
はじめに
「このテキストデータはどんなトピックで構成されているんだろう?」
これがわかると、把握や整理を行う助けになりますが、これを人的にこなすのは大変です。
機械の力を借りるとしても、テキストの前処理、形態素解析、ベクトル処理などが必要ですし、このケースは「教師なし学習」となりますので結果の解釈も伴います。
おまけに「事前にトピック数を決めて」などといわれると、手をつけようと思う初心者はまずいないのではないか?と感じます。
ただ、自然言語処理におけるテキスト分類は、機械学習や深層学習の進歩に伴い、単語の意味的な関係や文脈をより正確に理解できるようになってきているだけではなく、ほぼテキストデータを与えて実行するだけ等、実行の面も進歩しています。
この記事で扱う BERTopic は、形態素解析はおまかせ、トピック数も自動決定され、トピックモデリングに関する様々な可視化も簡単ということで、手つけやすさの敷居はずいぶん下がっている思います。
- 溜まる一方のテキストデータをなんとか整理・分類したい。
- 整理・分類まではいいが、あとで必要になったときに確実に引っかかる(検索)ようにしたい。
一過性のテキストデータはさておき、何とかしたいと思うものの、なかなかうまくいかないのがテキストデータとのお付き合いと思います。
ということで、この記事では BERTopic でテキストデータの分類がどの程度できるかを探ってみたいと思います。
用語の説明
トピックモデル
ニュース記事や口コミなどのテキストデータを分析すると、政治やスポーツやレストランなどのトピックが見つかります。
トピックモデルは、テキスト全体から各テキストのトピック(話題)を抽出する手法です。
BERTopic
BERTopic は、自然言語処理におけるトピックモデリング手法の1つです。Googleが開発したBERT(Bidirectional Encoder Representations from Transformers)という深層学習モデルをベースにしています。このモデルは、事前学習を通じて、テキストの単語表現をより複雑な文脈に基づいたより高次元のベクトル表現に変換することができることから、BERTopicは単語の意味的な関係や文脈をより正確に理解することができ、データから最適なトピック数を自動的に決定することもできるため、より柔軟で正確なトピック分析が可能とされています。
BERTopicによるトピックは、
まず、k-meansクラスタリングアルゴリズムによる初期クラスタリングを行い、HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise)アルゴリズムを使用して、各クラスターの密度に基づいてクラスターをマージします。クラスタリングの安定性と品質を向上させるためにこのプロセスが繰り返された後、HDBSCANは最適なトピック数を自動的に推定し、各トピックの代表語を決定します。
実行したこと
BERTopic実行結果
まず、ライブラリのインストールし、データを読み込みます。
