はじめに
実案件でDynamoDBを使ったので、「基本的な話」と、「注意スべき点」についてまとめておく。(個人的な集大成的なドキュメント)
自己解釈も大いに含まれている&わかりやすさ優先で記載しているので、あまり正確でない記述もあります。
ちゃんと最新の公式ドキュメントを読んでくださいね。
基本的な話
公式の開発ガイドも一通り読みましたが、Black Beltの資料が一番わかりやすかったので、それを抜粋しながら説明します。
ちゃんとした内容は最新の公式ドキュメントを読んでください。
引用資料
DynamoDBの概要がわかる資料 - AWS Black Belt Online Seminar 2017 Amazon DynamoDB
追加機能ついて説明されている資料 - AWS Black Belt Online Seminar 2018 Amazon DynamoDB Advanced Design Pattern
基本的な特徴
ポイント
- マネージド型:いわゆる機械運用的なことはAWS側がやってくれる。具体的にはパッチ適用とか。利用者としては楽ちん。ただしブラックボックスになりがちで、自由度は低くなりがち。
- NoSQL:NoSQLもいろいろあるけど、DynamoDBはいわゆるKVS(Key Value Store)。キーと値という、連想配列みたいな構造になっている。DBだけでは、キーでしか検索できないし、テーブル間結合もできない。アプリで補ってあげる必要がある。
- 低レイテンシー:レスポンスが早い!ただし、RDBMSと異なりコネクションは都度貼る形となるため、DBリクエストが多くなるような使い方はダサい。
高可用性
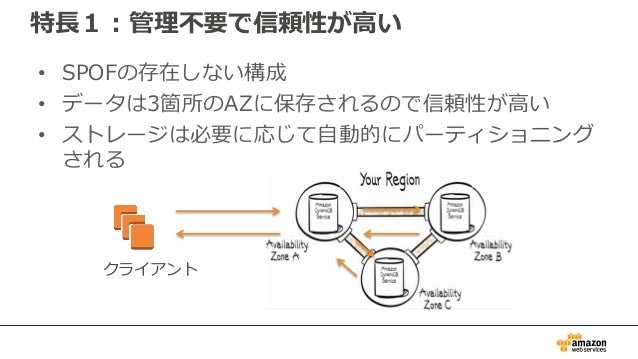
2018update
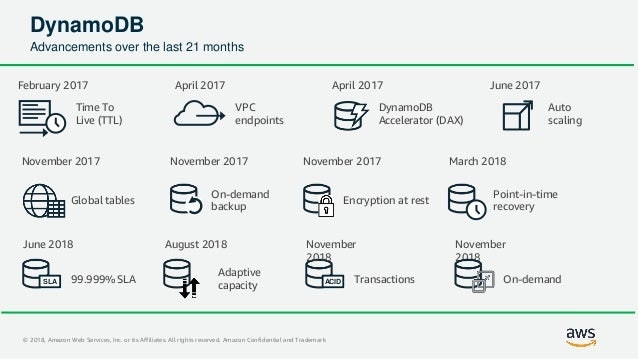
ポイント
- 分散DB:3つのAZ(アベイラビリティゾーン:要はデータセンター)を跨いでいるので、安心。
- SLA:99.999%(グローバルテーブルの場合)
- グローバルテーブル:AZ跨ぎじゃなくてリージョン(要は国)を跨げる機能。テーブルを作る時に指定する。途中で変更できない。
整合性モデル

