はじめに
最近Microsoft Purviewを触る機会がきたので、試しにS3上のファイルをスキャンしてメタデータを取り込んでみました。
以下のドキュメントを参考に実施しました。
https://learn.microsoft.com/ja-jp/azure/purview/register-scan-amazon-s3
Microsoft Purviewとは
ドキュメントには以下のように記載があります。
Microsoft Purview は、組織がデータ資産全体を管理、保護、管理するのに役立つデータ ガバナンス、リスク、コンプライアンス ソリューションのファミリです
https://learn.microsoft.com/ja-jp/purview/purview
わかりづらいので簡単に説明すると、組織内の複数の場所に分散しているデータの情報(メタデータ)を収集して一元的に管理し、データを統制しながら横断的にデータ活用するための機能を提供しているサービスになります。
今回はその一部の機能であるData Mapを使用して取り込み、Data Catalogで取り込んだメタデータの確認をしていきます。
前提
- Azureアカウント作成済み
- Microsoft Purviewアカウント作成済み
- AWSアカウント作成済み
- CSVファイルをSJISからUTF-8に変換済み
- S3バケットの作成とCSVファイル配置済み(サンプルファイルはこちらを使用)

実施内容
Purivewからのアクセス用にAWS側でIAMロールを作成
AmazonS3ReadOnlyAccessポリシーをアタッチしたazure-purview-access-s3-roleロールを作成します。

信頼ポリシーは以下を設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789123:root"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
}
}
}
]
}
Microsoft側のAWSアカウントIDと外部IDの確認方法
IAMロールの信頼ポリシーにはMicrosoft側のAWSアカウントIDと外部IDを設定する必要があるので、Microsoft Purviewのガバナンスポータルから事前に確認しておきます。

IAMロール作成時のアカウントIDと外部IDの指定
確認したアカウントIDと外部IDをIAMロール作成画面で以下のように設定することで、信頼ポリシーに自動的に設定されます。

Purivewの資格情報へのIAMロールARN値設定
先ほど作成したIAMロールのARN値をMicrosoft Purviewガバナンスポータルの資格情報に登録します。

