首記ご質問ですが、
ある程度のレベルの方向けに… ていねいな解説記事はこちら
IBM i の日本語言語コードは2つある 2962と2930
言語コードとはOS導入する際の一次言語、二次言語の識別に使われる4桁の数字です。
端的には GO LICPGM コマンドでシステムの言語コードが確認できます。
GO LICPGM OPT.20の導入済み二次言語 を表示させると、
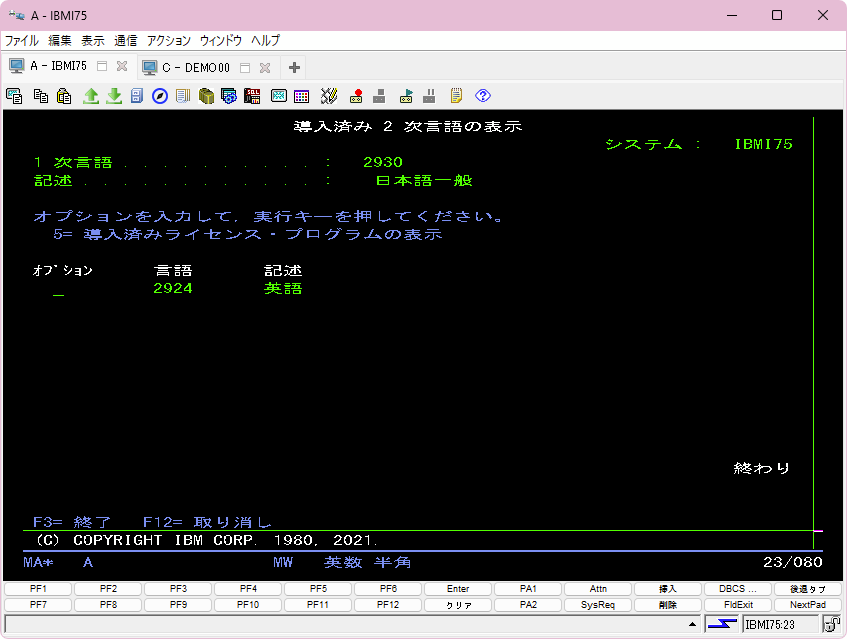
上記のように一次言語 の欄に表示されます。
このシステムは 2930の日本語言語コードが導入されていました。
IBM i 言語コードの一覧
こちらのページに記載があります。
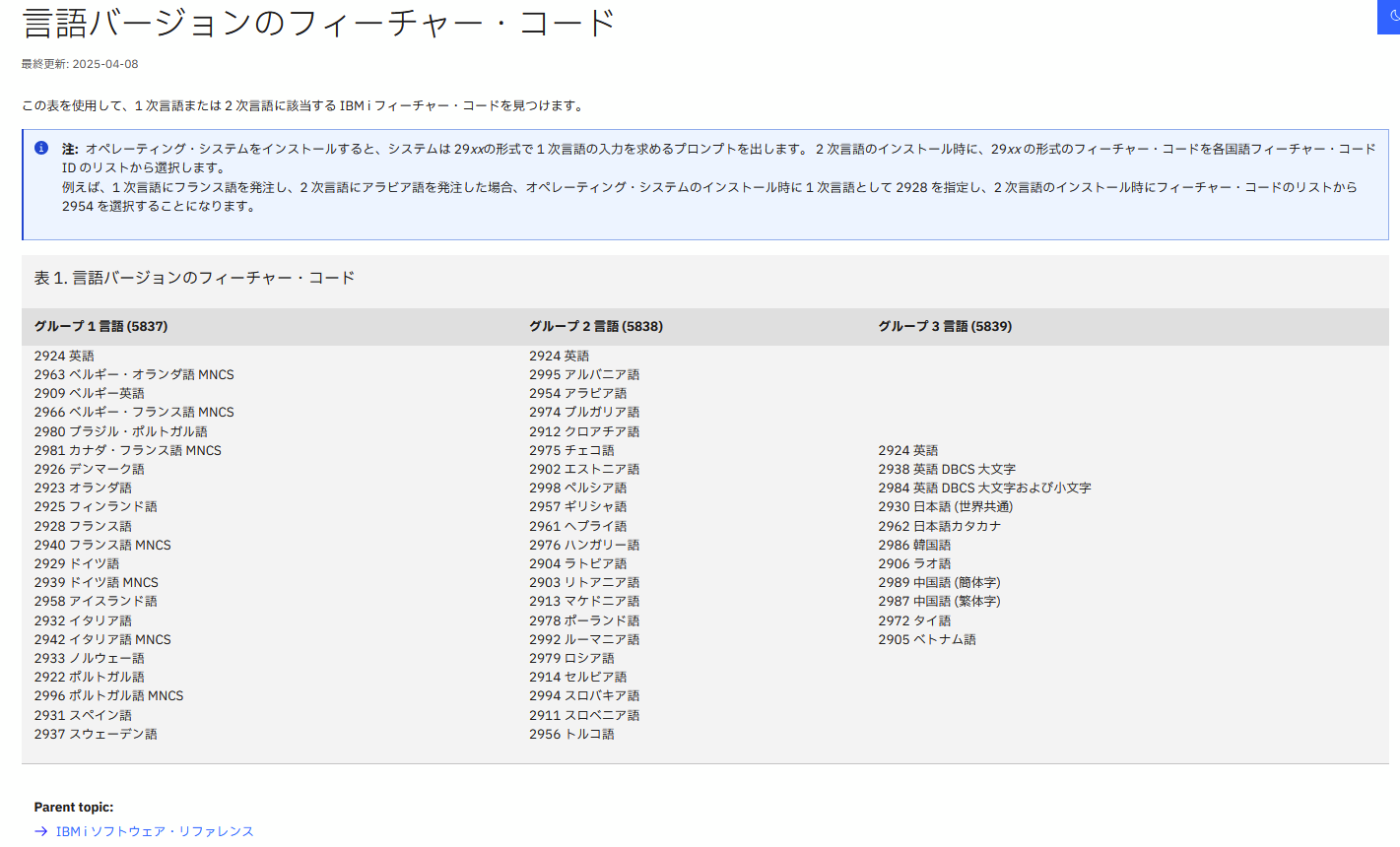
日本語は以下の2つがリストされています。
2930 日本語 (世界共通)
2962 日本語カタカナ
2930 日本語 (世界共通)はCCSID 1399ベース
2962 日本語カタカナはCCSID 5026ベース
と理解してOKです。
日本語の 2962 と 2930 の違い
言語コード2930はOS/400 V5R4から追加された事もあり、2962の言語コードで導入されているシステムの方が依然多いと推察されます。
途中で言語コード変更するにはテスト・検証が必要ですので…
言語コード2962と2930のシステム値デフォルトの相違点
以下のページに記載があります。
各国語バージョンのデフォルト・システム値
