本稿では、KerasベースのSeq2Seq(Sequence to Sequence)モデルによるチャットボットを、Bidirectionalの多層LSTM(Long short-term memory)アーキテクチャで作成し、Google Colaboratory上で動かしてみます。
1. はじめに
本稿はSeq2SeqをKerasで構築し、チャットボットの作成を目指す投稿の3回目です。前回の投稿では、単層LSTMのSeq2Seqニューラルネットワークを構築しましたが、今回は、これをBidirectionalの多層LSTMに拡張します。
2. 本稿のゴール
以下のとおりです。
- ニューラルネットワーク(Bidirectional多層LSTM)の構築と、訓練
- 応答文生成
なお、本稿の前提となる動作環境は、冒頭でも触れたとおり、Google Colaboratoryです。
ただし、Google Colaboratoryでは、TensorflowやKerasのバージョンが知らないうちに上がっていることがあるので、注意が必要です。本稿が前提とするTensorflowおよびKerasのバージョンは以下のとおりです。
- Tensorflow: 2.3.0
- Keras: 2.4.3
Google Colaboratoryの使い方については、こちらを参照願います。また、日本語の形態素解析にJuman++を使用しますが、そのインストール方法についてはこちらを参照してください。
なお、投稿第1回の内容に従って、訓練データが準備されているものとします。
3. ニューラルネットワーク構築
3−1. Bidirectional多層LSTMの構成
実装に当たっては、「深層学習による自然言語処理 」(講談社)を参考にしました。
エンコーダー、デコーダーとも、LSTMレイヤを2段にします。また、エンコーダーについては、入力系列を逆方向から処理するレイヤを設け、出力されるstatesを順方向のものと足し合わせて、デコーダーの入力にします。以下にレイヤ構成を図示します。
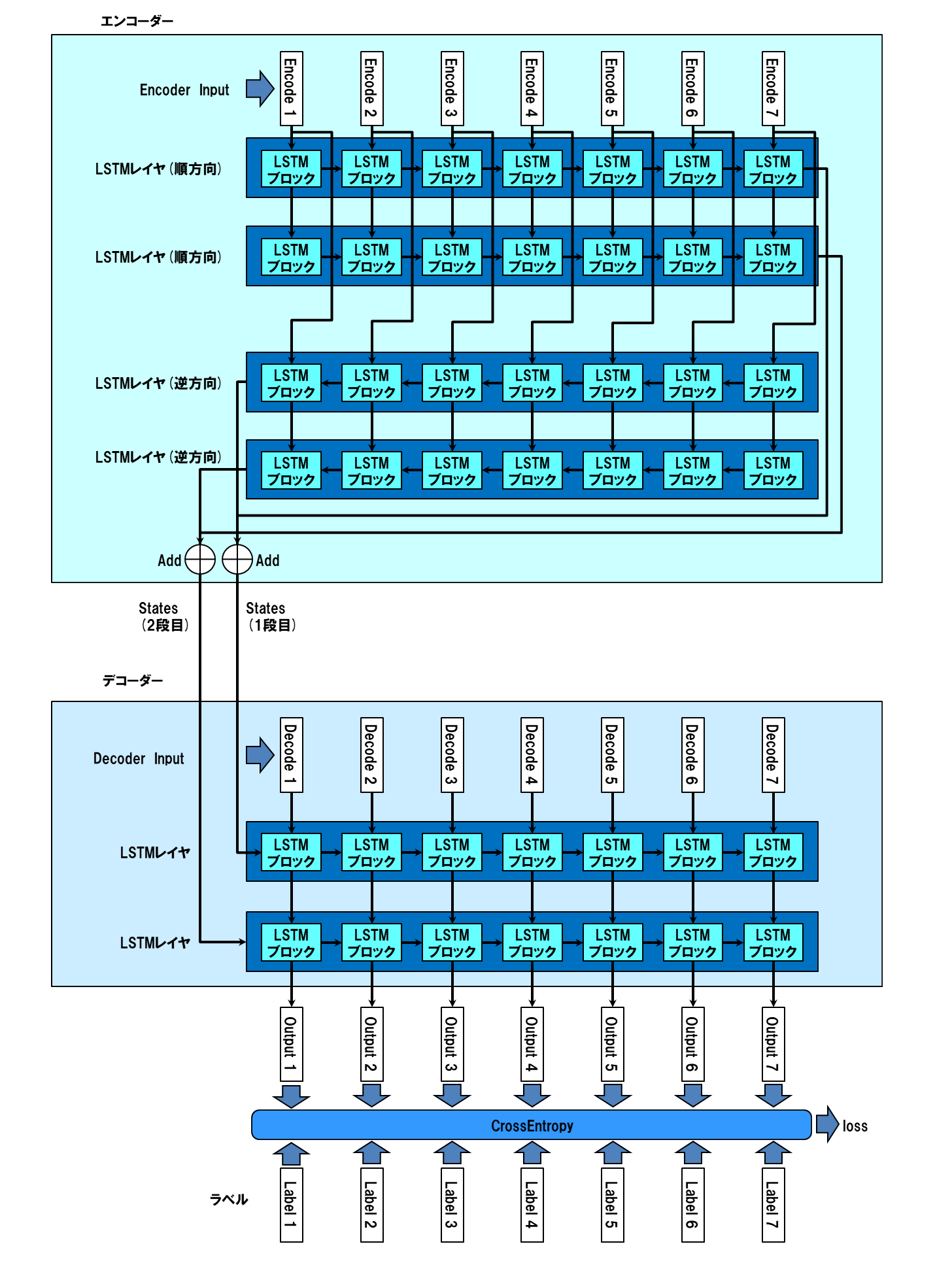
逆方向処理の実装方式は、LSTMのgo_backwardsオプションを使用しています。
3−2. ソースコード
作成したソースコードは以下の通りです。
| ファイル名 | 説明 |
|---|---|
| 1000_train.ipynb | 訓練実行処理 |
| 2000_response.ipynb | 応答文生成処理 |
| dialog.py | ニューラルネットワークのクラス定義 |
| dialog_encoder.py | ニューラルネットワークのうち、エンコーダ部分の定義 |
| dialog_decoder.py | ニューラルネットワークのうち、デコーダ部分の定義 |
| dialog_layers.py | ニューラルネットワークのレイヤ定義 |
| dialog_loss.py | 損失関数、評価関数定義 |
| dialog_train.py | ニューラルネットワークの訓練処理 |
ノートブック形式の1000_train.ipynbを実行すると、ニューラルネットワークの訓練が始まります。2000_response.ipynbを実行すると、入力文に対する応答文の生成を、対話形式で行うことが出来ます。これらの2ファイルは、好きな名称を付与して構いません。
dialog.pyはこれらのプログラムからimportされることで動作します。これ単独で動かすことはありません。その他のファイルもすべて、別のプログラムからimportされて動作します。それらの呼び出し関係は以下の通りです。
dialog.py ─┬─ dialog_encoder.py ─── dialog_layers.py
├─ dialog_decoder.py ─── dialog_layers.py
├─ dialog_train.py
├─ dialog_loss.py
└─ dialog_layers.py
これらのファイルはすべて、同一のGoogle Driveフォルダに配置してください。また、前回の投稿で作成した以下のファイルも、同じフォルダに格納しておいてください。
| ファイル名 | 説明 |
|---|---|
| d.pickle | 訓練データ(デコーダーインプット) |
| e.pickle | 訓練データ(エンコーダーインプット) |
| t.pickle | ラベルデータ |
| indices_word.pickle | インデックス→単語変換辞書 |
| word_indices.pickle | 単語→インデックス変換辞書 |
| maxlen.pickle | 系列長 |
| words.pickle | 単語一覧 |
3−2−1. 訓練実行処理(1000_train.ipynb)
訓練実行処理です。ノートブック形式で、複数のcellで構成されています。
先頭のcdコマンドで、ニューラルネットワーククラス定義や訓練データ等の格納フォルダ(筆者の例ではgooglecofab/003_seq2seq_bidirectional)に遷移します。
クリックして表示
%cd /content/drive/My Drive/GoogleColab/003_seq2seq_bidirectional
from dialog import Dialog
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
import codecs
# *******************************************************************************
# *
# 訓練データ、ラベルデータ等をロードする *
# *
# *******************************************************************************
def load_data() :
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words=pickle.load(ff)
#Encoder Inputデータをロード
with open('e.pickle', 'rb') as f :
e = pickle.load(f)
#Decoder Inputデータをロード
with open('d.pickle', 'rb') as g :
d = pickle.load(g)
#ラベルデータをロード
with open('t.pickle', 'rb') as h :
t = pickle.load(h)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
row = e.shape[0]
e = e.reshape((row, maxlen_e))
d = d.reshape((row, maxlen_d))
t = t.reshape((row, maxlen_d))
data = {
'e' :e,
'd' :d,
't' :t,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d,
'input_dim' : len(words),
'output_dim' : len(words)
}
return data
# *******************************************************************************
# *
# 訓練処理 *
# *
# *******************************************************************************
def prediction(epochs, batch_size , param_name, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
e = data['e']
d = data['d']
t = data['t']
n_hidden = data['n_hidden']
input_dim = data['input_dim']
vec_dim = data['vec_dim']
output_dim = data['output_dim']
data_row = e.shape[0] # 訓練データの行数
n_split = int(data_row*0.9) # データの分割比率
# データを訓練用とテスト用に分割
e_train, e_test = np.vsplit(e,[n_split]) #エンコーダインプット分割
d_train, d_test = np.vsplit(d,[n_split]) #デコーダインプット分割
t_train, t_test = np.vsplit(t,[n_split]) #ラベルデータ分割
# ニューラルネットワークインスタンス生成
prediction = Dialog(maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim)
emb_param = param_name+'.hdf5'
# 訓練
model = prediction.train(e_train, d_train, t_train,
