2022/08/15 紹介いただいた「国語研長単位」モデルで実行した番外編の記事もアップしました。
はじめに

この書籍は、テキストアナリティクス初学者向けの入門書です。
テキストアナリティクスとは何だということのみならず、頻出語やこれを表現したWordCloud、共起ネットワークをどのように活用すべきかが、実例に沿ってわかりやすく解説されていて、とても参考になりました。
紹介されているテキストアナリティクスを実行したい!ということで、
- 1回目は、テキストの頻出語確認→WordCloud→共起ネットワークの作成および原文検察を、形態素解析した単語で実行。
- 2回目は、1回目の内容を複合語(名詞+名詞)で実行。
- 3回目である今回は、ひとつの単語として表現したい複合語を辞書に登録し、実行してみました。
テキストアナリティクスは、テキストを形態素解析にかけて単語に分解し、WordCloudや共起ネットワークを描いて、これらを手がかりに本文を読み込み、知見を得るプロセスとなります。
例えば、「再エネ」を形態素解析にかけると、「再」「エネ」に分解されます。
これでも分析できなくはなく、巷で初手として実施されているのは、ほぼこの単語単位だと思います。これで実行したのが1回目の記事。
ただ、「再」「エネ」のように名詞が連続している場合は、できれば分解せずに複合語として足し合わせて表現したい。これで実行したのが2回目の記事。
複合語として足し合わせて表現したい語を辞書に登録して実行しようというのが3回目(今回)です。
複合語の対応は2回目の対応でなんとかできましたので、辞書登録に踏み込むかはすこし迷いました。
