python 四分位範囲で外れ値を除外したいんです・・
解決したいこと
ここに解決したい内容を記載してください。
初心者です。
pythonで機械学習のモデルを作成するために使用するデータの整理をしています。
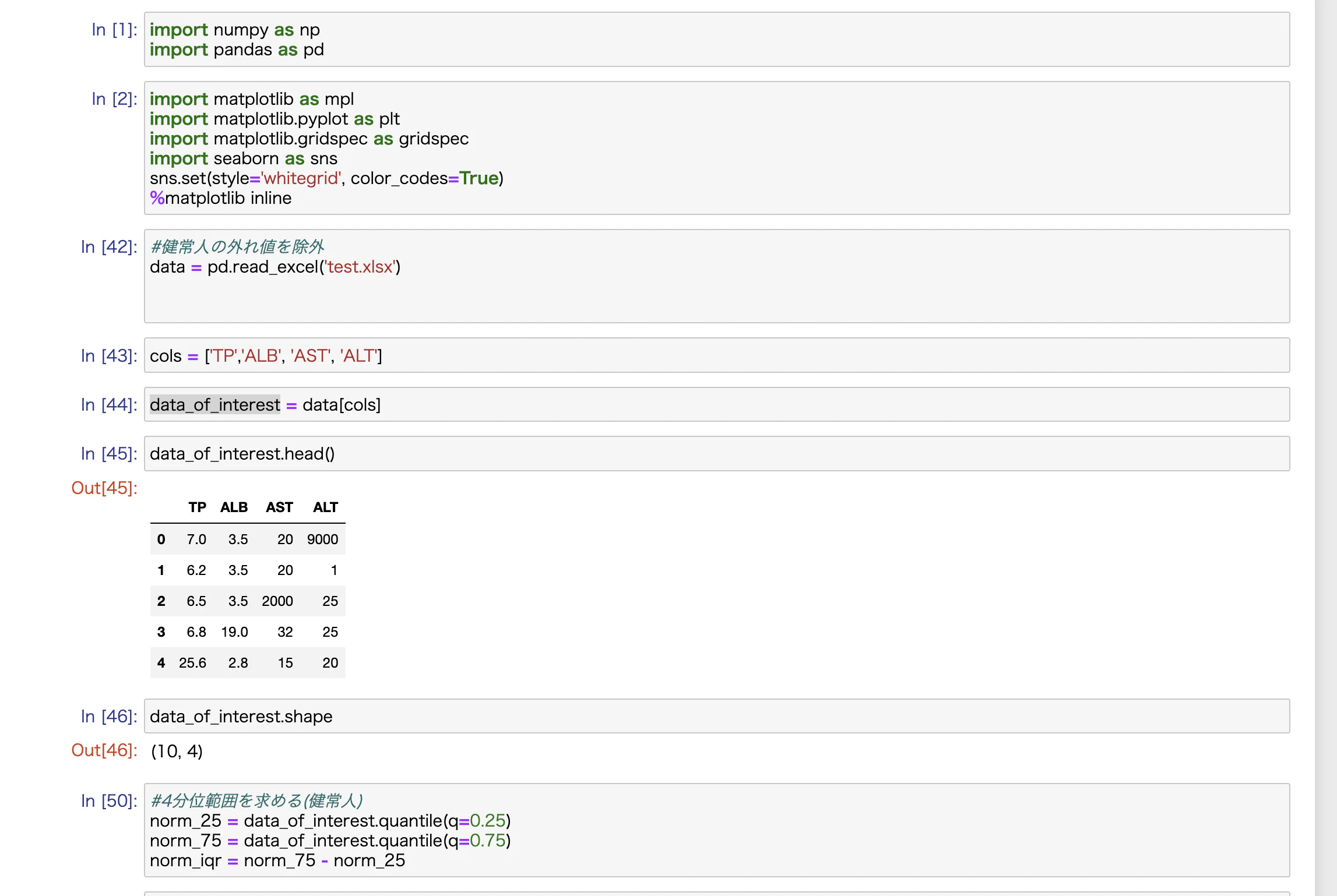