batch_size, epochs, emb_param)
print()
# テスト
celoss, \
perplexity,\
accuracy = prediction.eval_perplexity(model,
e_test, d_test, t_test, batch_size)
print('loss =',celoss, perplexity, accuracy)
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
# @title パラメータ入力フォーム
epochs = 30 #@param {type:"integer"}
batch_size = 100 #@param {type:"integer"}
vec_dim = 400 #@param {type:"integer"}
n_hidden = 800 #@param {type:"integer"}
param_name = 'param_001' #@param {type:"string"}
# データ読み込み
data = load_data()
vec_dim = 400
n_hidden = int(round(vec_dim * 2))
data['n_hidden'] = n_hidden
data['vec_dim'] = vec_dim
# 訓練処理
prediction(epochs, batch_size ,param_name, data)
3−2−2. 応答文生成処理(2000_response.ipynb)
応答文章生成処理です。訓練実行処理と同様にノートブック形式で、複数のcellで構成されています。
1つ目のcellは、Juman++実行ファイルロード等の処理です。Juman++実行環境は、Google Corab上に保持しておけないので、Google Drive上にコピーを保持しておき、Juman++実行の際にGoogle Corab上にロードします。
クリックして表示
%cd /content/drive/My Drive/GoogleColab
!cp -rvf ./juman/bin/jumanpp /usr/local/bin/
%mkdir /usr/local/libexec/
!cp -rvf ./juman/libexec/jumanpp /usr/local/libexec/
!chmod 755 /usr/local/bin/jumanpp
!chmod 755 /usr/local/libexec/jumanpp/jumandic.config
!chmod 755 /usr/local/libexec/jumanpp/jumandic.jppmdl
!ls -l /usr/local/bin/jumanpp
!ls -l /usr/local/libexec/jumanpp/*
!pip install pyknp
%cd /content/drive/My Drive/GoogleColab/003_seq2seq_bidirectional
# *******************************************************************************
# *
# import宣言 *
# *
# *******************************************************************************
from __future__ import print_function
from dialog import Dialog
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
from keras.utils import plot_model
# sys.path.append("/home/ishigaki/pyknp-0.3")
from pyknp import Juman
import codecs
# *******************************************************************************
# *
# 辞書ファイル等ロード *
# *
# *******************************************************************************
def load_data() :
#辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f) #単語をキーにインデックス検索
with open('indices_word.pickle', 'rb') as g :
indices_word=pickle.load(g) #インデックスをキーに単語を検索
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words=pickle.load(ff)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
data = {'words' :words,
'indices_word':indices_word,
'word_indices':word_indices ,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d,
#'n_hidden' :n_hidden,
'input_dim' :len(words),
#'vec_dim' :vec_dim,
'output_dim' :len(words)
}
return data
# *******************************************************************************
# *
# モデル初期化 *
# *
# *******************************************************************************
def initialize_models(param_file, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
n_hidden = data['n_hidden']
input_dim = data['input_dim']
vec_dim = data['vec_dim']
output_dim = data['output_dim']
gen_context = Dialog(maxlen_e, 1, n_hidden, input_dim, vec_dim, output_dim)
m, encoder_m , decoder_m = gen_context.create_model()
#param_file1 = 'param_0'+'{0:0>2d}'.format(i)+'.hdf5'
m.load_weights(param_file)
return m, encoder_m, decoder_m
# *******************************************************************************
# *
# 入力文の品詞分解とインデックス化 *
# *
# *******************************************************************************
def encode_request(cns_input, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
word_indices = data['word_indices']
words = data['words']
encoder_model = data['encoder_model']
# Use Juman++ in subprocess mode
jumanpp = Juman()
result = jumanpp.analysis(cns_input)
input_text=[]
for mrph in result.mrph_list():
input_text.append(mrph.midasi)
mat_input=np.array(input_text)
#入力データe_inputに入力文の単語インデックスを設定
e_input=np.zeros((1,maxlen_e))
for i in range(0,len(mat_input)) :
if mat_input[i] in words :
e_input[0,i] = word_indices[mat_input[i]]
else :
e_input[0,i] = word_indices['UNK']
return e_input
# *******************************************************************************
# *
# 応答文組み立て *
# *
# *******************************************************************************
def generate_response(e_input, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
