
はじめに
先日、以下の記事を読ませていただきました。
AutoMLって、こんなにあるんですね・・・。
早速、実行したことのなかったAutoMLのひとつ、H2O を試してみることにしました。
H2O は、”ソースコードを1行も書くことなくGUIのみですべての機械学習フローを実現” ってのが王道の利用スタイルようですが、本記事では、GUIを利用せず、Pythonで実装します。
いくつかのデータセット(分類や回帰)を読み込めるようにセットし、読込んだデータを訓練データとテストデータに分割してH2O に与えます。
その後、H2O を実行し、モデル学習やモデル評価を行います。
実行はノーコードです。いくつかの設定をドロップダウンとスライドバーで指定するだけです。
実行条件など
-Google colabで実行
-任意のデータセットとsklearn等のデータセットを読み出せるようにしています。
実行
1.読み込むデータセットとデータセットのタイプを設定します

2.データを読み込みます。
以下は、BostonHousingデータセット(回帰)を読み込んだ際の表示です
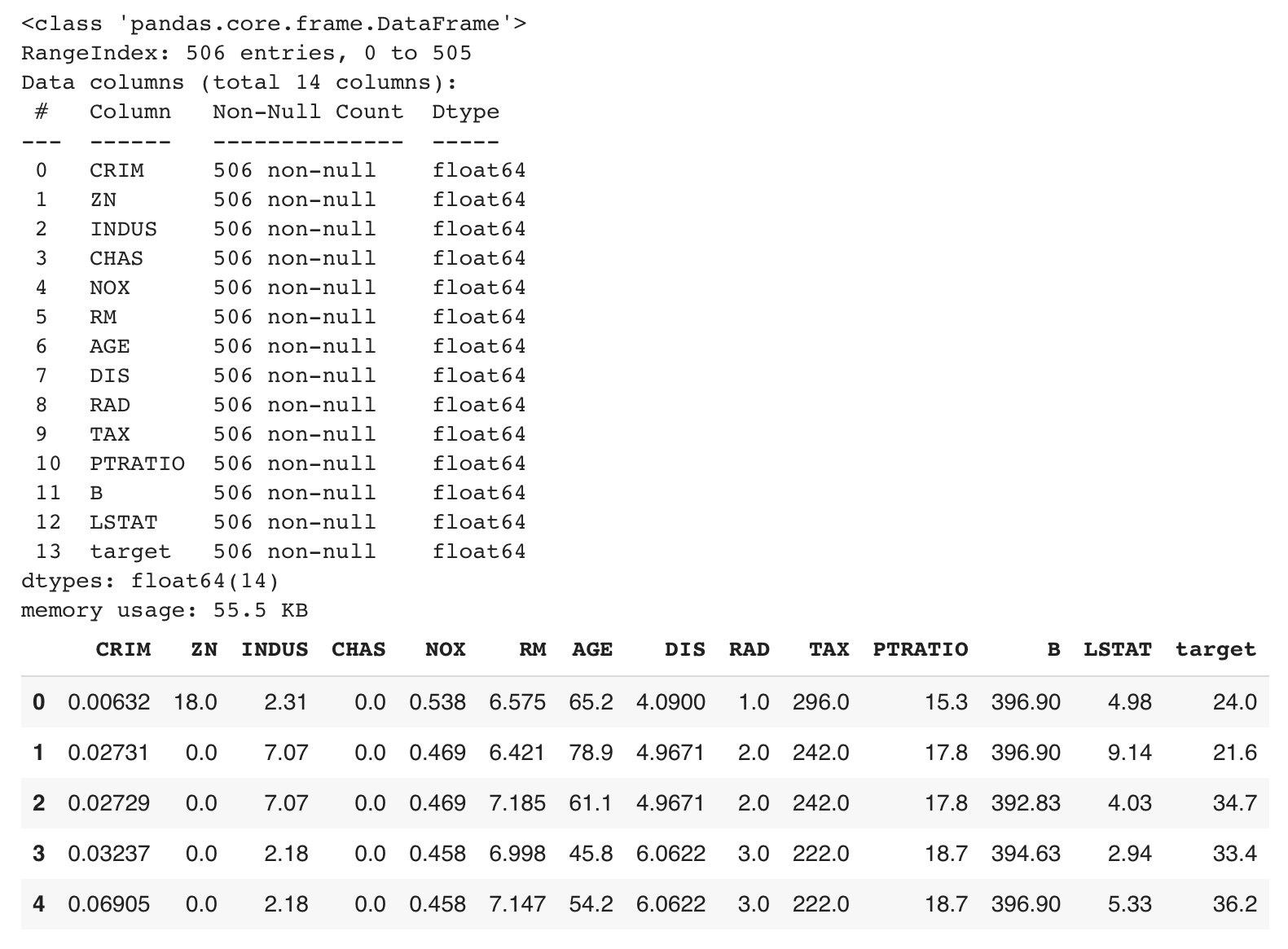
3.データクリーニングを実行します。
実装しているのは必要最小限のクリーニング項目だけです。
実装しているクリーニング項目は以下です
1.記号識別され欠損データをN.A.(NaN)に置換、2.不要なデータ項目の削除、3.欠損データを含む行を削除、4.カテゴリーデータ項目を Labelエンコード、5.すべての Obeject_col を Label encord、6.データ項目名を英訳
BostonHousingデータセットは、データ型がすべて数値(float64)で欠損値のない完全データなので、このデータクリーニングはスルーしています。
4.H2O
H2Oは、最初にイニシャライズが必要なので、実行します。
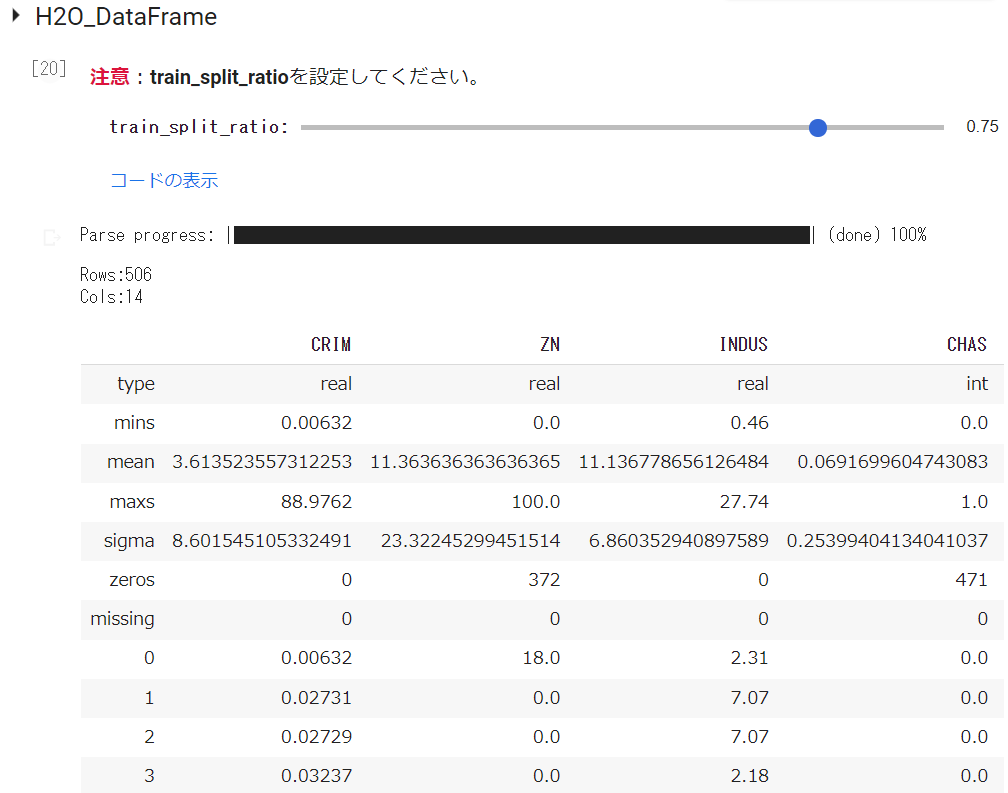
H2Oで処理するために、H2Oデータフレームに変換します。train_split_ratio(訓練データの比率)を設定し、実行するとH2Oデータフレームが表示されます。
Trainingを実行します。

実行すると、以下が示されます。
表示内容
>AutoML progress: |███████████████████████████████████████████████████████████████| (done) 100% Model Details ============= H2OStackedEnsembleEstimator : Stacked Ensemble Model Key: StackedEnsemble_BestOfFamily_4_AutoML_2_20221225_74455No summary for this model
ModelMetricsRegressionGLM: stackedensemble
** Reported on train data. **
MSE: 1.2033542239964747
RMSE: 1.0969750334426371
MAE: 0.7248377105045788
RMSLE: 0.04903287160581124
Mean Residual Deviance: 1.2033542239964747
R^2: 0.9856772778629282
Null degrees of freedom: 373
Residual degrees of freedom: 368
Null deviance: 31422.412266856
Residual deviance: 450.0544797746815
AIC: 1144.5982265633606
ModelMetricsRegressionGLM: stackedensemble
** Reported on cross-validation data. **
MSE: 11.382588671550861
RMSE: 3.373809222755617
MAE: 2.160857479133631
RMSLE: 0.14746778786336395
Mean Residual Deviance: 11.382588671550861
R^2: 0.8645206444684589
Null degrees of freedom: 373
Residual degrees of freedom: 369