initial settingは、何のデータを読み込むかのセッティングです。任意のtxtやcsvも読めるようにしています。今回は「再エネ」に関するtweetデータを読み込んでいます。

以下は読み込んだデータの表示です。
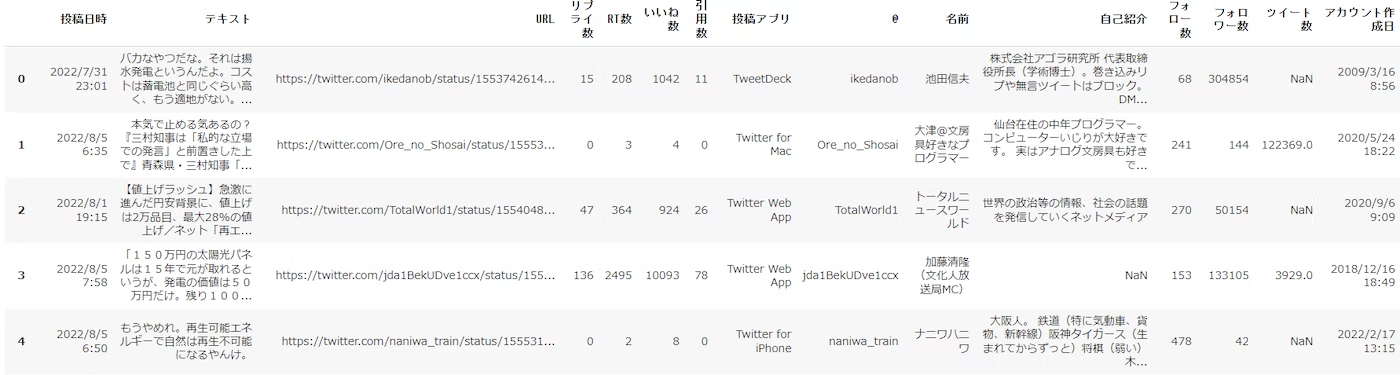
次に、テキスト分析したいデータカラム名を指定し、その後、最低限のテキスト処理も行っています。
実施したテキスト処理は、URL、メンション、記号、改行などの削除です。
stop_wordsは、表示させたくない語の設定です。今回読込んだtweetデータは、yahooニュースからの引用も多く、トピックの代表的なwordに「yahooニュース」が出てきていましたので、一度実行した後、追加しました。
BERTopicは、これらのテキスト処理を行わなくても実行できますが、結果を眺めつつ、最低限の処理はしたほうがよさそうです。

実行準備はここまでです。
BERTopicモデルを読込み、テキストでをfitさせます。
fitにすこし時間はかかりますが、これで処理はおしまいです。
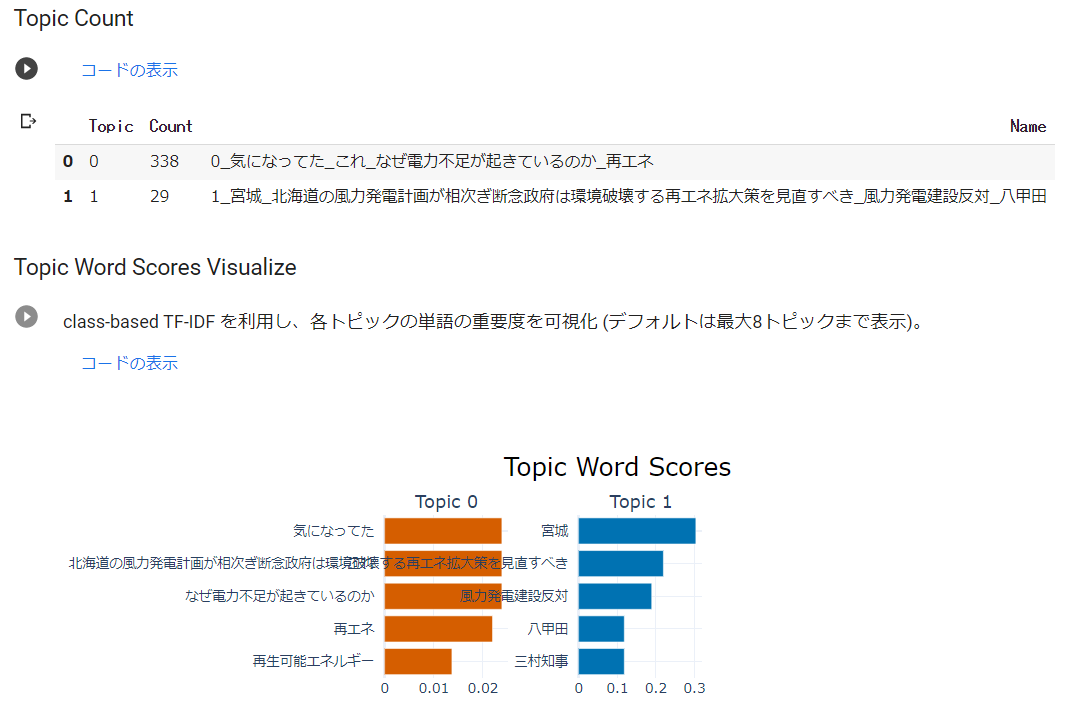
どのようなトピックに分けられたかみてみます。
以下の通り、なんと2つです。
※ どのトピックにも属さなかった場合、topic-1に位置付けられるようです。テキストの前処理を行わなわずに実行した時、「topic:-1」となったデータがいくつかありました。このことからも実行前に最低限の前処理は実行した方がよさそうです。
前回の記事では、同じデータをLDAでテキスト分類しています。
このデータは、トピックに分けるほどのバラエティがないんじゃないかなと予想していましたが、その通りだったようです。トピック(topic)とカウント(count)の関係を見ると明らかですね。
このデータは、テキスト分類するほどでもないのかもしれませんが、各トピックの代表的な語彙や強さがグラフで示されますので、わかりやすいです。
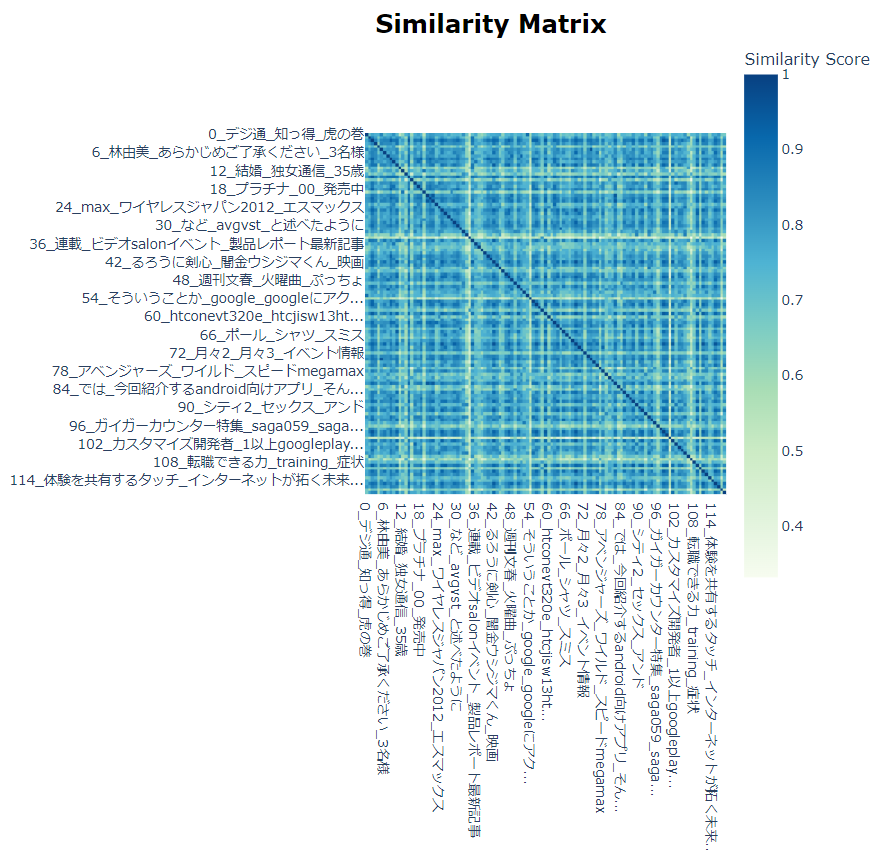
ただ、上記の結果は、試行としてはすこしさみしいので、livedoorコーパスでも適用してみました。うーん、いいですね。

グラフだけではなく、以下のように各トピックの代表的な語彙と強さの一覧も出せます。

以下は、Term score表示です。

トピックの分布を可視化するためのメソッドもあり、実行したのですが、以下と通りエラーとなりました。

発生したエラーは以下です。
ValueError: zero-size array to reduction operation maximum which has no identity
このエラーは、トピックモデルに渡される文書が空であったり、トピックモデルが生成したトピックが空である時などに出るようです。トピックモデルに十分な文書や情報が与えられていない可能性があるということなのですが、原因がよくわかりませんでしたので、livedoorコーパスでも実行し、これではうまくいきました。