n_hidden = data['n_hidden']
output_dim = data['output_dim']
#freq_indices = data['freq_indices']
indices_word = data['indices_word']
word_indices = data['word_indices']
words = data['words']
encoder_model = data['encoder_model']
decoder_model = data['decoder_model']
# Encode the input as state vectors.
encoder_result = encoder_model.predict(e_input)
encoder_outputs = encoder_result[0]
encoder_states_1 = encoder_result[1:3]
encoder_states_2 = encoder_result[3:5]
decoder_input_states_1 = encoder_states_1
decoder_input_states_2 = encoder_states_2
decoded_sentence = ''
target_seq = np.zeros((1,1) ,dtype='int32')
# Populate the first character of target sequence with the start character.
target_seq[0, 0] = word_indices['SSSS']
# 応答文字予測
for i in range(0,maxlen_d) :
decoder_result = decoder_model.predict([target_seq]+
decoder_input_states_1+
decoder_input_states_2)
do = decoder_result[0]
d_s1 = decoder_result[1:3]
d_s2 = decoder_result[3:5]
# 予測単語の出現頻度算出
sampled_token_index = np.argmax(do[0, 0, :])
#予測単語
sampled_char = indices_word[sampled_token_index]
# Exit condition: find stop character.
if sampled_char == 'SSSS' :
break
decoded_sentence += sampled_char
# Update the target sequence (of length 1).
if i == maxlen_d-1:
break
target_seq[0,0] = sampled_token_index
# 次段向け値設定
decoder_input_states_1 = d_s1
decoder_input_states_2 = d_s2
return decoded_sentence
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
# @title パラメータファイル名入力フォーム
vec_dim = 400 #@param {type:"integer"}
n_hidden = 800 #@param {type:"integer"}
param = 'param_001' #@param {type:"string"}
param = param + '.hdf5' # 出力文章数
# データロード
data = load_data()
vec_dim = 400
n_hidden = int(round(vec_dim * 2))
data['n_hidden'] = n_hidden
data['vec_dim'] = vec_dim
# モデル初期化
model, encoder_model ,decoder_model = initialize_models(param , data)
data['encoder_model'] = encoder_model
data['decoder_model'] = decoder_model
sys.stdin = codecs.getreader('utf_8')(sys.stdin)
# maxlen_e = data['maxlen_e']
n_hidden = data['n_hidden']
while True:
cns_input = input(">> ")
if cns_input == "q":
print("終了")
break
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
e_input = encode_request(cns_input, data)
#print(e_input)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence = generate_response(e_input, data)
cns_input = decoded_sentence
print(cns_input)
3-2-3. ニューラルネットワーククラス定義(dialog.py)
ニューラルネットワークの定義クラスです。
クリックして表示
# coding: utf-8
from tensorflow.keras.layers import Masking
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Multiply
from tensorflow.keras.models import Model
# from keras.initializers import uniform
from tensorflow.keras import backend as K
from tensorflow.keras.utils import plot_model
import tensorflow as tf
import os
# TF2.Xになったので、eager modeが必要になった
tf.config.experimental_run_functions_eagerly(True)
from dialog_layers import Layer_BatchNorm
from dialog_layers import Layer_Embedding
from dialog_encoder import Class_Encoder
from dialog_decoder import Class_Decoder
from dialog_train import train_main_proc
from dialog_train import train_test_main
from dialog_loss import fn_cross_loss
from dialog_loss import fn_get_perplexity
from dialog_loss import fn_get_accuracy
class Color:
BLACK = '\033[30m'
RED = '\033[31m'
GREEN = '\033[38;5;10m'
YELLOW = '\033[33m'
BLUE = '\033[34m'
PURPLE = '\033[35m'
CYAN = '\033[38;5;14m'
WHITE = '\033[37m'
END = '\033[0m'
BOLD = '\038[1m'
UNDERLINE = '\033[4m'
INVISIBLE = '\033[08m'
REVERCE = '\033[07m'
# *******************************************************************************
# *
# ニューラルネットワーククラス定義 *
# *
# *******************************************************************************
class Dialog :
def __init__(self, maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim):
self.data = {
'maxlen_e' : maxlen_e,
'maxlen_d' : maxlen_d,
'input_dim' : input_dim,
'vec_dim' : vec_dim,
'output_dim' : output_dim ,
'n_hidden' : n_hidden ,
'len_norm' : 2 ,
'r_lambda' : 0.00002
}
#***************************************************************************
