はじめに
今回は、「畳み込みニューラルネットワーク」を実装していきます。
ディープラーニングや畳み込みニューラルネットワークの基本については、下記の記事を参照してください。
🌟基本となるディープラーニングについて
https://qiita.com/hara_tatsu/items/c0e59b388823769f9704
🌟ディープラーニングの実装及び過学習対策
https://qiita.com/hara_tatsu/items/b7423e90574cf7730978
🌟「畳み込みニューラルネットワーク(CNN)まとめ」
https://qiita.com/hara_tatsu/items/8dcd0a339ad2f67932e7
畳み込みニューラルネットワークを実装する
今回は題材として、「【SIGNATE】画像ラベリング(10種類)」を使います。
https://signate.jp/competitions/133
画像データに映っているものを10種類のラベルから分類するものです。
データの前処理
必要なライブラリーをインポート
import numpy as np
import pandas as pd
from PIL import Image
import glob
目的変数と説明変数の処理
目的変数を読み込んでダミー変数へ変換
train_Y = pd.read_csv('train_master.tsv', delimiter='\t')
train_Y = train_Y.drop('file_name', axis=1)
# カテゴリー変数へ変換
from tensorflow.keras.utils import to_categorical
Y = to_categorical(train_Y)
print(Y.shape)
print(Y[:5])
(5000, 10)
array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], dtype=float32)
説明変数(画像データ)は、「glob」を使って読み込めるが画像データの並びがバラバラに読み込まれてしまう。そのため、読み込み後に小さい数字の順番に並び替える。
train_file = glob.glob('train_images/t*')
# 0埋めでない数値を小さい順に並び替える関数
import re
from collections import OrderedDict
def sortedStringList(array=[]):
sortDict=OrderedDict()
for splitList in array:
sortDict.update({splitList:[int(x) for x in re.split("(\d+)",splitList)if bool(re.match("\d*",x).group())]})
return [sortObjKey for sortObjKey,sortObjValue in sorted(sortDict.items(), key=lambda x:x[1])]
# 小さい順に並び替え
sort_file = sortedStringList(train_file)
print(sort_file[:5])
['train_images/train_0.jpg',
'train_images/train_1.jpg',
'train_images/train_2.jpg',
'train_images/train_3.jpg',
'train_images/train_4.jpg']
説明変数(画像データ)の前処理
現在は、「glob」で画像データのファイル名を取得している状態。
PIL形式で読み込み後にnumpy化及び正規化をする。
※画像データは「0〜255」までの数値の集まり。そのため、全体を「255.0」で割ることで、「0〜1」までの数値の集まりに変換する。
(✅ディープラーニングは、データの数値の幅が大きいと学習がうまくいかない)
from tensorflow.keras.preprocessing.image import load_img, img_to_array, array_to_img
# まずは、1枚で試してみる
train = sort_file[0]
# 画像ファイルからPIL形式で読み込み
train = load_img(train)
# PIL形式からnumpy形式へ + 正規化
train = img_to_array(train) / 255.0
print(train.shape)
(96, 96, 3)
# 画像表示
plt.imshow(train)

全ての画像を一括で処理。
※※CPU環境では学習に時間がかかる場合があるため、「image = load_img(image, target_size = (32, 32)) 」とすれば画像サイズを小さくできるので計算時間が減る。(予測精度は悪くなる可能性あり)
X = []
for image in sort_file:
# 画像ファイルのPIL形式で読み込み
image = load_img(image)
#image = load_img(image, target_size = (32, 32)) 学習時間を短縮したい場合
# PIL形式からnumpy形式へ + 正規化
image = img_to_array(image) / 255.0
# データをリストへ格納
X.append(image)
# Xはリスト型のためnumpy型へ変換
X_np = np.array(X)
print(X_np.shape)
print(X_np.dtype)
print(X_np[0])
(5000, 96, 96, 3)
float32
[[[0.57254905 0.5529412 0.42745098]
[0.5764706 0.5568628 0.43137255]
[0.5803922 0.56078434 0.43529412]
[0.6509804 0.627451 0.49411765]
[0.64705884 0.62352943 0.49019608]
...
