動機
SushiGAN 〜人工知能は寿司を握れるか?〜という記事を見て「寿司画像提供するか」と思ったことがきっかけ。この記事のように「実用性には疑問符がつくが、Deep Learningで面白いことやってみた!」という類の記事には強く賛同する
やったこと
寿司屋のホームページから、寿司画像を収集するプログラムを作成してみた。寿司屋のホームページは静的なものがほとんどなので、Scrapingは容易だった
使用ライブラリ
定番のBeautiful Soup
コード
sushicraper.py
import requests
from bs4 import BeautifulSoup
import re
import shutil
import os
import multiprocessing
from itertools import repeat
"""
Each sushi scraper function takes a soup object and returns image source urls and names
"""
def download_img(img_src, img_name, save_dir):
print('Downloading', img_src)
try:
r = requests.get(img_src, stream=True)
if r.status_code == 200:
img_path = os.path.join(save_dir, img_name)
with open(img_path, 'wb') as f:
r.raw.decode_content = True
shutil.copyfileobj(r.raw, f)
except Exception as e:
print('Could not download the image due to an error:', img_src)
print(e)
def multi_download(img_srcs, img_names, save_dir):
num_cpu = multiprocessing.cpu_count()
with multiprocessing.Pool(num_cpu) as p:
p.starmap(download_img, zip(img_srcs, img_names, repeat(save_dir)))
def sushibenkei(soup):
img_srcs = [x['src'] for x in soup.select('div.sushiitem > img')]
regex = re.compile(r'[0-9]+円')
parser = lambda x: regex.sub('', x.replace('\n', '').replace('\u3000', ''))
img_names = [x.text + '.png' for x in soup.select('div.sushiitem')]
img_names = list(map(parser, img_names))
return img_srcs, img_names
def oshidorizushi(soup):
img_srcs = [x['src'] for x in soup.select('div.menu-a-item > img')]
img_names = [x.text + '.jpg' for x in soup.select('p.menu-a-name')]
return img_srcs, img_names
def nigiri_chojiro(soup):
uls = soup.select('ul.menu-list')
img_srcs = ['https:' + li.find('img')['src'] for ul in uls for li in ul.find_all('li')]