Null deviance: 31469.16360095648
Residual deviance: 4257.088163160022
AIC: 1982.965767344206
Cross-Validation Metrics Summary:
mean sd cv_1_valid cv_2_valid cv_3_valid cv_4_valid cv_5_valid
mae 2.1570756 0.4769298 1.9393156 1.9640434 2.677928 1.5786797 2.6254113
mean_residual_deviance 11.360058 6.686784 7.374437 7.3213882 16.747698 5.1234636 20.233305
mse 11.360058 6.686784 7.374437 7.3213882 16.747698 5.1234636 20.233305
null_deviance 6293.8325 1444.3823 6872.6626 5281.382 8460.451 4799.2476 6055.4204
r2 0.8660946 0.0751128 0.9213642 0.8813892 0.8594477 0.9268509 0.7414208
residual_deviance 851.21967 504.17453 538.33386 622.318 1189.0865 348.39554 1557.9645
rmse 3.2550888 0.9775317 2.7155914 2.7058065 4.0923953 2.263507 4.4981446
rmsle 0.1449319 0.0264333 0.1260611 0.1501697 0.1711478 0.1099622 0.1673188
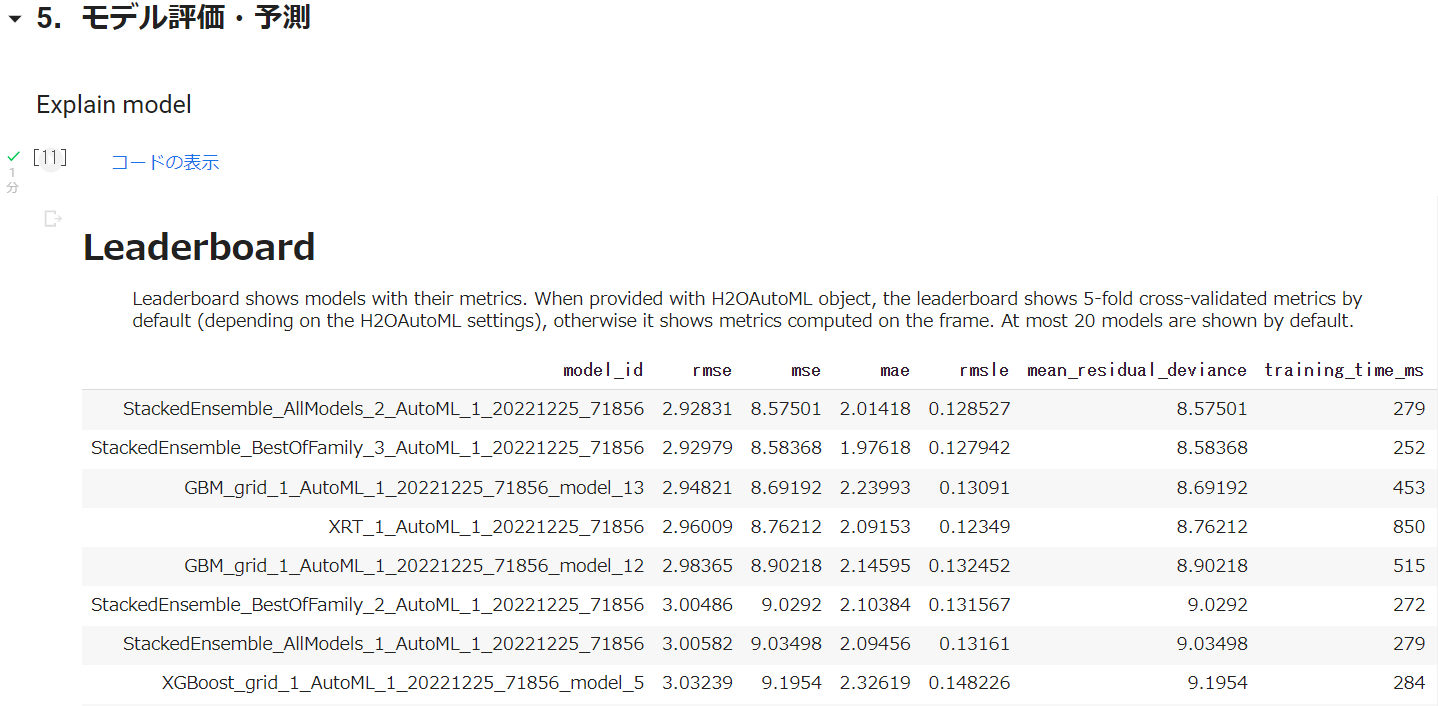
5.モデル評価・予測
Explain modelを実行します。これはモデル説明です。かなり充実しています。
Leaderboard
これは、モデル比較結果のサマリーです。
Residual Analysis
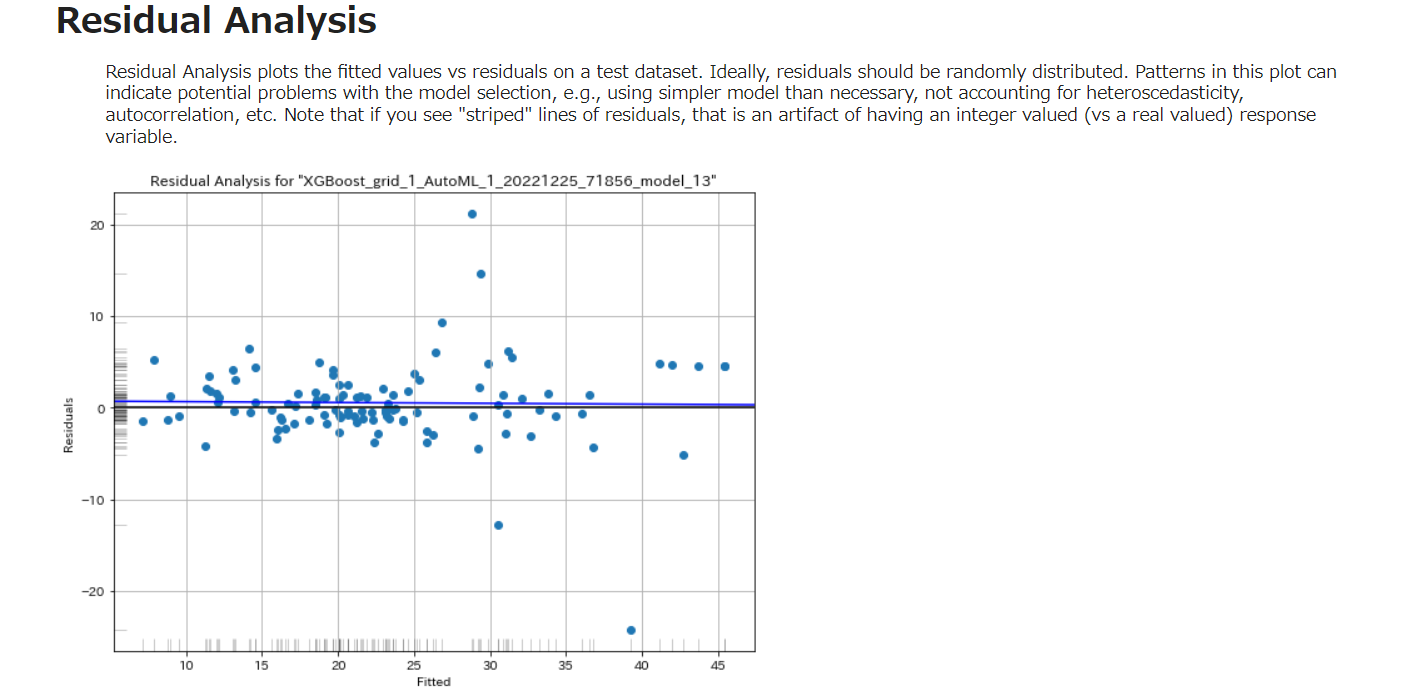
残差解析は、テストデータセットのフィット値対残差をプロットします。理想的には、残差はランダムに分布しているべきです。このプロットのパターンは、モデル選択における潜在的な問題、たとえば、必要以上に単純なモデルを使用している、異分散性、自己相関を考慮していない、などを示すことがあります。残差の「縞模様」の線が見える場合、それは整数値の応答変数(実数値に対して)のアーチファクトであることに注意してください。
Vriable Importance
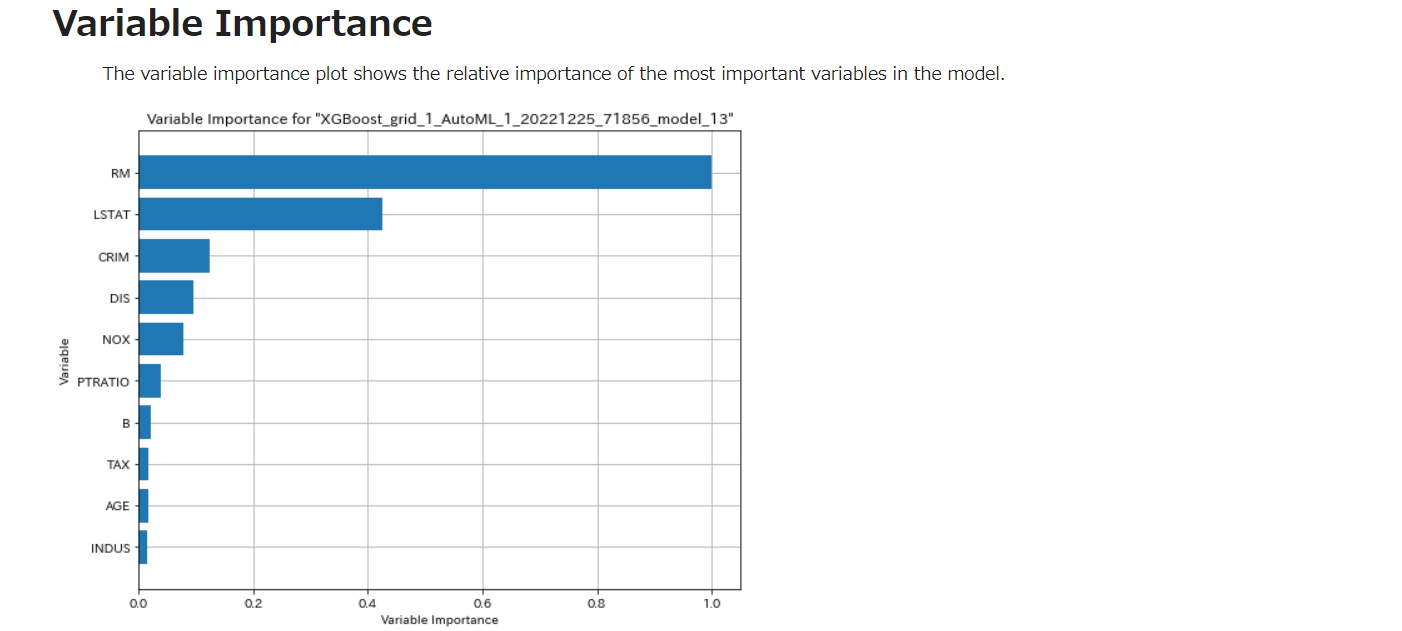
変数重要度プロットは、モデル中の最も重要な変数の相対的重要度を示す。
Variable Importance Heatmap
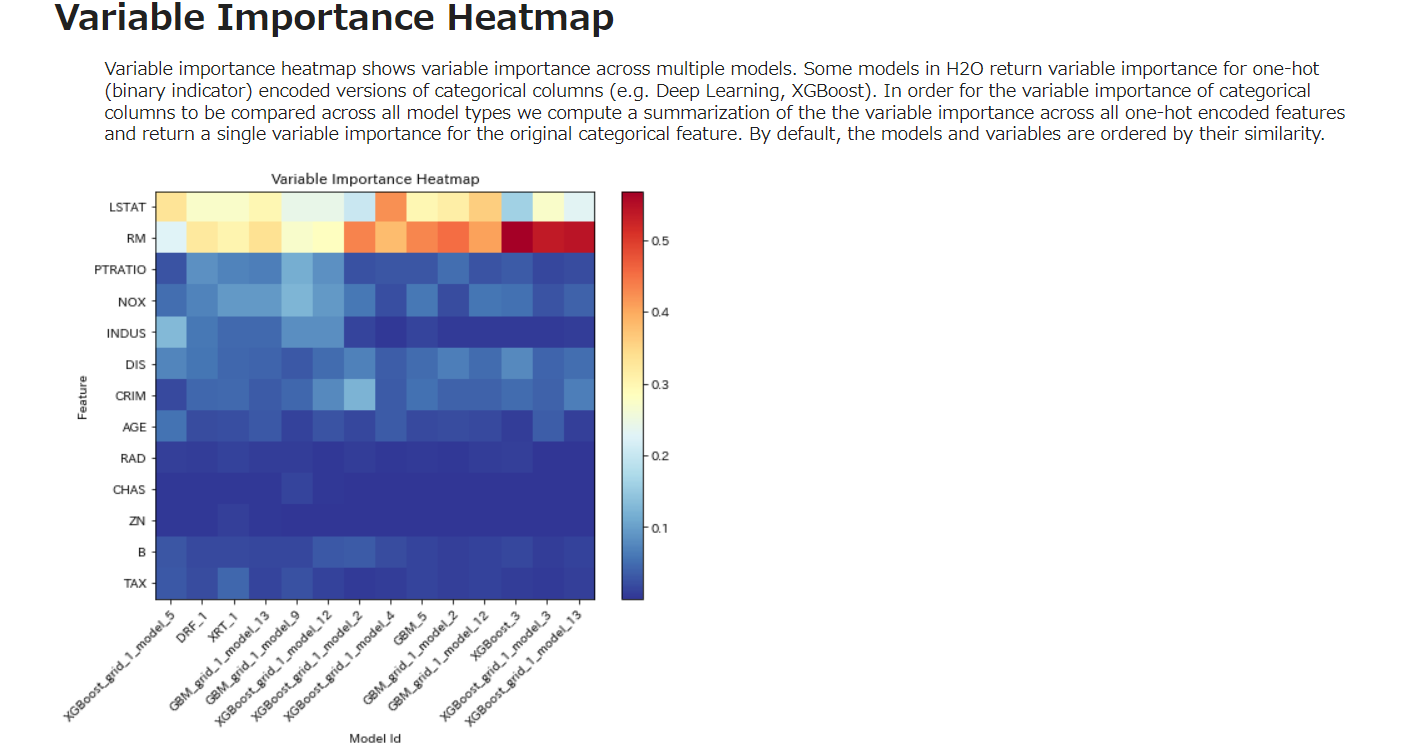
変数重要度ヒートマップは、複数のモデルにわたる変数重要度を示す。H2Oの一部のモデルは、カテゴリカルカラムのワンショット(バイナリ指標)エンコード版の変数重要度を返す(例:Deep Learning、XGBoost)。カテゴリカラムの変数重要度を全てのモデルタイプで比較するために、我々は全てのワンホットエンコードされた特徴量の変数重要度の要約を計算し、オリジナルのカテゴリ特徴量に対する単一の変数重要度を返す。デフォルトでは、モデルと変数はその類似性によって並べられる。
Model Correlation
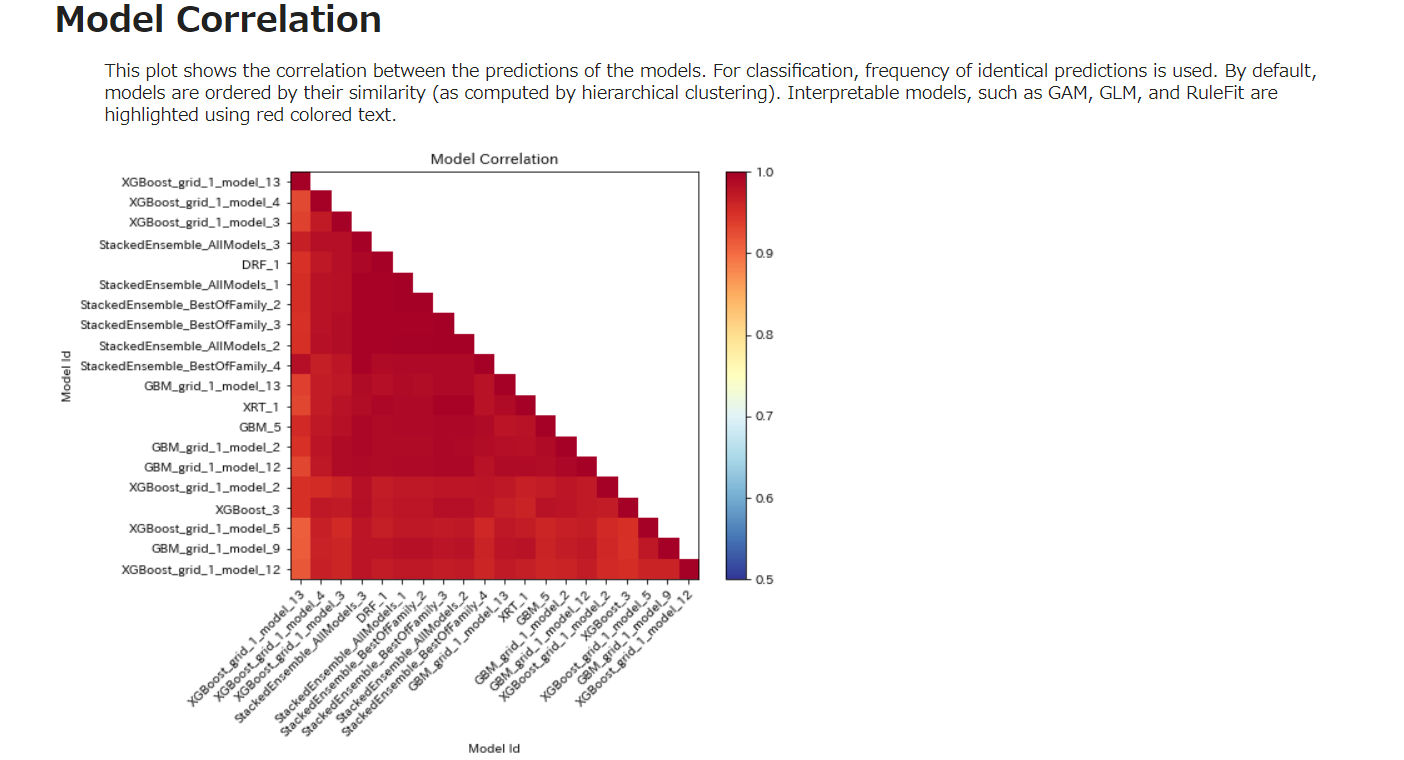
このプロットは、モデルの予測値間の相関を示す。分類には、同一の予測値の頻度が使用される。デフォルトでは、モデルはその類似性(階層的クラスタリングによって計算される)により並べられます。GAM、GLM、RuleFitのような解釈可能なモデルは、赤色のテキストでハイライトされています。
SHAP
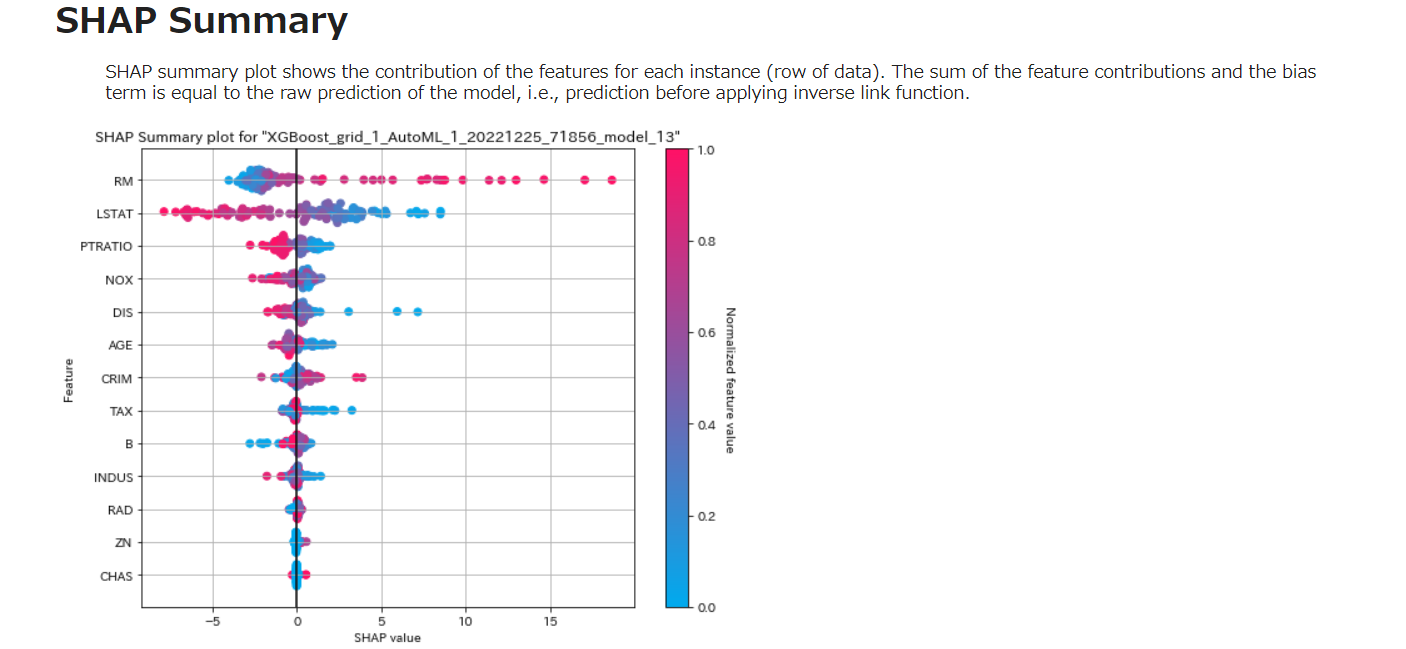
SHAPサマリープロットは、各インスタンス(データの行)に対する特徴の寄与を示す。特徴量の寄与とバイアス項の和は、モデルの生の予測値、すなわち逆リンク関数を適用する前の予測値と等しくなる。
Partial Dependence Plots