[0.6431373 0.61960787 0.4862745 ]]
[[0.57254905 0.5529412 0.42745098]
[0.57254905 0.5529412 0.42745098]
[0.5764706 0.5568628 0.43137255]
...
[0.5568628 0.4862745 0.43137255]]]
学習用データ、検証用データ、テストデータへ分割
# データの分割
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X_np, Y, test_size=0.2, random_state=0)
X_train, X_valid, Y_train, Y_valid = train_test_split(X_train, Y_train, test_size=0.2, random_state=0)
# 形状を確認
print("Y_train=", Y_train.shape, ", X_train=", X_train.shape)
print("Y_valid=", Y_valid.shape, ", X_valid=", X_valid.shape)
print("Y_test=", Y_test.shape, ", X_test=", X_test.shape)
Y_train= (3200, 10) , X_train= (3200, 96, 96, 3)
Y_valid= (800, 10) , X_valid= (800, 96, 96, 3)
Y_test= (1000, 10) , X_test= (1000, 96, 96, 3)
畳み込みニューラルネットワークモデルの構築
最初は単純なモデルで精度を確認する。
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation, Conv2D, Flatten, MaxPooling2D
# モデルの初期化
model = keras.Sequential()
# 入力層and畳み込み層
model.add(Conv2D(32, # フィルター数
kernel_size= 3, # フィルターのサイズ(3×3)
input_shape=(96, 96, 3,), # 入力データ(画像)のサイズ
padding="same", #ゼロパディング(画像サイズを小さくしない)
activation="relu" #活性化関数
))
# プーリング層
model.add(MaxPooling2D())
# 1次元に変換
model.add(Flatten())
# 全結合層
model.add(Dense(128, activation="relu"))
# 出力層
model.add(Dense(10, activation='softmax'))
# モデルの構築
model.compile(optimizer = "rmsprop", #誤差逆伝播
loss='categorical_crossentropy', #損失関数
metrics=['accuracy'] #訓練時に監視する指標
)
# モデルの表示
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_12 (Conv2D) (None, 96, 96, 32) 896
_________________________________________________________________
max_pooling2d_12 (MaxPooling (None, 48, 48, 32) 0
_________________________________________________________________
flatten_8 (Flatten) (None, 73728) 0
_________________________________________________________________
dense_17 (Dense) (None, 128) 9437312
_________________________________________________________________
dense_18 (Dense) (None, 10) 1290
=================================================================
Total params: 9,439,498
Trainable params: 9,439,498
Non-trainable params: 0
_________________________________________________________________
# EarlyStopping用
from tensorflow.keras import regularizers
%%time
# 学習の実施
log = model.fit(X_train, Y_train, #学習用データ
epochs=5000, #繰り返し計算する回数
batch_size=64, #ミニバッチ勾配降下法で分割するデータのかたまり
verbose=True, #計算過程を表示
#過学習していると判断したら学習を止める
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値
min_delta=0, #改善とみなされる最小の量
patience=30, #設定したエポック数改善がないと終了
verbose=1,
mode='auto' #監視する値が増減どうなったら終了か自動で推定
)],
validation_data=(X_valid, Y_valid) #検証用データ
)
結果の確認①
# テスト用データ(Y_test)をダミー変数から通常の数値へ復元
Y_test_ = np.argmax(Y_test, axis=1)
# モデルでの予測
Y_pred = model.predict_classes(X_test)
# モデルの評価
from sklearn.metrics import classification_report
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.63 0.80 0.70 93
1 0.47 0.44 0.45 100
2 0.72 0.66 0.69 99
3 0.32 0.34 0.33 103
4 0.46 0.50 0.48 117
5 0.23 0.20 0.22 93
6 0.46 0.52 0.49 101
7 0.56 0.36 0.44 110
8 0.62 0.68 0.65 88
9 0.55 0.54 0.55 96
accuracy 0.50 1000
macro avg 0.50 0.50 0.50 1000
weighted avg 0.50 0.50 0.50 1000
正解率50%!!
