はじめに 
最近は PostgreSQL の EXPLAIN ばかり眺めている @guppy0356 です。
「チューニングの練習をしたいけど、本番 DB は触りたくない」
「検証環境をつくるのもめんどいし、AI に投げられないかな?」
そんなことを考えて、PostgreSQL パフォーマンス検証箱をつくりました。
この記事では、その中身と、Claude にどう手伝わせているかを紹介します。
この記事はこんな人向けです
このあたりに心当たりがある人を想定しています。
- 本番やステージングの PostgreSQL を好き勝手に触れない立場だけど、
パフォーマンス・チューニングの勘所は身につけたい - EXPLAIN / EXPLAIN ANALYZE を、ドキュメントではなく「手を動かしながら」理解したい
- 検証用のテーブル設計やテストデータ作成を、できれば AI に手伝わせたい
- Claude などの LLM を「コード生成」ではなく、「検証プロセス」に組み込みたい
クイックスタート
まずはローカルで PostgreSQL の検証環境を立ち上げて、EXPLAIN を眺められるところまでいきます。
0. リポジトリ
https://github.com/guppy0356/pocquery
1. リポジトリを git clone する
git clone https://github.com/guppy0356/pocquery.git
cd pocquery
2. テストケースを選択してロード
./load-test.sh nested-loop-test
3. データベースをリセットして再起動
選んだテストケースで DB を作り直す。
docker compose down -v
docker compose up -d
4. psql で接続する
docker compose exec postgres psql -U postgres -d pocquery
5. テストケースの README で検証手順を確認
cat init-db-templates/nested-loop-test/README.md
6. EXPLAIN ANALYZE を眺める
EXPLAIN ANALYZE
SELECT u.name, o.order_date, o.amount
FROM users u
INNER JOIN orders o ON u.id = o.user_id
WHERE u.id = 1;
次のように EXPLAIN ANALYZE の結果を確認できます。
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.15..190.86 rows=51 width=226) (actual time=1.310..1.582 rows=1000 loops=1)
-> Index Scan using users_pkey on users u (cost=0.15..8.17 rows=1 width=222) (actual time=0.062..0.068 rows=1 loops=1)
Index Cond: (id = 1)
-> Seq Scan on orders o (cost=0.00..182.19 rows=51 width=12) (actual time=1.244..1.441 rows=1000 loops=1)
