
はじめに
自然言語処理におけるテキスト分類は、機械学習や深層学習の進歩に伴い、単語の意味的な関係や文脈をより正確に理解できるようになってきているだけではなく、ほぼテキストデータを与えて実行するだけ等、実行の面も進歩しています。
- 溜まる一方のテキストデータをなんとか整理・分類したい。
- 整理・分類まではいいが、あとで必要になったときに確実に引っかかる(検索)ようにしたい。
一過性のテキストデータはさておき、何とかしたいと思うものの、なかなかうまくいかないのがテキストデータとのお付き合いと思います。
ということで、前回記事 ではBERTopicによるテキスト分類を探ってみました。
今回は、Sentence Transformersによるテキストの意味検索はどの程度?をテーマにしたいと思います。
用語の説明
Sentence Transformers
Sentence Transformers は、自然言語処理におけるテキスト表現学習のためのフレームワークです。
異なる言語タスクに対して、文書分類、文書類似度比較、質問応答、自然言語推論、自動要約などのタスクに応用されています。
例えば、複数のテキストがあった場合、Sentence Transformersを使用するとこれらのテキストをベクトル化できます。そして、これらのベクトルを比較することで、意味が近いテキストを見つけることができます。
Sentence Transformersの主な特徴や利点は以下の通りです。
- 大量のテキストデータを使用してトレーニングされた事前トレーニング済みモデルを使用できるので、自分自身でトレーニングする必要がありません。
- 事前トレーニング済みモデルは、大規模なテキストコーパスを使用してトレーニングされているため、異なる言語、文化、ジャンルのテキストデータに対しても適応でき、高いパフォーマンスを発揮することができます。
- Sentence Transformersは、事前学習された言語モデルを使用して、自然言語テキストをベクトル表現に変換します。これにより、テキストの意味をよりよく表現することができます。
- 形態素解析の処理は、Sentence Transformers により実行されますので、ユーザーが明示的に行う必要はありません。
実行したこと
Sentence Transformersの実行内容
まず、ライブラリのインストールし、データを読み込みます。
Initial settingは、何のデータを読み込むかのセッティングです。任意のtxtやcsvも読めるようにしています。今回は「再エネ」に関するtweetデータを読み込んでいます。

以下は読み込んだデータの表示です。
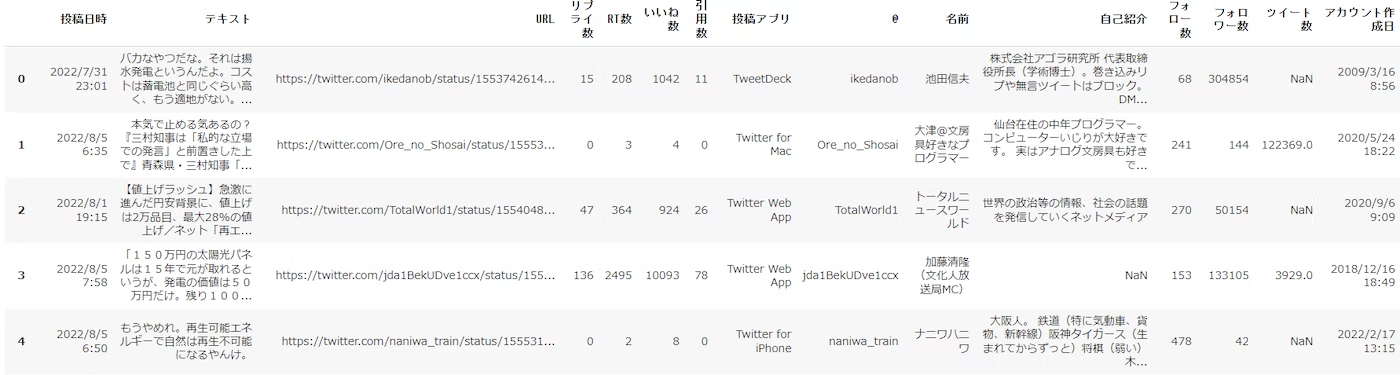
次に、テキスト分析したいデータカラム名を指定しています。

SentenceTransformerモデルを読込み、テキストをfitさせます。
fitにすこし時間はかかりますが、これで処理はおしまいです。

意味検索を行うための準備はここまでです。
Keywords: に入力したキーワードそれぞれに類似するテキストを検索し、Number_of_texts_shown: で指定した数のテキストをCos類似度と共に表示させました。

