0. Abstract
これまでの文書解析タスクでは、ある意味盲目的に時系列処理としてLSTM、RNNが用いられてきた。
しかし、ここ最近オートエンコーダベースのモデルにAttention機構という技術を組み合わせたモデルが登場してきており、これまでのLSTMやRNNの性能を上回っている。
Attention機構自体は昔から存在しているが、それを文書解析タスクで採用したものはTransformerというモデル、論文では「Attention Is All You Need」というものとなっている。
https://arxiv.org/abs/1706.03762
本技術の紹介サイトは様々あるが、王道のTensorflowを動作させるチュートリアルは探せなかったため、使い方を説明していきたい。
今回の参考サイトは以下である。
https://github.com/tensorflow/models/tree/master/official/transformer#model-training-and-evaluation
1. Installation
学習出来る環境まで構築していく。
Switch Tensorflow 2.0 with anaconda
TF2.0で使えるモデルらしいのでまずはTF2.0をインストール。
Cuda 10.0、CuDNN 7.4、Anacondaがよい(2019, 12月時点)。
Cuda 10.1の場合はライブラリパスが見つからなくなる。
$ conda update -n base conda
$ conda create --name tf2-gpu
$ conda activate tf2-gpu
$ pip install --upgrade pip
$ pip uninstall numpy
$ pip install numpy
$ pip install tensorflow-gpu==2.0.0-rc1
# cuda 10.1用
$ export LD_LIBRARY_PATH="/usr/local/cuda/lib64:/usr/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH"
condaを使うと、どうやらIntel製MKLで高速演算可能なNumpyがインストールされるらしいが、上手く動かなかったりするので一度アンインストールして再インストールを行う。上手く動く人は飛ばしてOK。
これでTensorflow 2.0がインストールされるので以下でGPUを読み込めているかを確認する。
import tensorflow
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
たまにnvidia-smi -lがバグるらしいのでその場合は再起動。
もしくはCudaの入れ替えを行う。
なお、CUDA 10.1用にドライバ入れなおす場合は以下のようにする。
$ sudo apt-get purge nvidia*
$ sudo apt-get install cuda-libraries-10-0
$ sudo add-apt-repository ppa:graphics-drivers
$ sudo apt-get update
$ sudo apt-get install nvidia-410
Download source code
取り合えず何も考えずにオフィシャルのTensorflowのモデルをGit cloneする。
Masterブランチを使うと未だ公開されていないTensorflowの関数を使おうとしてバグるのでRC1にダウングレードさせる。
$ git clone https://github.com/tensorflow/models.git
$ git checkout tf_2_0_rc1
次にパスを通して、依存関係をインストールする。その後、Transformerのディレクトリへ移動
因みに、この辺の解説は飛ばされることが多いが、めちゃくちゃ重要
$ export PYTHONPATH="$PYTHONPATH:<YOUR_PATH>/models"
$ pip install -r models/official/requirements.txt
$ cd models/official/transformer/v2/
今後、<YOUR_PATH>/models/official/transformer/v2が作業ディレクトリとなる。
またExportが外れないようにbashrcにでも書き込んでおこう。
v2フォルダはKeras及びTF2.0に対応したバージョンのソースコードとなっている。
Variables
これから以下の変数をよく使うので、定義しておくと楽である。