ソースの登録
資格情報が登録できたらクロール対象のソースを登録していきます。
データマップからソースの登録を押下して、対象のソースの種類を選択します。

次の画面でS3バケットのURL(※パスは含まない)と紐づけるコレクション(グルーピングされたデータの管理単位)を選択して登録を押下します。

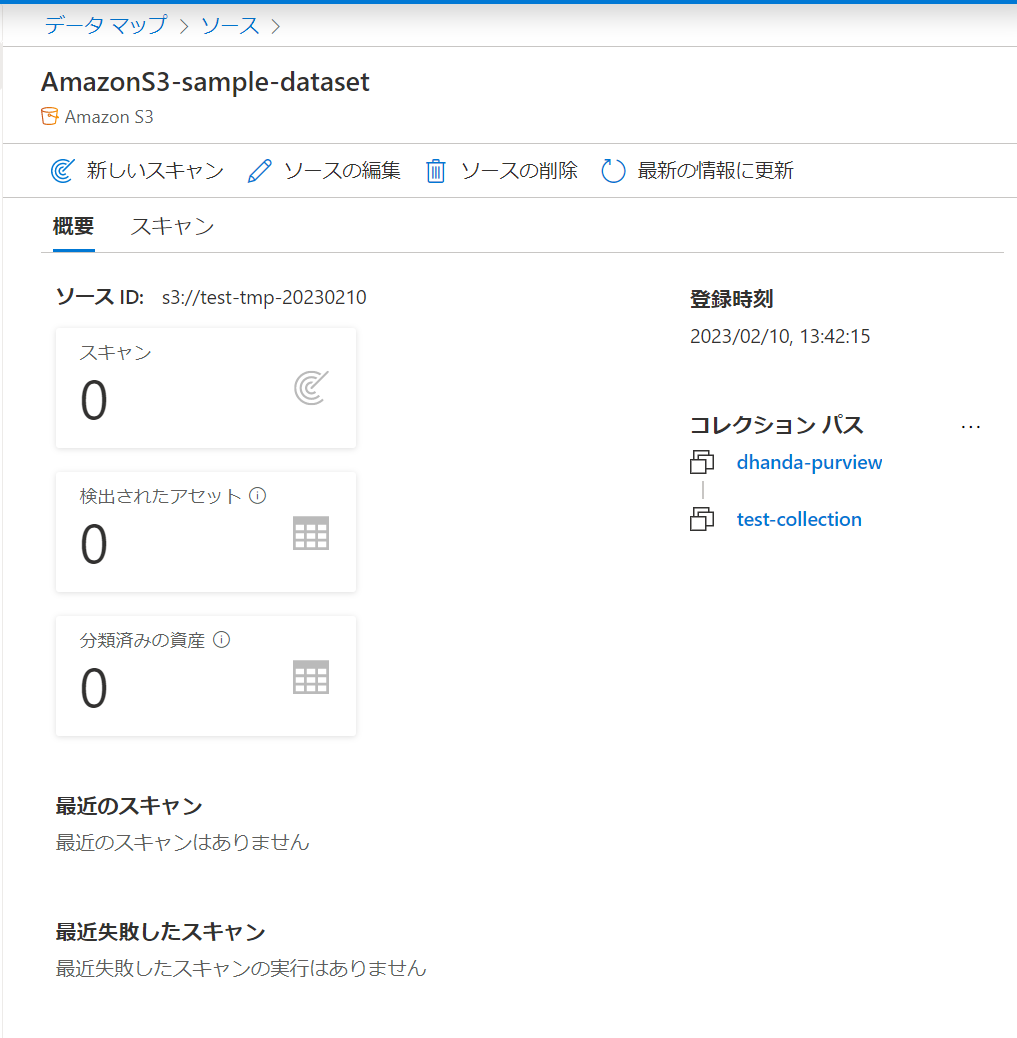
ソースにS3が表示されました。