以下は表示されるひとつのデータ項目のみのキャプチャです。
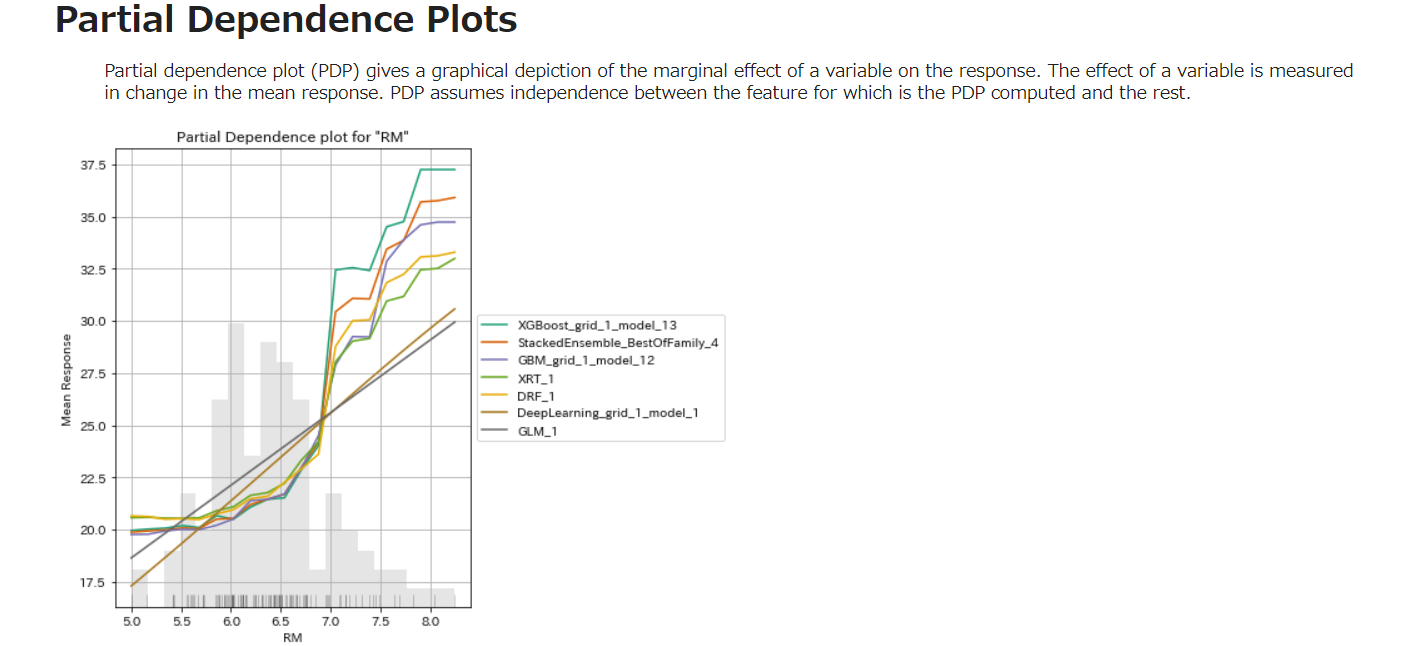
PDPは、応答での変数の限界効果のグラフィカルな描写を与える。変数の効果は、平均応答における変化で測定されます。PDPは、PDPが計算された特徴とそれ以外の特徴との間の独立性を仮定します。
Individual Conditional Expectation
以下は表示されるひとつのデータ項目のみのキャプチャです。
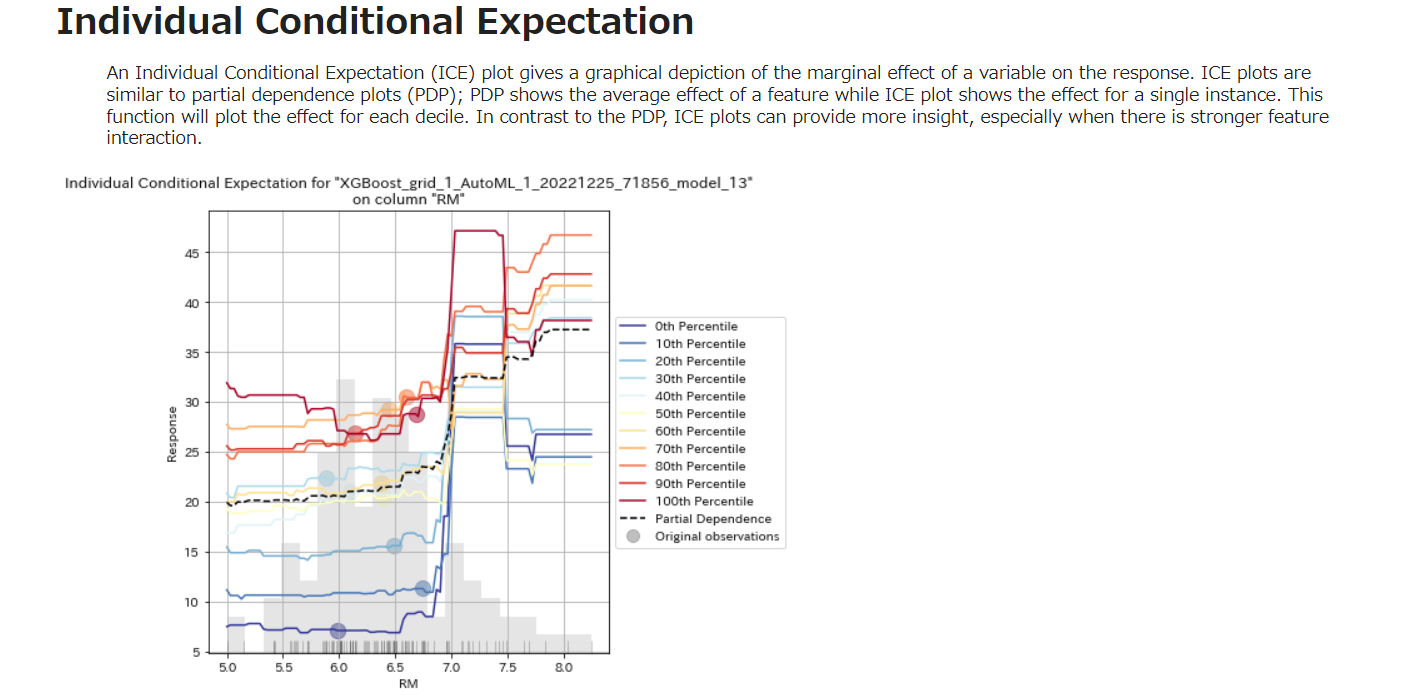
Individual Conditional Expectation (ICE) プロットは,応答での変数の限界効果のグラフィカルな描写を与える.ICE プロットは,部分依存プロット (PDP) に似ている.PDP が特徴の平均効果を示すのに対して,ICE プロットは単一インスタンスでの効果を示す.この関数は,各十分位について効果をプロットする.PDPとは対照的に、ICEプロットは、特に強い特徴の相互作用がある場合、より多くの洞察を与えることができます。
Best model & performance を実行します。

(中略)
以下は、テストデータのパフォーマンスです。

モデル評価を実行します。
これはsklearnで実行しています。
分類データで実行した場合は、以下のように混同行列とClassificationReportを表示します。
これは、datasetでTitanic(seaborn):binary を選択して実行した結果です。このデータには文字列や欠損値が混在しています。あらかじめ実装した前処理(データクリーニング)は実行せず、すべてH2Oに任せています。
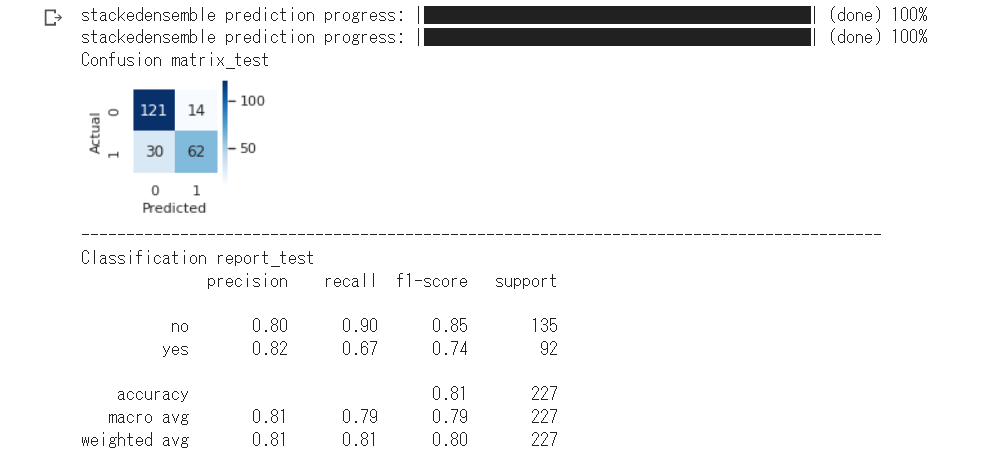
testデータ予測 を実行します。

最後に
この記事では、Boston(回帰データ)とTitanic(分類データ)でH2Oを実行しました。
ほぼ完全にH2Oまかせです。あらかじめいくつかの前処理も準備しましたが、不要でした。^_^;
前回までに同じデータでTPOT、AutoGloun、AutoViMLを適用しました。
H2Oは、モデル説明に関する視覚化がとても充実しています。
スコアも他のAutoMLと比較し、遜色ありませんでした。
H2Oは、独自のデータフレームに変換した後、各種処理を行いますので、Pandasベースでグラフ化など実行したいという場合は、H2OデータフレームをPandasデータフレームに変換する必要があります。
注意
以下のコードで実行できるのは、2値分類データと回帰データのみです。
selectdatasetの iris(マルチ)は実行できません。
実行コード
ライブラリのインストール
! apt-get install default-jre
!java -version
! pip install h2o
!pip install googletrans==4.0.0-rc1 --quiet
#matplotlib日本語化
!pip install japanize-matplotlib
import japanize_matplotlib
データセット読込み
データセットとデータセットタイプ(分類か回帰)選択のフォームセット
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset_type = 'Regression' #@param ["Classification", "Regression"]
dataset = 'Boston_housing :regression' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Titanic(seaborn) :binary', 'Iris :classification', 'Loan_prediction :binary','wine :classification', 'Occupancy_detection :binary', 'Upload']
データセット読み込み→データセットのインフォと先頭5行表示
#@title Load dataset
#ライブラリインポート
import numpy as np
import pandas as pd #データを効率的に扱うライブラリ
import seaborn as sns #視覚化ライブラリ