Keyword: いやだ
✓ @5JqE76BBTGx70xG @LY1FOLZTB2cVCXW これ今言い始めた訳じゃないですよ。半年前か、もっと前です。再エネ議連が調子に乗っていただけの話し。 (Cos類似度: 0.501)
✓ @7Znv478Zu8TnSWj 遅いんだよね!七波収束後だと、もう検討に入ってなければ!問題を先送りにすんなよ、モラトリアム首相。 (Cos類似度: 0.486)
✓ 原発再稼働へ 再エネはやっぱり主役にはなれない https://t.co/WnG30Vkwjy @WEDGE_ONLINEより (Cos類似度: 0.479)
✓ 表題で想像する以上の良記事。原発再稼働へ 再エネはやっぱり主役にはなれない https://t.co/Y06LORNMAc @WEDGE_ONLINEより (Cos類似度: 0.477)
✓ 原発再稼働へ 再エネはやっぱり主役にはなれない https://t.co/VaASumKVCD @WEDGE_ONLINEより (Cos類似度: 0.463)
Keyword: 環境
✓ 再エネは自然破壊。https://t.co/z30In2XTr0 (Cos類似度: 0.572)
✓ 【会員団体】大地を守る会は、持続可能な社会を創造する社会的企業として、「自然環境と調和した、生命を大切にする社会」の実現をめざします。消費者の視点からエネルギーを根本的に見直し、再エネへの転換に取り組んでいます。https://t.co/Y1Lbqpw480 (Cos類似度: 0.562)
✓ 再エネは、地球温暖化防止!地球環境のためと言いながら、皮肉なことに地球環境を壊し世界中で問題になり始めました。太陽光パネル義務化の罪😡💢https://t.co/2fgJw9h33I (Cos類似度: 0.523)
✓ 自然破壊しまくり中国パネルだらけで将来産廃の山になり死んだ土地となる?土壌は崩壊され水も汚される。マジでこんな未来描くのか?何が再エネだ😡東北山間部での再エネ開発、東京ドーム1200個分 https://t.co/7TW4gglz7O @Sankei_newsから (Cos類似度: 0.517)
✓ 自治体の脱炭素経営。日本再生可能エネルギー総合研究所代表、日本再生エネリンク代表取締役 北村和也氏が指摘する重要な視点。自治体に求められる“地域の脱炭素経営” ノルマではない前向きなカーボンニュートラルとは サステナブル・ブランズ ジャパン 2022.7.28https://t.co/Mlw91gjeOJ (Cos類似度: 0.511)
Keyword: 将来
✓ これは注視しなければならない🌲政府の再エネ導入目標に多少なりとも響くだろう🌴 (Cos類似度: 0.574)
✓ 自然破壊しまくり中国パネルだらけで将来産廃の山になり死んだ土地となる?土壌は崩壊され水も汚される。マジでこんな未来描くのか?何が再エネだ😡東北山間部での再エネ開発、東京ドーム1200個分 https://t.co/7TW4gglz7O @Sankei_newsから (Cos類似度: 0.564)
✓ これが不可逆な状態になる再エネですよ.SDGs(笑) (Cos類似度: 0.556)
✓ 【会員団体】調布未来(あす)のエネルギー協議会は、調布のまちに適した再エネを活用し、緑豊かで持続可能なまちにすること、未来に責任と希望が持てるまちにすることをめざし、公共施設での太陽光発電や普及啓発、環境教育活動に取り組んでいます。https://t.co/wJz27PLSVv (Cos類似度: 0.545)
✓ 厳選企業による一斉スカウト開始!参加者絶賛募集中! (Cos類似度: 0.522)
上記の通り、Keywordそのものへの合致ではなく、KeyWordの意味に近いテキストが抽出されています。
AND検索も行ってみました。
キーワードの 'いやだ','環境','将来' すべてを含んだ意味に近いテキストを抽出することになります。