これだけではスキャンが行われていないため、データソースのメタデータはまだ登録されていません。
ソースのS3の詳細を選択してスキャンを実行していきます。
データソースをスキャン
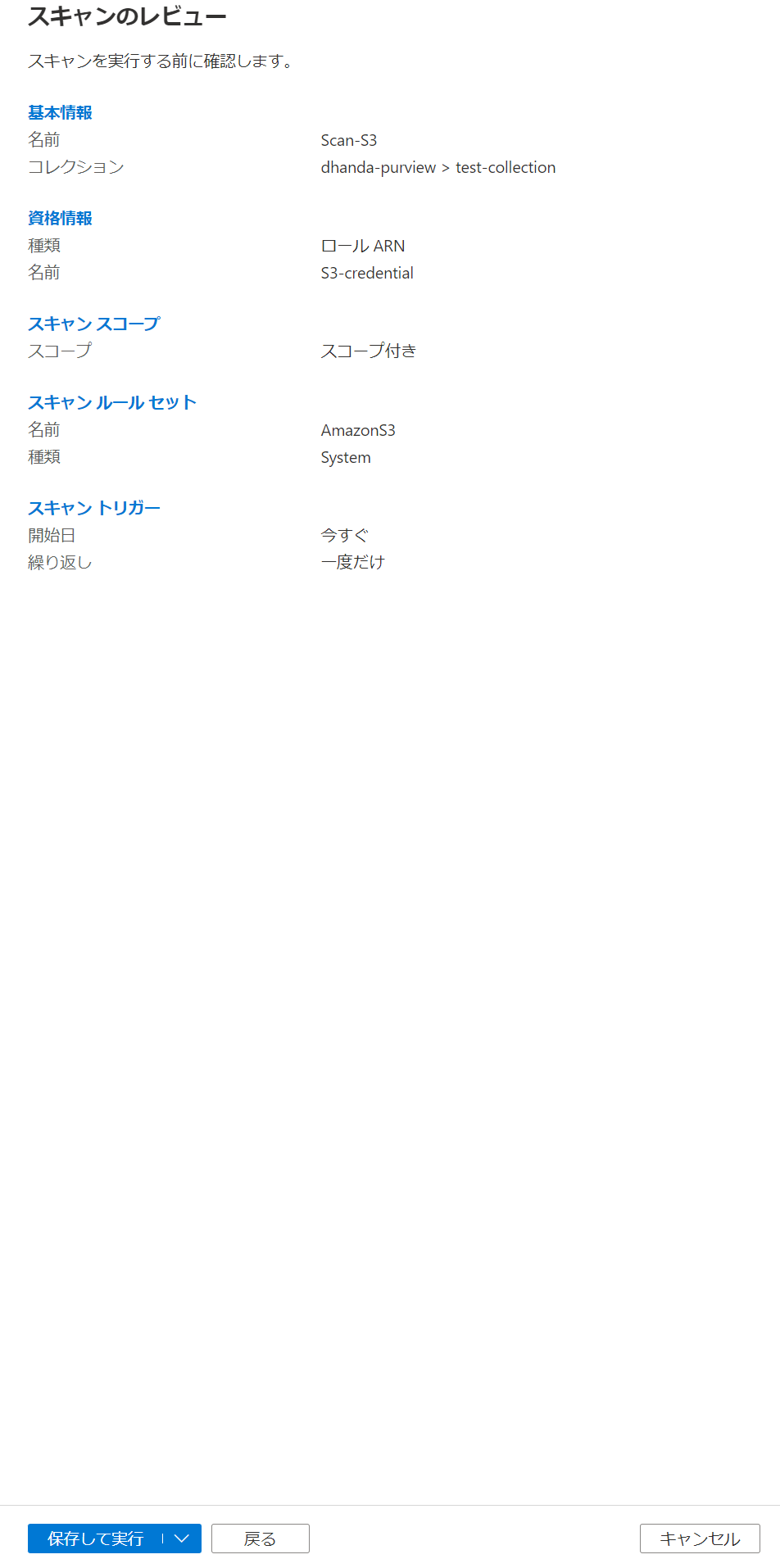
ソースのS3の詳細画面から新しいスキャンを押下して、スキャン名・使用する資格情報・紐づけるコレクション、を選択します。