ポイント
- 読み取り整合性は二種類ある。
- 「結果整合性」と、「強力な整合性」。
- デフォルトは、「結果整合性」。
- 読み取り整合性は、読み取り系APIでDyanmoDBにアクセスするときのオプションとして指定する。
- 何も指定しないと「結果整合性」が選択される。
- テーブル毎に指定するわけではなく、API呼び出しごとに指定することになる。
- 結果整合性:書き込み直後に読み取ると、古いデータが取れるかもしれない。
- メカニズムは公開されていないので、DynamoDBのベースであるCassandraの挙動を元に説明する。
- 基本的に書き込みは、3箇所のウチ、2つに書き込めれば終了。
- 残りの1箇所に対しては、しばらくしたらデータがコピーされる。
- そのコピーが完了するまでの間に、最新データが書き込まれていない残りの1箇所に運悪く読み込みに行ってしまうと、古いデータが返ってくる。
- 書き込みが2箇所に対して行われる一方、読み取りは通常、1箇所に対して行われる。
- 読み込みに行く先は、アプリケーションでは制御できない。
- 強力な整合性:書き込み直後の読取りでも、最新データを保証してくれる。
- メカニズムは公開されていないので、DynamoDBのベースであるCassandraの挙動を元に説明する。
- たぶん2箇所見に行って、新しい方のデータ取ってきてるんだと思う。
- その分、「キャパシティユニット」っていうDBアクセスのためのリソースを通常の2倍消費する。
- 要は、2倍、金がかかる。
料金体系

2018update

ポイント
- 「オンデマンドモード」と「プロビジョニングモード」がある。(オンデマンドモードは2018年に追加された)
- 基本的に性能面に差は無い。コスト面だけを考えれば良い。
- オンデマンドモード:従量課金。上限設定ができないので、青天井とも言える。
- パーティション/キャパシティユニットの設計をそこまで厳密に行わなくても良くなるので、少し楽になる。
- オンデマンドモードでもパーティション/キャパシティユニットの使われ方は変わらないので、パーティション/キャパシティユニットなどを意識しておいた方が良い設計であることに変わりはない。
- 上記記事でも触れられているが、設計コストや運用コスト、将来の機能追加なども考えると、圧倒的にオンデマンドモードがオススメ。
- パーティション/キャパシティユニットの設計をそこまで厳密に行わなくても良くなるので、少し楽になる。
- プロビジョニングモード:事前に使用量を予約しておくヤツ。オンデマンドモードより安い。ただ、予約量を超過するとエラーが返ってくる。
- S3のエクスポート/インポートを利用したい場合は、プロビジョニングモードが必要。
- ギリギリを狙うよりは、やや余裕をもって設定するのが基本となる。オートスケールにも対応しているため、ある程度柔軟に設定が可能。
- 参考: AWS Data Pipeline を使用して DynamoDB データをエクスポートおよびインポートする
補足
キャパシティユニットの算出は、32~34スライド目に説明がある。
構成要素
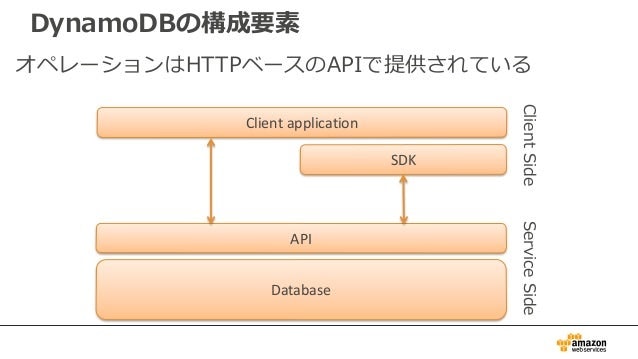
ポイント
- HTTPベースのAPIでアクセス可能。
- 一般的なRDBMSと異なり、都度コネクションを貼ることになる。そのため、アクセスのオーバーヘッド比較的大きいため、アクセス回数を減らすことが求められる。
- KVSという形式であることからも、1回で全てのデータをとってこれるようなテーブル構成が望ましい。
テーブル操作