acc = log.history['accuracy']
val_acc = log.history['val_accuracy']
loss = log.history['loss']
val_loss = log.history['val_loss']
epochs_range = range(37)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.show()

予測精度は低く、早い段階で過学習をしている。
原因として考えられるのは、
✅学習用データが少ないこと。
そこで学習用データの拡張と水増しをしてみる。
学習用データの拡張と水増し
✅学習用データの拡張と水増しが必要な理由
・対象の物体が逆さまや斜めになったデータも学習させることで、応用力をつけさせるため(データの拡張)
・必要な量の学習データが準備できていない(データの水増し)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 学習用データの拡張設定
image_gen = ImageDataGenerator(rotation_range=45, #45°回転
horizontal_flip = True, #左右反転
)
# 拡張データの生成
train_data_gen = image_gen.flow(X_train, Y_train, batch_size = 32, shuffle = False)
# 拡張データを表示する関数
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20,20))
axes = axes.flatten()
for img, ax in zip( images_arr, axes):
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()
augmented_images = [train_data_gen[0][0][0] for i in range(5)]
plotImages(augmented_images)

# 学習用データの状態確認
# 3200 / 32
print(len(train_data_gen))
100
print(type(train_data_gen))
tensorflow.python.keras.preprocessing.image.NumpyArrayIterator
検証用データを学習用データの状態に合わせる
valid_gen = ImageDataGenerator()
valid_data_gen = valid_gen.flow(X_valid, Y_valid, batch_size = 32)
# 800 / 32
print(len(valid_data_gen))
25
print(type(valid_data_gen))
tensorflow.python.keras.preprocessing.image.NumpyArrayIterator
学習用データを拡張して学習
%%time
# 学習の実施
log = model.fit_generator(train_data_gen, #学習用データ
steps_per_epoch = 100,
epochs = 5000, #繰り返し計算する回数
callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値
min_delta=0, #改善とみなされる最小の量
patience=30, #設定したエポック数改善がないと終了
verbose=1,
mode='auto' #監視する値が増減どうなったら終了か自動で推定
)],
validation_data = valid_data_gen, #検証用データ
validation_steps = 25)
結果の確認②
# 予測
Y_pred = model.predict_classes(X_test)
# モデルの評価
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.62 0.86 0.72 93
1 0.38 0.70 0.49 100
2 0.70 0.79 0.74 99
3 0.47 0.19 0.27 103
4 0.74 0.37 0.49 117
5 0.39 0.39 0.39 93
6 0.51 0.56 0.54 101
7 0.49 0.54 0.51 110
8 0.72 0.66 0.69 88
9 0.61 0.43 0.50 96
accuracy 0.54 1000
macro avg 0.56 0.55 0.53 1000
weighted avg 0.56 0.54 0.53 1000
正解率54%!!
acc = log.history['accuracy']
val_acc = log.history['val_accuracy']
loss = log.history['loss']
val_loss = log.history['val_loss']
epochs_range = range(69)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.show()
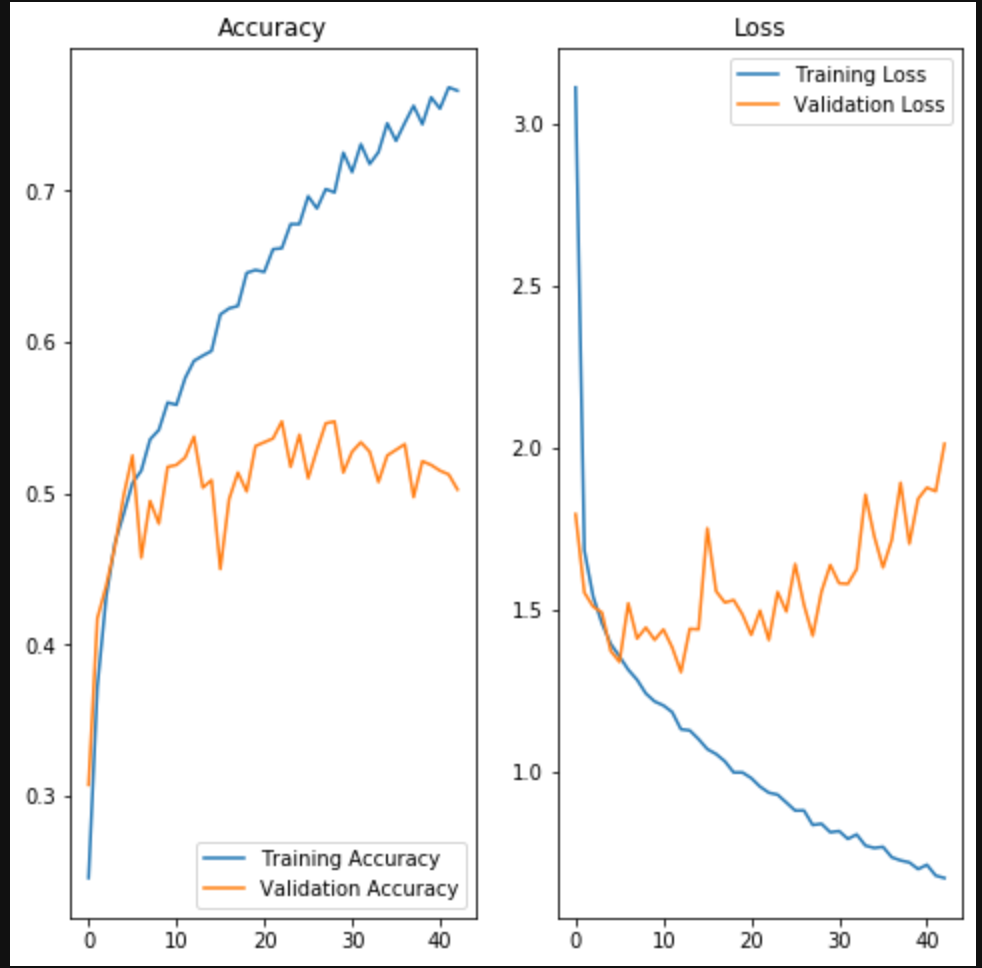
正解率は上昇したもの、まだまだ過学習しています。
最後に、過学習対策を施したモデルを構築します。