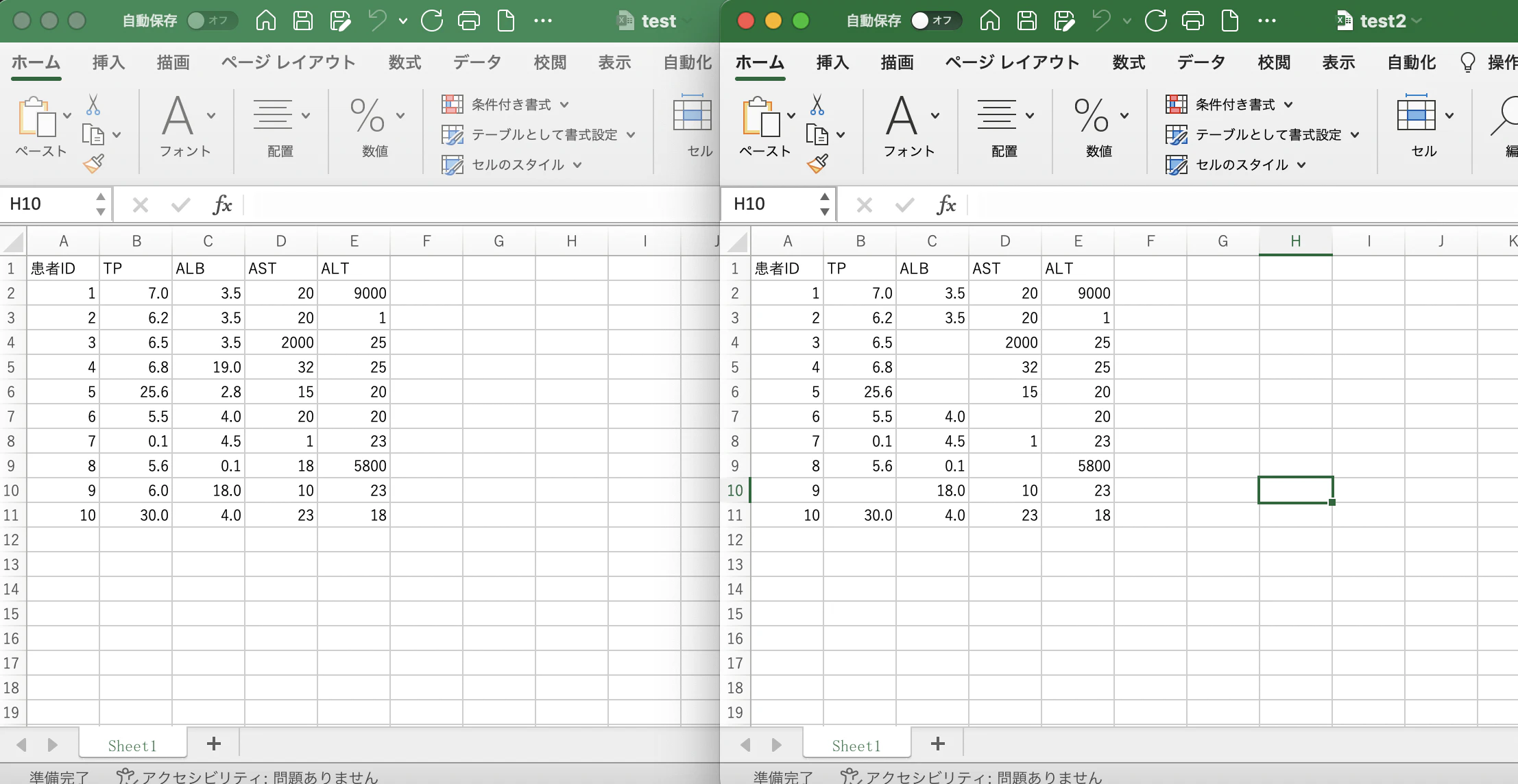
エクセルファイルから取り込んだデータについて、
各項目の数値について、四分位範囲で外れ値を除外したいのですが、うまくいきません。。
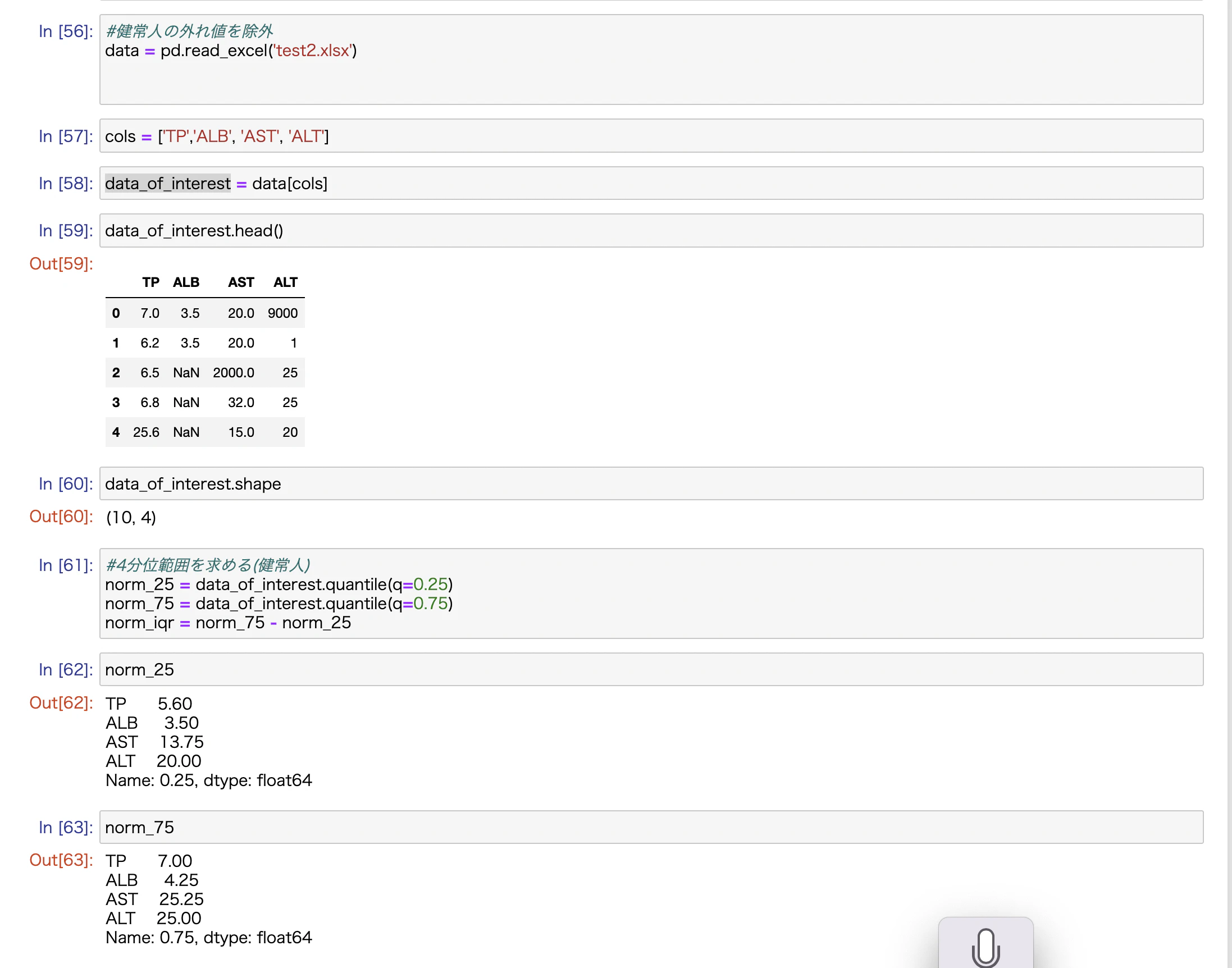