# *
# ニューラルネットワーク定義 *
# *
#***************************************************************************
def create_model(self):
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
maxlen_e = self.data['maxlen_e']
maxlen_d = self.data['maxlen_d']
input_dim = self.data['input_dim']
vec_dim = self.data['vec_dim']
output_dim = self.data['output_dim']
n_hidden = self.data['n_hidden']
len_norm = self.data['len_norm'] # constraintの最大ノルム長
r_lambda = self.data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_BatchNorm = Layer_BatchNorm(max_value=len_norm,
reg_lambda=r_lambda)
class_embedding = Layer_Embedding(max_value=len_norm,
reg_lambda=r_lambda)
#***********************************************************************
# *
# 処理インスタンス生成 *
# *
#***********************************************************************
encoder = Class_Encoder(self.data)
decoder = Class_Decoder(self.data)
print('#3')
#***********************************************************************
# *
# エンコーダー(学習/応答文作成兼用) *
# *
#***********************************************************************
#---------------------------------------------------------
#レイヤー定義
#---------------------------------------------------------
embedding =class_embedding.create_Embedding(vec_dim,
input_dim,
emb_name='Embedding')
input_mask = Masking(mask_value=0, name="input_Mask")
encoder_BatchNorm \
= class_BatchNorm.create_BatchNorm(bn_name='encoder_BatchNorm')
#---------------------------------------------------------
# 入力定義
#---------------------------------------------------------
encoder_input = Input(shape=(maxlen_e,),
dtype='int32',
name='encorder_input')
e_input = input_mask(encoder_input)
e_input = embedding(e_input)
e_input = encoder_BatchNorm(e_input)
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
encoder_outputs, \
encoder_states_1, encoder_states_2 \
= encoder.encoder_nn(e_input)
#---------------------------------------------------------
# エンコーダモデル定義
#---------------------------------------------------------
encoder_model = Model(inputs=encoder_input,
outputs=[encoder_outputs]+
encoder_states_1+
encoder_states_2
)
print('#4')
#***********************************************************************
# デコーダー(学習用) *
# デコーダを、完全な出力シークエンスを返し、内部状態もまた返すように *
# 設定します。 *
# 訓練モデルではreturn_sequencesを使用しませんが、推論では使用します。 *
#***********************************************************************
#---------------------------------------------------------
# レイヤー定義
#---------------------------------------------------------
decoder_BatchNorm \
= class_BatchNorm.create_BatchNorm(bn_name='decoder_BatchNorm')
#---------------------------------------------------------
#入力定義
#---------------------------------------------------------
decoder_inputs = Input(shape=(maxlen_d,),
dtype='int32', name='decoder_inputs')
d_i = Masking(mask_value=0)(decoder_inputs)
d_i = embedding(d_i)
d_i = decoder_BatchNorm(d_i)
d_input = d_i # 応答文生成で使う
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
d_out, _, _ \
= decoder.decoder_nn(d_i,
encoder_states_1, encoder_states_2)
# マスク処理
mask = Lambda(lambda x: K.sign(x))(decoder_inputs)
mask = Lambda(lambda x: K.cast(x,dtype='float32'))(mask)
mask = Reshape((maxlen_d,1))(mask)
mask = Lambda(lambda x: K.repeat_elements(x, output_dim, -1))(mask)
decoder_outputs = Multiply()([d_out, mask])
#---------------------------------------------------------
# モデル定義、コンパイル
#---------------------------------------------------------
model = Model(inputs=[encoder_input, decoder_inputs],
outputs=decoder_outputs)
model.compile(loss=fn_cross_loss,
optimizer="Adam",
metrics=[fn_get_perplexity, fn_get_accuracy])
#***********************************************************************
# *
# デコーダー(応答文作成) *
# *
#***********************************************************************
print('#6')
#---------------------------------------------------------
#入力定義
#---------------------------------------------------------
decoder_input_state_h_1 = Input(shape=(n_hidden,),
name='decoder_input_state_h_1')
decoder_input_state_c_1 = Input(shape=(n_hidden,),
name='decoder_input_state_c_1')
decoder_input_state_h_2 = Input(shape=(n_hidden,),
