はじめに
今回は国会APIから取得した衆参本会議の議事録を用いて、国会で議論されているトピックがどのように変化しているのかを分析しました。
トピックモデルとは
文書で取り上げられているトピックを推定する教師なし学習の手法です。文書の分析におけるクラスタリングと捉えることができます。
単語の次元をトピックの次元に削減する主成分分析とも言えます。
トピックモデルの考え方の根底には「文書は複数の潜在的なトピックから確率的に生成されている」という仮説があります。
各文書の単語頻度を観測し、共起性について確率的に分析することで、全ての文書から指定した数のトピックを求め、文書におけるトピック構成比率とトピックにおける単語の構成比率を求めることができます。
少々イメージが掴みにくいので、今回行う国会を例に考えてみましょう。
国会では本会議や予算委員会など様々な会議が開かれ、同じ会議の中でも、法案決議、外交、教育、雇用、社会保障、自衛隊、災害、不正献金など非常に多くの日本における政策、問題が話合われています。
発言をみてみましょう。これは2018年3月23日の参議院本会議の民進党矢田議員の発言です。
矢田わか子君 民進党・新緑風会の矢田わか子です。
ただいま議題となりました子ども・子育て支援法の一部を改正する法律案に関し、会派を代表して質問いたします。
本日の議題に入る前に、森友学園への国有地売却に関する公文書、決裁文書の改ざん問題について、一言申し上げなければなりません。
そもそも国有地は国民の貴重な財産であり,,,(中略),,,あってはならない公文書の改ざん問題について、政府の一員として、松山大臣の御見解をお伺いいたします。
また、本日議題となっている本法案は,,,(中略),,,以上のことを踏まえ、子ども・子育て支援法の一部改正案について質問をいたします。,,,(中略)
次に、保育士の処遇改善問題について質問します。,,,(中略)
さて次に、提出された本案に関わる企業主導型保育事業に関して質問します,,,(中略)
最後の質問として、今回提出された法案の大きな大きな柱の一つである待機児童対策協議会の設置について伺います,,,(中略)
いずれにしても、今回の法改正、場当たり的なものではなく、来年度、企業に追加拠出いただく一千億円相当もの拠出金が、真にこの国の将来を担う子供たちが健全に育つための施策に生かされるよう御期待申し上げ、私の代表質問とさせていただきます。
かなり長いのでちょくちょく中略させていただきましたが、まず森友問題についての指摘があり、議題である子ども・子育て支援法に関しても様々な指摘がなされています。
トピックモデルでは、これら全発言文書からトピックを推定し、それぞれの発言でのトピックの構成比率を求めることができます。
上記の一つの発言のみで見てみると、子育て支援が70%、森本問題が30%程度で発言の中でトピックが分かれていそうです。
トピックモデルでは全ての文書について分析し、子育て、外交、経済、自衛隊、といったトピックを教師なし学習で得ます。そしてトピックによる分類を全ての発言に関して行うことができるのです。
またトピック内での単語の構成比率を求めるとは、子育て支援というようなトピックには、子ども、待機児童、保育園、主婦といった単語がそれらのトピックを構成する単語であり、それらの単語がトピック中でどれくらいを占めているかを求めることができる、ということです。
ただしここで注意しなければならないのは、分類された各トピックがどのように分かれているかは事前に想定できないということです。上記の文章であれば子育て支援、森本問題というようなトピックとして分かれているとは限らず、子育てだけでなく、教育全般でのトピックとして分類されるかもしれませんし、森友問題についてもスキャンダルや、不正のようなトピックに分類されているかもしれません。指定するトピック数によってこれらトピックの抽象度は変わっていきます。分類されたトピックでの単語の出現確率から、それが何のトピックであるかは自分で考えなければいけません。
今回は数学的な解説は省略して、実装と分析についてまとめました。
今回はトピックモデルの代表的な手法であるLDAを用いて分析を行います。
これらのサイトを参考にさせていただきました。
https://blog.aidemy.net/entry/2018/05/11/162024
http://tdual.hatenablog.com/entry/2018/04/09/133000#gensim
https://qiita.com/Hironsan/items/2466fe0f344115aff177
https://qiita.com/shizuma/items/44c016812552ba8a8b88
分析は以下の環境で行いました。
・OS
ProductName: Mac OS X
ProductVersion: 10.12.6
BuildVersion: 16G29
・Python 3.6.4
・gensim 3.6.0
分析の流れ
1国会APIからデータを取得する
2議事録データを発言者ごとに文書に切り分け、形態素解析を行う
3コーパスの作成
4LDAで学習する
5トピック文書数の変化を年ごとに見てみる
1国会APIからデータを取得する
今回は2008年1月から2018年9月までの国会の議事録データを取得して、50トピックに分けてみます。
国会会議録検索システムには過去の会議録が保存されており、会議名、日時、発言者等で検索できます。
以下のサイトの使い方に従ってコードを書いて議事録データを取得しましょう。
[国会会議録システム検索用APIについて(http://kokkai.ndl.go.jp/api.html)
## データの取得
import urllib
import untangle
import urllib.parse
# 一ヶ月ごとにテキストファイルに保存する
if __name__ == '__main__':
start='1'#発言の通し番号
while start!=None:
keyword = ''
startdate='2008-01-01'
enddate= '2008-01-31'
meeting='本会議'
#urllib.parse.quoteが日本語をコーディングしてくれる
url = 'http://kokkai.ndl.go.jp/api/1.0/speech?'+urllib.parse.quote('startRecord='+ start
+ '&maximumRecords=100&speaker='+ keyword
+ '&nameOfMeeting='+ meeting
+ '&from=' + startdate
+ '&until='+ enddate)
#Get信号のリクエストの検索結果(XML)
obj = untangle.parse(url)
for record in obj.data.records.record:
speechrecord = record.recordData.speechRecord
