2022/10/01 国語研長単位がVer2.9→3.2にVer.upし、コード記述変更しないとインストールできなくなったのでpip変更
2022/08/16 一定の割合に満たない共起は除外(枝切り)するパラメータ(weight_cuttoff)を変更した際の共起ネットワークを追加。
はじめに

この書籍は、テキストアナリティクス初学者向けの入門書です。
テキストアナリティクスとは何だということのみならず、頻出語やこれを表現したWordCloud、共起ネットワークをどのように活用すべきかが、実例に沿ってわかりやすく解説されていて、とても参考になりました。
紹介されているテキストアナリティクスを実行したい!ということで、
- 1回目は、テキストの頻出語確認→WordCloud→共起ネットワークの作成および原文検察を、形態素解析した単語で実行。
- 2回目は、1回目の内容を複合語(名詞+名詞)で実行。
- 3回目は、ひとつの単語として表現したい複合語を辞書に登録し、実行しました。
テキストアナリティクスは、テキストを形態素解析にかけて単語に分解し、WordCloudや共起ネットワークを描いて、これらを手がかりに本文を読み込み、知見を得るプロセスとなります。
例えば、「再エネ」を形態素解析にかけると、「再」「エネ」に分解されます。
これでも分析できなくはなく、巷で初手として実施されているのは、ほぼこの単語単位だと思います。これで実行したのが1回目の記事。
ただ、「再」「エネ」のように名詞が連続している場合は、できれば分解せずに複合語として足し合わせて表現したい。これで実行したのが2回目の記事。
複合語として足し合わせて表現したい語を辞書に登録して実行したのが3回目です。
3回目の記事をアップした後、
@KoichiYasuokaさんから、
『「国語研長単位」モデルを使った方がうまくいくのではないか』 との意見を頂きました。
形態素解析により「再エネ」は「再」「エネ」と分解されてしまいますから、「再エネ」として扱えるように複合化したり、「再エネ」を辞書登録したりというのが、前回までの記事の内容ですが、この「国語研長単位」モデルを適用すれば、複合化や辞書登録は不要になる?!
これはやるっきゃない! ということで、早速実行するぞというのが 今回のテーマとなります。
実行したこと
- Google Colabで実行する
- Twitterデータ(csv)の読込み