また、書籍に紹介されている辞書登録のコードはGoogleColabに対応するためにすこし改変する必要もありましたので、スルーしていましたが、2回目に実行した共起ネットワークは、名詞+名詞の複合語以外の品詞に適用させることができませんでしたので、複合語を辞書登録し、他の品詞もあわせて適用しようというのが 今回のテーマとなります。
辞書登録について
書籍に紹介されている辞書登録のコードは、以下の内容となっています。
- 名詞と固有名詞の単語が それぞれ2つ3つ連続する複合語をテキストから200抽出し、textファイルに出力
- 抽出された複合語を厳選し、textファイルに保存、sudachiの辞書形式に変換
- sudachiの設定ファイルに辞書を追加
最後の設定ファイルの追加は、GoogleColabに見合った設定としないといけませんので、以下のサイトを参考にさせていただきました。
実行したこと
- Google Colabで実行する
- Twitterデータ(csv)を読込み、複合語を抽出し、厳選の上、辞書登録
- つぶやきの頻出語(上位)をグラフ化
- WordCloud生成(前回記事参照)
- 共起ネットワーク(複合語Ver.) 生成
辞書登録の実行に関する補足
- 書籍のコード実行すると、抽出された複合語が格納されたcharacters_raw.txt が出力されます。
- characters_raw.txt をPCデスクトップなどにダウンロードし、テキストエディタで開き、辞書登録したい単語を選び、characters.txt にリネームして保存します。
- 保存したcharacters.txt をGoogleColabにアップロードし、以下をGoogleColabで実行します。
!sudachipy ubuild \