print(speechrecord.date.cdata,
speechrecord.speech.cdata)
file=open('data_2008_1.txt','a')
file.write(speechrecord.speech.cdata)
file.close()
#一度に100件しか帰ってこないので、開始位置を変更して繰り返しGET関数を送信
start=obj.data.nextRecordPosition.cdata
かなりのファイルサイズになるため、一ヶ月ごとに保存しました。これを繰り返してデータを揃えましょう。
2議事録データを発言者ごとに文書に切り分け、形態素解析を行う
自然言語処理では前処理の作業が非常に多く、またそれぞれの文書に適した形で行う必要があります。
今回は
・テキストデータの切り分け(文書化)
・形態素解析
・ストップワードの設定
・名詞のみを取り出す
といった作業を行なっていきます。
取得したデータの一部をみてみます。

このように発言者ごとに◯で区切られていることがわかります。
また、日付や、昨日、午後、などトピックに直接関係のないものが含まれていることがわかります。これらはストップワードに指定し、分析対象から外していきます。
形態素解析とは、文章を最小単位に分割し、品詞などを同定していくことです。
特に日本語の文章は英語などとは異なり、単語と単語の間は空白ではなく、「が」、「の」といった助詞で繋がれており、単語に区切るには品詞分解をしていく必要があります。
日本語の形態素解析としてはMeCabやjanomeといったソフトが有名で、今回はMeCabをpython上で実装します。
また、MeCabで品詞分解していくにあたって辞書が必要になります。これらの辞書は日々変化していくもので、人の名前や、新しい流行語、造語などを踏まえた分析を行うには最新の辞書を適用していく必要があります。
MeCab ipadic-neologdは週に2回更新される辞書で、より正確な分析を行うことができるため、今回の分析でも使用していきます。
MeCabと辞書のインストールについてはこちらの記事が参考になります。
https://qiita.com/taroc/items/b9afd914432da08dafc8
辞書の効果を確認して見ましょう
import MeCab
m = MeCab.Tagger()
text = m.parse('安倍晋三首相らは国家安全保障会議で情報を分析するとともに対応を協議した。')
m_neo= MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/")
text_neo=m_neo.parse('安倍晋三首相らは国家安全保障会議で情報を分析するとともに対応を協議した。')
print(text)
print(text_neo)
結果は以下のようになりました。
◯辞書の設定なし

◯ipadic-neologdを辞書に設定

このように辞書を設定することで安倍晋三首相、国家安全保障会議というような名詞を認識できるようになっていることがわかりますね。
今回は形態素解析から得られた名詞のみを取り出して、リストに保存していきます。
ストップワードは、ストップワード一覧をネットから取得し、さらに今回の国会議事録での分析に合わせて追加しました。
## 必要なモジュールのインポート
from urllib import request
import numpy as np
import re
import MeCab
mecab = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/")
## 前処理
# 日本語ストップワードをネットから取得
res = request.urlopen("http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt")
stopwords = [line.decode("utf-8").strip() for line in res]
# 英語ストップワードをネットから取得
res = request.urlopen("http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/English.txt")
stopwords += [line.decode("utf-8").strip() for line in res]
# 国会議事録頻出の分析に不必要な言葉
mydict = ['安倍晋三','ん','国民','我が国','内閣総理大臣','日本','重要','の','平成','お尋ね','今後','昨年','必要','実現','改革','強化','政府','環境','対策','制度','経済','世界']
stopwords = stopwords + mydict
class Tokenizer:
def __init__(self, stopwords, parser=None, include_pos=None, exclude_posdetail=None, exclude_reg=None):
self.stopwords = stopwords
self.include_pos = include_pos if include_pos else ["名詞"]#名詞のみを取得
self.exclude_posdetail = exclude_posdetail if exclude_posdetail else ["接尾", "数"]
self.exclude_reg = exclude_reg if exclude_reg else r"$^" # no matching reg
if parser:
self.parser = parser
else:
mecab = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/")
self.parser = mecab.parse
def tokenize(self, text, show_pos=False):
# こちらはニュース記事の分析に使用したものなので今回は不要です(国会の議事録に該当する言葉はなさそうです。)
text = re.sub(r"https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+", "", text)
text = re.sub(r"\"?([-a-zA-Z0-9.`?{}]+\.jp)\"?" ,"", text)
text = text.lower()
l = [line.split("\t") for line in self.parser(text).split("\n")]
res = [
i[2] if not show_pos else (i[2],i[3]) for i in l
if len(i) >=4 # has POS.