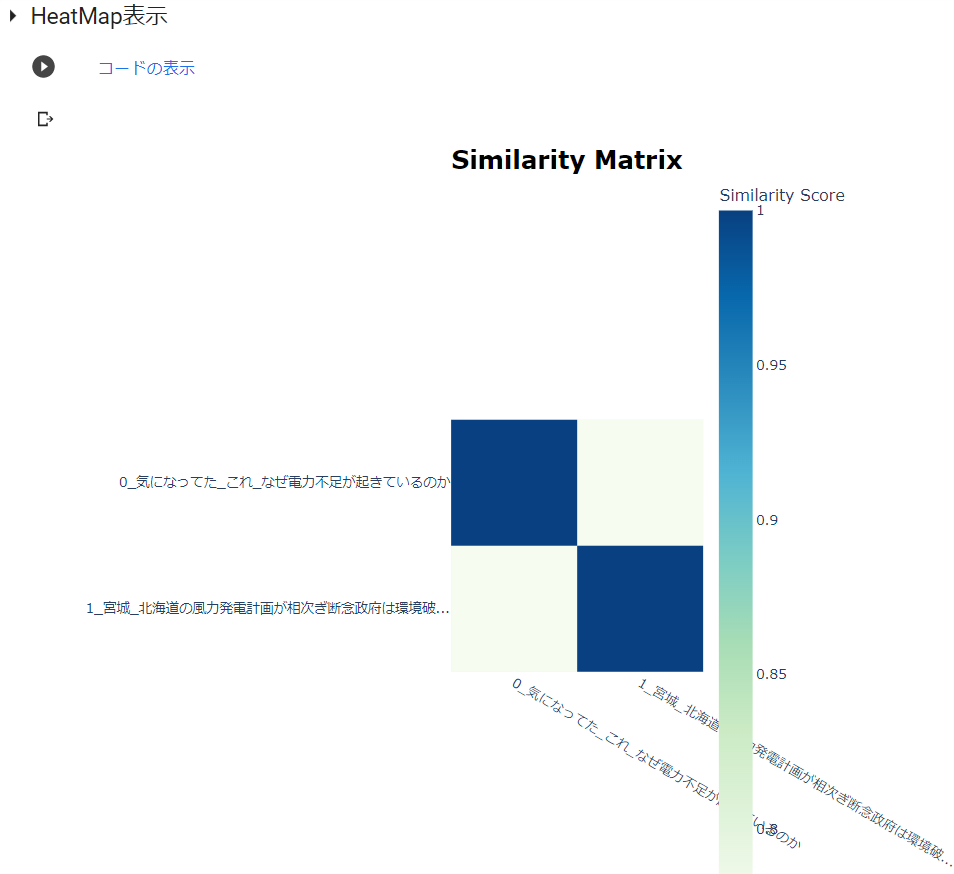
heatmapも表示できます。
これはlivedoorコーパスの結果です。
最後に
私はこれまで、教師なしのテキスト分類によい印象が持てずにいましたが、BERTopicで認識が変わりました。
とにかく手軽、解釈の助けとなる視覚化も充実しています。
この記事で実行したことは、公式のサンプルコードそのものです。
データがあれば、最低限の前処理だけで実行できます。
公式には、この記事で紹介したこと以外に実行できることもありますので、ご興味ある方はぜひ!という感じです。
もう、ちまちまと形態素解析から始める時代は終わりを迎えるかもしれませんねぇ。
実行コード
GoogleColabで実行するためのライブラリのインストール
以下のライブラリや辞書をインストールしました。
%%capture
!pip install bertopic
データ読込み
まず、データの読込みです。
データの読込みにおいては、GoogleColabのフォーム機能を利用し、データセットを選択できるようにしています。
選択肢は2つ。tweetサンプルデータ(tweet_data_sampleを選択)と、任意のcsvファイル(Uploadを選択)です。
※tweet_data_sampleは、Githubにアップしたこの記事の適用データです。
#@title Initial Settings { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'tweet_data_sample' #@param ['tweet_data_sample','蜘蛛の糸','Upload_csv','Upload_txt']
以下を実行すると、datasetの選択に沿ったデータが読み込まれ、読み込んだデータをデータフレームに反映し、表示します。
#@title データ読込み
#@markdown **<font color= "Crimson">ガイド</font>:Upload 選択 ⇒ [ファイル選択]ボタンをクリックしてください。サンプルデータの場合は自動で読み込みます。**
import pandas as pd
import numpy as np
pd.set_option('display.unicode.east_asian_width', True)
from google.colab import files
import codecs
import warnings
warnings.simplefilter('ignore')
# データの読み込み
if dataset =='Upload_csv':
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target,encoding='utf-8')
elif dataset == 'tweet_data_sample':
file_url ='https://raw.githubusercontent.com/hima2b4/Natural-language-processing/main/TwExport_20220806_152219.csv'