Filter: (user_id = 1)
Rows Removed by Filter: 9000
Planning Time: 1.620 ms
Execution Time: 1.963 ms
(8 rows)
7. ステップを進めてクエリが改善することを確認する
CREATE INDEX idx_orders_user_id ON orders(user_id);
EXPLAIN ANALYZE
SELECT u.name, o.order_date, o.amount
FROM users u
INNER JOIN orders o ON u.id = o.user_id
WHERE u.id = 1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=16.18..101.70 rows=1000 width=226) (actual time=0.290..0.696 rows=1000 loops=1)
-> Index Scan using users_pkey on users u (cost=0.15..8.17 rows=1 width=222) (actual time=0.026..0.043 rows=1 loops=1)
Index Cond: (id = 1)
-> Bitmap Heap Scan on orders o (cost=16.04..83.53 rows=1000 width=12) (actual time=0.256..0.478 rows=1000 loops=1)
Recheck Cond: (user_id = 1)
Heap Blocks: exact=6
-> Bitmap Index Scan on idx_orders_user_id (cost=0.00..15.79 rows=1000 width=0) (actual time=0.155..0.155 rows=1000 loops=1)
Index Cond: (user_id = 1)
Planning Time: 2.935 ms
Execution Time: 0.868 ms
(10 rows)
README の中は段階的にクエリの改善がわかるようになっています。
ステップ1: インデックスなしの状態を確認
ステップ2: インデックスを作成
ステップ3: インデックス作成後の性能を確認
インデックス追加前後で EXPLAIN ANALYZE を比較した結果、実行時間が 約2.26倍 高速化することがサクッと確認できました。
ここまでは、人間がテストケースを選んで EXPLAIN を眺める「手動ルート」です。
実際の開発では、Claude の AskUserQuestion ツールを使って
- どんなドメインのデータか
- どれくらいのデータ量か
- どんなクエリパターンを試したいか
を聞き取りしながら test-data.sql を自動生成させています。
そのあたりの「AI にどう任せているか」は、後半で詳しく書きます。
Claude に何を任せているか(AskUserQuestion 編)
AskUserQuestion の役割
- ユーザーのドメイン情報・データ量・検証したいパターンを質問する
- その回答をもとに、ToDo を作成して
test-data.sqlの中身を組み立ててもらう
