こんにちは。
タイトルの通り、現在趣味半分で個人開発中のきゅうり収穫支援システムについてつらつらと書いていきます。
(記念すべき初投稿記事です!)
1. プロローグ
私はきゅうり栽培を営む農家の両親を持つ一会社員なのですが、スマート農業で両親の仕事を助けられないかと考え、今回の個人開発を始めてみました。
将来的には近年の農業従事者数の減少と高齢化の問題解決に貢献できればいいなぁと漠然と考えています。
2. 開発前の調査
開発を始める前に、両親へのヒアリングをする中で、きゅうり収穫における以下のような課題感が掴めてきました。
①目視による等級判定の難しさ
一般的に収穫したきゅうりは農協へ出荷するのですが、その際にきゅうりの長さや重さ、形、色に応じて以下の例のように等級分けされ、単価も等級で変わってきます。
GitHub - workpiles/CUCUMBER-9
- 2L〜2S
良品。色艶がよく、比較的まっすぐで太さも偏っていないもの。大きさにより2Lから2Sまで5段階に選別される。- BL〜BS
B品。色合いが悪かったり、少し曲がっていたり太さが不均一なもの。大きさによりL〜Sまで3段階に選別される。- C
C品。形の悪いもの。

例えばA級品なら1本あたり50円、B級品なら30円といった具合で単価が変わるため、収益を最大化したければ極力A級品だけを収穫してB級品以下は後日の収穫のために取っておくのがベスト。
等級には明確な基準(◯グラム、△cm以上など)があるのですが、いちいち長さや重さを計りながら収穫してたら日が暮れてしまうので、勘と経験を頼りに目視で瞬時に収穫判定を行わなければなりません。
両親曰く、そこで問題となってくるのが新人教育とのこと。
私の両親はパートの方を数人雇っているのですが、人の入れ替わりがあるたびにこの等級判定を新人に一から教えなければならないのが中々大変らしい。
新人の教育時にはまず収穫の際に小さなはかりを持たせ、自分が収穫可能と思ったきゅうりを好きに茎からハサミでちぎってもらっています。
きゅうりをちぎる度にいちいち重さを量って自分の判断が間違っていなかったかどうかを「教師あり学習」させることで勘を養ってもらいます。
私自身も実際にこれを体験したことがあるのですが、1時間も続ければある程度コツを掴んでくるものの、ビニールハウス内の暑さもあって長時間続けると集中力と体力が低下し、ある種のゲシュタルト崩壊が起こって精度が落ちてきます。。
安定した精度で瞬時に収穫可能なきゅうりを見極めるのには熟練の経験と勘(と体力)が必要みたいです。
②収穫漏れが多い
トマトとかと違って、きゅうりは緑色だから葉っぱの色に完全同化しちゃって、収穫可能なきゅうりが目の前にあっても気づかずスルーしちゃうことが熟練者でもザラらしい。(特に老眼になると見落としやすくなる?)
だから一通り自分が担当の収穫エリアでちぎり終わったら「見直し」をしないといけなくて、ここで案外見落としが多いことに気づいて再度そのエリアで収穫することになり、二度手間が発生してしまう。
③農場にネット環境がない
上記の課題を、AIやロボットなどを駆使したいわゆる「スマート農業」で解決できないかと考えたのですが、特に地方の農場にはインターネット環境がないことがほとんどで、両親のハウスにもWi-fi環境がありませんでした。
という訳で、今回開発するものはインターネット接続不要で使えるもの目指しました。
これは今流行りのエッジAIでなんとかなりそうです。
3. ターゲット
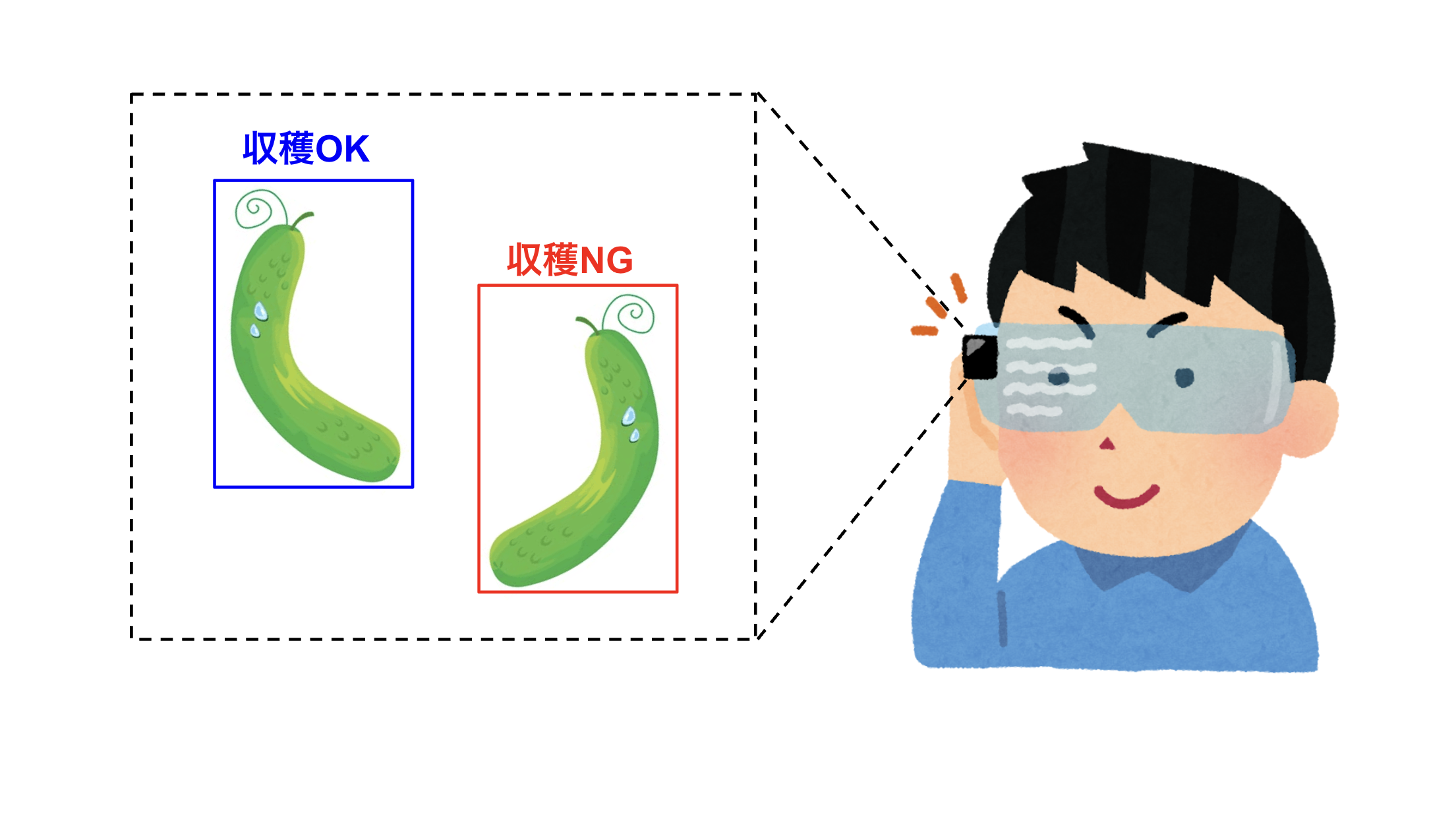
以上の課題を解決するために、本開発ではインターネット接続不要で使用できるAIチップ搭載のARグラスを通じたきゅうり収穫支援を最終的には目指しています。