ポイント
- PutItem:SQLのInsertと近しいが、異なる。Insertはキーが同じレコードが存在したら、登録失敗になる。一方、PutItemはキーが同一のitem:項目が存在したら、上書き。
- Conditionというパラメータで条件を指定できるため、「キーが同一のitem:項目が存在していたらエラー」という指定は可能。(指定しないと、上書き扱いになる。)
- Scan/Query:SQLのSELECTが近いが、異なる。DynamoDBでは「パーティションキー」と「ソートキー」という二種類を「プライマリキー」として利用ができる。Queryで指定できるのはその二種類のみ。それ以外のattributes:属性(RDBMSで言う所のカラム)では、検索できない。
- じゃぁどうすればいいかと言うと、データを全部取ってきて、その後アプリケーションのロジックで絞り込む感じ。
- RDBMSがやっていてくれた部分を、DynamoDBとアプリケーションで協力して実現する感じ。
- 検索画面とかの要件があるなら、RDBMSにレプリケーションして、RDBMSを検索したほうが良いかも。
テーブル設計基礎知識
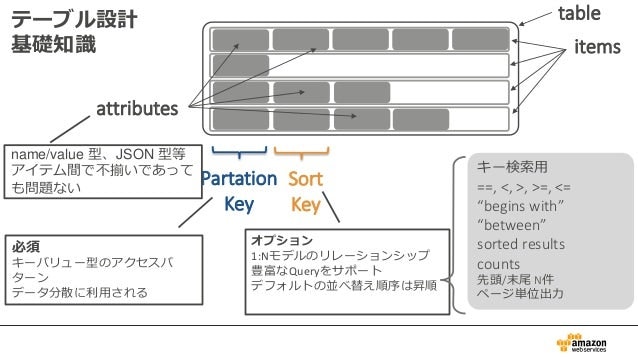
ポイント
RDBMSで言い換えるなら。
- table(テーブル):テーブル。
- items(項目):レコード。
- attributes(属性):カラム。
- Partition Key:プライマリキー。必須。
- Sort Key:プライマリキー。オプション。複合プライマリキーを実現したい時に、Partition Keyと合わせて実現するためのモノ。
パーティション
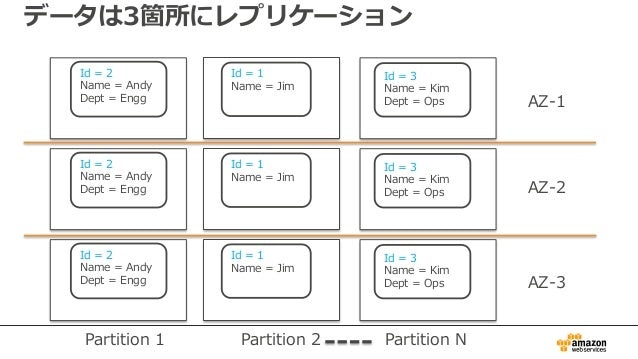
ポイント
- データは、パーティションに分割されて格納される。
- パーティションキーをハッシュ化して、どのパーティションに格納するか決まる。(DynamoDBが勝手に決める)
- パーティション数は、DynamoDBが勝手に決める。以下を元に決めている。
- テーブルのデータサイズ
- キャパシティユニットの数
補足
もう少し細かい話が知りたい場合は、36~45スライド目がオススメ。
Attributes:属性
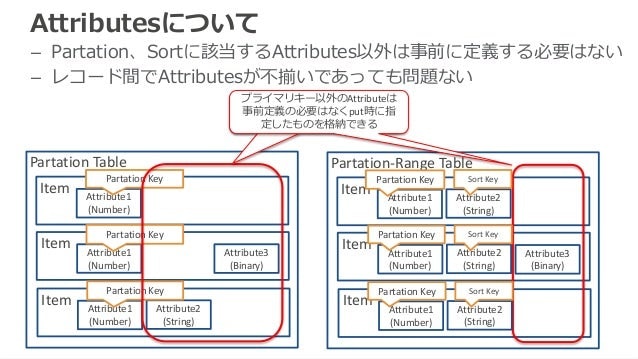
ポイント
- RDBMSと異なり、事前にカラムを定義しておく必要はない。
- item:項目(レコード)毎に、attributes:属性(カラム)が異なっても良い。
- パーティションキーは必須。ソートキーを利用している場合は、ソートキーも必須。
スケーリング