df = pd.read_csv(file_url,encoding='utf-8')
elif dataset =='Upload_txt':
files = files.upload()
filename = list(files.keys())[0]
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
elif dataset == "蜘蛛の糸":
#蜘蛛の糸のテキストデータ(zipファイル)をダウンロード
!curl -O "https://www.aozora.gr.jp/cards/000879/files/92_ruby_164.zip"
#zipファイルを解凍
!unzip 92_ruby_164.zip
#文章切り出し(=注釈削除 [冒頭削除:tail -n +**][末尾削除:head -n -**] 任意設定要)
!tail -n +18 kumono_ito.txt | head -n -15 > kumono_ito_data.txt
#テキストファイル読み込み
text_file = open('/content/kumono_ito_data.txt',encoding = 'shift_jis')
def main():
# Shift_JIS ファイルのパス
shiftjis_path = 'kumono_ito_data.txt'
# UTF-8 ファイルのパス
filename = 'kumono_ito_utf.txt'
# 文字コードを utf-8 に変換して保存
fin = codecs.open(shiftjis_path, "r", "shift_jis")
fout_utf = codecs.open(filename, "w", "utf-8")
for row in fin:
fout_utf.write(row)
fin.close()
fout_utf.close()
if __name__ == '__main__':
main()
filename = 'kumono_ito_utf.txt'
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
#pd.set_option('display.max_colwidth', None)
#display(df.style.set_properties(**{'text-align': 'left'}))
df.head()

次に、テキスト処理するカラムを指定します。
これもGoogleColabのフォーム機能を利用し、カラム名を入力することで指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、テキストと入力しています。
#@title 意見カラム名の入力 { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