name='decoder_input_state_h_2')
decoder_input_state_c_2 = Input(shape=(n_hidden,),
name='decoder_input_state_c_2')
decoder_input_states_1 = [decoder_input_state_h_1,
decoder_input_state_c_1]
decoder_input_states_2 = [decoder_input_state_h_2,
decoder_input_state_c_2]
#---------------------------------------------------------
# デコーダー実行
#---------------------------------------------------------
res_decoder_outputs, \
res_decoder_state_1, \
res_decoder_state_2 = decoder.decoder_nn(d_input,
decoder_input_states_1,
decoder_input_states_2)
print('#7')
#---------------------------------------------------------
# モデル定義
#---------------------------------------------------------
decoder_model = Model(inputs= [decoder_inputs] +
decoder_input_states_1 +
decoder_input_states_2,
outputs=[res_decoder_outputs] +
res_decoder_state_1 +
res_decoder_state_2 )
return model, encoder_model, decoder_model
#***********************************************************************
# *
# 学習 *
# *
#***********************************************************************
def train(self, e_input, d_input, target,
batch_size, epochs, emb_param) :
print ('#2',target.shape)
model ,encoder_model , decoder_model = self.create_model()
if os.path.isfile(emb_param) :
model.load_weights(emb_param) #埋め込みパラメータセット
# ネットワーク図出力
plot_model(model, show_shapes=True,to_file='model.png')
plot_model(encoder_model, show_shapes=True,
to_file='encoder_model.png')
plot_model(decoder_model, show_shapes=True,
to_file='decoder_model.png')
print ('#8 number of params :', model.count_params())
# 学習メイン処理
params = {'model' : model,
'e' : e_input,
'd' : d_input,
't' : target,
'batch_size' : batch_size,
'epochs' : epochs,
'emb_param' : emb_param }
_, _, _ = train_main_proc(params, self.data)
return model
#***********************************************************************
# *
# perplexity計算 *
# *
#***********************************************************************
def eval_perplexity(self, model, e_test, d_test, t_test, batch_size) :
params = {'model' : model,
'e' : e_test,
'd' : d_test,
't' : t_test,
'batch_size' : batch_size,
'epochs' : '',
'emb_param' : ''}
return train_test_main('test', params, self.data)
3-2-4. エンコーダ定義(dialog_encoder.py)
ニューラルネットワークのうち、エンコーダ部分を定義したクラスです。
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# エンコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
from tensorflow.keras.layers import Add
from dialog_layers import Layer_LSTM
class Class_Encoder :
def __init__(self, data):
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_hidden = data['n_hidden']
len_norm = data['len_norm'] # constraintの最大ノルム長
r_lambda = data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_LSTM = Layer_LSTM(max_value=len_norm, reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤーインスタンス生成 *
# *
#***********************************************************************
self.encoder_LSTM_fw1 = class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_return_sequences=True,
lstm_name='encoder_LSTM_fw1')
self.encoder_LSTM_bw1 = class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_return_sequences=True,
lstm_go_backwards=True,
lstm_name='encoder_LSTM_bw1')
self.encoder_LSTM_fw2 = class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_name='encoder_LSTM_fw2')
self.encoder_LSTM_bw2 = class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_go_backwards=True,
lstm_name='encoder_LSTM_bw2')
def encoder_nn(self, e_input) :
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
#---------------------------------------------------------
# メイン処理
#---------------------------------------------------------
e_o_fw1, e_h_fw1, e_c_fw1 = self.encoder_LSTM_fw1(e_input)
e_o_bw1, e_h_bw1, e_c_bw1 = self.encoder_LSTM_bw1(e_input)
e_o_fw2, e_h_fw2, e_c_fw2 = self.encoder_LSTM_fw2(e_o_fw1)
e_o_bw2, e_h_bw2, e_c_bw2 = self.encoder_LSTM_bw2(e_o_bw1)
encoder_outputs = Add()([e_o_fw2, e_o_bw2])
encoder_states_1 = [Add()([e_h_fw1, e_h_bw1]),
Add()([e_c_fw1, e_c_bw1])]
encoder_states_2 = [Add()([e_h_fw2, e_h_bw2]),
Add()([e_c_fw2, e_c_bw2])]
return encoder_outputs, encoder_states_1, encoder_states_2