and i[3].split("-")[0] in self.include_pos
and i[3].split("-")[1] not in self.exclude_posdetail
and not re.search(r"(-|−)\d", i[2])
and not re.search(self.exclude_reg, i[2])
and i[2] not in self.stopwords
]
return res
t = Tokenizer(stopwords + ["…。"] , mecab.parse, exclude_reg=r"\d(年|月|日)")
一ヶ月のデータを◯で区切り、先ほど設定したクラスを実行していきましょう
texts=[]
docs=[]
dict_2008 = {}#辞書型
for num in ['1','2','3','4','5','6','9','10','11','12']:#7,8月は休会
dict_2008[num]= open(f'data_2008_{num}.txt')
data1 = dict_2008[num].read()#全てのデータを返す
dict_2008[num].close()
#テキストデータを◯で切って文書化
sentences = data1.split('○')
#文書ごとに前処理してリストに格納
for sentence in sentences:
texts.append(sentence)
docs.append(t.tokenize(sentence))
この処理を08年から18年まで行い、発言ごとにリスト格納しました。
34205個の発言文書が得られました。
この各発言文書をLDAで学習してトピックを推定していきます。
3 コーパスの作成
ここからはgensimというライブラリを利用してコーパスの作成、LDAの学習を行なっていきます。
まず、gensimのcorporaクラスのDictionaryを用いて単語とIDのマッピングを行います。
from gensim import corpora
# 辞書の設定
dictionary = corpora.Dictionary(docs)
docs_words = dictionary.token2id#辞書型
print(len(docs_words))
docs_wordsは{単語:id}の辞書型です。
単語数は44507個になりました。
余談ですが、文書数34205個に対して単語数44507個ということで、それぞれの文書で結構な頻度で同じ言葉が使われていることがわかります。
次に単語のフィルタリングを行います。
単語の出現頻度に基づいて単語を除去します。
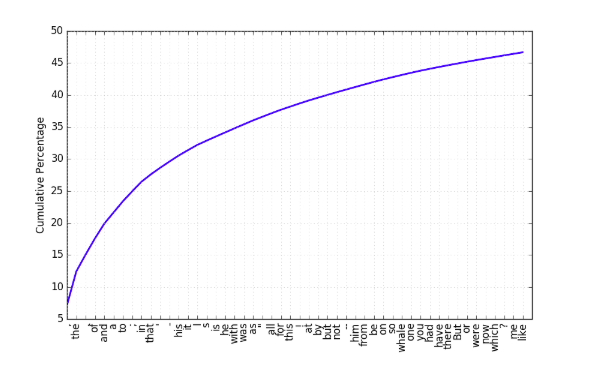
こちらは英単語ですが、theやofといった単語がテキストの50%近くを占めていることがわかります。
また、文書での出現頻度があまりにも少ない単語も全体のトピック分類にとっては重要性の低い単語であると考えられます。
今回は全文書の50%以上で出現する単語と出現文章が3回以下の単語と除去しました。
# フィルタリング
dictionary.filter_extremes(no_below=3,no_above=0.5)
# 使われている文章がno_belowより少ない単語を無視、no_aboveの割合以上に出てくる単語を無視
dictionary.compactify()#IDを振り直してコンパクトにする
docs_words_compact = dictionary.token2id
print(len(docs_words_compact))
これによって単語数は27015個に減りました。
次にコーパスを作成します。
これはLDAのモデルで学習するためのデータのことで、先ほどの辞書を適用することで各文書の単語について単語IDと出現頻度のタプルにします、この形式のことをBag of Words(Bow)と言います。
corpus = [dictionary.doc2bow(w) for w in docs]
これで準備が終わりました。
4 LDAで学習を行う
今回扱うLDAとは日本語で潜在ディリクレ分配法と言われるもので、
事前分布をディリクレ分布に仮定することで、文書は少数のトピックで構成され、トピックも少数の複数の単語で表現されるという事前情報を組み込んだものになっています。
gensimのmodelsクラスのldamodel.LdaModelを用いて学習していきます。
引数にはコーパスと辞書、トピック数を指定します。
今回は50個のトピックに分けていきます。
また、LDAモデルの性能評価としてPerplexityというものがあります。
こちらも詳細な説明は今回省きますが、Perplexityは単語の生成確率の逆数の幾何平均を表しています。単語の生成確率の逆数は選択肢の数を表してします。
ある単語を生成するときに、全文書の中からランダムに生成される場合、単語の生成確率は
「1/全文書の出現単語数」 となり、
生成される単語が完全に予測されている場合は生成確率は1となります。
ランダムに単語を生成するのではなく、特定の文書に現れる限られた単語の中から生成させる方が良いモデルと言えるので、Perplexityは全文書の単語数と比べて小さいほどよく学習できていると言えます。
