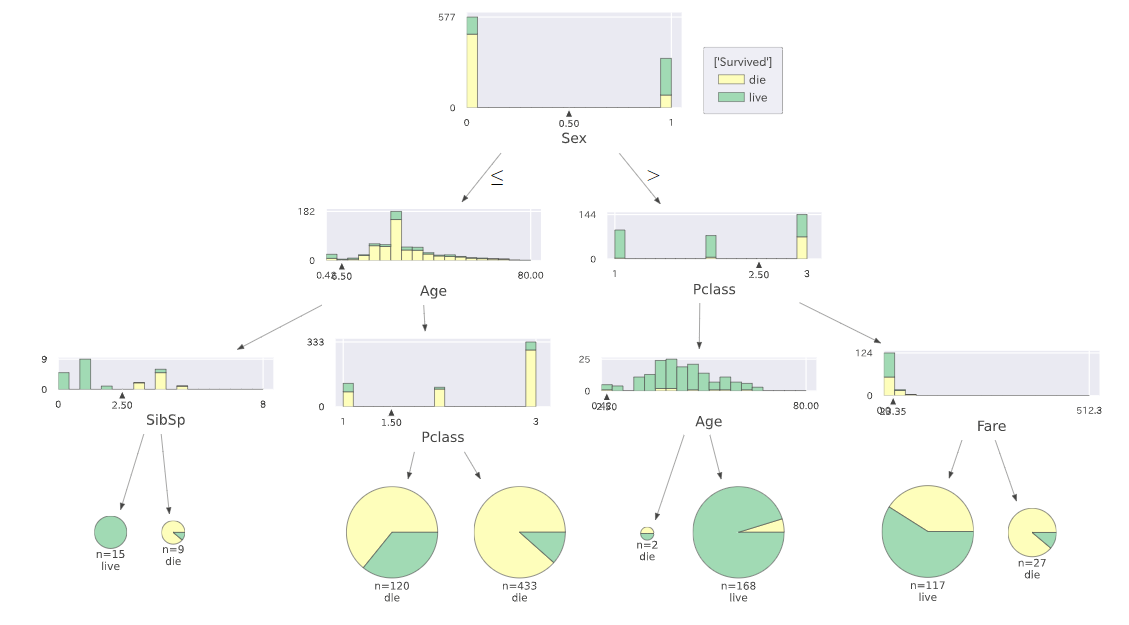
『タイタニックでの生死は、性別で大きく傾向が異なり、男性は多くが亡くなり、女性は多くが生存。
男性は、(幼児と高齢者除く)若者層の多くが客室クラスによらず亡くなっている。
女性は、多くは生存されているが、ある客室クラスに亡くなった方が集中している。』といったことが簡単に読み取れる。
最後に
美しいだけでなく、可読性も高い。
う~ん、dtreevizは本当にすばらしい。
スッキリ解釈したい、スッキリしにくいものをうまく共有したい といった場面で絶対に活躍するはずと思います。
※以下に決定木の学習と予測のコードものせておきます。
学習データとテストデータの設定
# データセットを学習データ(8割)とテストデータ(2割)に分割(random_stateは0)
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.2, random_state=0)
# 分割の確認
print('分割の確認:',X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 学習実行
# インスタンスの作成
model = DecisionTreeClassifier(max_depth=2)
# モデルの作成
model.fit(X_train, y_train)
# 学習データからの予測値
pred_train = model.predict(X_train)
# テストデータからの予測値
pred_test = model.predict(X_test)
なぜかdtreevizが描けないときは”ココ”を確認して
- データに欠損値があると描画してくれませんでした。描けない場合は欠損値の有無を確認し、欠損値があれば処理を行ってから実行したほうがいいです。
- 同じカラムのデータのなかに異なるDTypeのデータ、例えばintとfloat等が混在していると受け付けてくれませんでした。(※私は、Titanicデータ”Age”の欠損値を平均値に置き換えました。置換した値はfloatでしたが他の値はintでした。これにより描画できませんでした。)
参考サイト