import warnings #警告を表示させないライブラリ
warnings.simplefilter('ignore')
'''
dataset(ドロップダウンメニュー)で選択したデータセットを読込み、データフレーム(df)に格納。
目的変数は、データフレームの最終列とし、FEATURES、TARGET、X、yを指定した後、データフレーム
に関する情報と先頭5列を表示。
任意のcsvデータを読込む場合は、datasetで'Upload'を選択。
'''
#任意のcsvデータ読込み及びデータフレーム格納、
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
#Diabetes データセットの読込み及びデータフレーム格納、
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns = diabetes.feature_names)
df['target'] = diabetes.target
#Breast_cancer データセットの読込み及びデータフレーム格納、
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
df = pd.DataFrame(breast_cancer.data, columns = breast_cancer.feature_names)
#df['target'] = breast_cancer.target #目的変数をカテゴリー数値とする時
df['target'] = breast_cancer.target_names[breast_cancer.target]
#Titanic データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
#目的変数 Survived をデータフレーム最終列に移動
X = df.drop(['Survived'], axis=1)
y = df['Survived']
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#Titanic(seaborn) データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic(seaborn) :binary":
df = sns.load_dataset('titanic')
#重複データをカットし、目的変数 alive をデータフレーム最終列に移動
X = df.drop(['survived','pclass','embarked','who','adult_male','alive'], axis=1)
y = df['alive'] #目的変数データ
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#iris データセットの読込み及びデータフレーム格納、
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
#df['target'] = iris.target #目的変数をカテゴリー数値とする時
df['target'] = iris.target_names[iris.target]
#wine データセットの読込み及びデータフレーム格納、
elif dataset == "wine :classification":
from sklearn.datasets import load_wine
wine = load_wine()
df = pd.DataFrame(wine.data, columns = wine.feature_names)
#df['target'] = wine.target #目的変数をカテゴリー数値とする時
df['target'] = wine.target_names[wine.target]
#Loan_prediction データセットの読込み及びデータフレーム格納、
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
#Occupancy_detection データセットの読込み及びデータフレーム格納、
elif dataset =='Occupancy_detection :binary':
data_url = 'https://raw.githubusercontent.com/hima2b4/Auto_Profiling/main/Occupancy-detection-datatest.csv'