実際のフロー
- Claude にプロンプトで指示をする
BETWEEN を使った絞り込みでもインデックスが有効であることを確認したい。 - AskUserQuestion から、ドメイン情報、データ量、検証したいパターンが質問として返ってくる
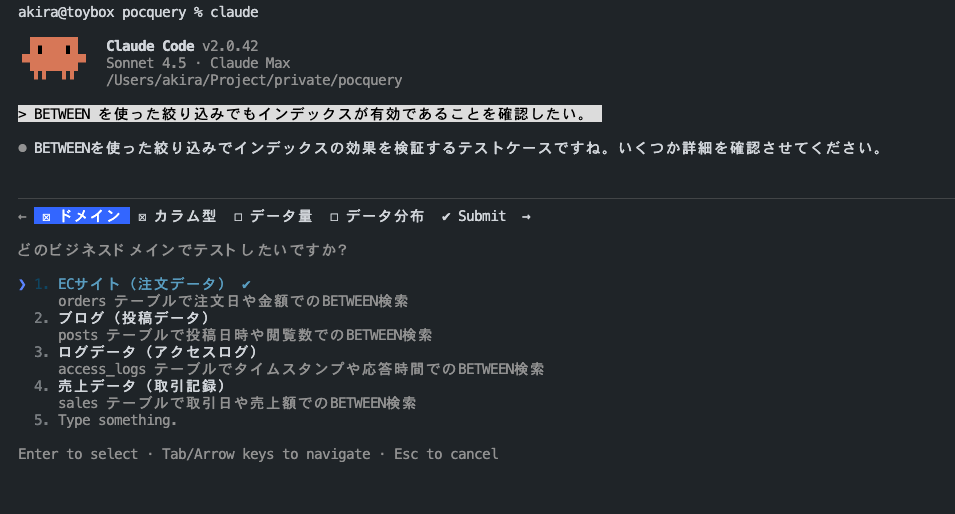
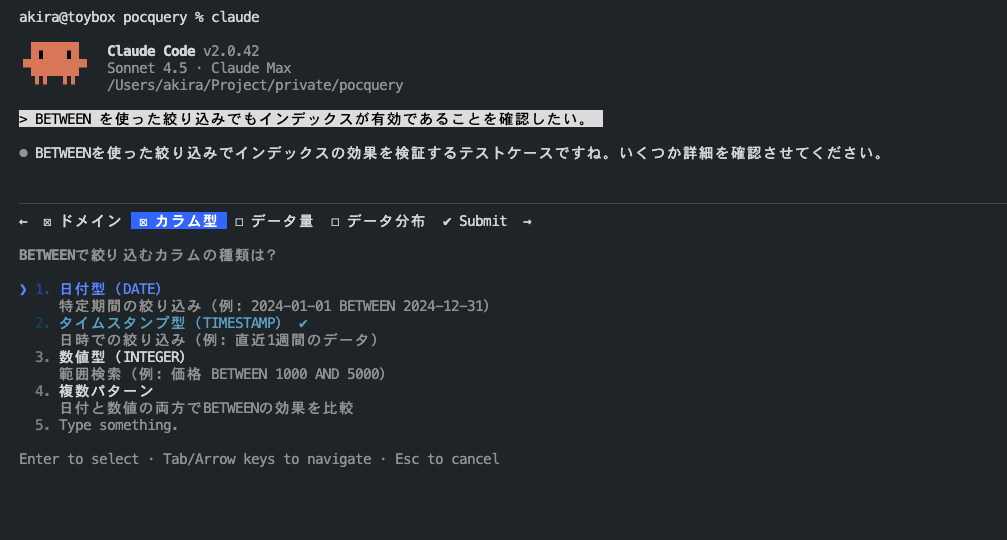
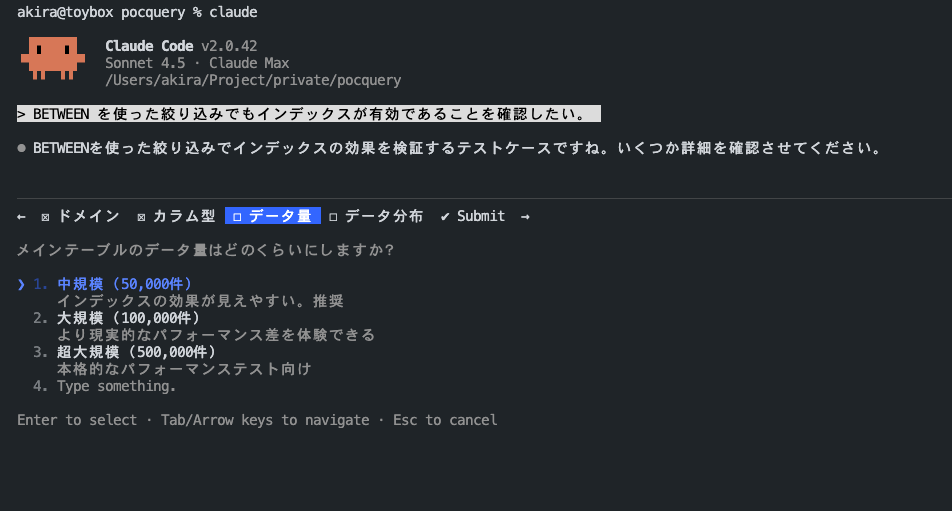

- 回答を埋めると ToDo を作成する

- CLAUDE.md に書いてある方針にしたがって、「悪い状態」と「改善後」の
EXPLAIN ANALYZEを比較し、期待したパフォーマンス特性になっているかを Claude が確認 - 問題なければ、
test-data.sqlと検証手順を書いた README を保存

init-db-templates ディレクトリに検証内容をまとめたディレクトリがあるのでクイックスタートで紹介したとおり次の手順でテストケースを選択して、検証することができます。
./load-test.sh between-index-test
docker compose down -v
docker compose up -d
CLAUDE.md は最初から 800 行じゃない(育て方の話)
いまのリポジトリには 800 行くらいある CLAUDE.md がいますが、
最初からこんなものを書くつもりはありませんでした。
最初はもっと原始的で、「とりあえずプロンプトだけで完結させよう」としていました。
最初の一歩は「とりあえず環境作って」の一文から
いちばん最初に投げていたのは、ほんとうにこれだけです。
ここは SQL のパフォーマンスを検証するリポジトリです。PostgreSQL で動かしたいので Docker で動く環境を作ってください
この一文と、ChatGPT 側のコンテキストだけで
- Docker Compose の定義
- PostgreSQL コンテナ
- 初期化用の SQL
まで一気に作ってもらおうとしていました。
ただ、このやり方だと「毎回その場のノリでコードを生やすだけ」になりがちで、
- テストケースごとに構成がブレる
- 検証用のデータやクエリを、毎回プロンプトにベタ書き
- 一度作ったケースを、別テーマに再利用しづらい
という限界が見えてきました。
Nested Loop を題材にした長文プロンプト時代
次のステップでは、まず Gemini に Nested Loop Join の説明を書いてもらい、
「やっぱりちゃんとしたテーブル定義と実データがほしいな」となったので、
Claude 向けにこんな感じの“シナリオ付きプロンプト”を用意しました。
あなたは SQL パフォーマンス・チューニングの専門家です。
JOIN の実行アルゴリズムである「Nested Loop Join(ネステッドループ結合)」について、
SQL の実行例を使ってステップバイステップで教えてください。
以下の「テストデータ」「対象クエリ」「解決クエリ」を使用して、
パフォーマンスが改善される過程を `EXPLAIN` の結果を比較しながら説明してください。
このあとに続くプロンプトの中では、
-
users/ordersテーブルの DDL & DML - インデックスなしの状態でのクエリ
-