Keyword: ('いやだ', '環境', '将来') のAnd検索
✓ 環境危機を警告する人達が見過ごしていること:『地球温暖化で人類は絶滅しない』 https://t.co/ymBfKDlgcu つうか日本は緩和策と適応策とどっちに金を出すか、再エネや炭素税なのか、堤防やダムなのか、という問題がある (Cos類似度: 0.693)
✓ 再エネは、地球温暖化防止!地球環境のためと言いながら、皮肉なことに地球環境を壊し世界中で問題になり始めました。太陽光パネル義務化の罪😡💢https://t.co/2fgJw9h33I (Cos類似度: 0.647)
✓ 自然破壊しまくり中国パネルだらけで将来産廃の山になり死んだ土地となる?土壌は崩壊され水も汚される。マジでこんな未来描くのか?何が再エネだ😡東北山間部での再エネ開発、東京ドーム1200個分 https://t.co/7TW4gglz7O @Sankei_newsから (Cos類似度: 0.645)
✓ 【会員団体】大地を守る会は、持続可能な社会を創造する社会的企業として、「自然環境と調和した、生命を大切にする社会」の実現をめざします。消費者の視点からエネルギーを根本的に見直し、再エネへの転換に取り組んでいます。https://t.co/Y1Lbqpw480 (Cos類似度: 0.641)
✓ 自治体の脱炭素経営。日本再生可能エネルギー総合研究所代表、日本再生エネリンク代表取締役 北村和也氏が指摘する重要な視点。自治体に求められる“地域の脱炭素経営” ノルマではない前向きなカーボンニュートラルとは サステナブル・ブランズ ジャパン 2022.7.28https://t.co/Mlw91gjeOJ (Cos類似度: 0.640)
なかなかやるな という感じです。
最後に、UIで AND/OR が選択できるようにしました。

所見
私が実行したのは、読み込んだデータをリスト形式にして SentenceTransformers 渡した・・・というだけです。あとは ほぼ公式のサンプルコードです。
検索だけを目的としましたので、事前のテキスト処理等もなく、あっさりと実行できました。
「はじめに」で述べましたが、
- 整理・分類まではいいが、あとで必要になったときに確実に引っかかる(検索)ようにしたい。
という場合に、これは使えるなと感じました。
例えば、ある分類されていない調査結果が大量にある場合、調査結果をChatGPTなどの使って文字数を決めて要約し、要約テキストを 手掛かりとなりそうなキーワードで意味検索する・・・。
キーワードが一致しないと引っかからないという検索は、近い将来オワコンの運命かもしれません。
実行コード
ライブラリのインストール
%%capture
!pip install -U sentence-transformers
データ読込み
まず、データの読込みです。
データの読込みにおいては、GoogleColabのフォーム機能を利用し、データセットを選択できるようにしています。
選択肢は2つ。tweetサンプルデータ(tweet_data_sampleを選択)と、任意のcsvファイル(Uploadを選択)です。
※tweet_data_sampleは、Githubにアップしたこの記事の適用データです。
#@title Initial Settings { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'tweet_data_sample' #@param ['tweet_data_sample','蜘蛛の糸','Upload_csv','Upload_txt']
以下を実行すると、datasetの選択に沿ったデータが読み込まれ、読み込んだデータをデータフレームに反映し、表示します。
#@title データ読込み
#@markdown **<font color= "Crimson">ガイド</font>:Upload 選択 ⇒ [ファイル選択]ボタンをクリックしてください。サンプルデータの場合は自動で読み込みます。**
import pandas as pd
import numpy as np
pd.set_option('display.unicode.east_asian_width', True)
from google.colab import files
import codecs
import warnings
warnings.simplefilter('ignore')
# データの読み込み
if dataset =='Upload_csv':
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target,encoding='utf-8')
elif dataset == 'tweet_data_sample':
file_url ='https://raw.githubusercontent.com/hima2b4/Natural-language-processing/main/TwExport_20220806_152219.csv'
df = pd.read_csv(file_url,encoding='utf-8')
elif dataset =='Upload_txt':
files = files.upload()
filename = list(files.keys())[0]
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
elif dataset == "蜘蛛の糸":
#蜘蛛の糸のテキストデータ(zipファイル)をダウンロード
!curl -O "https://www.aozora.gr.jp/cards/000879/files/92_ruby_164.zip"
#zipファイルを解凍
!unzip 92_ruby_164.zip
#文章切り出し(=注釈削除 [冒頭削除:tail -n +**][末尾削除:head -n -**] 任意設定要)
!tail -n +18 kumono_ito.txt | head -n -15 > kumono_ito_data.txt
#テキストファイル読み込み
text_file = open('/content/kumono_ito_data.txt',encoding = 'shift_jis')
def main():
# Shift_JIS ファイルのパス
shiftjis_path = 'kumono_ito_data.txt'
# UTF-8 ファイルのパス
filename = 'kumono_ito_utf.txt'
# 文字コードを utf-8 に変換して保存
fin = codecs.open(shiftjis_path, "r", "shift_jis")
fout_utf = codecs.open(filename, "w", "utf-8")
for row in fin:
fout_utf.write(row)
fin.close()
fout_utf.close()
if __name__ == '__main__':
main()
filename = 'kumono_ito_utf.txt'
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
#pd.set_option('display.max_colwidth', None)
#display(df.style.set_properties(**{'text-align': 'left'}))
df.head()

