はじめに
この記事は、初めてトピックモデルを扱いたい人で、とりあえずコピペで動くものを見たい!というような人をターゲットにしています。
かくいう私もまだまだ経験が浅いので、間違っていることが含まれている可能性が高いことも念頭において頂ければ幸いです。
今回の実践は以下の記事通りに実践したものに補足を加えたものになります。この記事でわからないことがあれば、元記事を参照して下さい。
LDAによるトピックモデル with gensim ~ Qiitaのタグからユーザーの嗜好を考える ~
https://qiita.com/shizuma/items/44c016812552ba8a8b88
今回の実践にあたっては、必要なパッケージはすでにインストールされている前提としています。
パッケージがない方は必要に応じてpipコマンド等でインストールして下さい。特にLDAを使うためのgensimは以下のコマンドでインストール出来ます。
$ pip install gensim
ソースコードの修正
今回、上記の記事と同じように試してみました。基本的なソースコードはこちらから取得して下さい。
この記事自体が大分古い記事ですので、少し仕様が変わっているようでした。
具体的には、2つめのファイルの以下の部分を最新にすることで動きました。
target_url = 'https://qiita.com/api/v2/users/' + user[1] + '/following_tags'
tag['name']がtag['id]に変更する必要があります。
また、1000人分を実行するに恐ろしく時間が掛かりそうなのと、APIの上限に引っかかるらしいので、10人分で処理を終えるようにしました。
こちらは2つめのファイルの修正済みのソースコードになります。
import csv, requests, os.path, time
# 先程のユーザーデータを使います。
f = open('qiita_users.csv', 'r')
reader = csv.reader(f)
next(reader)
qiita_tags = []
qiita_user_tags = []
# CSVのユーザーデータの個数を取得します。(1回目は関係なし)
if os.path.isfile('qiita_user_tags.csv'):
user_tag_num = sum(1 for line in open('qiita_user_tags.csv'))
else:
user_tag_num = 0
# CSVのタグデータが既にあればそのタグデータを取得(1回目は関係なし)
if os.path.isfile('qiita_tags.csv'):
f_tag = open('qiita_tags.csv', 'r')
reader_tag = csv.reader(f_tag)
qiita_tags = [tag[0] for tag in reader_tag]
# CSVファイルをオープン
f_tag = open('qiita_tags.csv', 'w')
writer_tag = csv.writer(f_tag, lineterminator='\n')
f_user_tag = open('qiita_user_tags.csv', 'a')
writer_user_tag = csv.writer(f_user_tag, lineterminator='\n')
# ユーザーごとにAPIを叩く
for user in reader:
if int(user[0]) > 10:
break
if user_tag_num < int(user[0]):
target_url = 'https://qiita.com/api/v2/users/' + user[1] + '/following_tags'
print('scraping: ' + user[0] + ', name:' + user[1])
# エラーチェック (リクエスト数のオーバー、ユーザーが存在しないの2点が出る)
try:
result = requests.get(target_url)
except requests.exceptions.HTTPError as e:
print(e)
break
target = result.json()
# リクエスト数オーバーのときは諦める
if 'error' in target:
print(target['error'])
if target['error'] == 'Rate limit exceeded.':
break
continue
# user_id, tag_1, tag_2, ... のようにデータを入れる
qiita_user_tag = [int(user[0])]
for tag in target:
print('tag: ')
print(tag['id'])
if tag['id'] in qiita_tags:
qiita_user_tag.append(qiita_tags.index(tag['id']) + 1)
else:
qiita_tags.append(tag['id'])
tag_num = len(qiita_tags)
qiita_user_tag.append(tag_num)
qiita_user_tags.append(qiita_user_tag)
time.sleep(1) # サーバーに負荷をかけ過ぎないように1秒間隔を空ける
# データをCSVに吐き出す
for tag in qiita_tags:
writer_tag.writerow([tag])
writer_user_tag.writerows(qiita_user_tags)
f_tag.close()
f_user_tag.close()
f.close()
結果について
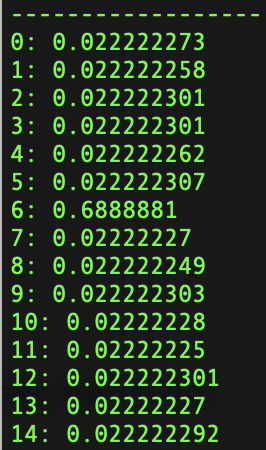
さて、実行すると以下のような結果が得られます。うまく動いたようです。
トピックにGoや機械学習など、最近のワードが多く抽出されており、参考にした記事が作成された2年前と時代の変化を感じます。
行が各トピックを表しています。
要するにユーザーをフォローしているタグで15グループに分類すると、それぞれのグループが重視している単語が分かっているイメージだと思います。
トピック数は3つ目のファイルの以下の行で指定されています。
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, num_topics=15)
解析結果
行がそれぞれのトピックを表し、列は左に行くほど重要であることを表しています。

こちらがタグ1とタグ2をフォローしているユーザーがどのトピックに属しているかを数値化したものですが、こちらは7となっています。