CREATE INDEXを実行したあとのクエリ - 解説で触れてほしいポイント(実行計画の違いなど)
までを全部、1 本の Markdown として書き込んでいました。
これはこれで「1 テーマに集中した記事」を書かせるには便利だったのですが、
実際に使ってみると問題も見えてきます。
- テーマが変わるたびに、この長文プロンプトをゼロから書き換える必要がある
- データ量やドメインが固定されていて、再利用しづらい
- 「悪い状態」「改善後」のパターンが毎回プロンプト依存で揺れる
そこで発想を変えて、「プロンプトの中身をリポジトリ側の構造に逃がす」方向に振りました。
CLAUDE.md とディレクトリ構成に“知識”を逃がす
やったことは大きく 3 つです。
-
テストケースをディレクトリに分割した
-
init-db-templates/nested-loop-test/のように、
テーマごとにディレクトリを切って-
test-data.sql(テーブル定義とデータ) -
README.md(検証手順と学習ポイント)
を置くようにしました。
-
- これで「長文プロンプトにベタ書き」していた内容を、
そのままファイルとしてバージョン管理できるようになりました。
-
-
「どう作るか」のルールを CLAUDE.md 側に寄せた
- さっきの長文プロンプトのうち、
- 「悪い状態から始める」
- 「インデックスを貼って改善を確認する」
- 「EXPLAIN ANALYZE のどこを見てほしいか」
といった“毎回同じことを言っている部分”だけをCLAUDE.mdに切り出しました。
- 代わりに、テーマ固有の部分(Nested Loop/WHERE vs HAVING など)は、
各テストケースの README 側に書くようにしました。
- さっきの長文プロンプトのうち、
-
ドメイン情報のヒアリングを AskUserQuestion にした
- 最初は「EC サイトで〜」「SNS で〜」といったドメイン情報を、
箇条書きの質問をそのままプロンプトに並べて聞いていました。 - 途中からは AskUserQuestion ツールを使って、
- テーマ(検証したいパフォーマンス特性)
- ドメイン(EC / ブログ / SNS など)
- データ量
- データ分布
を選択肢ベースで聞き出すように変えました。
- こうすることで、ユーザーの回答をそのまま
test-data.sqlと README の雛形に落とし込みやすくなりました。
- 最初は「EC サイトで〜」「SNS で〜」といったドメイン情報を、
結果的に、CLAUDE.md は「一発で何でもやってくれる魔法のプロンプト」ではなく、
- リポジトリの構造
- テストケースの設計原則
- AskUserQuestion で集める項目
- 検証時に必ず確認してほしいポイント
をまとめた「AI 用の開発ガイド」に近いものとして育っていきました。
個人的には、
いきなり完璧なプロンプトを書こうとするのではなく、
場当たり的に書いていた指示のうち「毎回言っていること」だけを
少しずつCLAUDE.mdに吸い上げていく
くらいのペースで育てていくのが、LLM 向けドキュメントとは相性がいいと感じています。
動作確認済み環境
- macOS / Apple Silicon
- Docker Desktop 4.38.0 (181591)
- PostgreSQL 15