QCHRIDのDBCS部分(1027:290)
QCCSID(5026:1399)
Q_LOCALE(JA_JP_5026:JA_JP_1399)
が異なります。
言語コード2962

言語コード2930

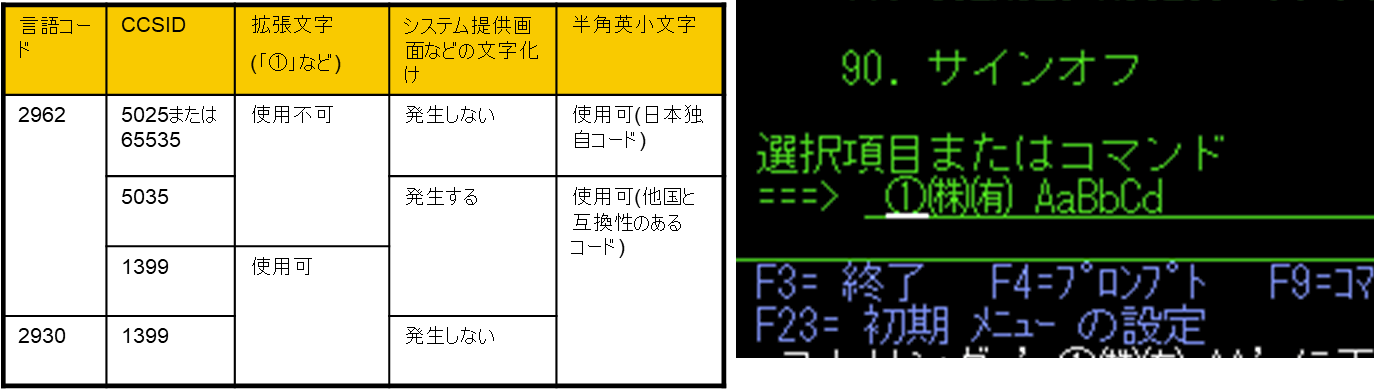
言語コード 2962でよくある不具合
①OS画面の半角カタカナや英小文字が化ける。
2962の画面
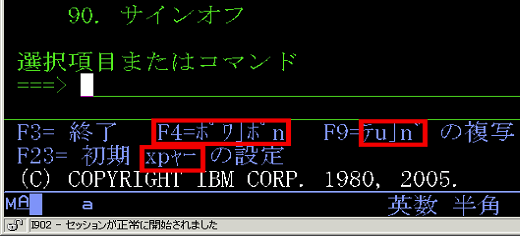
2930の画面

半角カタカナが化けています
これは言語コード2962がCCSID 5026ベースでOS画面(OS提供のメニュー画面やメッセージ等)を記述していることが原因です。
このため、英小文字を使いたい等で、CCSID 55035/1399 と ホストコードページ 939の組合せ環境で5026-5035で文字コードの異なる英小文字・半角カタカナなどが化けてしまいます。
その他にも設定環境によっては以下のようなエラーが発生したりします
②プログラム実行時のエラー

③日本語の文字化け
これらのエラーを根本的に回避するには言語コード2930をシステムに導入する必要があります。(一時言語または二次言語どちらでも可)
言語コード 2930 FAQ
FAQ1. 言語コード2962と動作上変わってくる点を教えてください
たとえば、5250からの入力の場合、言語コード2962では①、㈱、などのいわゆるNEC選定文字、JIS第4水準の文字などが文字化けする場合があり外字登録で回避しているケースがあると思いますが、言語コード2930では問題無く使用できます。