ポイント
- RDBMSだとDB単位でスループット(コネクション数など)を決めていたが、DynamoDBではテーブル単位でスループット(キャパシティユニット)を決める。
- キャパシティユニットは、パーティションで等分されてしまう。そのため、特定のパーティションにアクセスが偏った場合、「テーブル全体で見るとキャパシティユニットは余っているのに、特定のパーティションは枯渇してしまったために、エラーが返される」という現象が発生してしまう。
- バーストキャパシティというセーフティーネット的な機能をAWSが用意してくれているが、これは発生させないことを前提に設計したほうが良い。
LSI:ローカルセカンダリインデックス
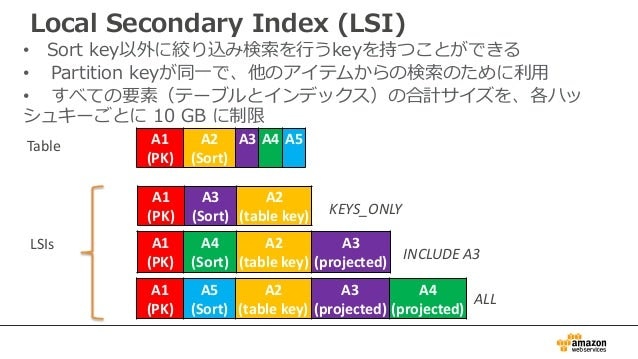
ポイント
- RDBMSのインデックスと同じようなモノ。
- パーティションキーは、元となるテーブルと同じという制約がある。
- ソートキーは、元のテーブルとは異なるものが設定可能。
- 「強力な整合性」が利用できるため、整合性を求める要件の場合でも、利用できる。
GSI:グローバルセカンダリインデックス
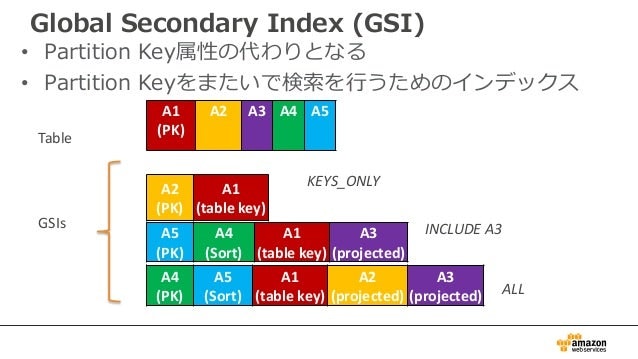
ポイント
- RDBMSのインデックスと同じようなモノ。
- パーティションキーもソートキーも、元のテーブルとは異なるものが設定可能。
- 一方で、「結果整合性」しか利用できない。整合性を求める要件の場合は、こちらは利用不可。
- 感覚的にはLSIよりもGSIの方が使う機会が多いかも。
LSI/GSIを使う際の注意事項

ポイント
- スライドそのまま。
TTL:Time To Live

ポイント
- RDBMSと異なり、TTLという「データ有効期限」が指定できる。
- 有効期限が切れると、自動的にデータが削除されるよ!(データクリーニングバッチとか要らないよ!)
DAX:DynamoDB Accelerator

ポイント
- おまけ機能だよ!
- DAXを使うと、読取りが早くなるよ!(要はキャッシュ)
- 「結果整合性」しか用意してないので、「強力な整合性」を求める場合は使えないよ。
- この記事では深掘りしないので、細かい説明は資料見てね。
DynamoDB Stream

ポイント
- おまけ機能だよ!
- 書き込みとかを検知して、イベントを発火させることができるよ!
- そういう性質上、他のサービスと連携する時に、めちゃくちゃよく使う機能だよ!
- 具体的には、Lambdaとかと連携して、レプリケーション機能とかも実装できるよ!
- この記事では深掘りしないので、細かい説明は資料見てね。
DynamoDB Transactions
2018update

ポイント
- 2018年に追加された機能。
- RDBMS(JDBC)ほどではないが、ある程度のトランザクション制御が可能。
- 詳細を知りたい場合は以下へ。
バックアップ