製品イメージとしては、収穫可能なきゅうりがどこにあるのかをネット接続不要でリアルタイムに教えてくれるスマートグラスを考えており、お年寄りの農家さんでも電源をつけるだけで手軽に使えるものを作りたいです。
これを実現するための第一歩として、昨年発売されたRaspberry Pi AI Kitを用いた収穫判定AIの実装を今回行い、とりあえず動くプロトタイプを作るところまで進めてみました。
今回作ったAIは以下の2種類です。
- 1.カメラに映った映像からきゅうりを検出するAI
- 2.カメラに映った映像からきゅうりを検出し、そのきゅうりが収穫可能かどうかを判定するAI
AIに学習させるのは熟練者(今回は私の母)の経験と勘です。
4. 大まかな開発フロー
1. 実家のビニールハウスで母親の耳にウェアラブルカメラを取り付け、収穫時の手元を撮影・録画して学習データ収集
2. Labelimgでアノテーション
3. Google Colabで物体検出モデルYOLOv8を学習させる
4. AIチップへ学習済みモデルを移植し、どこでも動作可能なポータブルエッジAIシステム構築
5. 実際にビニールハウスで使用してみて動作確認
5.使用するもの
- Raspberry Pi 5 (RAM 8GB)
- Raspberry Pi 5用公式アクティブクーラー(ビニールハウスでの使用を想定しているので必須)
- Raspberry Pi AI HAT+ 26TOPS (AI Kit)
- モバイルバッテリーAnker 523 Power Bank(Powercore 10000) (ラズパイのポータブル化に使用、こちらの記事を参考に購入)
- ウェアラブルカメラ Ordro EP6 Plus 4K (学習用データ収集、リアルタイム推論の映像入力に使用)
- Freenove 7インチ タッチスクリーンモニター (移動しながら画面入出力するために使用)
- Google Colab Pro (モデルの学習と学習済みモデルをHailoで読み込み可能な形式に変換する作業に使用。無料版だとメモリ不足で先に進めなかったのでやむを得ず課金。)
- Google Drive (無料版の容量がすぐ埋まってしまったため課金)
- 六角オネジ・メネジ MB26-16.5×4(AI Kit付属のスペーサーはメネジ・メネジだったのでタッチスクリーンモニターへ固定する際に使用できなかった)
6. 学習データ取得・モデルの学習
母の耳にウェアラブルカメラを取り付け、1080p, 30fpsで録画開始。
そのまま30分ほど収穫してもらい、データ取得完了。
収穫判定の前に、まずはきゅうりを検出できるようになるかどうかを検証。
取得した映像フレームを間引いて5fpsに変換し、各フレーム画像に対してLabelimgでアノテーションを以下のように実行(Labelimgの使い方はこちらを参照)。

毎日100枚アノテーションしてGoogle Driveにアップし、Google ColabでYOLOv8を学習させました(YOLOv8の学習方法はこちらの記事を参照)。
毎日学習させると少しずつきゅうりを検出できるようになってきたので、終盤ではこの子にアノテーションを代行してもらいました。
以下のように学習済みの重みファイルlast.ptを読み込み、save_txt=Trueを指定して推論を実行すれば枠情報がテキストファイルに出力されるので、その結果をLabelimgで読み込んで枠の位置を調整。
from ultralytics import YOLO
model = YOLO('./runs/detect/train_result/weights/last.pt')
model("./predict",save=True, save_txt=True, conf=0.3, iou=0.5)
大まかではあるものの、枠を自動でつけてくれるだけで毎回イチからアノテーションするよりもずっと効率がよくなりました。