FAQ2. Db2 for iテーブルやジョブのCCSIDとの関係はどうなっていますか?
システムに導入する言語コードはシステム全体の環境を決定します(OS提供のメニュー画面など)。データベースやジョブのCCSIDのデフォルト値は言語コードに関連して決定されますが、デフォルトとは別にユーザーが個々に設定することも可能です。
たとえば言語コード2962のシステムのデフォルトCCSIDは5026ですが、Db2 for i テーブルやジョブのCCSIDは5035/1399も設定できます。言語コード2930でも同様で、デフォルトは1399ですが、5026/5035のCCSIDを個別のテーブル、ジョブなどに設定可能です。
FAQ3. 5250画面を使わず、ODBC/JDBCでデータベースアクセスする場合、差異はありますか?
IBM i (Db2 for i)は実行するジョブ(ODBC/JDBCのジョブ)とアクセスするテーブルのCCSIDを参照して正しく文字コード変換を行う機能を搭載しているので、(システムデフォルトに拠らず個別に最適なCCSIDを設定するのであれば)SQLでCRUDするデータ自体、処理では言語コードの差異を無効にできます。
FAQ4. 1つのIBM i LPAR上で言語コード 2962と2930を同居できますか?
はい、一次言語、二次言語でそれぞれを導入できます。使用するジョブによって適切な言語環境を使用するように設定すれば可能です。