過学習対策をしたモデルを構築
from tensorflow.keras.layers import Dropout
# モデルの初期化
model = keras.Sequential()
# 入力層
model.add(Conv2D(
32, kernel_size=3,
input_shape=(96, 96, 3,),
padding="same",
activation="relu",
))
# プーリング層
model.add(MaxPooling2D())
model.add(Dropout(0.25))
# 層のユニットの繰り返し
model.add(Conv2D(64, kernel_size=3, padding="same", activation="relu"))
model.add(MaxPooling2D())
model.add(Dropout(0.25))
# 1次元に変換
model.add(Flatten())
model.add(Dense(128, activation="relu"))
model.add(Dense(64, activation="relu"))
model.add(Dropout(0.5))
# 出力層
model.add(Dense(10, activation='softmax'))
# モデルの構築
model.compile(optimizer = "rmsprop", loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 96, 96, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 48, 48, 32) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 48, 48, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 48, 48, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 24, 24, 64) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 24, 24, 64) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 36864) 0
_________________________________________________________________
dense_7 (Dense) (None, 128) 4718720
_________________________________________________________________
dense_8 (Dense) (None, 64) 8256
_________________________________________________________________
dropout_5 (Dropout) (None, 64) 0
_________________________________________________________________
dense_9 (Dense) (None, 10) 650
=================================================================
Total params: 4,747,018
Trainable params: 4,747,018
Non-trainable params: 0
_________________________________________________________________
%%time
# 学習の実施
log = model.fit_generator(train_data_gen, #学習用データ
steps_per_epoch = 100,
epochs = 5000, #繰り返し計算する回数
callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値
min_delta=0, #改善とみなされる最小の量
patience=30, #設定したエポック数改善がないと終了
verbose=1,
mode='auto' #監視する値が増減どうなったら終了か自動で推定
)],
validation_data = valid_data_gen, #検証用データ
validation_steps = 25)
結果の確認③
# 予測
Y_pred = model.predict_classes(X_test)
# モデルの評価
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.73 0.77 0.75 93
1 0.45 0.59 0.51 100
2 0.87 0.63 0.73 99
3 0.49 0.42 0.45 103
4 0.57 0.59 0.58 117
5 0.38 0.23 0.28 93
6 0.54 0.75 0.63 101
7 0.64 0.42 0.51 110
8 0.69 0.76 0.72 88
9 0.56 0.73 0.63 96
accuracy 0.58 1000
macro avg 0.59 0.59 0.58 1000
weighted avg 0.59 0.58 0.58 1000
正解率58%!!