少し待つとデータソースの構成が表示されるので、スキャンを行う際のスコープを指定します。
今回はutf8変換をしたフォルダ配下のみスキャンしたいので、以下のように設定します。

次にS3上のファイルをスキャンするルールを設定します。
今回はデフォルトで用意されているシステムルールセットにあるAmazonS3ルールを使用します。

AmazonS3のルールセットが既に表示されているので、そのまま次の画面に移動します。

スキャントリガーの設定ですが、今回は繰り返し実行はしないので、一度だけ実行するように設定します。

保存して実行ボタンを押下すると、すぐにスキャンが開始されます。

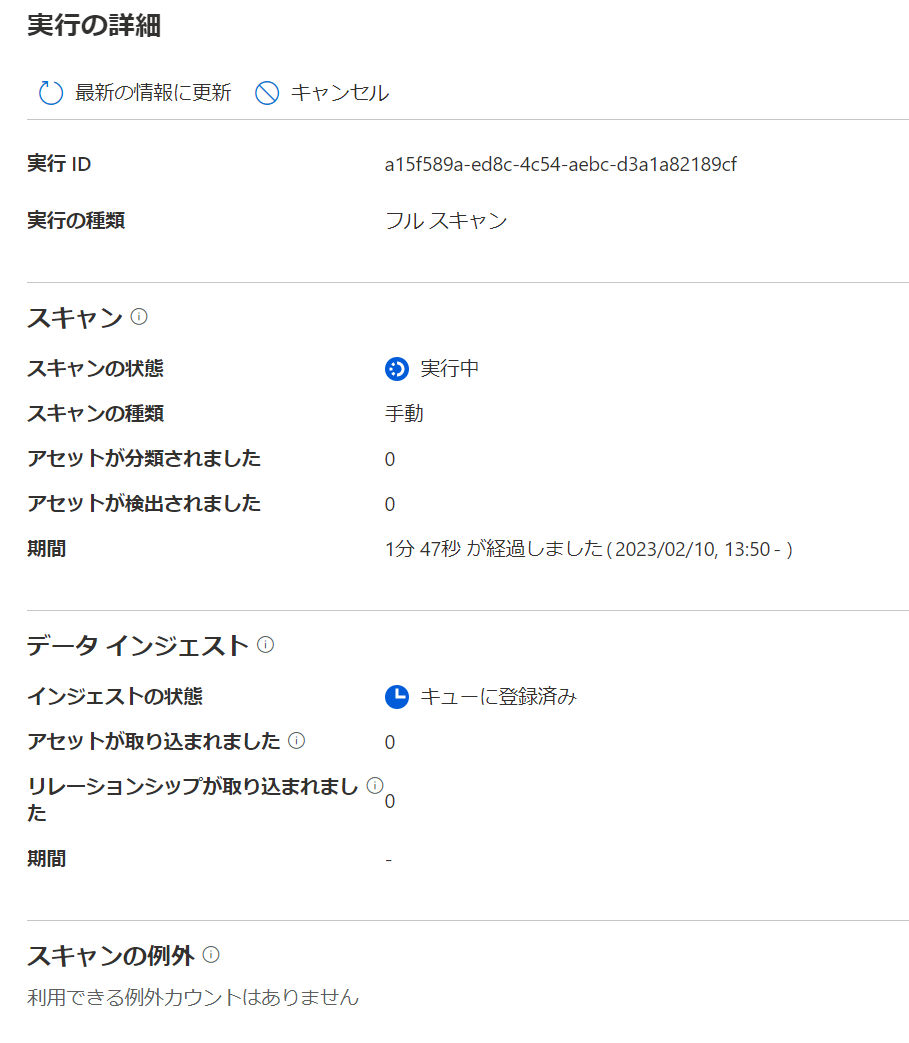
スキャンはキューに登録後、順次実行されていくので、定期的に最新の情報に更新すると処理が開始されたかを確認できます。

