概要
7stepにてyolov8にてオリジナルモデル学習及び使用する方法をメモした。
1.環境整備、download yolov8
2.download モデル
3.教師データの準備
4.教師データの読み込み先及びクラスの修正
5.クラス数の修正
6.学習
7.学習したモデルを使い画像にて検証
8.Webカメラを使いリアルタイムで検証
1.環境整備、download yolov8
環境:anaconda(Python>=3.8仮想環境yolov8などお好きな名前で作った上)下記コマンドを実行する。cuda環境使っている場合はpytorch cudaを別途入れておく必要がある。
※PyTorch>=1.8が必要。自分はCPUタイプをまず試してみた。
pip install ultralytics
今度、コード、必要なファイル一式をgithubからdownloadする
downloadした中身はいっぱいあるが、その中クラスの設定は(ultralytics-main\ultralytics\cfg\datasets)datesetsのフォルダに入っている。後ほど使う。
2.download モデル
モデルは5種類あるが、精度と速度が半比例している感じで、必要に応じて選べばよいが、ここではnを使ってみる。
Jupyterを使って、サンプルコードを試してみる。
結果は画像通り。テスト結果が同じ階層の下にdetectのフォルダが生成され、格納されている。
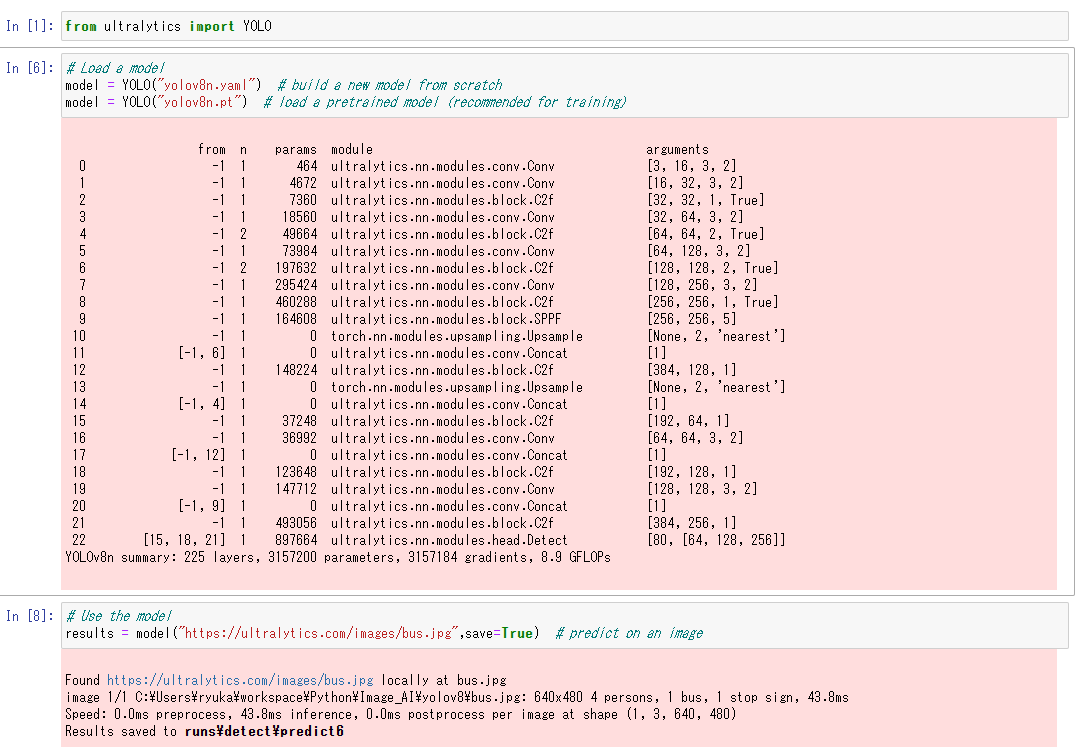
格納されているdetect結果
実際model=YOLO"yolov8n.pt"を実行している時点で同階層に6MBくらいのモデルがdownloadされている。手動でもできますが、githubから直接同階層にdownloadしてもよい。(なければ、downloadするようにコーディングされているようです)
3.教師データの準備
free ツールのlabelimgを使って、yoloのfomatで自分が作りたい教師データを準備する。
MYDATEの教師データフォルダを作り、画像とラベルを分けて、それぞれtrain用とval用のデーターを格納した。
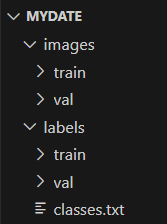
大体8:2の比例で学習させたいデーターを学習と検証データを分けて格納する。
この中classes.txtの中は使うClassesを入れている。ステップ4のところのクラスの定義と同じようにすればよい。
4.教師データの読み込み先及びクラスの修正
ultralytics-main\ultralytics\cfg\datasetsの中coco.yamlファイルを参考して自分の学習用ファイルを作成する。この中に教師データの格納先及びClassesの定義がされている。
# Ultralytics YOLO, AGPL-3.0 license
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /Users/ryuka/workspace/Python/Image_AI/yolov8/mydate # dataset root dir
train: images/train # train images (relative to 'path')
val: images/VAL # val images (relative to 'path')
#test: # test images (optional)
# Classes
names:
0: red_kaeru
1: bule_kaeru
2: black_man
3: white_man
5.クラスの修正
フォルダの(ultralytics-main\ultralytics\cfg\models\v8)の中yolov8.yamlファイルの中のクラス数を自分が用意したクラス数に変える。
# Parameters
#nc: 80 # number of classes