df = pd.read_csv(data_url)
df['date'] = pd.to_datetime(df['date']) #[date]のデータ型をdatetime型に変更
#Boston データセットの読込み及びデータフレーム格納
else:
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns = boston.feature_names)
df['target'] = boston.target
#データフレーム表示
df.info(verbose=True) #データフレーム情報表示(verbose=Trueで表示数制限カット)
df.head() #データフレーム先頭5行表示
データクリーニング
H2Oは、前処理も実行してくれますので、必要になるのは「データ項目の削除」くらいかと思います。
不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@title 不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@markdown **<font color= "Crimson">注意</font>:Drop_label_is(カラムを指定して削除)の記載は <u> ' ID ' , ' Age ' </u> などとしてください。**</font>
Drop_label_is = 'sibsp', 'parch'#@param {type:"raw"}
try:
if Drop_label_is is not "":
Drop_label_is = pd.Series(Drop_label_is)
print('-----------------------------------------------------------------------------------------')
print("Drop of specified column:", Drop_label_is.values)
df.drop(columns=list(Drop_label_is),axis=1,inplace=True)
else:
print('※削除カラムの指定なし→処理スキップ')
except:
print("※正常に処理されませんでした。入力に誤りがないか確認してください。")
#データの7割以上が欠損値のカラムを削除(☑ =実行)
Over_70percent_missing_value_is_drop = True #@param {type:"boolean"}
#各列ごとに、7割欠損がある列を削除
if Over_70percent_missing_value_is_drop == True:
for col in df.columns:
nans = df[col].isnull().sum() # nanになっている行数をカウント
# nan行数を全行数で割り、7割欠損している列をDrop
if nans / len(df) > 0.7:
# 7割欠損列を削除
print('-----------------------------------------------------------------------------------------')
print("Drop of missing 70% column:", col)
df.drop(col, axis=1, inplace=True)
print('-----------------------------------------------------------------------------------------')
df.head()
欠損データを含む行を削除(☑ =実行)
#@title 欠損データを含む行を削除(☑ =実行)
Null_Drop = True #@param {type:"boolean"}
if Null_Drop == True:
df = df.dropna(how='any')
df.head()
カテゴリーデータ項目を Labelエンコード(対象:Dtype が int64, float64 以外のデータ項目)
#@title カテゴリーデータ項目を Labelエンコード(**対象:Dtype が int64, float64 以外のデータ項目**)
