前回の反省を生かして再度word_cloudに挑戦
前回は自分のツイートをword_cloudしたが、「する、てる」など意味を持たない単語が上位に抽出され特徴が見えにくかった。
(参考:前回記事 https://qiita.com/hikarumosity/items/d7aa7b5ec31912448dbe)
ツイート数が少ないことが原因と考え、3か月経ったところで再度同じ手法でword_cloudしたものを下記に示す。

改善は見られ、前回よりは具体的なワードが増えた。
-「シンガポール」の話をする傾向にある
- 笑を使用してシリアスな話もまるくツイートしたくなる傾向がある
- ツイッターを再開したのはここ半年であり80%ほどは大学生のころのツイートが占めている。そのため「がんばる」「飲む」など今あまりツイートしないワードが多い。
ただし
依然としてワードだけみても何の話題が多いかわからず、もしも上司に見せる機会があったとしたら「で、なに?」と言われそうな内容である。
単語を完全一致でツイート回数を数えるだけだと一致することが少ないので、このようにとっ散らかってしまう。
そこで傾向をとらえる手法としてまずは簡単にできるポジネガ分析を実施した。
ポジネガ分析に挑戦
今回は形態素解析をした後、各単語がポジティブ/ネガティブかを外部からのデータを用いて判定し、割合を求めたものである。
手法は下記サイトを参考にした。
(参考:https://qiita.com/uchim/items/db20d662d762efbfa9e5)
## Reading 単語感情極性表(Semantic Orientations of Words)
sowdic <- read.table("http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic", sep=":",
col.names=c("term","kana","pos","value"), colClasses=c("character","character","factor","numeric"),
fileEncoding="Shift_JIS")
# 名詞+品詞で複数の候補がある場合は平均値を採用します
sowdic2 <- aggregate(value ~ term + pos, sowdic, mean)
後に自分のツイートを取得し、inner_joinする。
# --------------------------
# Scrapig my timeline
# --------------------------
# Scraping my timeilne
# リツイートも含めて最新の2000ツイートを抽出
tweets <- userTimeline([アカウント], 2000, includeRts = T)
# list to dataframe
df <- twListToDF(tweets) %>% select(text, created)
# write.table for check frequency
write.table(df,"d.txt")
# Frequency
frq_Zimin <- RMeCabFreq("df.txt")
# wordcloud
frq_Zimin_exp <- frq_Zimin %>%
filter(Info1 %in% c("名詞","形容詞","動詞")) %>%
filter(Freq > 15) %>%
filter(!(Info2 %in% c("数", "サ変接続", "一般", "非自立"))) %>%
filter(!(Term %in% c("する", "いる", "ある", "てる")))
# ポジティブとネガティブの感情分析
frq_Zimin_posinega <- frq_Zimin %>%
rename(term = Term) %>%
inner_join(sowdic2, by = "term") %>%
#0以上をポジティブと定義
mutate(posi_nega = if_else(value > 0, "Posi", "Nega"))
# 円グラフ用に集計
posinega_sum <- frq_Zimin_posinega %>%
group_by(posi_nega) %>%
summarize(n())
# 円グラフを表示
pie(posinega_sum$`n()`, labels = posinega_sum$posi_nega, col = rainbow(2), clockwise = TRUE)
その結果が下記である。

これを見ると私はネガティブなことばかりつぶやいていると思ってしまうが、ポジティブ/ネガティブの判定に使用した単語感情極性表の中身を見てみる。
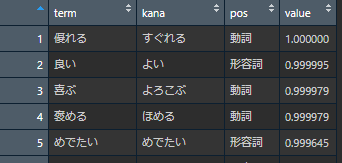
1に近い単語
-1に近い単語
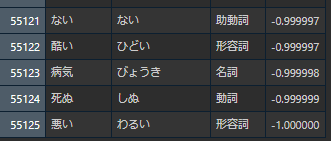
上記に挙げた単語を確認すると感覚と一致するが、一方で同じくマイナスの単語を見るとマイナスと判定されることは感覚と少し異なる。
0の近いマイナス
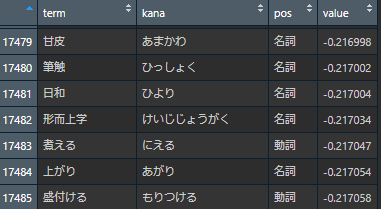
加えて単語感情極性表には55125個の単語が格納されているが、そのうち0を上回る単語は約5100個のみである。
結論
上記の通り円グラフをみて「ネガティブなワードが多いんだ。メンヘラかもしれない!」と結論付けるのはミスリード。
感覚のポジティブ/ネガティブに近づけるためには以下の工夫が必要と私は考える。
- ポジティブの判定を引き下げる(具体的なバーの選定は難しいが)
- ポジティブなワードの割合は1割が通常であるため、その傾向を織り込む
今回はここまで!