2018update
ポイント
- バックアップはいくつか手段があるよ。という話。
- なお、2018updateでイントインタイムリカバリがサポートされています。(静止点でのバックアップが可能になった)
注意すること
実際に使ってみて悩んだ部分とか。
一部、上でまとめた内容と重複する。
コンテンツ
- トランザクション制御
- 採番方式
- 強力な整合性
- テーブルとかパーティションキーの設計
- RDS(Aurora)へのレプリケーション
- バックアップ(災害対策)@大阪
トランザクション制御
詳細:DevelopersIOさんのブログ:DynamoDBのトランザクションを試してみた #reinvent
DynamoDBTransactionsという機能が2018年にリリースされたが、RDBMSのトランザクション管理とは異なる。
そもそも、RDBMSでサポートされているようなトランザクション制御は不可能。(「アプリケーションの途中でエラーを出したら、ロールバック!」みたいなやつは、存在しない。)
できること
- 複数のクエリをまとめて発行。(発行タイミングは1回にまとめる)
- 頭から順に発行していき、途中で失敗したらロールバック。
できないこと
- アプリケーションの処理のいろんなところで、発行したクエリをまとめてロールバック。
どうすれば良いか?(案)
- ひとまず書き込み系処理に関しては、アプリケーション処理の最後に回す。
- なおかつ、DynamoDBTransactionsを利用する。
採番方式
詳細:DynamoDB開発ガイド:アトミックカウンタ
詳細:Qiita:ID生成大全
DynamoDBには、シーケンスオブジェクトとか無い。
DB側で採番を実現したいなら、アトミックカウンタを用いましょう。
ただ、あんまりDynamoDBの性質と合わない気がするので、できればアプリケーション内部で採番できる仕組みを利用したほうがいい気がする。
flakeとか。
結果整合性/強力な整合性
※「基本的な話」にも出てきた内容です。
基本的に、DynamoDBは「結果整合性」を基準にしているので、「強力な整合性」を使おうとすると制約が増える。
「結果整合性」は 「データは、すべてのストレージの場所で結果的に整合性が保たれます (通常は 1 秒以内)。」 と記載されています。
ただ、最大時間は記載されていないので、整合性を気にするような業務の場合は、「強力な整合性」が必須になると思います。
「強力な整合性」を使うことで生じるデメリット
- DAXという読取り高速化オプションが利用できない
- グローバルセカンダリインデックスが利用できない(ローカルセカンダリインデックスは使える)
- 金がかかる
テーブルとかパーティションキーの設計
詳細:DynamoDB開発ガイド:パーティションキーの設計
詳細:DynamoDB開発ガイド:ベストプラクティス>時系列データ
基本的な考え方
NoSQLでは、DB側でテーブル間結合ができない。テーブル間結合が必要な場合は、関連するテーブルのデータ全てを持ってきて、アプリ側で結合する必要がある。
そのため、特別な理由がない限り、「アプリケーション:テーブルは、1:1」が理想形である。
アクセス頻度によるテーブルの分割
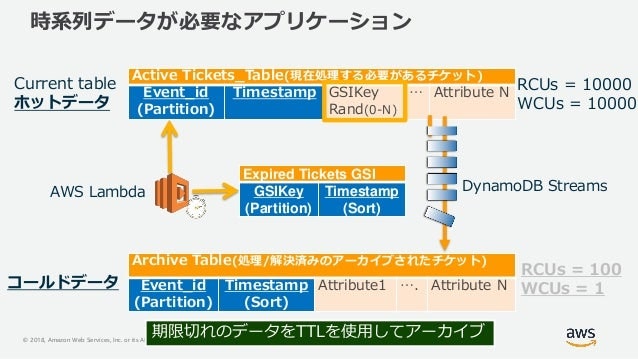
プロビジョニングモードの場合、コスト削減を意識して、アクセス頻度によるテーブル分割が推奨される。
例えば時系列データの場合、直近1日のデータへのアクセス頻度が高くなりがちであるため。
テーブル分割以外にもアクセス頻度の差異を吸収するプラクティスはある。
以下スライドの49~63スライド目に記載あり。
AWS Black Belt Online Seminar 2018 Amazon DynamoDB Advanced Design Pattern