#@markdown **<font color= "Crimson">注意</font>:指定は <u> ' ID ' , ' Age ' , </u> などとしてください。**
Object_label_to_encode_is = '', '', '' #@param {type:"raw"}
Object_label_to_encode_is = pd.Series(Object_label_to_encode_is)
from sklearn.preprocessing import LabelEncoder
encoders = dict()
try:
for i in Object_label_to_encode_is:
if Object_label_to_encode_is is not "":
series = df[i]
le = LabelEncoder()
df[i] = pd.Series(
le.fit_transform(series[series.notnull()]),
index=series[series.notnull()].index
)
encoders[i] = le
print('-----------------------------------------------------------------------------------------')
print('[エンコードカラム]:',i)
le_name_mapping = dict(zip(le.classes_, le.transform(le.classes_)))
print(le_name_mapping)
else:
print('skip')
except:
print("※正常に処理されなかった場合は入力に誤りがないか確認してください。")
print('-----------------------------------------------------------------------------------------')
df.head()
すべての Obeject_col を Label encord(☑ =実行)
#@title すべての Obeject_col を Label encord(☑ =実行)
Encord_all_object_label = True #@param {type:"boolean"}
from sklearn.preprocessing import LabelEncoder
if Encord_all_object_label == True:
le = LabelEncoder()
for col in df.columns:
if df[col].dtype == 'object':
df[col] = le.fit_transform(df[col].astype(str))
print('-----------------------------------------------------------------------------------------')
print(col)
print(le.classes_, "= [0, 1, 2...]" )
# else:
# print(col,':エンコードしない→処理スキップ')
print('-----------------------------------------------------------------------------------------')
df.head()
データ項目名を英訳(☑ =実行)
#@title データ項目名を英訳(☑ =実行)
Column_English_translation = False #@param {type:"boolean"}
from googletrans import Translator
if Column_English_translation == True:
eng_columns = {}
columns = df.columns
translator = Translator()
for column in columns:
eng_column = translator.translate(column).text
eng_column = eng_column.replace(' ', '_')
eng_columns[column] = eng_column
df.rename(columns=eng_columns, inplace=True)