- つぶやきの頻出語(上位)をグラフ化
- WordCloud生成
- 共起ネットワーク生成
GoogleColabでの実行に関する補足
以下のライブラリや辞書をインストールしました。
※ CUDA is not available というメッセージが出ましたが実行に問題はありませんでした。GPUで動作させるとこのメッセージは出ませんでした。
!pip install sudachipy sudachidict_core
!pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
#!pip install ja_gsdluw deplacy -f https://github.com/megagonlabs/UD_Japanese-GSD/releases/tag/r2.9-NE
!pip install https://github.com/megagonlabs/UD_Japanese-GSD/releases/download/r2.9-NE/ja_gsdluw-3.2.0-py3-none-any.whl
import pkg_resources, imp
imp.reload(pkg_resources)
pip install pyvis
!apt-get -y install fonts-ipafont-gothic
!pip install japanize-matplotlib
#nlp = spacy.load('ja_ginza')
nlp = spacy.load("ja_gsdluw")
頻出語グラフ -複合語対応でどうなる?-
前々回記事同様、「再エネ」でtweet検索したつぶやきを ついすぽ でcsvにエクスポートしたデータとしています。
書籍に紹介されていた複合語(名詞+名詞)に加え、'PROPN', 'VERB', 'ADJ'(固有名詞と動詞と形容詞)も加えて、上位の頻出語を確認しました。
まず、普通に実行した結果が以下です。
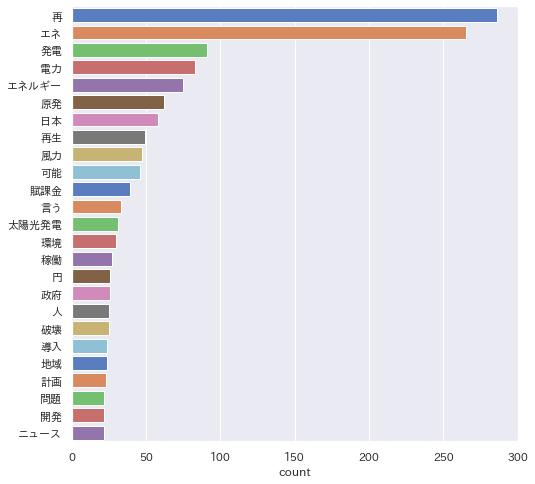
次に複合語対応(+固有名詞+動詞+形容詞)して実行した結果です。
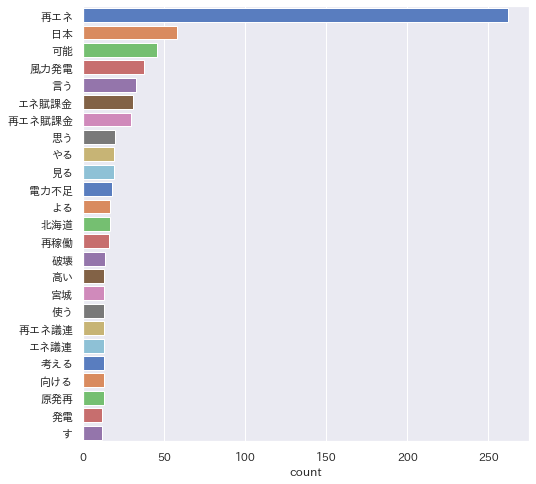
次に辞書登録して実行した結果です。
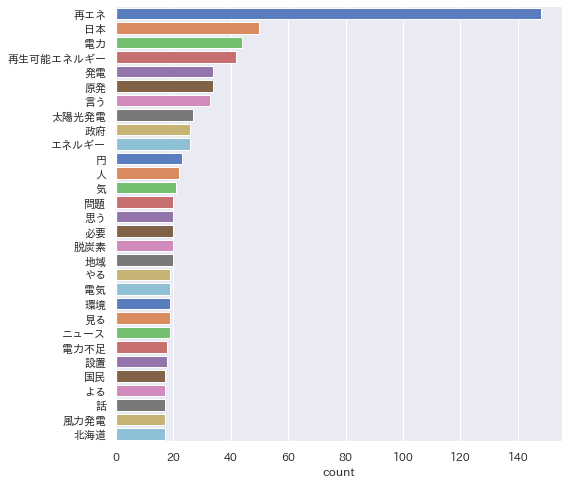