acc = log.history['accuracy']
val_acc = log.history['val_accuracy']
loss = log.history['loss']
val_loss = log.history['val_loss']
epochs_range = range(69)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.show()
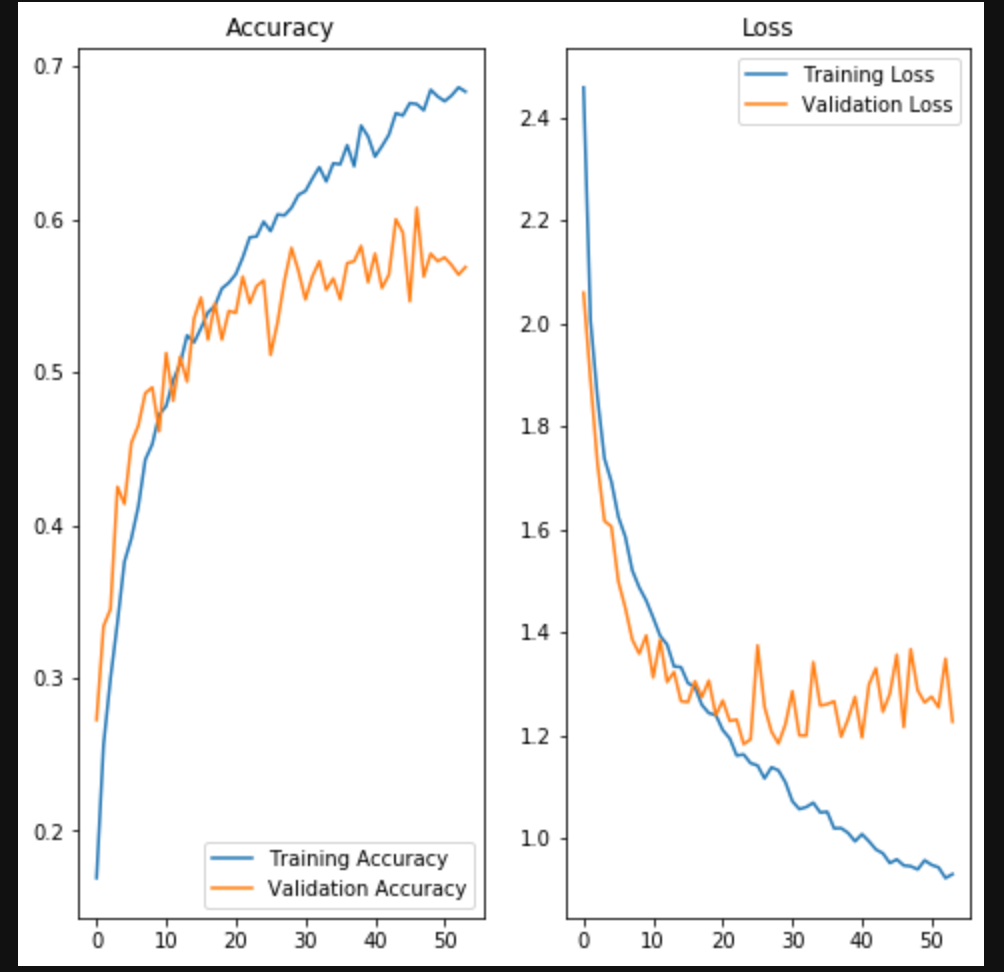
おわりに
正解率はあまり向上しなかったが、いい感じに学習が進んでいるグラフになっている。
さらなる精度向上を目指すなら、
・モデルの構築をより複雑にする
・転移学習
・学習用データをもっと集める