テキスト処理
つぎは、テキスト処理です。
#@title 意見カラムの名称入力 { run: "auto" }
#@markdown **<font color= "Crimson">必須</font>:テキスト分析したいカラム名を指定してください。**</font>
column_name = 'テキスト' #@param {type:"raw"}
#@title テキスト処理
#from collections import Counter
#import spacy
import pandas as pd
import re
#import time
#from tqdm import tqdm
# 口コミに含まれている空行を削除
#df[column_name] = df[column_name].replace('\n+', '\n', regex=True)
#df.dropna(subset=[column_name], inplace=True)
stop_words = 'ザ・リバティWeb', 'Yahooニュース','TheLibertyWeb','Yahoo!ニュース','日本経済新聞' #@param {type:"raw"}
# テキストデータの前処理
def text_preprocessing(text):
# 改行コード、タブ、スペース削除
text = ''.join(text.split())
# URLの削除
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', text)
# メンション除去
text = re.sub(r'@([A-Za-z0-9_]+)', '', text)
# 記号の削除
text = re.sub(r'[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥]', '', text)
# stop_wordsを'|'で連結して正規表現パターンを作る
pattern = '|'.join(stop_words)
# re.sub()でパターンにマッチする部分を空文字に置換する
text = re.sub(pattern, '', text)
return text
df[column_name] = df[column_name].map(text_preprocessing)
# 口コミに含まれている空行を削除
df[column_name] = df[column_name].replace('\n+', '\n', regex=True)
df.dropna(subset=[column_name], inplace=True)
# corpus_list(前処理し、データフレームに格納したテキストをリスト化)
corpus_list = df[column_name].to_list()
df.head()
BERTopic
#@title BERTopicモデル読込み → fit
import pandas as pd