取得データ単位によるテーブルの分割
パーティションキー/ソートキーだけで、期待する取得データ単位が実現出来ない場合、テーブル分割によって実現することを考えても良い気がする。
ただ、上記BlackBelt資料(49~63スライド)にあるような解決策で対応できるなら、そっちのが良いかも?
パーティションキーの設計
アクセスが分散されるようなキーを「パーティションキー」に指定するのが望ましい。
「日付」などは直近の日付にアクセスが集中することが予想されるため、一般的にパーティションキーには向いていない。
「商品ID」などは一般的には向いているが、極端に人気な商品がある場合は、パーティションキーとしては向いてない可能性がある。
ローカル環境での開発
以下を参考にして、ローカル環境をセットアップしましょう。
ただし、本稼働環境でアプリケーションをデプロイする場合、DynamoDB ウェブサービスを使用できるようにコードに微調整を加える必要があります。
基本的にはmavenとかで制御すればできると思いますが、プロジェクトによって、ローカル版を使うかどうかはケースバイケースだと思います。
AWS開発者ガイド - DynamoDB ローカル (ダウンロード可能バージョン) のセットアップ
RDS(Aurora)へのレプリケーション
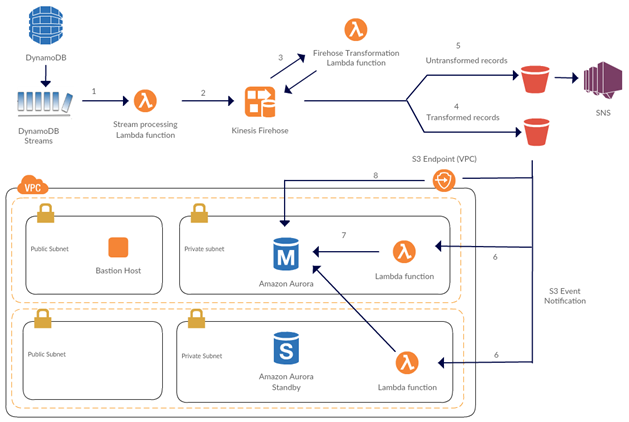
詳細:AWS公式ブログ:Amazon DynamoDB からのデータストリームを AWS Lambda と Amazon Kinesis Firehose を活用して Amazon Aurora に格納する
RDBMSなどとLambdaは相性が悪い!みたいな話は良く聞く。
そこで効くのが「kinesis firehose」。(kinesis Datastreamもあるけど、ここではfirehoseだけ触れる。)
詳細は開発ガイド読んで欲しいですけど、要はキューイングサービスです。(SQSとかSNSとかMQとかと分類は同じ)
「kinesis firehose」と他のサービスで一番違うので、「リクエストをある程度まとめることができる」という点。
60秒間まとめてから放出とかができる。
そうすることで、RDS(Aurora)側のコネクション数を抑えることができます。
SQS-Lambdaなどの組み合わせの場合、コネクションが悩ましいポイントだったりしたんですが、「kinesis firehose」なら大丈夫。
バックアップ(災害対策)@大阪
災害対策のバックアップを考えた時、他のリージョンにもデータを保管しておきましょうという話になります。
感覚的には、グローバルテーブルを使えるならそれに越したことは無いです。
ただ、日本国内縛りとかあると、大阪がグローバルテーブルをサポートしてないので、制限が多くなります。
「Data Pipeline」を用いて、「S3」に連携するのが現時点の選択肢になるかな?と思います。
ただ、その場合、キャパシティーモードを「プロビジョニングモード」にしておく必要があります。
「プロビジョニングモード」の場合、キャパシティの予測が立てられることが前提になってくるため、そうでない業務にはフィットしません。
ポイントインタイムリカバリで別テーブルとしてリストアして、新しく作ったテーブルをプロビジョニングモードにして、Data Pipelineを使えば、「オンデマンドモード」を実現できるかも・・・
さいごに
改めてですが、ちゃんと最新の公式ドキュメントを確認してくださいねー。
RDBMS脳のままだと混乱する話が多いので、DynamoDB脳にちゃんと切り替えて行きましょー。
あ、間違ってるとかあればコメント/編集リクエストなどで教えてくださいー。
以上です。