そして、「国語研長単位」モデルを適用し、実行した結果が以下です。
もう すばらしい! としか、いいようがありません。
tweetを「再エネ」で検索したデータなので「再エネ」が頻出するのは当然ですが、単語 → 複合語 → 辞書登録 → 国語研長単位」辞書 と「再エネ」の辞書登録により他の語も均等に見えるようになりました。

WordCloud生成
次に、先と同様、複合語対応(+固有名詞+動詞+形容詞)したWordCloudを描きました。
まず、普通に実行した結果が以下です。

次に複合語対応(+固有名詞+動詞+形容詞)して実行した結果です。

次に辞書登録して実行した結果です。
辞書登録した「再生可能エネルギー」他が表示されていることが確認できました。

そして、「国語研長単位」モデルを適用し、実行した結果が以下です。
一発でこのアウトプットが得られるのはすごいです。

共起ネットワーク
次に、共起ネットワーク を描きました。
まず、普通に実行した結果が以下です。
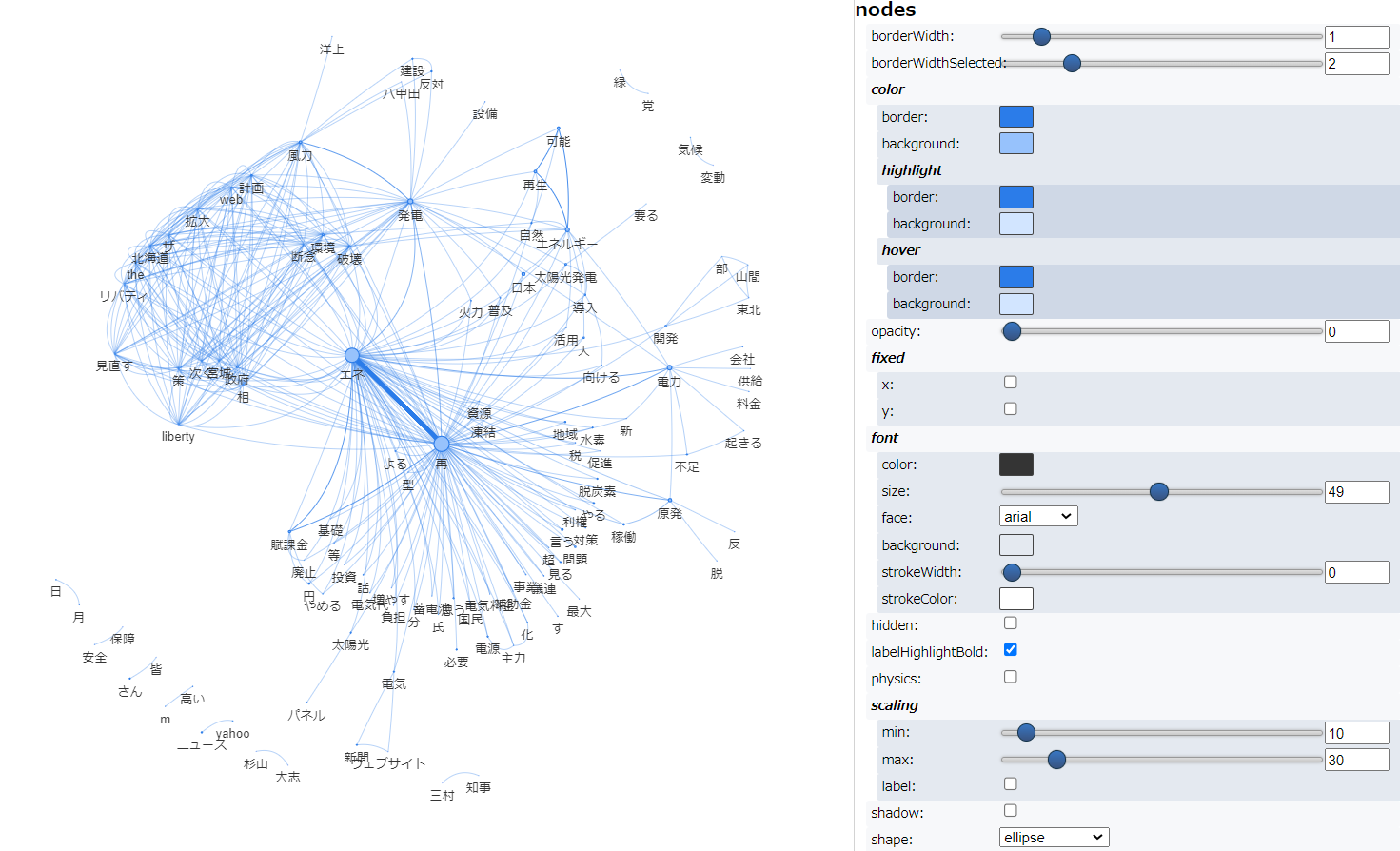
次に複合語対応して実行した結果です。