corpusを分割してtrainデータで学習していきます。
import logging
import random
from gensim import models
# モデルの学習
# 時間がかかります
# test,trainに分けて学習
test_size = int(len(corpus) * 0.1)
test_corpus = corpus[:test_size]#1割
train_corpus = corpus[test_size:]#9割
# 学習状況を確認するためのlogの設定
logging.basicConfig(format='%(message)s', level=logging.INFO)
# トピック数50に設定して学習
lda = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=50, passes=10)
# Nはのべの出現単語数(test)
N = sum(count for doc in test_corpus for id, count in doc)
print("N: ",N)
# perplexityで性能評価
perplexity = np.exp2(-lda.log_perplexity(test_corpus))
print("perplexity:", perplexity)
Nは451122個に対してperplexityは344とよく学習できているようです。
結果を見てみます。
50トピックについて上位出現頻度の単語を100個ずつ取り出して、csv形式で出力します。
# 各トピックの要素の表示
topic50 = []
for topic_ in lda.show_topics(num_topics=50, num_words=100, formatted=False):
topic50.append([token_[0] for token_ in topic_[1]])
topic50 = pd.DataFrame(topic50)
# print(topic50)
topic50.to_csv(('topic08-18.csv').__str__(), index=False, encoding='utf-8')
また、上位20トピックの上位10単語を表示すると以下のようになりました。

4番目は震災、5番目は財政、14番目は子ども、女性といったようなトピックがわかります。
また、各文書について結果をみていきます。
最初に取り上げた矢田氏の発言がどのようなトピック構成比率に分かれているか確認してみます。
# 文書ごとのトピック分類結果を得る
topics = [lda[c] for c in corpus]
def sort_(x):
return sorted(x, key=lambda x_:x_[1], reverse=True)
# トピックを取得
num_topics = lda.get_topics().shape[0]
target_doc_id =539
print(texts[target_doc_id])
print(sort_(topics[target_doc_id]))

矢田氏の発言は49%がtopic18, 10%がtopic40, 6%がtopic25,,,という結果になりました。
50個に分けた中でtopic18は子どもに関するトピックですので、正しくトピック分類ができていることがわかります。11年分の文書でトピックを50個に分けたので森友問題は単独のトピックとしては現れませんでした。topic40は問題、答弁といった単語が上位にあり、野党による与党追求のトピックと推測されますが、定かではありませんね、、
5 トピック文書数の年ごとの変化を見る
トピックxが20%以上含まれるものをトピックx文書とします。
先ほどのsorted_(topic[])から特定のトピックについてトピック文書を取り出してみます。
topic38について行ってみます。
topic38は上位単語が活動,自衛隊,支援,補給,テロ,アフガニスタン,海賊,沖縄,米,給油,派遣,対処,米軍,米国,移設,インド洋,憲法,安全,負担,国際社会,,,となっており、自衛隊活動に関するトピックです。
# 年ごとにトピック文書を格納するリストの作成
for num in range(50):
exec('topic{}_text =[]'.format(num))
exec('topic{}_text_number=[]'.format(num))
for j in range(2008,2019):
exec('topic{}_text_{} =[]'.format(num, j))
# トピックの指定
for i in range(34205):
for j in range(len(topics[i])):
if sort_(topics[i])[j][0]==38:
if sort_(topics[i])[j][1]>=0.20:
topic38_text.append(texts[i])
topic38_text_number.append(i)
# 該当する文書の数の確認
print(len(topic38_text_number), len(topic38_text))
トピック38文書は449個あることがわかりました。