PARAM_SET=big
DATA_DIR=$HOME/transformer/data
MODEL_DIR=$HOME/transformer/model_$PARAM_SET
VOCAB_FILE=$DATA_DIR/vocab.ende.32768
本稿は変数にしてしまうと分かりにくいので、ハードコーディングで進めて行く。
なお、変数で定義する場合は絶対パスを使わないと上手く動かない箇所が存在する。
Prepare datasets
今回のタスクはポルトガル語から英語への変換である。このため、これらのコーパスをダウンロードする。
$ mkdir datasets
$ python3 data_download.py --data_dir=./datasets/
亀の歩みでダウンロードが始まる。

ダウンロードが全て終わると、Shufflingが行われて以下のようなログが表示される
2. Training
ここまできてようやく学習を開始させられる。
まず重みを記録するフォルダを作成する。
$ mkdir checkpoints
次に、以下のコマンドで学習を開始する。
python transformer_main.py --data_dir=./datasets/ --model_dir=./checkpoints --vocab_file=./datasets/vocab.ende.32768 --param_set=big
学習が開始されればこのような画面が表示される。
3. Prediction
公式から急に説明がなくなるが、どうやらソースコードでは実装されている。
以下でPredictionができる。
python transformer_main.py --data_dir=./datasets/ --model_dir=./checkpoints --vocab_file=./datasets/vocab.ende.32768 --param_set=big --mode==predict
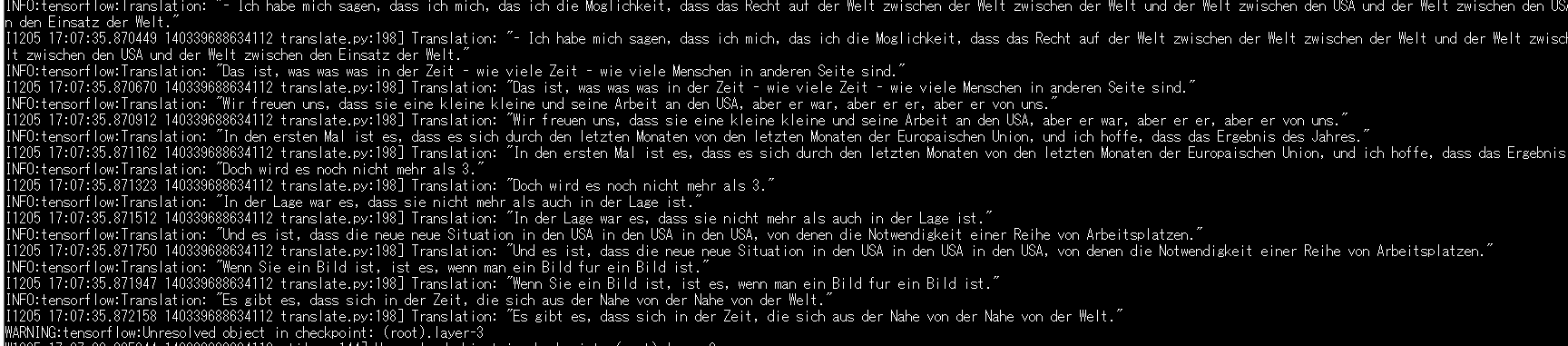
結果はこのような感じ。
対訳取得
次に対訳表現を取得したい。しかし、インプットデータはTokenizeされているし、TF.Dataset形式だし・・・という状況。
おもむろにtransformer_main.pyを開き、以下のように書き直す。
def predict(self):
"""Predicts result from the model."""
params = self.params
flags_obj = self.flags_obj
with tf.name_scope("model"):
model = transformer.create_model(params, is_train=False)
self._load_weights_if_possible(
model, tf.train.latest_checkpoint(self.flags_obj.model_dir))
model.summary()
subtokenizer = tokenizer.Subtokenizer(flags_obj.vocab_file)
ds = data_pipeline.eval_input_fn(params)
ds = ds.map(lambda x, y: x).take(_SINGLE_SAMPLE)
ret = model.predict(ds)
val_outputs, _ = ret
dataset = ds.batch(1)
iterator = dataset.make_one_shot_iterator()
batch = iterator.get_next()
for i in range(62):
translate.translate_from_input(batch[0][i].numpy(), subtokenizer)
length = len(val_outputs)
for i in range(length):
translate.translate_from_input(val_outputs[i], subtokenizer)
TF2.0からDatasetの使い方変わりすぎ・・・
書き直して実行すると米語→独語の対訳が得られる。
英語
On the other hand, 76% of voters were white but these represented only 46% of early voters.
対訳
In den anderen anderen Worten, aber nicht nur wenige % des Jahres.
5分学習したくらいじゃ全然翻訳出来ないことが分かった。