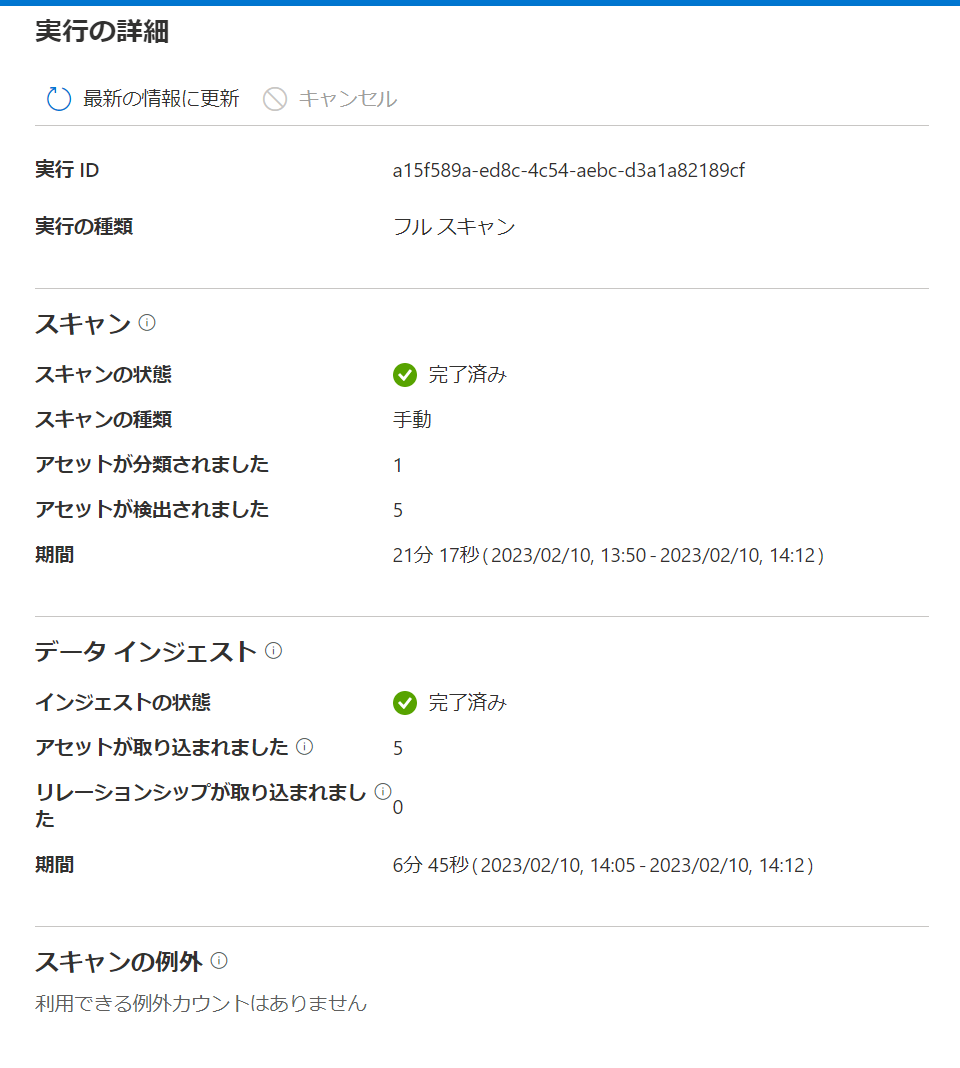
しばらくしたらスキャンが完了しました。
そこまでデータサイズはないはずですが、思ったよりもかかりました。
スキャン後データ確認
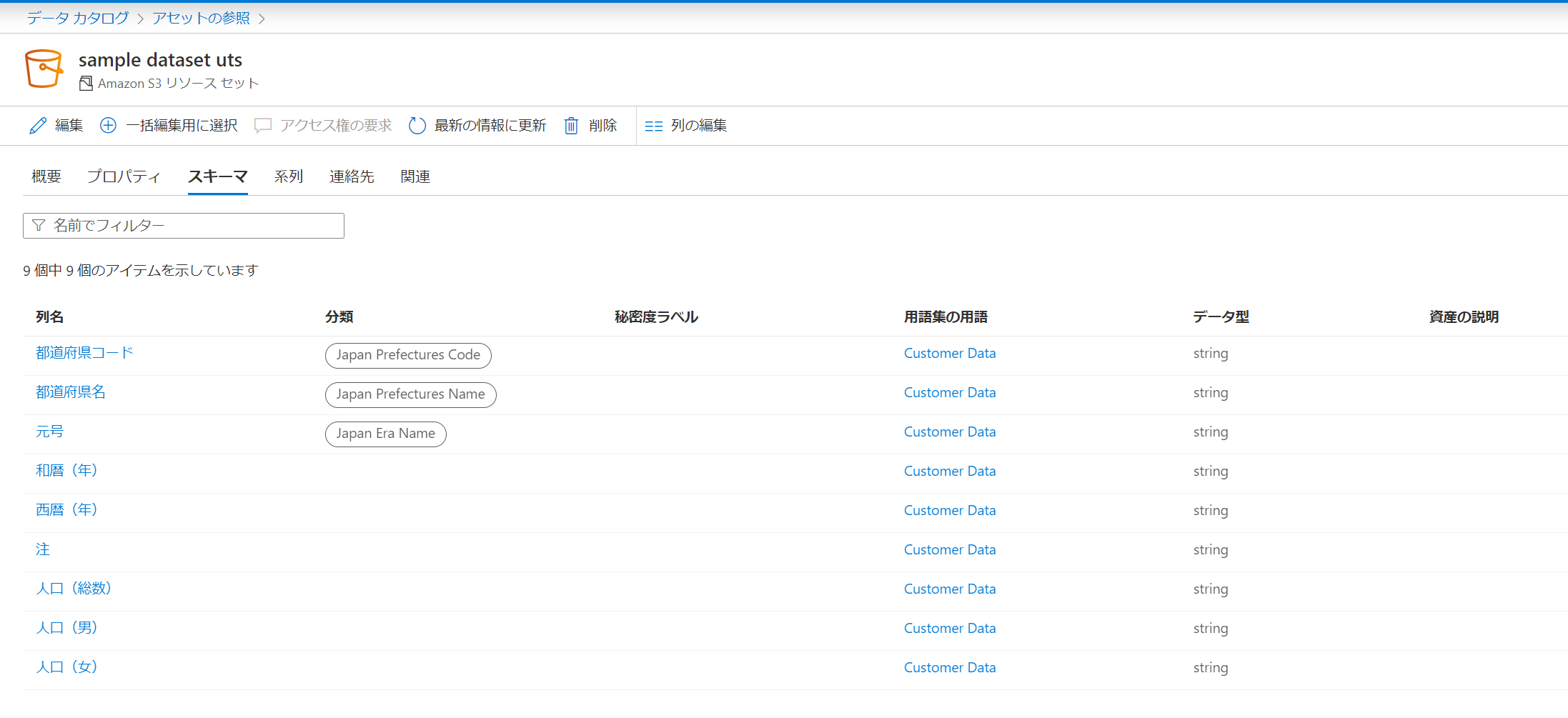
ガバナンスポータルのデータカタログから登録されたメタデータを確認することができます。
特に指定はしていなかったですが、CSVファイル名からアンダースコアと数値を除いた英語部分がリソースセットの名前になっていました。