最終的に約千枚を学習させたのち、試しに未学習画像を推論させてみたところ、そこそこきゅうりを検出できるようになった模様。

続いて、本命の収穫判定ができるかどうか検証。
先ほどきゅうりの特徴を学習させたモデルを事前学習済みモデルとして、検出されたきゅうりが「収穫可能(harvestable)」か「収穫不可(unharvestable)」のどちらに属するのか2クラスに分類するようファインチューニングしました。
正直ここのアノテーションが一番苦行でした^^;
まずアノテーションは、母の収穫映像を観て実際に収穫されたきゅうりに"Harvestable"ラベルを、収穫されずにスルーされたラベルに"Unharvestable"ラベルを与えました。
実際にやってみると分かるのですが、これがなかなか難しいです。
例えばあるフレームに映るきゅうりaが収穫された場合、きゅうりaに対しては迷わず"Harvestable"ラベルを与えれば良いのですが、同一フレームに映ったきゅうりbがその時はスルーされたとしても、もし後々のフレームで収穫された場合はbに対しても"Harvestable"ラベルを与える必要があります。
簡単に聞こえるかもしれませんが、ちぎったきゅうりaを箱に並べる際にカメラの画角から一旦きゅうりbが消えてしまうため、再度画角内に映ったきゅうりがさっきまでみていたきゅうりbと同一なものかどうか、背景との位置関係から判定しなければなりませんでした。。
かなり根気が必要な作業でしたが、手作業で約二千枚ほどアノテーションしました。
いざ学習を実行してみたところ、そこそこうまくいってそうな感触。
という訳で、収穫判定AIのプロトタイプ第1号がとりあえずできました。

7. 学習済みモデルのhefフォーマットへの変換
学習させたモデルを、Raspberry Pi AI HAT+に乗っているAIチップHailo-8が読み込める形に変換しました。
ここもなかなかどうして長い道のりでした。
基本的にはこちらの動画を参考にしました。
ざっくりとした流れを先に説明すると、先ほど学習させた結果得られた重みファイルlast.ptをHailo Dataflow Compilerで.onnx->.har->.hefという拡張子のファイルに変換していきました。
まず動画で説明されている通り、学習させたYOLOv8の重みファイルlast.ptを以下のコードでONNXフォーマットに変換。
from ultralytics import YOLO
model = YOLO('./runs/detect/train_result/weights/last.pt')
model.export(format="onnx")
生成されたonnxファイルをHailoのコンパイラで変換していきます。
かなり重い処理で時間がかかるようなのでGPUマシン環境が推奨とのこと。
GPUマシンが手元にあれば公式推奨のDockerイメージで環境を作成すればよいのですが、自分の場合はGPUマシンがなかったので、Colab上に推奨環境をイチから構築することにしました。
具体的な構築環境は以下の通り。
- Ubuntu 22.04.4 LTS
- Python3.8 (ColabのデフォルトバージョンはPython3.11.11が入ってた)
- CUDA11.8 (デフォルトはCUDA12.5)
- cuDNN8.8.9
推奨バージョン以外だと色々エラーが出てきたので、以下のように既存のバージョンを削除したりインストールしなおしたりして無理くりバージョンを揃え、Python3.8の仮想環境を作成しました。
#Google Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive
# 既存のCUDAを削除
!sudo apt-get --purge remove "*cublas*" "*cufft*" "*curand*" "*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "cuda*" "nsight*" -y
!sudo apt-get --purge remove "*nvidia*" -y
!sudo apt-get autoremove -y
!sudo apt-get autoclean -y
!sudo rm -rf /usr/local/cuda*
#CUDA11.8をインストール
!wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
!sudo sh cuda_11.8.0_520.61.05_linux.run --silent --toolkit
#既存のcuDNNを削除
!sudo apt-get remove --purge --allow-change-held-packages libcudnn9-cuda-12 libcudnn9-dev-cuda-12
!apt-get remove --purge -y libcudnn*
!rm -rf /usr/local/cuda/include/cudnn*
!rm -rf /usr/include/cudnn*
#cuDNN8.9をインストール
!apt-get update
!apt-get install -y libcudnn8=8.9.0.*-1+cuda12.1
#Python3.8と関連ライブラリをインストール
!sudo apt-get install python3.8
!sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1
!sudo update-alternatives --config python3
!sudo apt install python3.8-dev
!sudo apt install python3.8-distutils
!sudo apt install python3-tk
!sudo apt install graphviz
!sudo apt install libgraphviz-dev
#Python3.8の仮想環境を作成
!sudo apt install python3.8-venv
!python3 -m venv hailo
!source hailo/bin/activate
#pipをインストール
!curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
!sudo python3 get-pip.py
なお、CPUメモリは16GB以上が推奨されてます。
実際自分も最初はColabの無料版を使用していたのですが、メモリが12GBしか使えず途中でメモリ不足になって先に進めず、やむを得ずColab Proに課金してハイメモリを使用できるようにしたことで先に進めました。
一通り環境ができたら、Hailo Developer ZoneのSoftware Downloadsから環境に合致するDataflow CompilerをダウンロードしてwhlファイルをGooble Driveにコピーし、以下のコマンドでインストールを実行。
!hailo/bin/pip install hailo_dataflow_compiler-3.30.0-py3-none-linux_x86_64.whl
続いてHailo Model Zooのリポジトリをクローンしてパッケージをインストール。
!git clone https://github.com/hailo-ai/hailo_model_zoo.git
%cd hailo_model_zoo
!../hailo/bin/pip install -e .