次に、テキスト処理するカラムを指定します。
これもGoogleColabのフォーム機能を利用し、カラム名を入力することで指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、テキストと入力しています。
#@title 意見カラム名の入力 { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
SentenceTransformers
#@title SentenceTransformerモデル読込み → fit
from sentence_transformers import SentenceTransformer
model_ = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')
#@title テキストリスト化 → ベクトル化
from sentence_transformers import SentenceTransformer, util
import torch
# corpus_list(前処理し、データフレームに格納したテキストをリスト化)
corpus_list = df[column_name].to_list()
# embeddings(ベクトル化)
corpus_embeddings = model_.encode(corpus_list, convert_to_tensor=True)
意味検索(セマンティック検索)
#@title Cos類似度を利用した Keyword による原文検索(OR検索)
#@markdown **<font color= "Crimson">ガイド</font>:意味で検索したいキーワードを Keywords 欄 に入力('A','B',… 等)して実行してください。**</font>
Keywords = 'いやだ', '環境', '将来' #@param {type:"raw"}
Number_of_texts_shown = 5 #@param {type:"slider", min:3, max:10, step:1}
from sentence_transformers import SentenceTransformer, util
# Keywordsとテキストのコサイン類似度を算出し、意味が近いテキストを指定した数で表示
top_k = min(Number_of_texts_shown, len(corpus_list))
print('\n')
print('● Keywords と意味が近いテキストを検索した結果')
print('\n')
for keyword in Keywords:
keyword_embedding = model_.encode(keyword, convert_to_tensor=True)
cos_scores = util.cos_sim(keyword_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
print("Keyword:", keyword)
for score, idx in zip(top_results[0], top_results[1]):
print('\t✓', corpus_list[idx], "(Cos類似度: {:.3f})".format(score))
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
#@title Cos類似度を利用した Keyword による原文検索(AND検索)
#@markdown **<font color= "Crimson">ガイド</font>:意味で検索したいキーワードを Keywords 欄 に入力('A','B',… 等)して実行してください。**</font>
Keywords = 'いやだ', '環境', '将来' #@param {type:"raw"}
Number_of_texts_shown = 5 #@param {type:"slider", min:3, max:10, step:1}
from sentence_transformers import SentenceTransformer, util
# Keywordsとテキストのコサイン類似度を算出し、意味が近いテキストを指定した数で表示
top_k = min(Number_of_texts_shown, len(corpus_list))
print('\n')
print('● Keywords と意味が近いテキストを検索した結果')
print('\n')
keyword_sum = '|'.join(Keywords)
keyword_sum_embedding = model_.encode(keyword_sum, convert_to_tensor=True)
cos_scores = util.cos_sim(keyword_sum_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
print("Keyword:", Keywords,"のAnd検索")
for score, idx in zip(top_results[0], top_results[1]):
print('\t✓', corpus_list[idx], "(Cos類似度: {:.3f})".format(score))
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
#@title Cos類似度を利用した Keyword による原文検索
#@markdown **<font color= "Crimson">ガイド</font>:意味で検索したいキーワードを Keywords 欄 に入力('A','B',… 等)して実行してください。**</font>
Search_type = 'AND' #@param ['AND','OR']
Keywords = 'いやだ', '環境', '将来' #@param {type:"raw"}
Number_of_texts_shown = 5 #@param {type:"slider", min:3, max:10, step:1}
from sentence_transformers import SentenceTransformer, util
import torch
# Keywordsとテキストのコサイン類似度を算出し、意味が近いテキストを指定した数で表示
top_k = min(Number_of_texts_shown, len(corpus_list))
print('\n')
print('● Keywords と意味が近いテキストを検索した結果')
print('\n')
if Search_type == 'OR':
for keyword in Keywords:
keyword_embedding = model_.encode(keyword, convert_to_tensor=True)
cos_scores = util.cos_sim(keyword_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
print("Keyword:", keyword)
for score, idx in zip(top_results[0], top_results[1]):
print('\t✓', corpus_list[idx], "(Cos類似度: {:.3f})".format(score))
else:
keyword_sum = '|'.join(Keywords)
keyword_sum_embedding = model_.encode(keyword_sum, convert_to_tensor=True)
cos_scores = util.cos_sim(keyword_sum_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
print("Keyword:", Keywords,"のAnd検索")
for score, idx in zip(top_results[0], top_results[1]):
print('\t✓', corpus_list[idx], "(Cos類似度: {:.3f})".format(score))
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
参考