-s /usr/local/lib/python3.7/dist-packages/sudachidict_core/resources/system.dic \
dic_characters.txt
※私の環境では、実行すると以下が表示され、user.dic が生成されました。
/content/dic_characters.txt -> 152 in 0.00 sec
validate -> 152 in 0.00 sec
pos_table -> 2 in 0.00 sec
conn_matrix -> 6 in 0.00 sec
trie -> 7172 in 0.00 sec
word_id table -> 764 in 0.00 sec
word_params -> 916 in 0.00 sec
wordinfo_offsets -> 608 in 0.00 sec
wordinfos (copy only) -> 3910 in 0.00 sec
次にこちらのサイトで公開してくださっている「ユーザー辞書の設定追加スクリプト」を実行すれば辞書登録完了です。
私の環境では、実行により以下が表示されました。
sys_dic_path: /usr/local/lib/python3.7/dist-packages/sudachidict_core/resources/>system.dic
user_dic_path: /content/user.dic
sudachi_path: /usr/local/lib/python3.7/dist-packages/sudachipy/resources/>sudachi.json
update
頻出語グラフ -複合語対応でどうなる?-
前々回記事同様、「再エネ」でtweet検索したをつぶやきを ついすぽ でcsvにエクスポートしたデータとしています。
書籍に紹介されていた複合語(名詞+名詞)に加え、'PROPN', 'VERB', 'ADJ'(固有名詞と動詞と形容詞)も加えて、上位の頻出語を確認しました。
まず、普通に実行した結果が以下です。
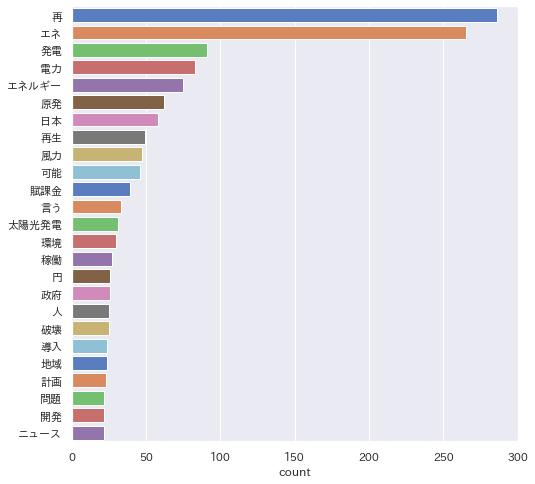
次に複合語対応(+固有名詞+動詞+形容詞)して実行した結果です。
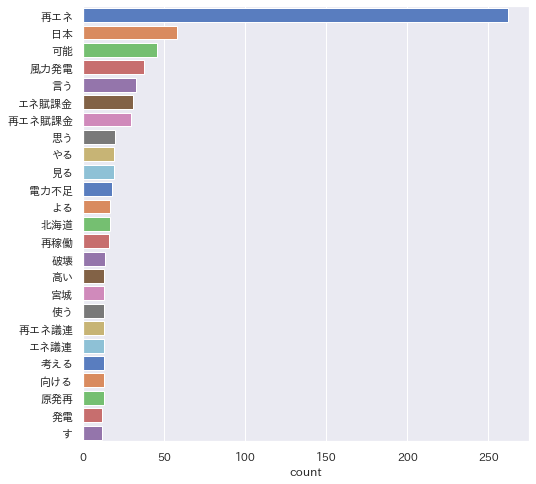
そして以下が、辞書登録して実行した結果です。
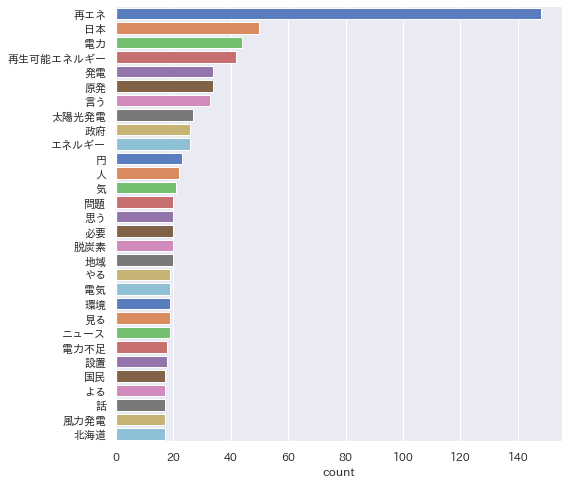
tweetを「再エネ」で検索したデータなので、「再エネ」が多いのは当然ですが、辞書登録により他の語も均等に見えるようになりました。(※これだけ頻出語表示数を30にしています。)
WordCloud生成
次に、先と同様、複合語対応(+固有名詞+動詞+形容詞)したWordCloudを描きました。
まず、普通に実行した結果が以下です。

次に複合語対応(+固有名詞+動詞+形容詞)して実行した結果です。

そして以下が辞書登録して実行した結果です。

辞書登録した「再生可能エネルギー」他が表示されていることが確認できました。
共起ネットワーク
次に、共起ネットワーク を描きました。
まず、普通に実行した結果が以下です。
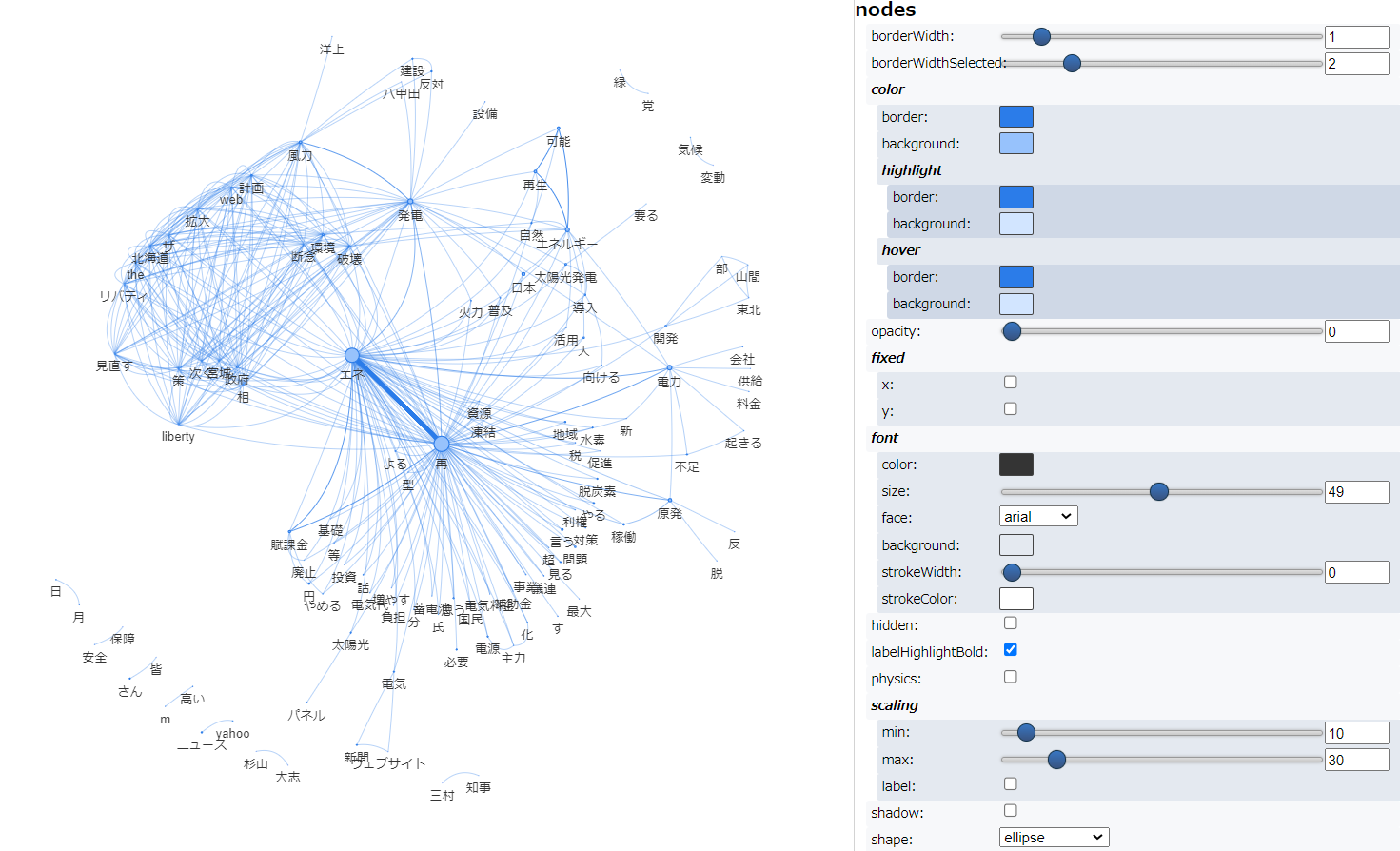
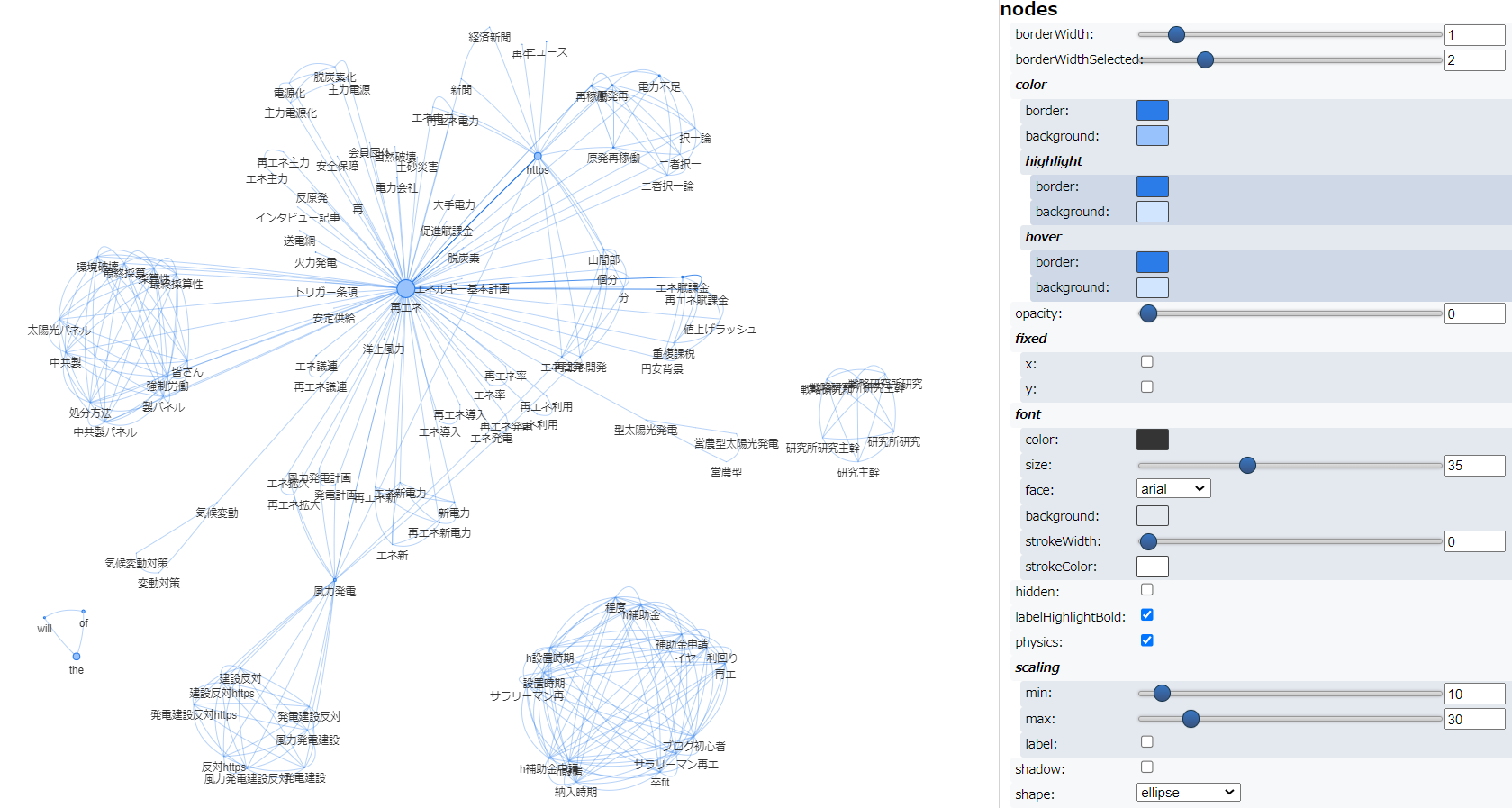
次に複合語対応して実行した結果です。