これで基本的にコンパイルできるようになるはずなのですが、自分の場合はSoftware DownloadsからHailoRTをインスールしないとhailomzコマンドが通りませんでした。
ダウンロードしたwhlファイルとdebファイルをGoogle Driveにコピーして以下のコマンドを実行。
!hailo/bin/pip install hailort-4.20.0-cp38-cp38-linux_x86_64.whl
!sudo dpkg -i hailort_4.20.0_amd64.deb
hailomzが通るようになったら引数を指定して以下を実行。
!hailo/bin/hailomz compile --ckpt ./ultralytics/runs/detect/train_result/weights/last.onnx --hw-arch hailo8 --calib-path ./ultralytics/datasets/cucumber_data/images/train --yaml ./hailo_model_zoo/hailo_model_zoo/cfg/networks/yolov8l.yaml --classes 2
- --hw-arch: 使用しているHailoチップの種類を指定(今回はHailo-8なのでhailo8と入力)
- --calib-path: キャリブレーションに用いるデータセット(今回は学習に用いたきゅうり画像データセットを指定)
- --yaml: 使用するモデルのyamlファイルを指定
- --classes: 分類クラス数(今回は"Harvestable"と"Unharvestable")
- --performance: つけると精度が向上する?らしいが今回はつけずに実行
上記を実行するとlibcublasLt.so.12がないと怒られたので、以下のようにシンボリックリンクを作成してCUDA11系のライブラリが使用されるようにしたところエラーが消えました。
!ln -s /usr/local/cuda-11.8/lib64/libcublasLt.so.11 /usr/local/cuda-11.8/lib64/libcublasLt.so.12
!ln -s /usr/local/cuda-11.8/lib64/libcublas.so.11 /usr/local/cuda-11.8/lib64/libcublas.so.12
しばらく待ってキャリブレーションのための学習が4エポック終わったところで、以下のように環境変数USERが設定されていないと怒られてしまいました。
Epoch 1/4
508/508 [==============================] - 894s 1s/step - total_distill_loss: 5.3461 - _distill_loss_yolov8l/conv97: 0.1406 - _distill_loss_yolov8l/conv82: 0.1911 - _distill_loss_yolov8l/conv67: 0.2067 - _distill_loss_yolov8l/conv25: 0.1467 - _distill_loss_yolov8l/conv100: 0.0351 - _distill_loss_yolov8l/conv88: 0.0924 - _distill_loss_yolov8l/conv73: 0.1236 - _distill_loss_yolov8l/conv103: 0.6931 - _distill_loss_yolov8l/conv89: 0.6931 - _distill_loss_yolov8l/conv74: 0.6931
Epoch 2/4
508/508 [==============================] - 588s 1s/step - total_distill_loss: 5.1056 - _distill_loss_yolov8l/conv97: 0.1196 - _distill_loss_yolov8l/conv82: 0.1682 - _distill_loss_yolov8l/conv67: 0.1330 - _distill_loss_yolov8l/conv25: 0.1284 - _distill_loss_yolov8l/conv100: 0.0307 - _distill_loss_yolov8l/conv88: 0.0776 - _distill_loss_yolov8l/conv73: 0.0906 - _distill_loss_yolov8l/conv103: 0.6931 - _distill_loss_yolov8l/conv89: 0.6931 - _distill_loss_yolov8l/conv74: 0.6930
Epoch 3/4
508/508 [==============================] - 582s 1s/step - total_distill_loss: 5.0115 - _distill_loss_yolov8l/conv97: 0.1087 - _distill_loss_yolov8l/conv82: 0.1583 - _distill_loss_yolov8l/conv67: 0.1180 - _distill_loss_yolov8l/conv25: 0.1196 - _distill_loss_yolov8l/conv100: 0.0264 - _distill_loss_yolov8l/conv88: 0.0681 - _distill_loss_yolov8l/conv73: 0.0796 - _distill_loss_yolov8l/conv103: 0.6931 - _distill_loss_yolov8l/conv89: 0.6931 - _distill_loss_yolov8l/conv74: 0.6930
Epoch 4/4
508/508 [==============================] - 580s 1s/step - total_distill_loss: 4.9491 - _distill_loss_yolov8l/conv97: 0.0997 - _distill_loss_yolov8l/conv82: 0.1529 - _distill_loss_yolov8l/conv67: 0.1115 - _distill_loss_yolov8l/conv25: 0.1144 - _distill_loss_yolov8l/conv100: 0.0227 - _distill_loss_yolov8l/conv88: 0.0600 - _distill_loss_yolov8l/conv73: 0.0733 - _distill_loss_yolov8l/conv103: 0.6931 - _distill_loss_yolov8l/conv89: 0.6931 - _distill_loss_yolov8l/conv74: 0.6930
[info] Model Optimization Algorithm Quantization-Aware Fine-Tuning is done (completion time is 00:44:13.07)
[info] Starting Layer Noise Analysis
Full Quant Analysis: 100% 8/8 [06:20<00:00, 47.60s/iterations]
[info] Model Optimization Algorithm Layer Noise Analysis is done (completion time is 00:06:28.27)
[info] Model Optimization is done
[info] Saved HAR to: /content/drive/MyDrive/yolov8l.har
[info] Loading model script commands to yolov8l from /content/drive/MyDrive/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov8l.alls
[error] KeyError: 'USER'
そこで以下のように環境変数USERを任意の値に設定するとエラーが消えました。
import os
os.environ['USER'] = 'colab_user'
そのあとは結構時間がかかりましたが、気長に待ち続けた結果yolov8l.hefが生成されていたので、早速これをエッジで動かしてみました。
8. いよいよエッジで動かす!