3-2-5. デコーダ定義(dialog_decoder.py)
ニューラルネットワークのうち、デコーダ部分を定義したクラスです。
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# デコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
from dialog_layers import Layer_LSTM
from dialog_layers import Layer_Dense
class Class_Decoder :
def __init__(self, data):
self.data = data
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
output_dim = data['output_dim']
n_hidden = data['n_hidden']
len_norm = data['len_norm'] # constraintの最大ノルム長
r_lambda = data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_Dense = Layer_Dense(max_value=len_norm, reg_lambda=r_lambda)
class_LSTM = Layer_LSTM(max_value=len_norm, reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤーインスタンス生成 *
# *
#***********************************************************************
#---------------------------------------------------------
# デコーダーLSTM
#---------------------------------------------------------
self.decoder_LSTM_1 = class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_return_sequences=True,
lstm_name='decoder_LSTM_1')
self.decoder_LSTM_2 = class_LSTM.create_LSTM(n_hidden,
lstm_return_state=True,
lstm_return_sequences=True,
lstm_name='decoder_LSTM_2')
#---------------------------------------------------------
# 全結合
#---------------------------------------------------------
self.decoder_Dense = class_Dense.create_Dense(output_dim,
dense_activation='softmax',
dense_name='decoder_Dense')
def decoder_nn(self, d_i, e_s1, e_s2) :
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
#--------------------------------------------------------
# decoderメイン処理
#--------------------------------------------------------
# LSTM
d_o_1, d_h_1, d_c_1 = self.decoder_LSTM_1(d_i, initial_state=e_s1)
d_o_2, d_h_2, d_c_2 = self.decoder_LSTM_2(d_o_1, initial_state=e_s2)
decoder_states_1 = [d_h_1, d_c_1]
decoder_states_2 = [d_h_2, d_c_2]
# 全結合
decoder_outputs = self.decoder_Dense(d_o_2)
return decoder_outputs, decoder_states_1, decoder_states_2
3-2-6. ニューラルネットワークレイヤ定義(dialog_layers.py)
ニューラルネットワークを構成する、各種レイヤの定義クラスです。
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# レイヤークラス定義 *
# *
# *******************************************************************************
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.initializers import glorot_uniform
# from tensorflow.keras.initializers import uniform
from tensorflow.keras.initializers import orthogonal
from tensorflow.keras.initializers import Ones
from tensorflow.keras import regularizers
from tensorflow.keras import backend as K
from tensorflow.keras.constraints import max_norm
# *******************************************************************************
class Layer_LSTM :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_LSTM(self, lstm_units,
lstm_return_state=False, lstm_return_sequences=False,
lstm_go_backwards=False, lstm_name='LSTM') :
layer = LSTM(lstm_units, name=lstm_name ,
return_state=lstm_return_state,
return_sequences=lstm_return_sequences,
recurrent_activation='sigmoid',
go_backwards=lstm_go_backwards,
recurrent_regularizer=regularizers.l2(self.reg_lambda) ,
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
#kernel_constraint=max_norm(max_value=self.max_value, axis=0),
#recurrent_constraint=max_norm(max_value=self.max_value, axis=0),
kernel_initializer=glorot_uniform(seed=self.seed),
recurrent_initializer=orthogonal(gain=1.0, seed=self.seed),
bias_initializer=Ones(),
dropout=0.5, recurrent_dropout=0.0
)
return layer
# *******************************************************************************
class Layer_Dense :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Dense(self, dense_units,
dense_activation=None, dense_name='Dense'):
if dense_activation==None :
act_reg = None
else :
act_reg = regularizers.l1(self.reg_lambda)
layer = Dense(dense_units, name=dense_name,
activation=dense_activation,
kernel_initializer=glorot_uniform(seed=self.seed),
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
bias_regularizer=regularizers.l2(self.reg_lambda) ,
activity_regularizer=act_reg,
#kernel_constraint=max_norm(max_value=self.max_value, axis=0),
