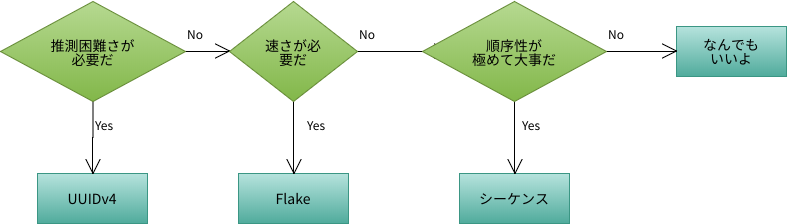
セッションIDやアクセストークン、はたまた業務上で使う一意の識別子など、いろんなところで一意のIDを生成しなきゃいけないケースが存在します。
そこで世間で使われているIDの生成方法について調べてみました。
選択基準
ID生成における要求として、以下の観点が上げられるかと思います。
- 生成の速度
- 大量にデータを短期間で処理し、それらにIDを付与する場合、ID生成そのものがボトルネックとなることがあります。
- 推測困難性
- IDを機密情報と結びつける場合、IDを改ざんされても、機密データが見れないようにできている必要があります。
- 順序性
- 採番した順にデータをソートする必要がある場合は、IDがソートキーとして使えないといけません。
それぞれについて各生成手段を評価します。
ID生成の手段
データベースの採番テーブル
採番用のテーブルを作り、そこで番号をUPDATEしながら取得していくやりかたです。古い基幹システムではよく使われていました。
| 速度 | 推測困難 | 順序 |
|---|---|---|
| × | × | ◎ |
ロックしてSELECT&UPDATEするので、高速に発番するのは不可能ですが、そういった要求がない&シーケンスのないRDBMSであれば採用しても構わないのではないでしょうか。
データベースのシーケンス(またはIDENTITY)
| 速度 | 推測困難 | 順序 |
|---|---|---|
| △ | × | ◎ |
RDBMSの機能として、一意性を保証した連番をふるためのSEQUENCEがあります。
Oracle RACのような分散環境では、ノード間で同期をとるために順序性を保とうとすると、とたんに性能が落ちてしまうので、やはり大量のデータに対して高速に連番をふる用途には適していませんが、性能を多少犠牲にできればデータベースに登録するものにID発行するには一番お手軽な方法ではあります。
UUID version1
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ◎ | × | × |
UUIDは現在バージョン1から5までが規格化されており、一意の識別子の用途でよく使われるのは、タイムスタンプベースのVersion1とランダムベースのVersion4です。バージョン1は以下のように、タイムスタンプとミリ秒ごとの連番、ノード(MACアドレス)から構成されます。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time_low |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time_mid | time_hi_and_version |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|clk_seq_hi_res | clk_seq_low | node (0-1) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| node (2-5) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
残念ながらJava標準でのUUID v1の生成はできませんが、いくつかオープンソースの実装はあります。
https://github.com/groupon/locality-uuid.java
Snowflake
Twitterで使われている(いた?)IDです。
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ◎ | × | ○ |
- 41bit タイムスタンプ
- 10bit マシンID (データセンタID + ワーカーID)
- 12bit シーケンス
Flake
FlakeはErlangで実装されたSnowflakeを128bit長に拡げたようなIDです。
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ◎ | × | ○ |
UUID v1のタイムスタンプでソートできない、タイムスタンプが一般的なUNIXエポックでなく、1582年10月15日からのグレゴリオ暦からのエポックになっていて取っ付きにくい、といったところが改善されています。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time_hi |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time_mid | time_low |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| MAC address (0-3) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| MAC address (4-5) | sequence |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
ULID
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ○ | △ | ○ |
タイムスタンプとランダム値をつなげたものです。したがって、推測困難さもそこそこあって、タイムスタンプ順にソートも可能です。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 32_bit_uint_time_high |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 16_bit_uint_time_low | 16_bit_uint_random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 32_bit_uint_random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 32_bit_uint_random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Firebase PushID
Firebaseで使われているPushIDです。
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ○ | △ | ○ |
全部で120bitで、
- 48bit タイムスタンプ
- 72bit ランダム
で構成されます。ULIDよりもランダムbit数が、ちょっとだけ少なくなっています。
Instagram ID
インスタで使われているID生成です。
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ◎ | × | ○ |
- 41bit タイムスタンプ
- 13bit シャードID
- 10bit ミリ秒ごとの連番
ほぼSnowflakeに近い構成です。
UUID version4
| 速度 | 推測困難 | 順序 |
|---|---|---|
| ○ | ○ | × |
UUIDのバージョン(4bit)とバリアント(2bit)以外の122bitがランダム値で埋められたものです。ランダムによる推測困難性が高いので、セッションIDやアクセストークンの用途でよく利用されます。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| random |0 0 1 0| random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|1 0| random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
よく話題になるIDの衝突可能性ですが、現在人類が扱うデータ量からすれば、まず考えなくてよい程度です。(→ 十分大きな乱数をユニークな識別子として使うのがなぜ安全なのか)
世間のID生成事例
オープンソースのプロダクトたちを見てみると、IDの長さは(デフォルトで)だいたい128bitです。
TomcatのセッションID
while (resultLenBytes < sessionIdLength) {
getRandomBytes(random);
for (int j = 0;
j < random.length && resultLenBytes < sessionIdLength;
j++) {
byte b1 = (byte) ((random[j] & 0xf0) >> 4);
byte b2 = (byte) (random[j] & 0x0f);
if (b1 < 10)
buffer.append((char) ('0' + b1));
else
buffer.append((char) ('A' + (b1 - 10)));
if (b2 < 10)
buffer.append((char) ('0' + b2));
else
buffer.append((char) ('A' + (b2 - 10)));
resultLenBytes++;
}
}
デフォルトでは16バイトずつランダムなcharacterを生成しています。あまり高速性は重要ではないとの意志が感じられます。
JettyのセッションID
id=Long.toString(r0,36)+Long.toString(r1,36);
2つのLongをランダムに生成してつなげ合わせます。
Spring Securityのアクセストークン
DefaultOAuth2AccessToken token = new DefaultOAuth2AccessToken(UUID.randomUUID().toString());
UUID v4をそのまんま使っています。
RackのセッションID
def generate_sid(secure = @sid_secure)
if secure
secure.hex(@sid_length)
else
"%0#{@sid_length}x" % Kernel.rand(2**@sidbits - 1)
end
rescue NotImplementedError
generate_sid(false)
end
secureフラグがtrueなら、/dev/randomが、オフならば/dev/urandomから128bit生成されます。
ID生成の速度比較
実際、各種生成手段によって、どれくらい生成速度に差があるのか簡単なベンチマークをとってみました。SecureRandomはNativePRNGで統一されている(ハズ)
openjdk version "1.8.0_144"
CPU: i7-5500U @ 2.40GHz
Mem: 8086444 kB
Benchmark Mode Cnt Score Error Units
GenIdBenchmark.flake thrpt 20 11043386.675 ± 46283.482 ops/s
GenIdBenchmark.uuidv1 thrpt 20 10250694.091 ± 67545.760 ops/s
GenIdBenchmark.uuidv4 thrpt 20 2096022.751 ± 5687.221 ops/s
GenIdBenchmark.jetty thrpt 20 1164988.060 ± 5680.736 ops/s
GenIdBenchmark.tomcat thrpt 20 684121.048 ± 6194.204 ops/s
Java標準のUUID v4もなかなかのスループットなので、とりあえず順序性が必要ないときは、UUID v4使っとけでも良い気がします。
まとめ
以上まとめると、こんな感じで生成方法決めるとよいのではないでしょうか?