nc: 4 # number of classes
6.学習
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE' #エラー対策
from ultralytics import YOLO
# Create a new YOLO model from scratch
model = YOLO('/Users/ryuka/workspace/Python/Image_AI/yolov8/ultralytics-main/ultralytics/cfg/models/v8/myyolov8.yaml')
# Load a pretrained YOLO model (recommended for training)
model = YOLO('/Users/ryuka/workspace/Python/Image_AI/yolov8/myyolov8n.pt')
# Train the model using the 'coco128.yaml' dataset for 3 epochs
results = model.train(data='/Users/ryuka/workspace/Python/Image_AI/yolov8/ultralytics-main/ultralytics/cfg/datasets/mycoco.yaml', epochs=30,batch=4)
# Evaluate the model's performance on the validation set
results = model.val()
epochの回数を増やせばもうちょっと精度が上がると思うが、とりあえず学習はできた。確率はバラバラだが拾いたいものは全部拾えている感じ。
最後の学習終了時の結果:


7.学習したモデルを使い検証
最後、学習完了後、runs\detect\train\weightsが生成される(2回目以降の学習結果を上書きされないようにtrainのフォルダ名が数値追加される)。このフォルダの中にbest.ptとlast.ptが生成される。これは学習で得られたモデルになる。過学習になる可能性があるため、lastは=bestではない。ここでbestを使ってみる。
使う場合Step2のコードのショートカットを変えるだけよい。
from ultralytics import YOLO
# コンフィグは学習時と同じコンフィグでよい
model = YOLO("/Users/ryuka/workspace/Python/Image_AI/yolov8/ultralytics-main/ultralytics/cfg/models/v8/myyolov8.yaml") # build a new model from scratch
# bestのモデルを使う
model = YOLO("/Users/ryuka/workspace/Python/Image_AI/yolov8/runs/detect/train14/weights/best.pt") # load a pretrained model (recommended for training)
results = model("/Users/ryuka/workspace/Python/Image_AI/yolov8/test_img/20230206200553.jpg",save=True) # predict on an image
実行すると、検出結果はruns\detect\predictに格納された。

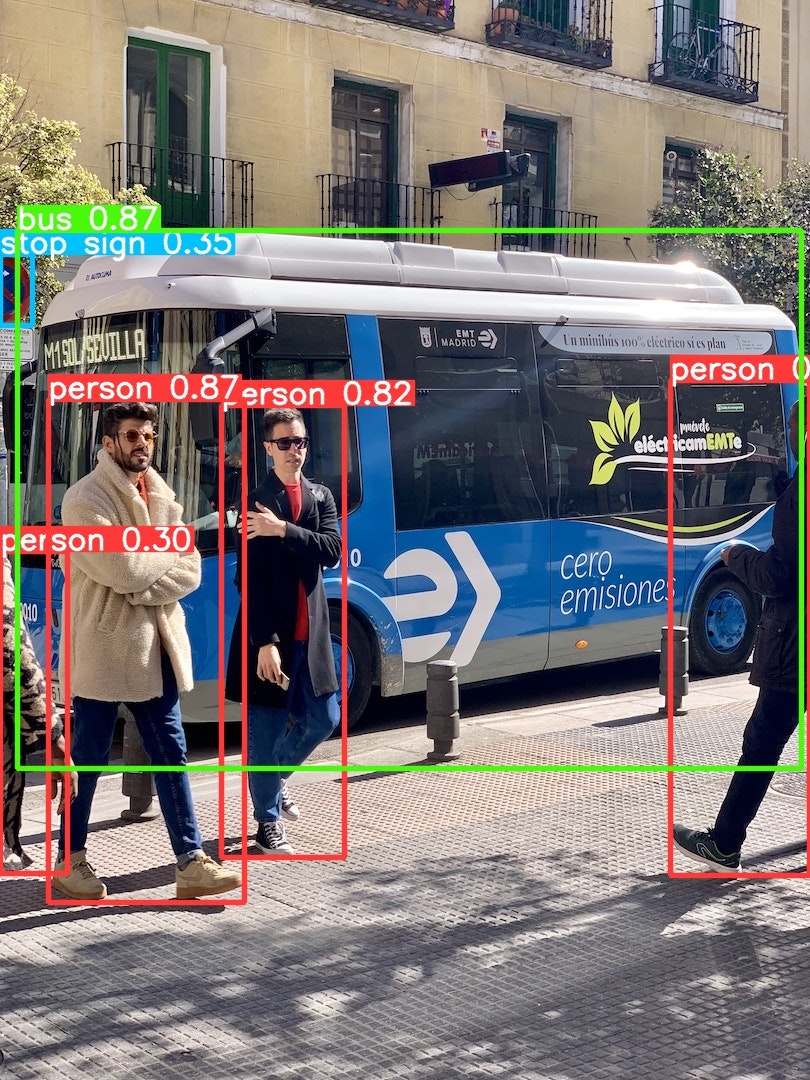
正確に検出できたことがわかります。
でもこれだけだと、検出した結果は自己満足にしか使えないから、この結果を使って自分がやりたいことに繋げるためには検出した情報を更に変数にして扱いたいから、下記コマンドを使えば便利です。