#bias_constraint=max_norm(max_value=self.max_value, axis=0),
)
return layer
# *******************************************************************************
class Layer_BatchNorm :
def __init__(self, max_value=2, reg_lambda=0.01):
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_BatchNorm(self, bn_name='BatchNorm'):
layer = BatchNormalization(axis=-1,
name=bn_name,
beta_regularizer=regularizers.l2(self.reg_lambda) ,
gamma_regularizer=regularizers.l2(self.reg_lambda) ,
beta_constraint=max_norm(max_value=self.max_value, axis=0),
gamma_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
# *******************************************************************************
class Layer_Embedding :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Embedding(self, emb_out_dim, emb_in_dim, emb_name='Embedding'):
layer = Embedding(output_dim=emb_out_dim, input_dim=emb_in_dim,
mask_zero=True, name=emb_name,
#embeddings_initializer=uniform(seed=self.seed),
embeddings_regularizer=regularizers.l2(self.reg_lambda),
embeddings_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
3-2-7. 損失関数、評価関数定義(dialog_loss.py)
損失関数、perprelexity算出関数、正解率算出関数を定義したプログラムファイルです。
クリックして表示
from tensorflow.keras import backend as K
# ---------------------------------------------------------
# 損失関数
# ---------------------------------------------------------
def fn_cross_loss(y_true, y_pred) :
perp_mask = K.sign((y_pred))
perp_mask = perp_mask[:, :, 0]
#print(perp_mask.numpy()[0, :])
sum_mask = K.sum(perp_mask, axis=-1, keepdims= True)
#print('perp_mask1',K.int_shape(perp_mask))
epsilons = 1 / 2 * y_pred + K.epsilon()
cliped = K.maximum(y_pred, epsilons)
log_pred = -K.log(cliped)
cross_e = y_true * log_pred
cross_e = K.sum(cross_e, axis=-1)
masked_entropy = perp_mask * cross_e
sum_entropy = K.sum(masked_entropy, axis=-1, keepdims= True)
celoss = sum_entropy / sum_mask
#print('celoss',K.int_shape(celoss))
return K.mean(celoss)
# ---------------------------------------------------------
# perplexity
# ---------------------------------------------------------
def fn_get_perplexity(y_true, y_pred) :
perp_mask = K.sign((y_pred))
perp_mask = perp_mask[:, :, 0]
sum_mask = K.sum(perp_mask, axis=-1, keepdims= True)
epsilons = 1 / 2 * y_pred + K.epsilon()
cliped = K.maximum(y_pred, epsilons)
log_pred = -K.log(cliped)
cross_e = y_true * log_pred
cross_e = K.sum(cross_e, axis=-1)
masked_entropy = perp_mask * cross_e
sum_entropy = K.sum(masked_entropy, axis=-1, keepdims= True)
perplexity = sum_entropy / sum_mask
perplexity = K.exp(perplexity)
#perplexity = K.repeat(perplexity , self.maxlen_d)
return K.mean(perplexity)
# ---------------------------------------------------------
# 評価関数
# ---------------------------------------------------------
def fn_get_accuracy(y_true, y_pred) :
perp_mask = K.sign((y_pred))
perp_mask = perp_mask[:, :, 0]
perp_mask = K.cast(perp_mask,dtype='int32')
y_pred_argmax = K.argmax(y_pred, axis=-1)
y_true_argmax = K.argmax(y_true, axis=-1)
n_correct = K.abs(y_true_argmax - y_pred_argmax)
n_correct = K.sign(n_correct)
n_correct = K.ones_like(n_correct, dtype='int64') - n_correct
n_correct = K.cast(n_correct, dtype='int32')
n_correct = n_correct * perp_mask
n_correct = K.cast(K.sum(n_correct, axis=-1, keepdims= True),
dtype='float32')
n_total = K.cast(K.sum(perp_mask,axis=-1, keepdims= True),
dtype='float32')
accuracy = n_correct / n_total
#print('accuracy',K.int_shape(accuracy))
return K.mean(accuracy)
3-2-8. ニューラルネットワーク訓練処理(dialog_train.py)
ニューラルネットワークの訓練処理です。ニューラルネットワーククラスのメソッドとして定義してあります。
クリックして表示
# coding: utf-8
from tensorflow.keras.utils import to_categorical
from tensorflow.data import Dataset
import numpy as np
import sys
import time
class Color:
BLACK = '\033[30m'
RED = '\033[31m'
GREEN = '\033[38;5;10m'
YELLOW = '\033[33m'
BLUE = '\033[34m'
PURPLE = '\033[35m'
CYAN = '\033[38;5;14m'
WHITE = '\033[37m'
END = '\033[0m'
BOLD = '\038[1m'
UNDERLINE = '\033[4m'
INVISIBLE = '\033[08m'
REVERCE = '\033[07m'
# *******************************************************************************
# *
# 訓練/テスト共通関数 *
# *
# *******************************************************************************
def train_test_main(kind, params, data) :