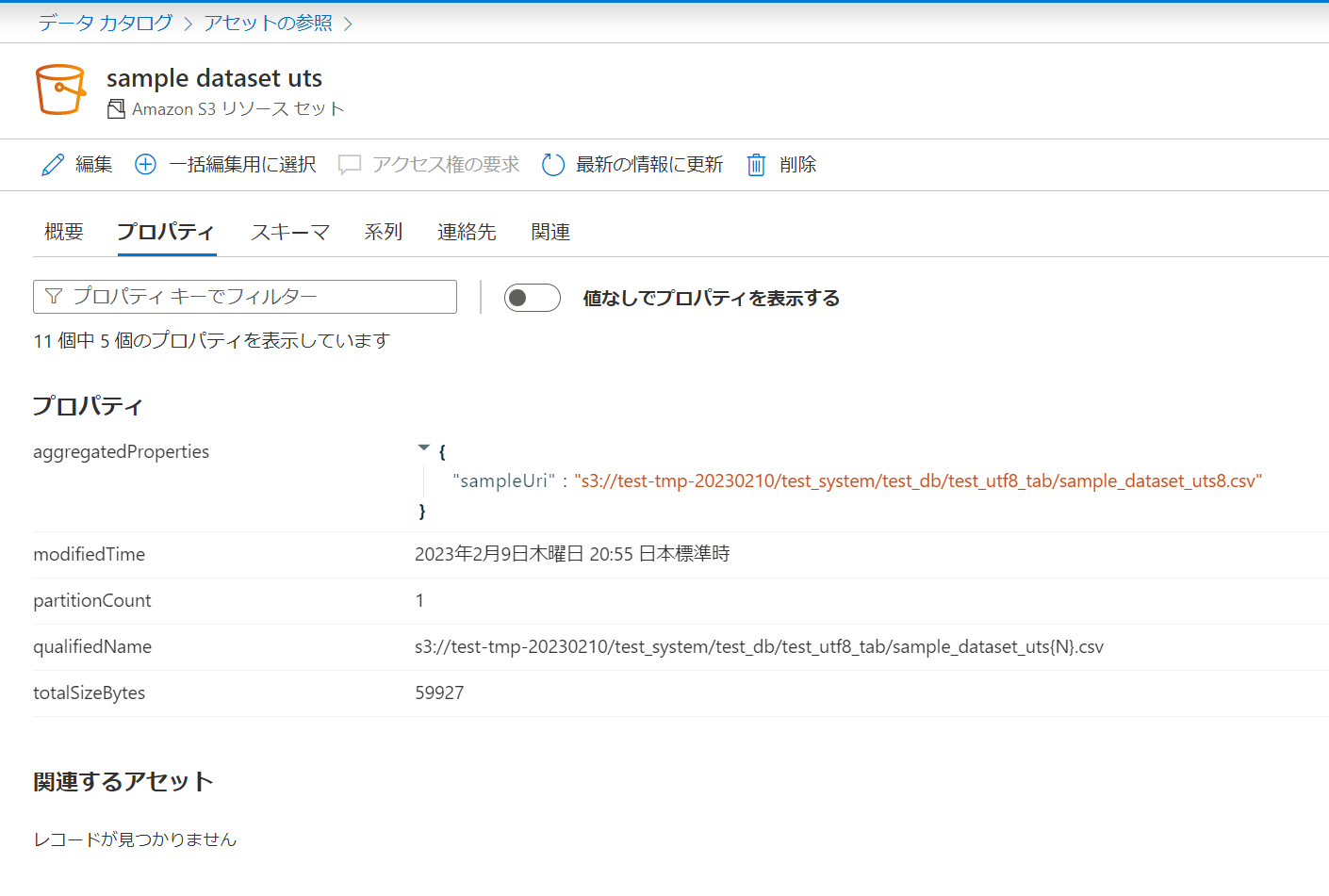
CSVに含まれていたスキーマも登録されていますし、プロパティにはファイルサイズや取得元のデータソースの情報が登録されていました。
おまけ
せっかくデータソースをS3にしているので、Glueからもクロールしてみました。
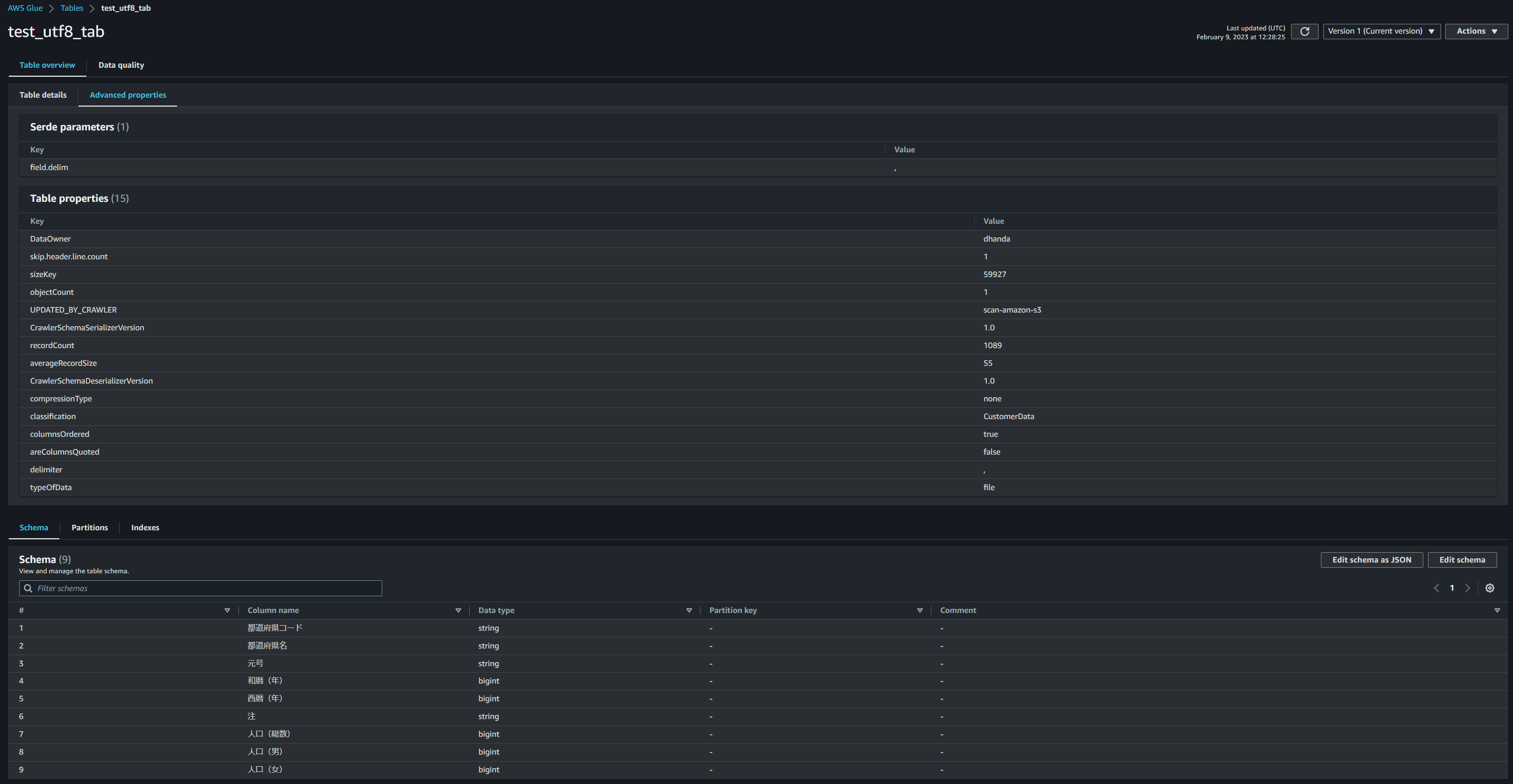
スキャン時間は1分かからず終わって、Glue Data Catalogには以下のように登録されていました。
Azure側ではすべてのカラムのデータ型がstringになっていましたが、AWSでは一部のカラムのデータ型がbigintとして登録されていました。
この辺りの違いはサービスの裏側で使用されている仕組みの問題か、データソースと同じクラウドサービスを利用しているからなのか、どちらもありそうです。
こう見比べてみると、Azure側はデータ統制するためにGUI上での操作や可視化に特化しているのに対して、GlueはGUIからというよりはシステムから利用されることに特化して設計されてるのが良くわかります。
サービスの目的から違うのだと思いますが、実際に触ってみるとその違いが良くわかるので面白かったです。
おわりに
普段Azureを触る機会はほとんどないので、試しに触ってみる良い機会になりました。
また、他のサービスを触る機会があれば書いてみようと思います。