この449個の文書を年ごとに分類していきます。
最初に文書を結合する際に各年の文書数を数えておきました。それを利用して文書を年ごとのリストに格納し、文書数を数えたリストを作成します。
for i in range(len(topic38_text_number)):
if topic38_text_number[i]<=2876:
topic38_text_2018.append(topic38_text_number[i])
elif 2876< topic38_text_number[i]<=5694:
topic38_text_2017.append(topic38_text_number[i])
elif 5694< topic38_text_number[i]<=9005:
topic38_text_2016.append(topic38_text_number[i])
elif 9005< topic38_text_number[i]<=11958:
topic38_text_2015.append(topic38_text_number[i])
elif 11958< topic38_text_number[i]<=15403:
topic38_text_2014.append(topic38_text_number[i])
elif 15403< topic38_text_number[i]<=19687:
topic38_text_2013.append(topic38_text_number[i])
elif 19687< topic38_text_number[i]<=22293:
topic38_text_2012.append(topic38_text_number[i])
elif 22293< topic38_text_number[i]<=25584:
topic38_text_2011.append(topic38_text_number[i])
elif 25584< topic38_text_number[i]<=28649:
topic38_text_2010.append(topic38_text_number[i])
elif 28649< topic38_text_number[i]<=31419:
topic38_text_2009.append(topic38_text_number[i])
elif 31419< topic38_text_number[i]<=34205:
topic38_text_2008.append(topic38_text_number[i])
topic38_time=[
len(topic38_text_2008),
len(topic38_text_2009),
len(topic38_text_2010),
len(topic38_text_2011),
len(topic38_text_2012),
len(topic38_text_2013),
len(topic38_text_2014),
len(topic38_text_2015),
len(topic38_text_2016),
len(topic38_text_2017),
len(topic38_text_2018)]
topic38_time
この結果をプロットすると以下のようになります。
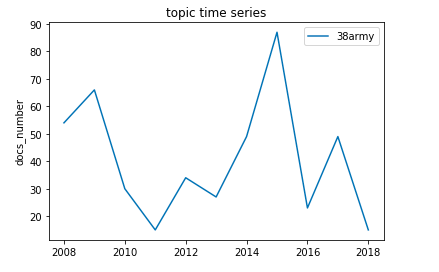
自衛隊に関する発言文書は2011年頃に減少し、2015年に急増していることがわかります。
東日本大震災により、国内での自衛隊要請は高まった一方で海外出動に関する議論が減ったことがわかりました。国内の震災への自衛隊の対応は震災関連のトピックに分類されていることが考えられます。
2015年には集団的自衛権を行使できるようになる安全保障関連法(安保法)が参院本会議で自民、公明両党などの賛成多数で可決し、成立しました。その期間で発言文書が急激に増加しています。
同様の分析をtopic25:教育、27:外交,29:農業,48:金融に関しても行いました。
(これらのトピック名は私がつけたものです。)
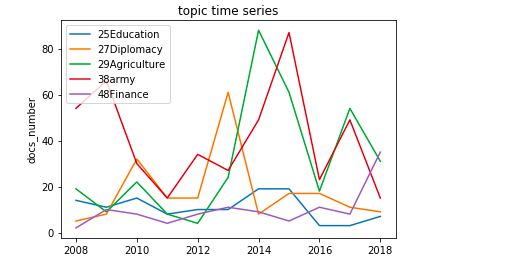
2014年にはアメリカで農業法が成立したことにより国会でも農業に関する議論が増加したようです。
国会で議論できる量には上限があります。プロットを行うと何らかの法案議論時にそのトピック文書数が急激に高まり、法案成立後は急激に低下するという動きが見られ、国会での議論内容は多岐にわたり、恒常的に変化していることが推察されました。
終わりに
前処理でのストップワードの設定や出現頻度での単語除去、トピックの命名など、私的な判断で行ったものが多く、あくまで私的な見解に過ぎませんが、LDAを用いて国会での議論がいかに変化しているかを確認できました。
データを月ごと、週ごとに分割したり、tf-idfによる単語の重み付け等を行うとまた異なる結果が得られるかもしれません。
*追加の分析を行ってみました(12/29)
https://qiita.com/hasuminbanana/private/4b7c6ca94630b4503787
全てのコードはこちらにあげてあります。
https://github.com/hasuminbanana/topic_model_LDA