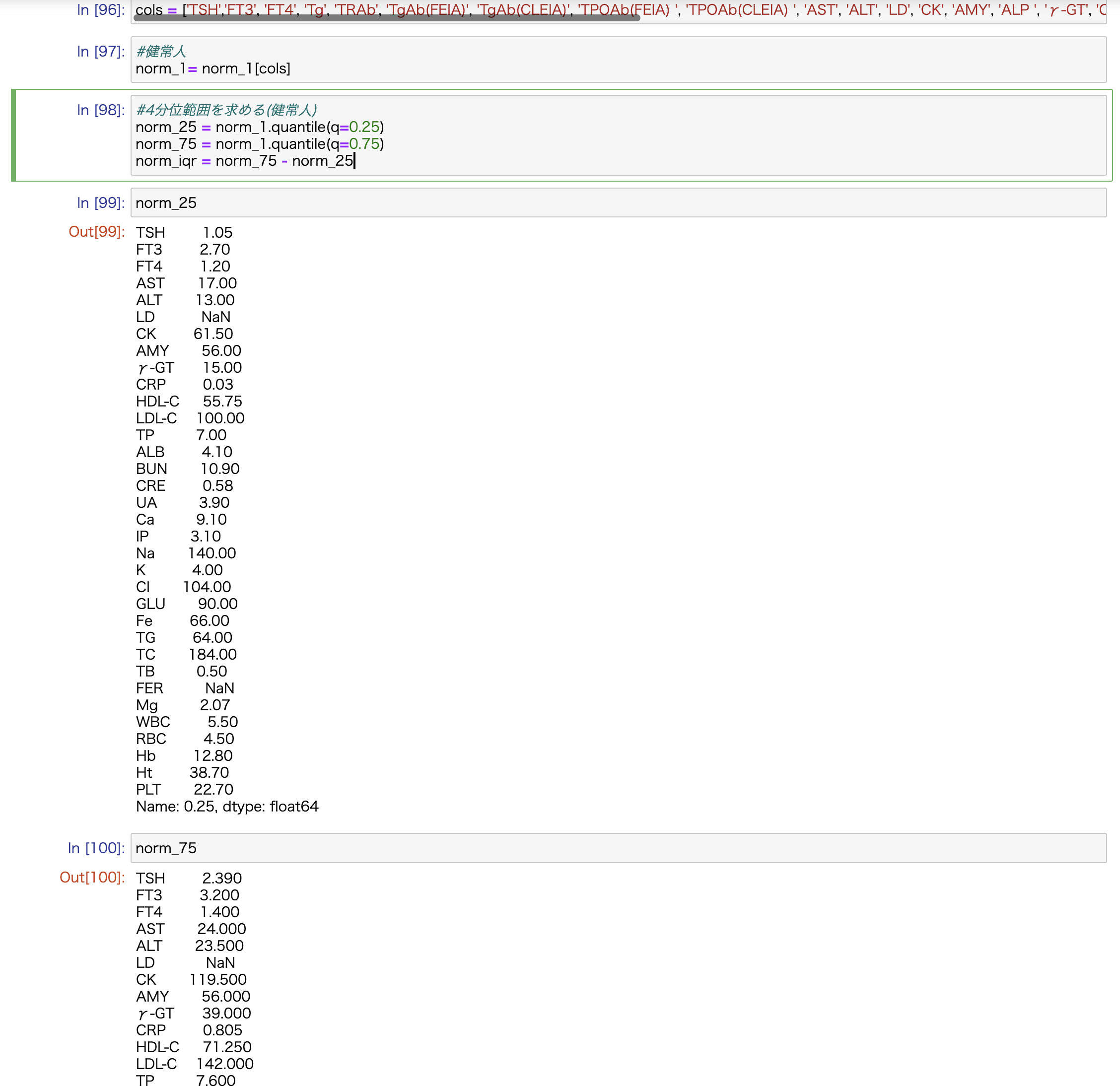
取り込んだエクセルファイルにnorm_1という名前をつけ、
各項目の4分位範囲から外れ値を除外したいのです。
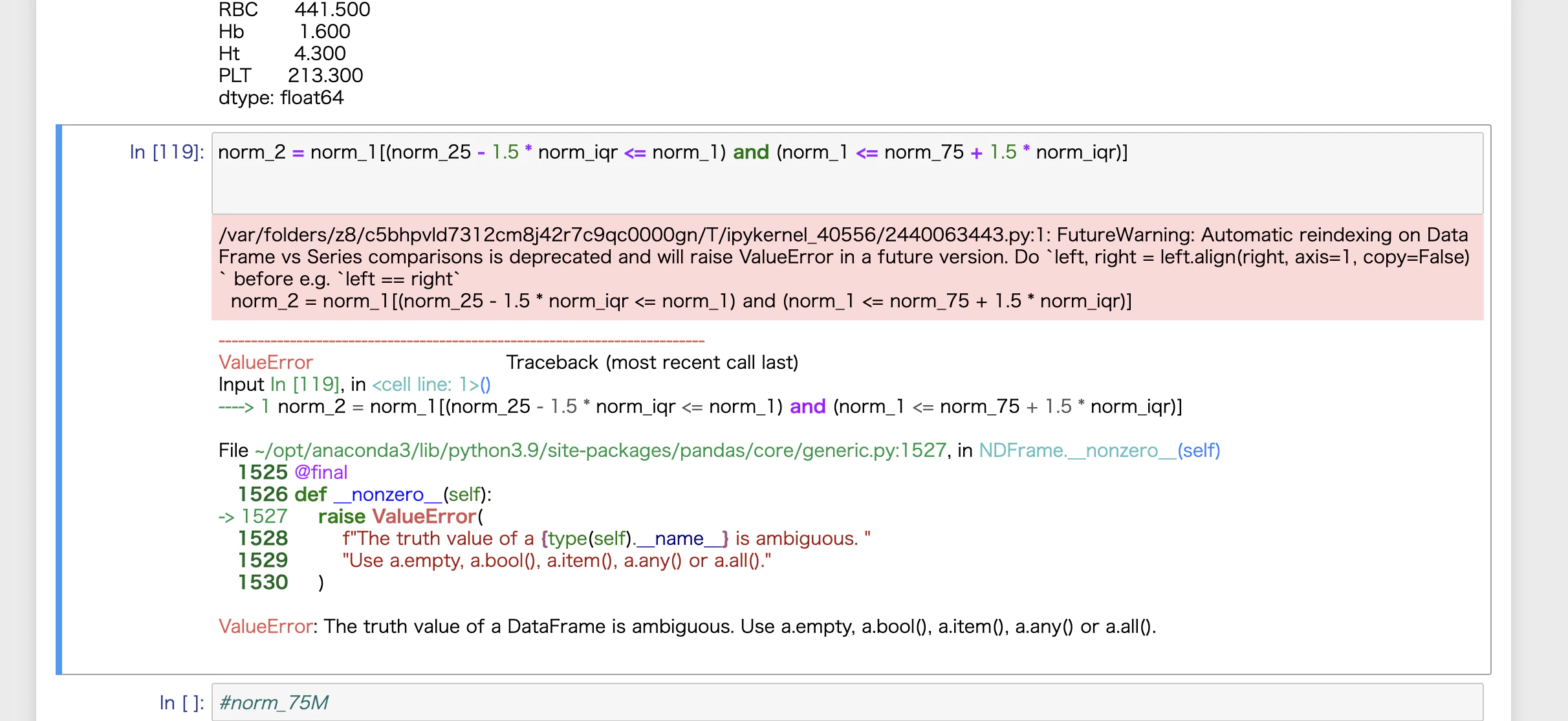
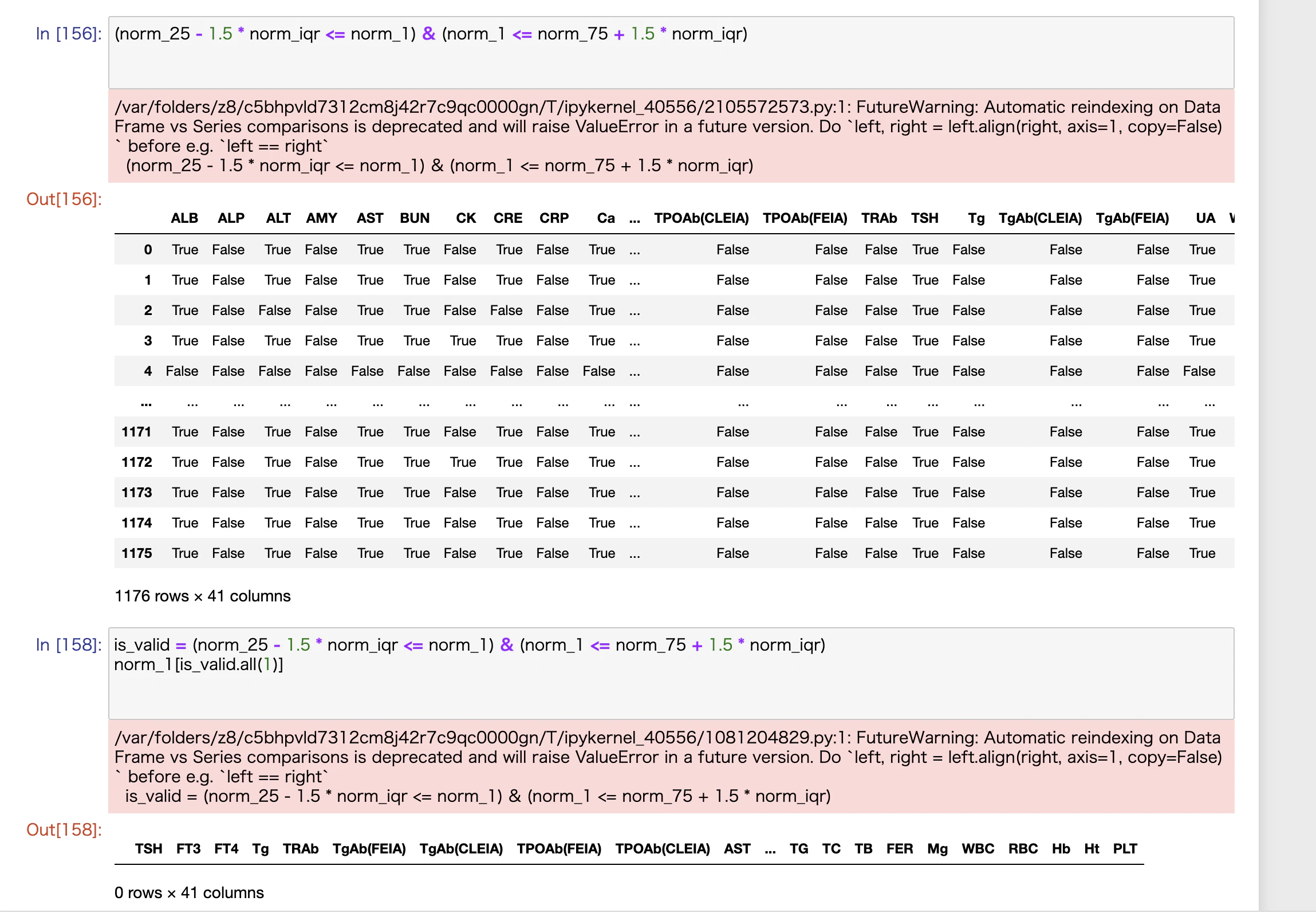