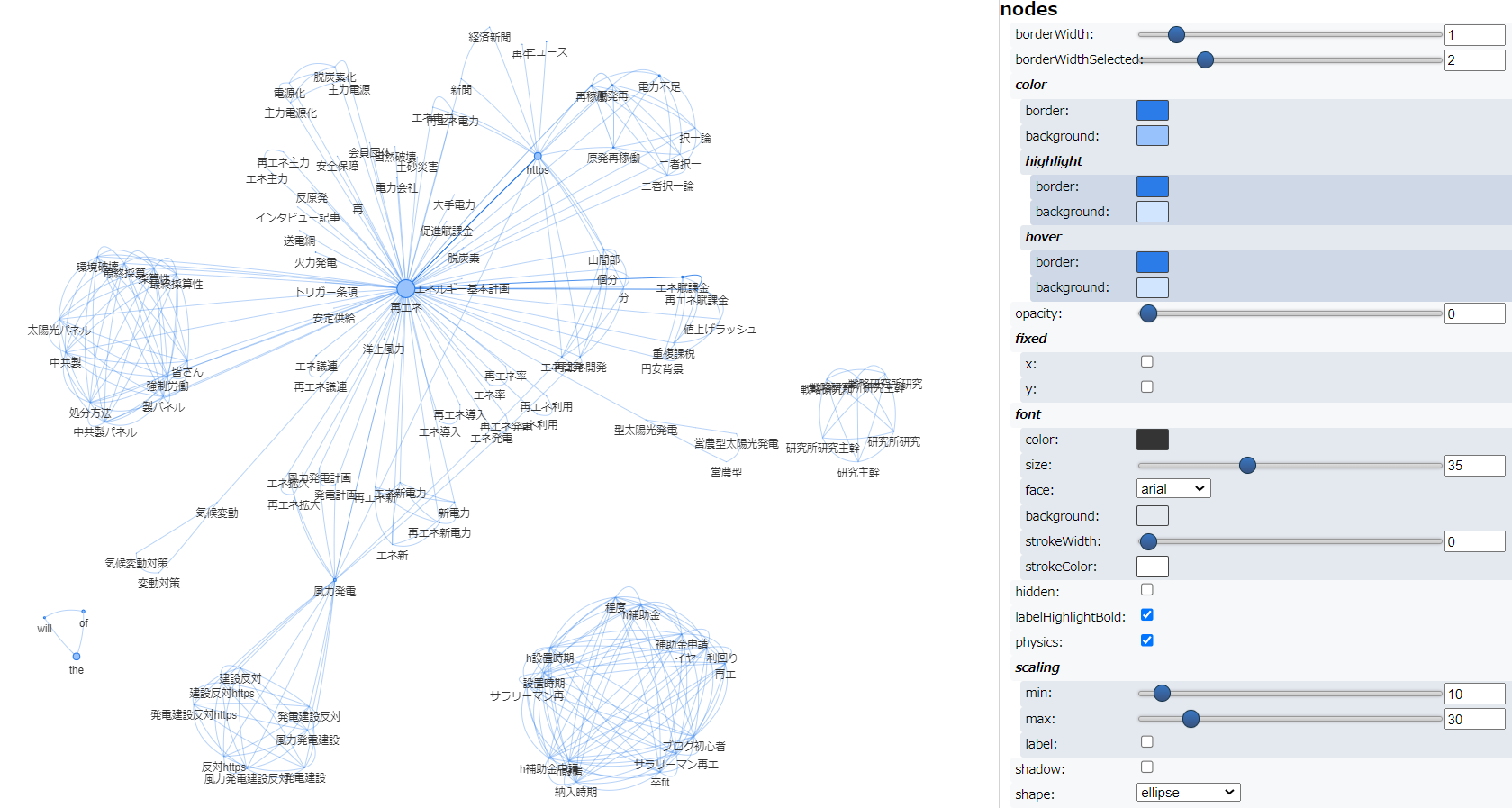
次に辞書登録して実行した結果です。
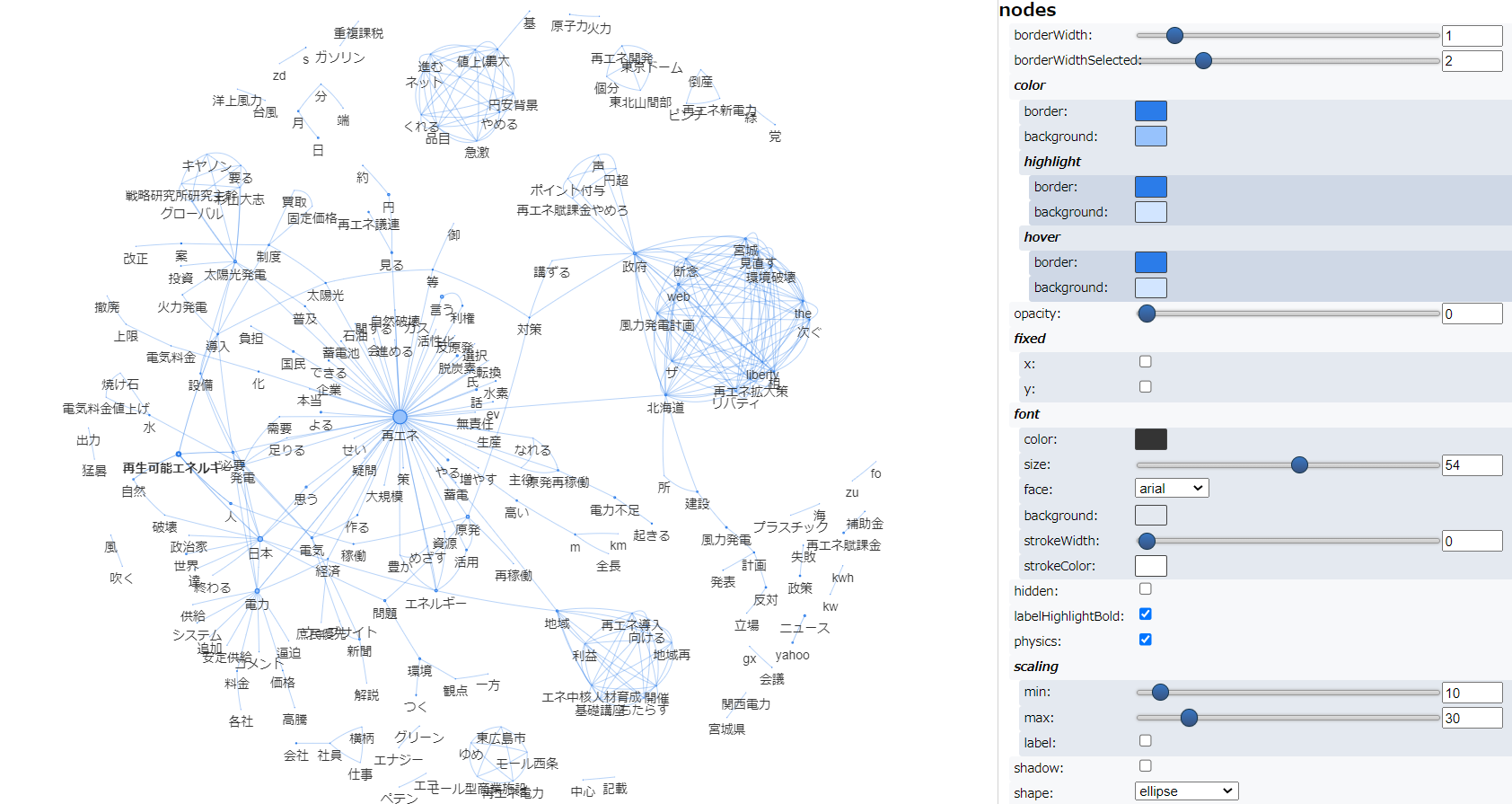
そして、「国語研長単位」モデルを適用し、実行した結果が以下です。
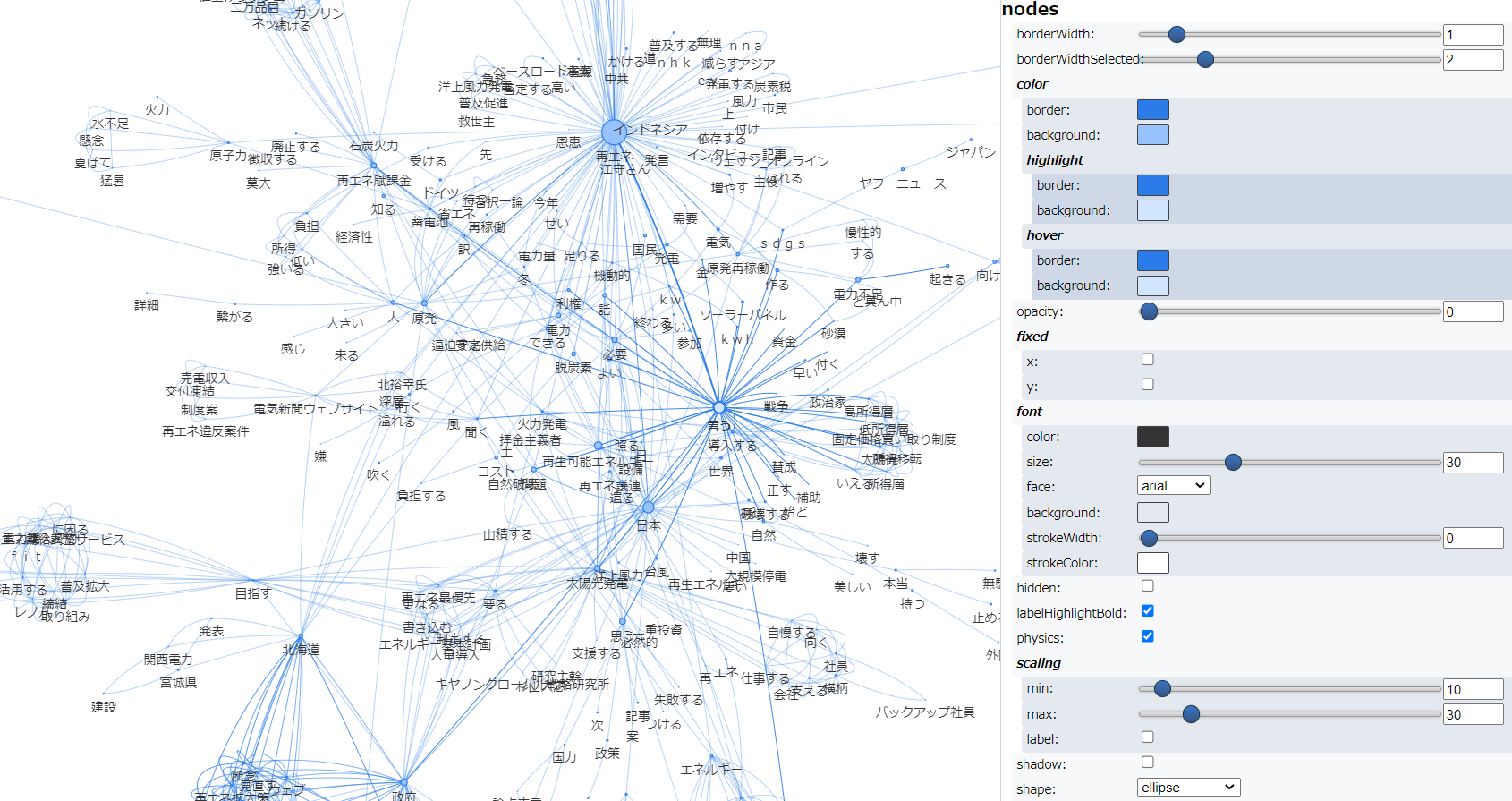
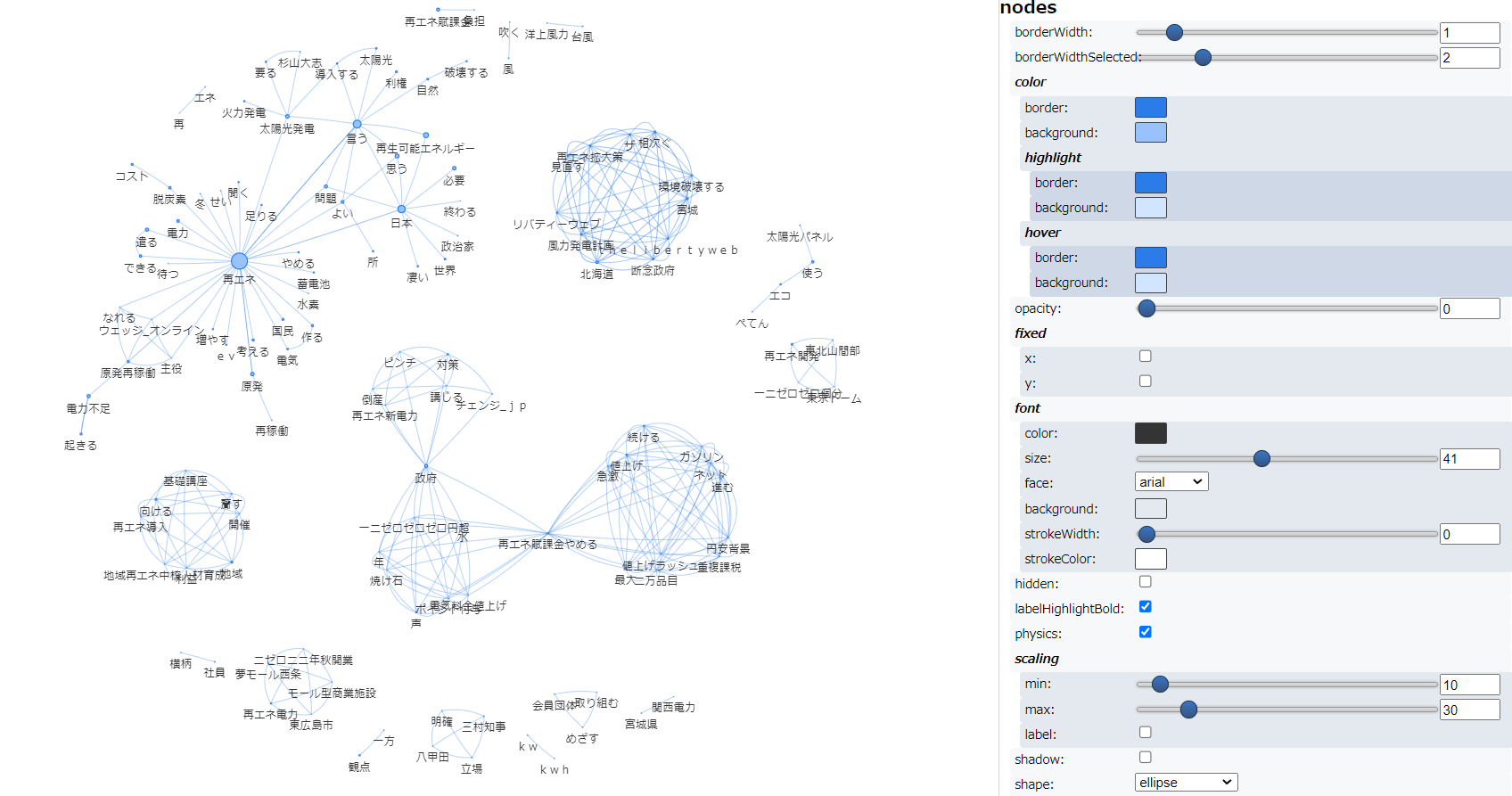
すこし粒度が細かな共起ネットワークとなりました。テキストアナリティクス入門 で紹介されている共起ネットワークのコードに一定の割合に満たない共起は除外(枝切り)するweight_cuttoffというパラメータ設定 がありますので、0.02 → 0.03に変更し、実行した結果が以下です。スッキリし、可読性があがりました。
最後に
@KoichiYasuokaさんに紹介いただいた 「国語研長単位」モデルを使わせていただきました。
テキストアナリティクスを進めるにあたり「このまとまりであって欲しい」と期待する名詞+名詞等で表現された複合語がモデル設定だけで得ることができます。これはすごいですね。
ja_ginza を読み込んだ時と比較しますと、形態素解析や原文検索の処理にすこし時間を要しましたが、特別な操作なく、これだけの結果が簡便に得られたこと、素直にうれしく思います。
※ でも、原文検索だけはja_ginzaのお世話になろうかな 笑
あと、余談ですが、適用したtweetデータには「 」(全角スペース)やURL(※https://t.co…) を含むつぶやきが数多くありましたので、全角スペースが頻出語上位に現れたり、WordCloudに「HTTPS」が表示されたりしました。
「 」や「HTTPS」をstopwordに設定することで、頻出語とWordCloudについては対応できましたが、共起ネットワークはネットワーク図に現れた「https」「t」「co」をstopwordに設定してもなぜか表記を消すことができませんでしたので、形態素解析を行う前にデータから「 」(全角スペース)やURLを除去しました。
テキストアナリティクスにおいては、形態素解析の前に明らかに不要な語を除去する前処理も大事ですね。
最後に、貴重な情報を紹介いただいた@KoichiYasuokaさん、ありがとうございました😭。
長単位、今後も活用させていただきます。
参考