print('-----------------------------------------------------------------------------------------')
print('[カラム名_翻訳結果(翻訳しない場合も表示)]')
print('-----------------------------------------------------------------------------------------')
df.head(0)
H2O
H2O_initialize
#@title H2O_initialize
import h2o
from h2o.automl import H2OAutoML
h2o.init()
H2O_DataFrame
#@title H2O_DataFrame
#@markdown **<font color= "Crimson">注意</font>**:**train_split_ratio**を設定してください。</font>
train_split_ratio = 0.75 #@param {type:"slider", min:0.1, max:0.9, step:0.05}
# Load data into H2O
df = h2o.H2OFrame(df)
#FEATURES、TARGET、X、yを指定
FEATURES = df.columns[:-1] #説明変数のデータ項目を指定
TARGET = df.columns[-1] #目的変数のデータ項目を指定
#X = df.loc[:, FEATURES] #FEATURESのすべてのデータをXに格納
#y = df.loc[:, TARGET] #TARGETのすべてのデータをyに格納
y = TARGET
x = df.columns
x.remove(y)
train, test = df.split_frame(ratios=[train_split_ratio], seed = 1)
df.describe()
H2O_Training
#@title Training
if dataset_type =='Classification':
aml = H2OAutoML(max_models = 10, balance_classes=True, seed = 1)
else:
aml = H2OAutoML(max_runtime_secs =120,
max_models =None,
stopping_metric ='rmse',
sort_metric ='rmse',
seed =1)
aml.train(x = x, y = y, training_frame = train)
Explain model
#@title Explain model
explain_model = aml.explain(frame = test, figsize = (8,6))
Best model & Best performance
#@title Best model & Best performance
best_model = aml.get_best_model()
print(best_model)
#best model performance
best_model.model_performance(test)
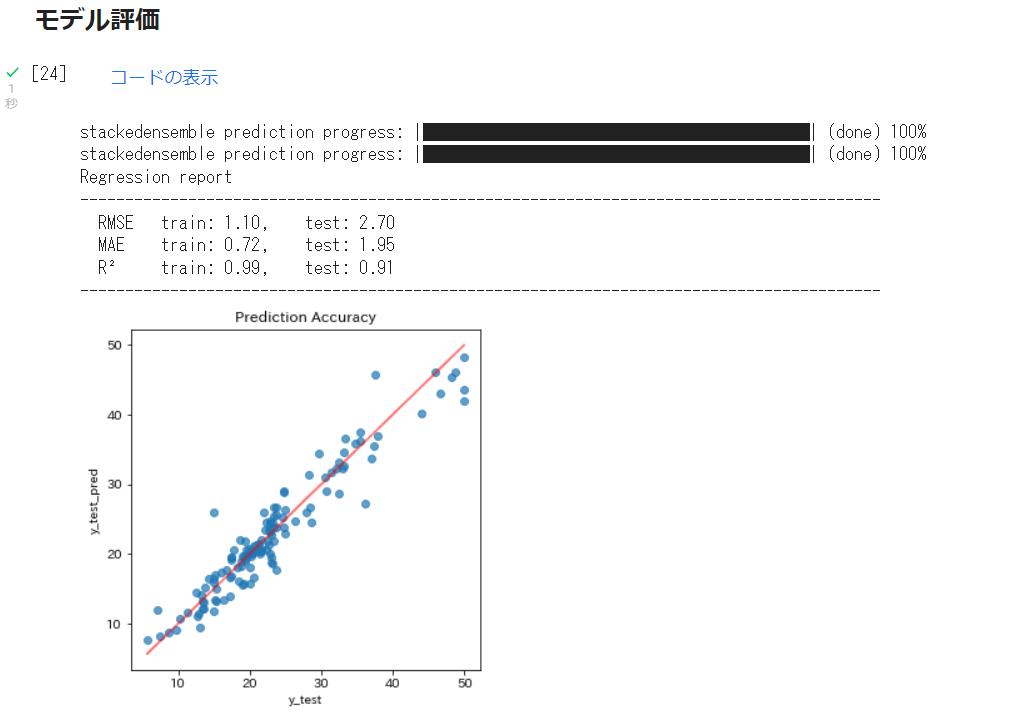
モデル評価
#@title **モデル評価**
#指標関連ライブラリインストール
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import f1_score #F1スコア
from sklearn.metrics import confusion_matrix #混同行列
from sklearn.metrics import classification_report #classification report
import matplotlib.pyplot as plt #視覚化ライブラリ
#データ予測
y_test_pred = aml.predict(test)
y_train_pred = aml.predict(train)
#H2Oデータフレーム→pandasデータフレーム
y_test_pred_ = h2o.as_list(y_test_pred[0])