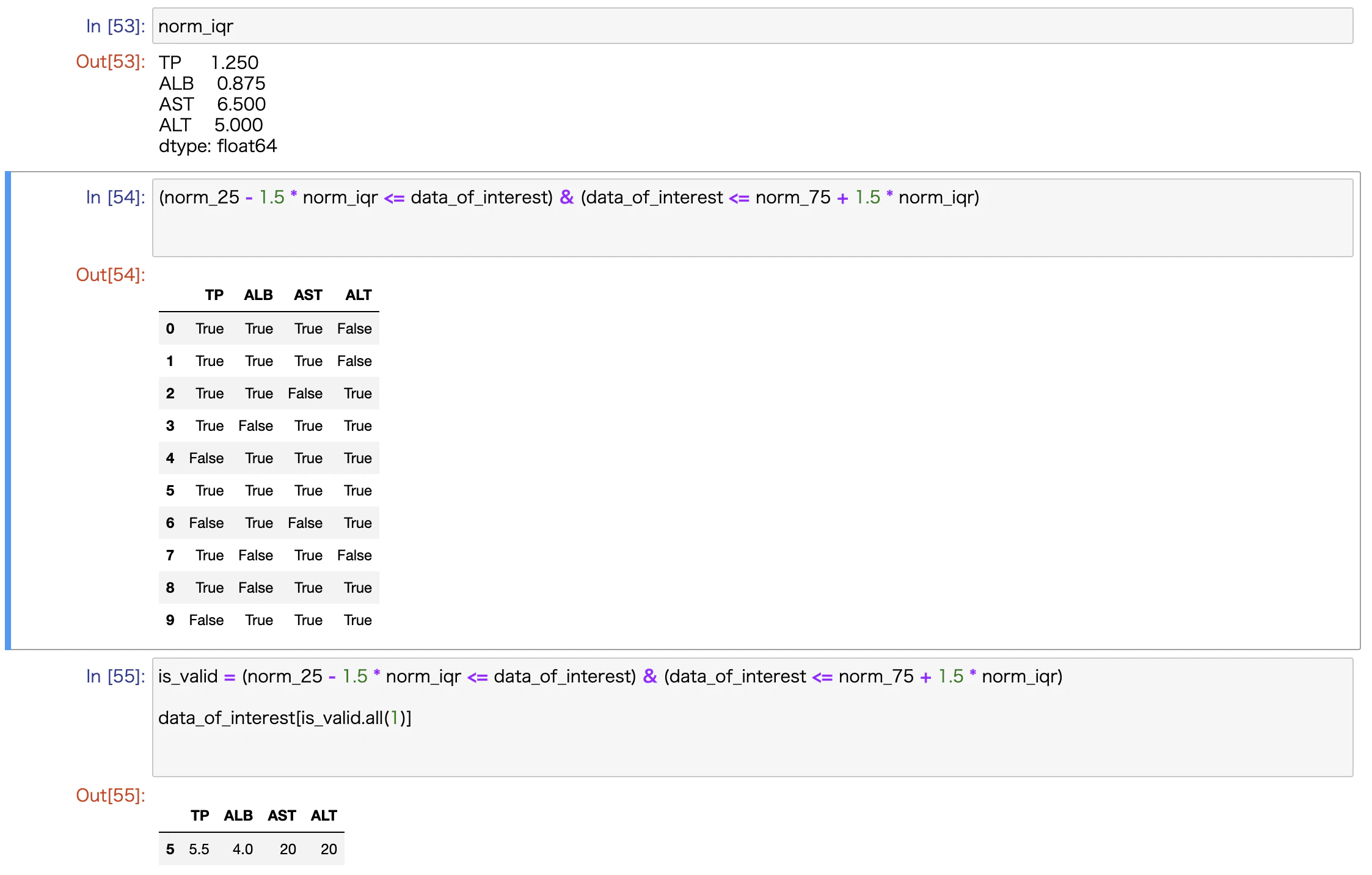
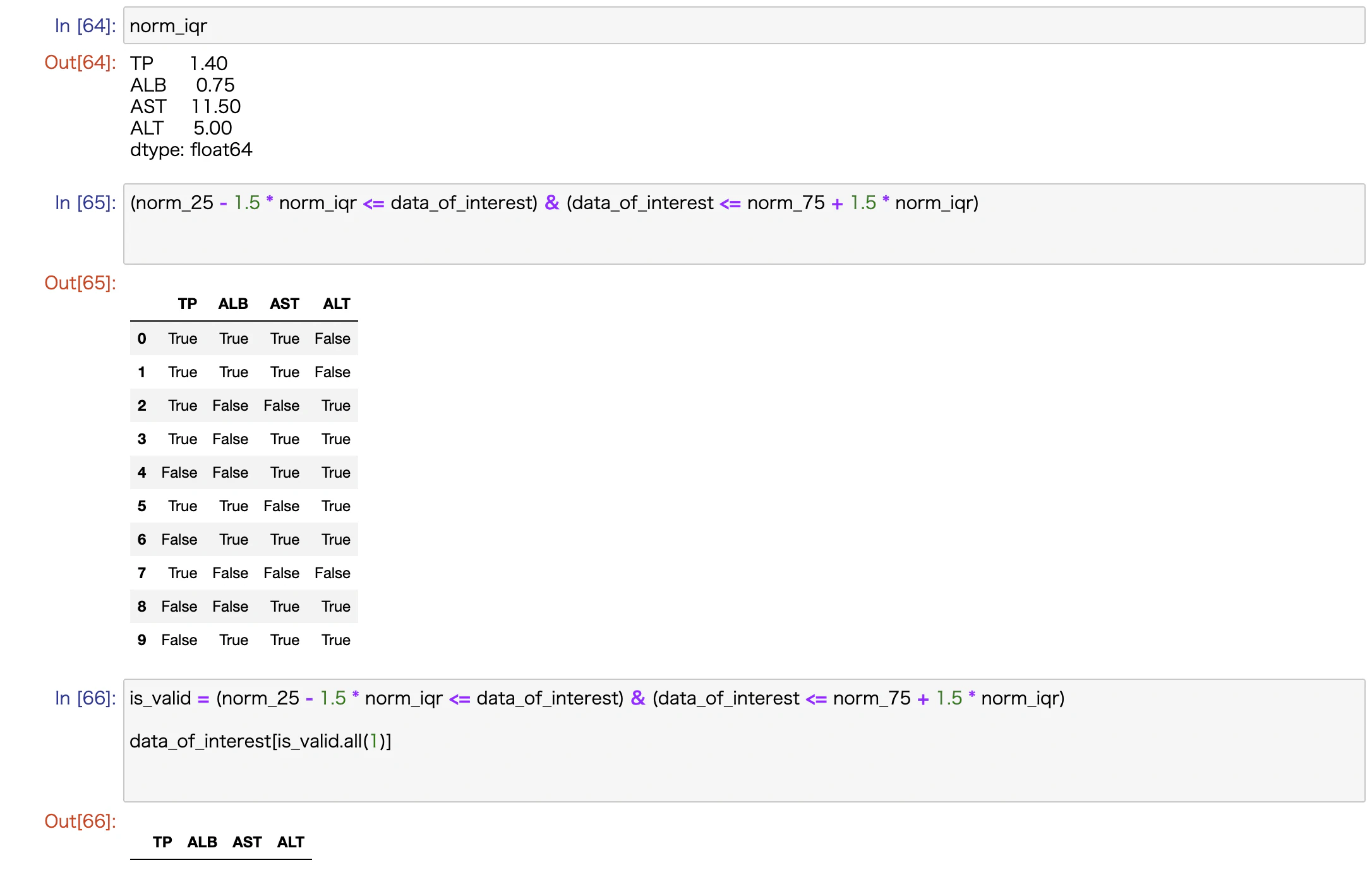
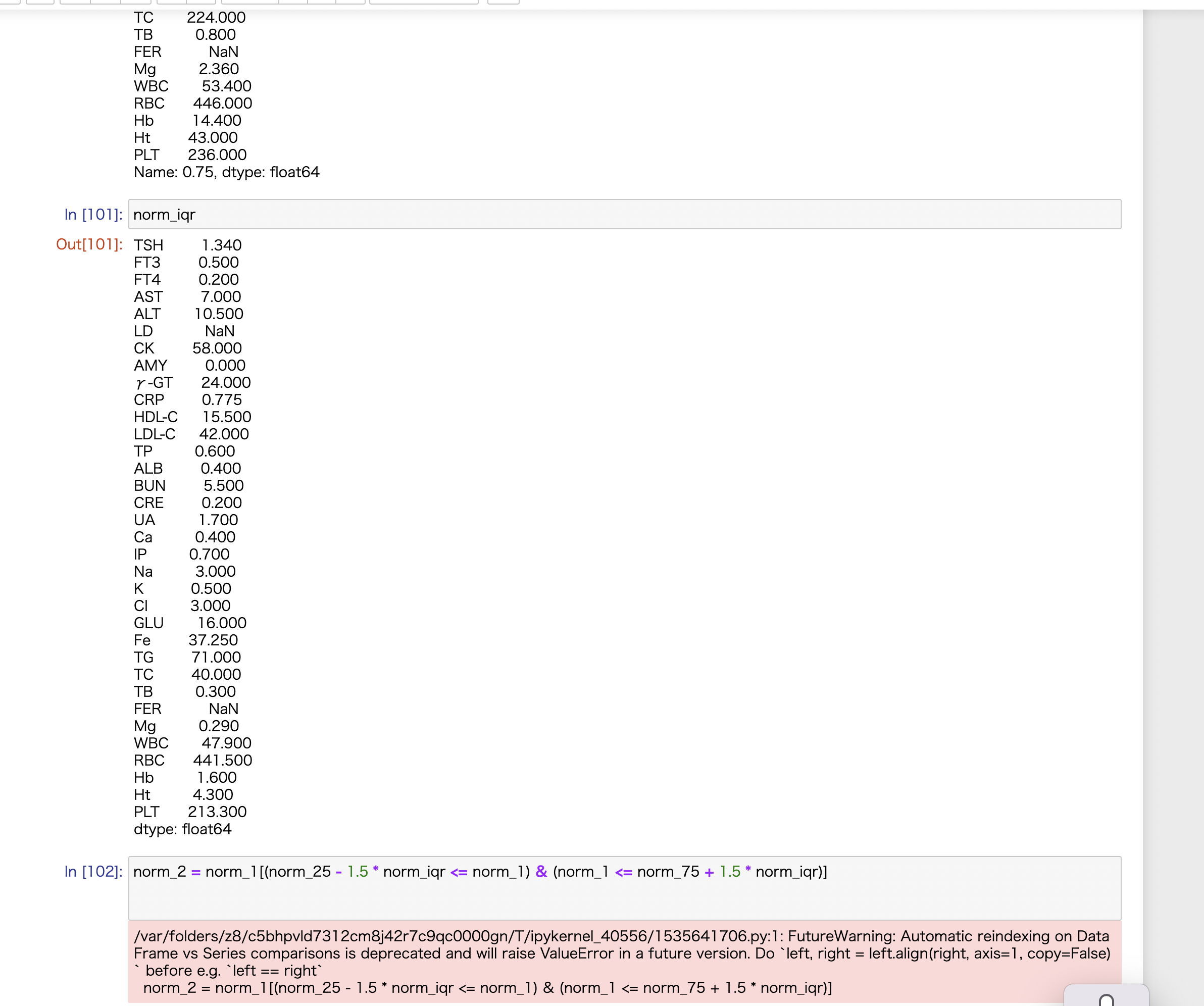
第1四分位数(norm_25)、第3四分位数(norm_75)、第3-第1四分位数(norm_iqr)などの抽出はかかるのですが、
いざ、外れ値を除外しようとするとできません。
以前(2年くらい前)は、このコードで除外できていたのですが・・・
色々ネットで調べたりしたのですが分かりません。
どなたか詳しい方いらっしゃいませんでしょうか?
発生している問題・エラー
``
エラーというかこのようなメッセージが表示されます。
/var/folders/z8/c5bhpvld7312cm8j42r7c9qc0000gn/T/ipykernel_40556/1535641706.py:1: FutureWarning: Automatic reindexing on DataFrame vs Series comparisons is deprecated and will raise ValueError in a future version. Do `left, right = left.align(right, axis=1, copy=False)` before e.g. `left == right`
norm_2 = norm_1[(norm_25 - 1.5 * norm_iqr <= norm_1) & (norm_1 <= norm_75 + 1.5 * norm_iqr)]
または、問題・エラーが起きている画像をここにドラッグアンドドロップ
0 likes