ここからは既にAI Kitのセットアップが完了してサンプルコードを動かせている前提で話を進めます。
AI Kitのセットアップからサンプルコードを動かすまでの手順は色々な記事があると思うのでそちらを参照してください(こちらの記事とか)。
まず、生成されたhefファイルをscpコマンドでラズパイに転送。
こちらのリポジトリをラズパイでクローンし、hailo-rpi5-examples/resources下にyolov8l.hefを置いてcucumber.hefのように好きな名前に変更。
同じディレクトリ内にbarcode-labels.jsonがサンプルとして入っているので、これをコピーしてcucumber-labels.jsonのように別名に変更。
このjsonファイルの中身は以下のように設定しました。
{
"detection_threshold": 0.3,
"iou_threshold": 0.5,
"max_boxes":200,
"labels": [
"Harvestable",
"Unharvestable"
]
}
これでソフト部分の設定は終わり。
続いて外装を整えました。
ラズパイをビニールハウス内に携帯し、収穫者の耳元に取り付けられたウェアラブルカメラから取り込まれた映像をリアルタイムでAI推論処理にかけてタッチパネルに結果を出力する想定で、以下の仕様を定めました。
- カメラ入力はラズパイとUSBケーブルで有線接続されたウェアラブルカメラで取り込む。無線接続も試したが、どうしても1秒程度の遅延が発生してしまうため今回は断念。
- ラズパイはモバイルバッテリーで給電することでポータブル化。
- 入出力を行えるよう、ラズパイ用のタッチパネルを使用。タッチパネル裏面にラズパイを固定できるのでスマートな外観を実現。ターミナルへのコマンド入力等は仮想キーボードでタッチ入力できるので、マウスやキーボードを持ち歩く必要はない。
外観的にはこんな感じで、かなりスマートにまとまりました。
(例として、妻のぬいぐるみ"あおこ"にカメラをつけてみました笑)

タッチパネルの裏面はこんな感じ。

仮想環境を起動したら、使用するhefファイルとjsonファイル、入力デバイスを以下のように指定してdetection.pyを実行。
python3 basic_pipelines/detection.py --hef-path resources/cucumber.hef --input /dev/video0 --labels-json resources/cucumber-label.json
現場での検証はまた後日するとして、ここでは簡単な検証としてPCに映したきゅうり画像をカメラ入力してみました。


精度はイマイチ感があるが、収穫可能なきゅうり(青枠)と不可なきゅうり(緑枠)をちゃんと識別できているっぽい。
フレームレートは15fps程度出ており、遅延も実用上ほとんど気にならないレベルだと思います。
9. 今後の課題
- ラズパイやHailo-8がハウス内の高熱に耐えられるのか?
- 学習データが少ないので天候による光のあたり方とかにも推論精度が左右されそう
- カメラ一つだと人間の視野を全てカバーできないので、将来的には複数カメラを使用したほうがいいかも
10. おわりに
今回はきゅうりの収穫判定AIを作ってAIチップに乗せるところまでの開発を進めてみました。
とりあえず動く試作機を作ってみたという感じなので、精度面では正直まだまだ粗いと思います。
結構無理やり感があるので、コードの間違い等あればご指摘いただけると助かります!
ビニールハウスでの本物のきゅうりを映した検証も実施予定なので、進捗があれば記事にて報告したいと思います。
うまくいけばスマートグラスに乗せて実用化するところまで到達できればいいなと思いますので、コメント等お待ちしてます!