from bertopic import BERTopic
# load model & clustering
model = BERTopic(embedding_model="paraphrase-multilingual-MiniLM-L12-v2") # 多言語モデルで日本語を使う
topics, probs = model.fit_transform(corpus_list)
トピックカウント
#@title Topic Count
display(model.get_topic_info().style.set_properties(**{'text-align': 'left'}))
トピックグラフ
#@title Topic Word Scores Visualize
#@markdown class-based TF-IDF を利用し、各トピックの単語の重要度を可視化 (デフォルトは最大8トピックまで表示)。
model.visualize_barchart()
トピックWordスコア
#@title Topic Word Scores
model.get_topics()
Term score
#@markdown トピックは、最も代表的な単語から始まるいくつかの単語で表現される。各単語はc-TF-IDFスコアで表現される。スコアが高いほど、トピックを代表する単語を意味する。トピックの単語はc-TF-IDFスコアでソートされているため、単語を追加するごとにスコアは徐々に低下する。ある時点で、トピックの表現に単語を追加しても、c-TF-IDFスコアの合計がわずかに増加するだけになる。この効果を視覚化するために、各トピックのc-TF-IDFスコアを各単語の順位でプロットすることができる。つまり、c-TF-IDFスコアが最も高い単語がランク1となる単語の位置(単語ランク)をx軸に、Y軸にc-TF-IDFスコアを配置すると、トピック表現に単語を追加したときにc-TF-IDFスコアが低下していることを視覚化できる。これにより、エルボー法を用いて、トピックに含まれる最適な単語数が選択できる。
model.visualize_term_rank()
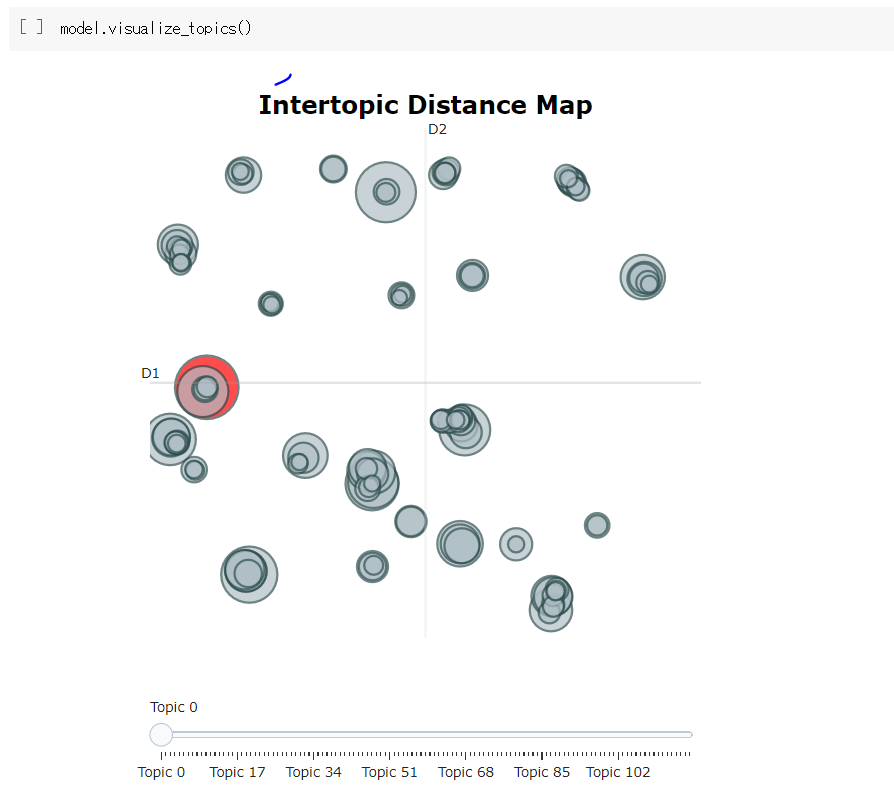
トピック分布可視化
model.visualize_topics()
heatmap
#@title HeatMap表示
model.visualize_heatmap()
データフレーム表示
#@title データフレーム表示
number_of_shown = 10 #@param {type:"slider", min:5, max:20, step:1}
result_df = pd.DataFrame(
{
"text": corpus_list,
"topic_no": topics,
"proba": probs,
}
)
#pd.set_option('display.max_colwidth', None)
result_df.head(number_of_shown)
参考