y_train_pred_ = h2o.as_list(y_train_pred[0])
y_test = h2o.as_list(test[-1])
y_train = h2o.as_list(train[-1])
#モデル評価結果の表示
if dataset_type == 'Classification':
print('Confusion matrix_test')
#混同行列
sns.set(rc = {'figure.figsize':(1.5,1.5)})
sns.heatmap(confusion_matrix(y_test,y_test_pred_),
square=True, cbar=True, annot=True, cmap='Blues',fmt='g')
plt.xlabel('Predicted', fontsize=11)
plt.ylabel('Actual', fontsize=11)
plt.show()
print('-----------------------------------------------------------------------------------------')
print('Classification report_test')
print(classification_report(y_true=y_test, y_pred=y_test_pred_))
else:
print('Regression report')
print('-----------------------------------------------------------------------------------------')
print(' RMSE\t train: %.2f,\t test: %.2f' % (
mean_squared_error(y_train, y_train_pred_, squared=False),
mean_squared_error(y_test, y_test_pred_, squared=False)))
print(' MAE\t train: %.2f,\t test: %.2f' % (
mean_absolute_error(y_train, y_train_pred_),
mean_absolute_error(y_test, y_test_pred_)))
print(' R²\t train: %.2f,\t test: %.2f' % (
r2_score(y_train, y_train_pred_), # 学習
r2_score(y_test, y_test_pred_) # テスト
))
print('-----------------------------------------------------------------------------------------')
plt.figure(figsize = (5,5))
plt.title('Prediction Accuracy')
ax = plt.subplot(111)
ax.scatter(y_test, y_test_pred_,alpha=0.7)
ax.set_xlabel('y_test')
ax.set_ylabel('y_test_pred')
ax.plot(y_test,y_test,color='red',alpha =0.5)
plt.show()
#@title testデータ予測(☑ =csv保存実行)
csv_output = False #@param {type:"boolean"}
#y_pred = predictor.predict(X_test)
#result = pd.concat([y_test,y_test_pred],axis=1, keys=['true','pred'])
col_name = ['True','Pred']
result=pd.concat([y_test,y_test_pred],axis=1)
result.columns = col_name
#csv出力
if csv_output == True:
result.to_csv('pred_test_data.csv',encoding='utf_8_sig',index=False)
from google.colab import files
files.download('pred_test_data.csv')
result