result = results[0] #検出した結果をresultに格納
idem=len(result.boxes) #検出したアイテムの数を出す
print(idem)
box = result.boxes[0] #検出したアイテムのNo.0のBoxの情報
class_id = result.names[box.cls[0].item()]
cords = box.xyxy[0].tolist()
cords = [round(x) for x in cords]
conf = round(box.conf[0].item(), 2)
print("Object type:", class_id)
print("Coordinates:(四捨五入後の値)", cords)
print("Probability:", conf)
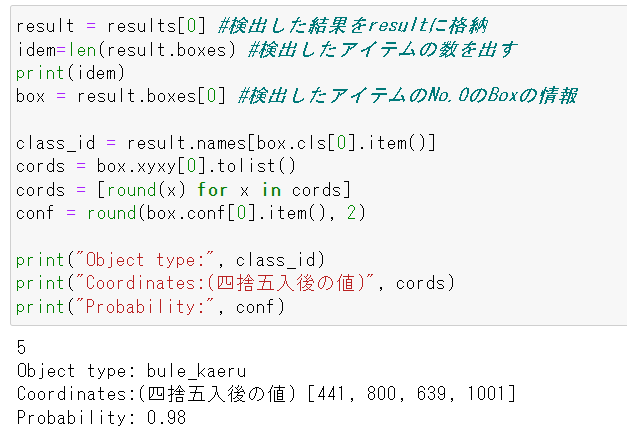
例として0番の結果を表示した見てみたが、実際使う時に目的に合わせて変ればよいですね。検出Box数のLoopすれば、ターゲットとしたいものが出ているかどうかを確認するとか、数を確認するとかはできるわけ。
8.Webカメラを使いリアルタイムで検証
更にカメラにてリアルタイムで検出したい場合は下記showのパラメータ設定すれば、裏でcv2にてカメラを起動し、動画で確認することができる。
from ultralytics import YOLO
# コンフィグは学習時と同じコンフィグでよい
model = YOLO("/Users/ryuka/workspace/Python/Image_AI/yolov8/ultralytics-main/ultralytics/cfg/models/v8/myyolov8.yaml") # build a new model from scratch
# bestのモデルを使う
model = YOLO("/Users/ryuka/workspace/Python/Image_AI/yolov8/runs/detect/train14/weights/best.pt") # load a pretrained model (recommended for training)
results = model(0,show=True,conf=0.7) # 0は(No.0番)カメラ指定、confは確信度閾値
実行すると、Opencvのカメラの画面が起動され、検出できた物体にフレームが表示されると同時に下記絵のように検出状況がprintされる。

ざっくりですが、内容は下記になります。
カメラNo.:カメラで撮った画像サイズ 物体数 物体ID① 物体名①,物体ID② 物体名②...使用した時間
補足:
1.step6の時点でlabelsの中のclassesの順番(black_man,white_man)とmycoco.yamlのclassesの順番(white_man,black_man)が異なることにより、検出結果がblack_manとwhite_man逆になってしまいました。それを修正した結果、正しく検出できるようになりました。注意しないといけない。
2.nのモデルを使って学習したが、やはり画像を追加しても精度上げることが難しかったようで、sのモデルを使って学習した結果、かなり精度がよくなりましたね。
感想
SSDと比べて学習(自分はノードの3050GPUを使って50枚くらいの画像で今回学習してみたが、使った時間は5分かからなかった)、検出もかなり速い、枠もより正確に物体の周りにきれいに囲んでいる。
memo:
CUDAで対応したところ下記エラーが発生した。torchvisionがcudaバージョンに対応していないようで、CUDAバージョンを再度インストールして直して、解消。
“NotImplementedError: Could not run ‘torchvision::nms‘ with arguments from the ‘CUDA‘ back