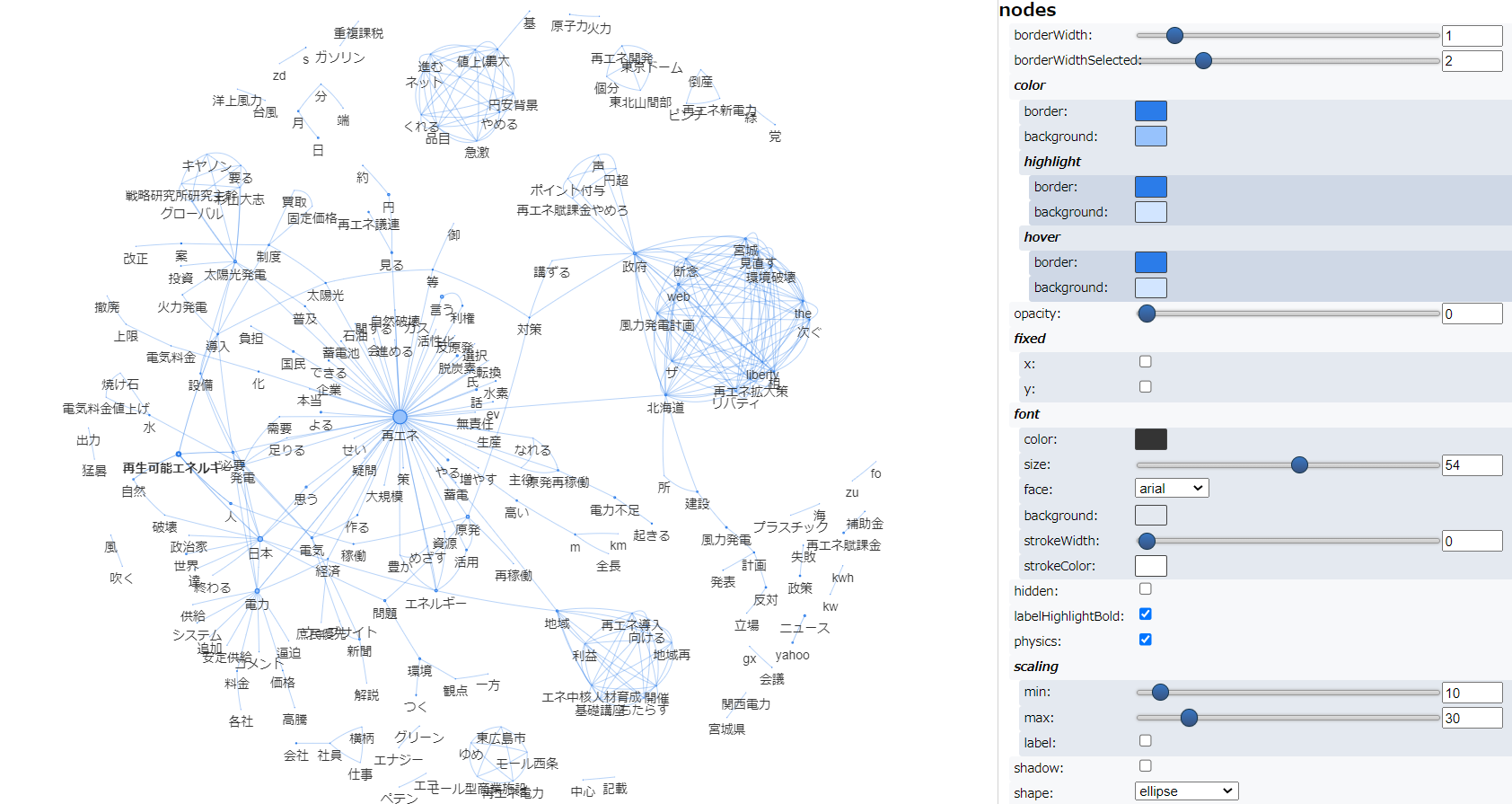
そして以下が辞書登録して実行した結果です。
最後に
「テキストアナリティクス入門」で紹介されている、頻出語→WordCloud→共起ネットワーク→本文検索を、単語、複合語、辞書登録の3パターンで実行してみました。
この一連の実行で、2回目に実行した頻出語グラフとWordCloudは「名詞」を取り上げるのを忘れていることに気がつきました。(すいません)
2回目と3回目の実行結果は、おおむね同じ結果になるはずなのに、若干異なるのはこのためです。
※2回目は「複合語+固有名詞+動詞+形容詞」、3回目は「名詞+固有名詞と動詞+形容詞」です。辞書登録した単語は名詞と固有名詞の中に含まれています。
辞書登録は「すこし面倒かな」と思っていましたが、やってみるとそうでもありませんでした。
頻出語グラフとWordCloudは、3回目の内容がもっとも現実的なのだろうと思います。
一方、共起ネットワークは、複合名詞だけで描いた2回目のほうが3回目よりも可読性が高いように思いました。
これは、テキストの内容によって変わるのではないかと思いますので、これさえやっておけば、この方法をとっておけばということではないのかもしれません。
「テキストアナリティクス入門」に、
『「さまざまな手掛かりで対象となるテキストを絞り込んだうえで、本文を読み込む」というのが実際の分析のうえでのプロセス』とありました。
う〜ん、なるほど。
頻出語グラフ、WordCloud、共起ネットワークなどを手掛かりに、本文を読み込むということを繰り返し、テキストの本質に迫ってゆくということが大事なんだなということで、全3回の試行を締めくくりたいと思います。
参考