img_names = [li.find('dt').text for ul in uls for li in ul.find_all('li')]
parser = lambda x: x.split('/')[0].lower().replace(' ', '_') + '.jpg'
img_names = list(map(parser, img_names))
return img_srcs, img_names
def nigiri_no_tokubei(soup):
img_srcs = [x['href'] for x in soup.select('a.item_link')]
img_names = [x.text + '.jpg' for x in soup.select('dt.item_title')]
return img_srcs, img_names
def sushi_value(soup):
img_srcs = [x['src'] for x in soup.select('img.attachment-full')]
img_names = [x['alt'] + '.jpg' for x in soup.select('img.attachment-full')]
return img_srcs, img_names
def daiki_suisan(soup):
regex = re.compile(r'.+grandmenu/menu.+.jpg')
img_srcs = [x['src'] for x in soup.find_all('img', {'src': regex})]
img_names = [x['alt'] + '.jpg' for x in soup.find_all('img', {'src': regex})]
return img_srcs, img_names
def main():
img_dir = 'images'
if not os.path.exists(img_dir): os.mkdir(img_dir)
funcs_urls = [
(sushibenkei, 'http://www.sushibenkei.co.jp/sushimenu/'),
(oshidorizushi, 'http://www.echocom.co.jp/menu'),
(nigiri_chojiro, 'https://www.chojiro.jp/menu/menu.php?pid=1'),
(nigiri_no_tokubei, 'http://www.nigirinotokubei.com/menu/551/'),
(sushi_value, 'https://www.sushi-value.com/menu/'),
(daiki_suisan, 'http://www.daiki-suisan.co.jp/sushi/grandmenu/'),
]
for func, url in funcs_urls:
soup = BeautifulSoup(requests.get(url).text, 'lxml')
img_srcs, img_names = func(soup)
save_dir = os.path.join(img_dir, func.__name__)
if not os.path.exists(save_dir): os.mkdir(save_dir)
multi_download(img_srcs, img_names, save_dir)
if __name__ == '__main__':
main()
実行結果
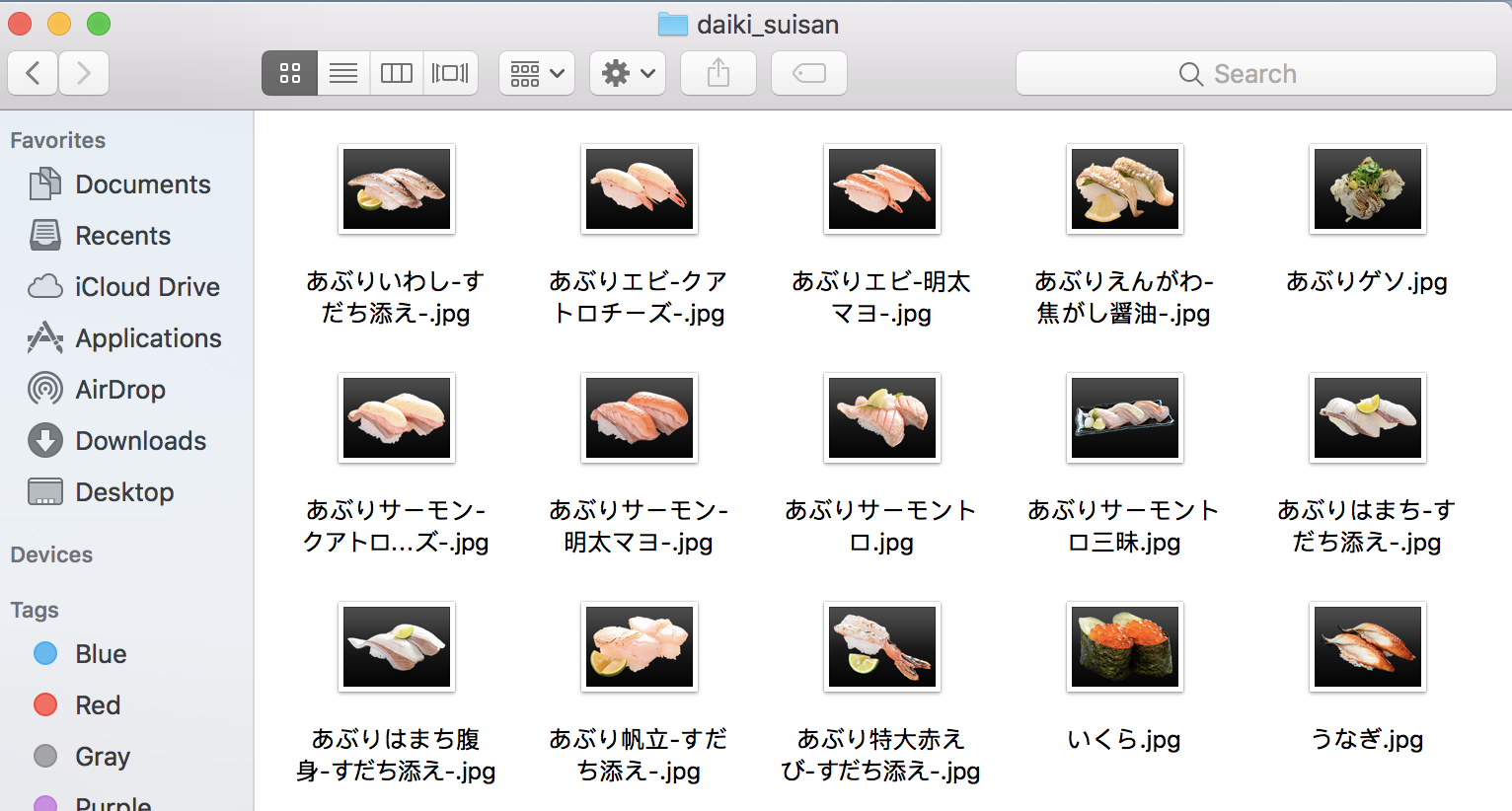
寿司屋の店名毎にフォルダが作成され、その中に画像が収集される↓
戯言
SushiNetとかSushi-Mask-RCNNとか作成したら面白そう