model = params['model']
e_train = params['e']
d_train = params['d']
t_train = params['t']
batch_size = params['batch_size']
emb_param = params['emb_param']
output_dim = data['output_dim']
#損失関数、評価関数の平均計算用リスト
list_loss = []
list_perplexity =[]
list_accuracy =[]
s_time = time.time()
row=d_train.shape[0]
dataset_on_batch \
= Dataset.from_tensor_slices((e_train,
d_train,
t_train)).batch(batch_size)
for i, (e_on_batch,
d_on_batch,
t_on_batch) in enumerate(dataset_on_batch) :
e = min([(i+1) * batch_size,row])
t_on_batch = to_categorical(t_on_batch, output_dim)
if kind == 'train' :
result = model.train_on_batch([e_on_batch, d_on_batch],
t_on_batch)
else :
result = model.test_on_batch([e_on_batch, d_on_batch],
t_on_batch)
list_loss.append(result[0])
list_perplexity.append(result[1])
list_accuracy.append(result[2])
elapsed_time = time.time() - s_time
if i % 100 == 0 :
sys.stdout.write("\r"
+" "
+" "
+" "
+" "
+" "
+" "
)
sys.stdout.flush()
if kind == 'train' :
ctl_color = Color.CYAN
else :
ctl_color = Color.GREEN
sys.stdout.write(ctl_color
+ "\r"+str(e)+"/"+str(row)+" "
+ str(int(elapsed_time))+"s "+"\t"
+ "{0:.4f}".format(np.average(list_loss)) + "\t"
+ "{0:.4f}".format(np.average(list_perplexity)) + "\t"
+ "{0:.4f}".format(np.average(list_accuracy))
+ Color.END)
sys.stdout.flush()
if i % 100 == 99 and kind == 'train':
model.save_weights(emb_param)
del e_on_batch, d_on_batch, t_on_batch
print()
return np.average(list_loss), \
np.average(list_perplexity), \
np.average(list_accuracy)
# *******************************************************************************
# *
# 学習メイン処理 *
# *
# *******************************************************************************
def train_main_proc(params, data) :
model = params['model']
e_input = params['e']
d_input = params['d']
target = params['t']
batch_size = params['batch_size']
epochs = params['epochs']
emb_param = params['emb_param']
#===================================================================
# train on batch
#===================================================================
def on_batch() :
n_split = int(d_input.shape[0]*0.1)
e_val = e_input[:n_split,:]
d_val = d_input[:n_split,:]
t_val = target[:n_split,:]
e_train = e_input[n_split:,:]
d_train = d_input[n_split:,:]
t_train = target[n_split:,:]
p_train = {'model' : model,
'e' : e_train,
'd' : d_train,
't' : t_train,
'batch_size' : batch_size,
'epochs' : epochs,
'emb_param' : emb_param }
_, _, _ = train_test_main('train', p_train, data)
model.save_weights(emb_param)
p_test = {'model' : model,
'e' : e_val,
'd' : d_val,
't' : t_val,
'batch_size' : batch_size,
'epochs' : epochs,
'emb_param' : emb_param }
return train_test_main('test', p_test, data)
#===================================================================
# メイン処理
#===================================================================
loss_bk = 10000
perplexity_bk = 10000
accuracy_bk = 0
patience = 0
# tensorflow2だとmetrics_nameが空なのでコメントアウト
#print(Color.CYAN,model.metrics_names[0]+" "
# +model.metrics_names[1]+" "
# +model.metrics_names[2] ,
# Color.END)
for j in range(0,epochs) :
print(Color.CYAN,"Epoch ",j+1,"/",epochs,Color.END)
loss, \
perplexity, \
accuracy = on_batch()
#-----------------------------------------------------
# EarlyStopping
#-----------------------------------------------------
if j == 0 or (loss <= loss_bk and
perplexity <= perplexity_bk and
accuracy >= accuracy_bk):
loss_bk = loss
perplexity_bk = perplexity
accuracy_bk = accuracy
patience = 0
elif patience < 1 :
patience += 1
else :
print('EarlyStopping')
break
return loss, perplexity, accuracy
3−3. ネットワーク図
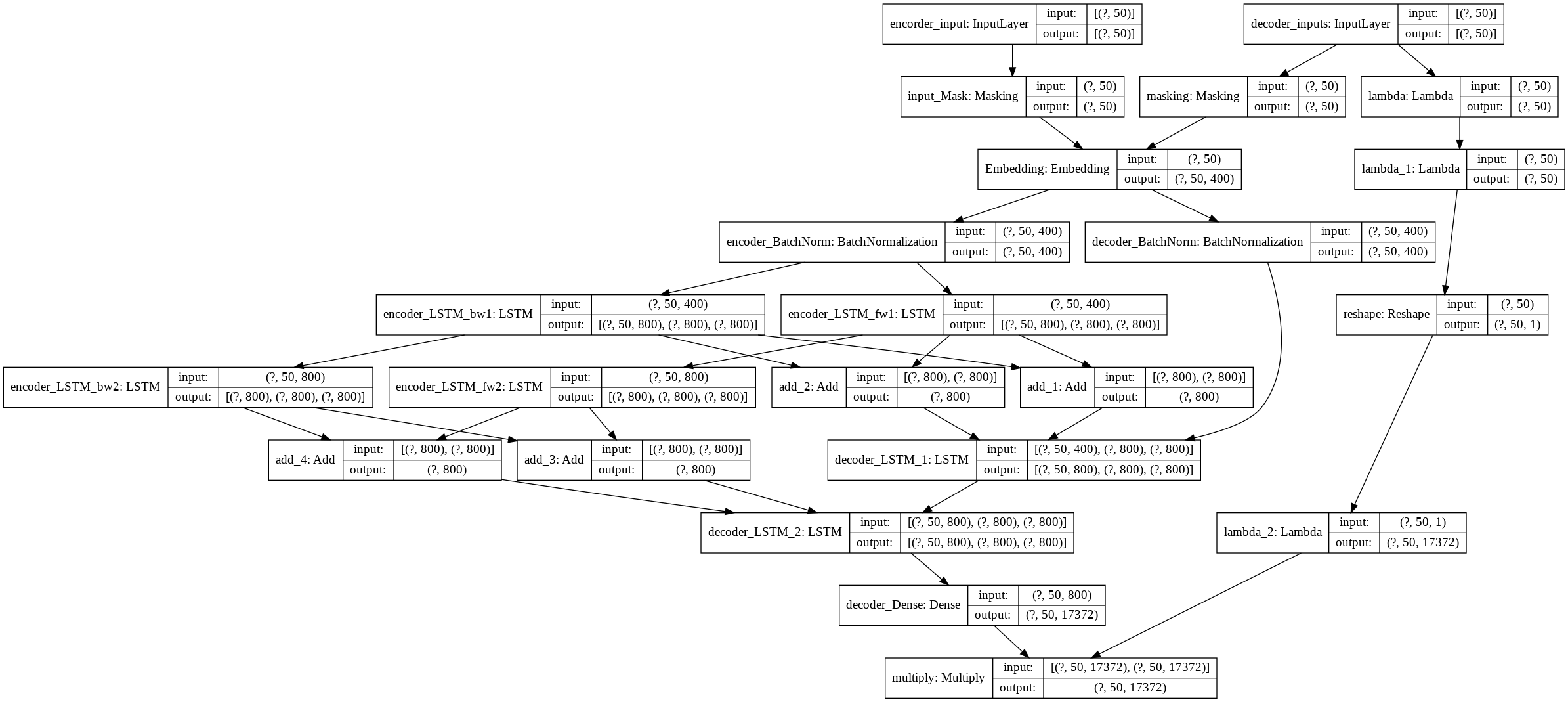
発話エンコーダー+訓練用デコーダーモデルです。
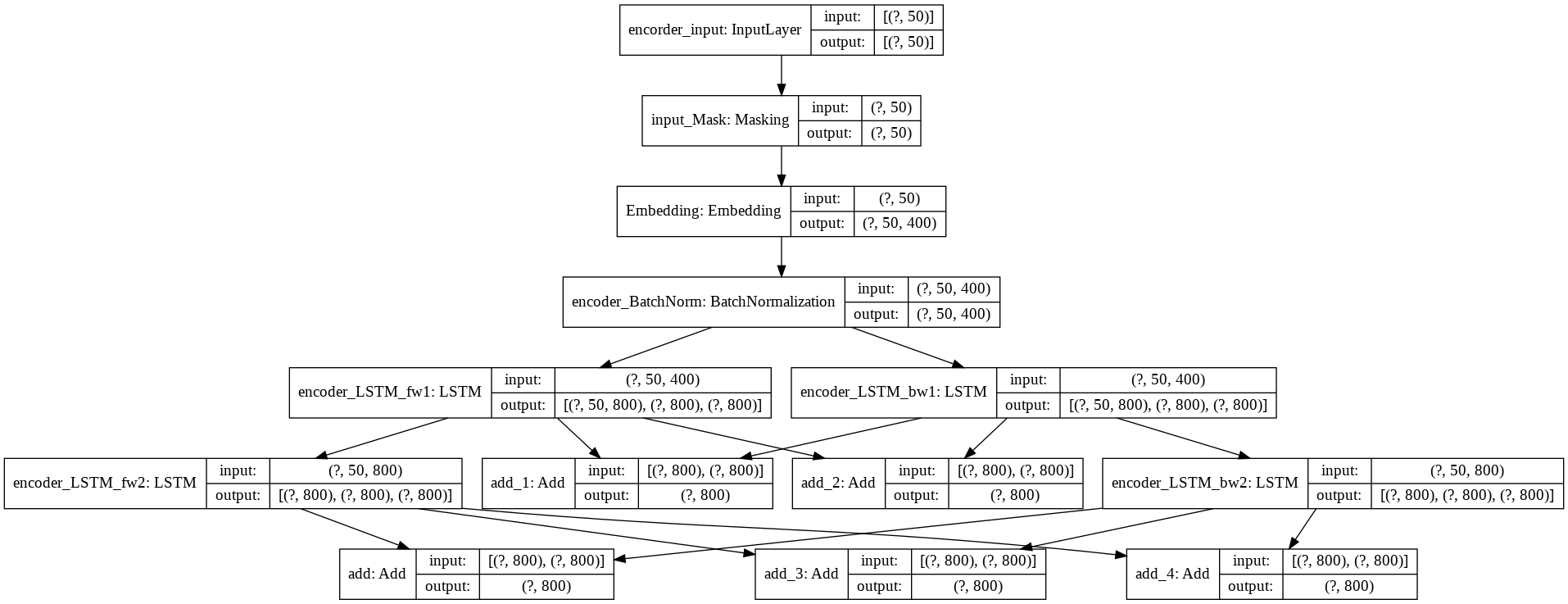
発話文エンコーダーモデルです。
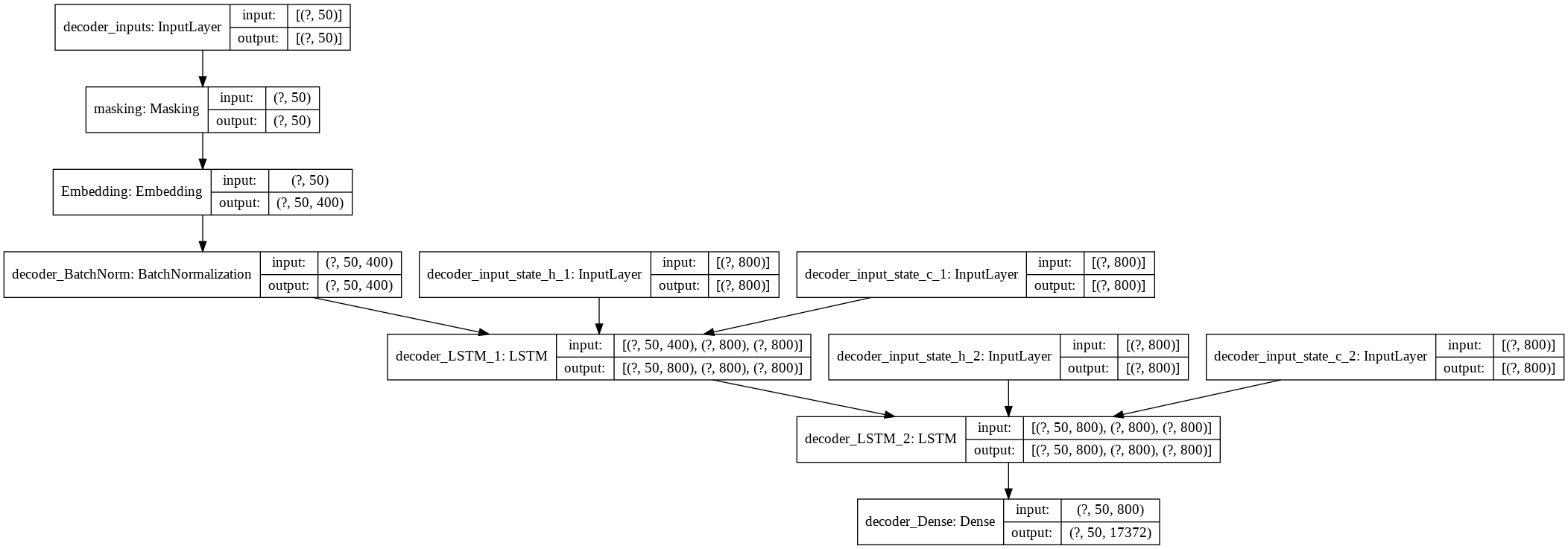
応答文生成用デコーダーモデルです。
4. 訓練
3-2-1項のノートブックを実行すると、訓練が始まります。Early stoppingで訓練が停止した時のperplexityは約133でした。
5. 応答文生成
3-2-1項のノートブックを実行後に3-2-2項のノートブックを実行します。発話文入力用のダイアログボックスが開きますので、文を入力してみてください。以下のワーニングメッセージに続いて、応答文が生成、出力されます。
/usr/local/lib/python3.6/dist-packages/tensorflow/python/data/ops/dataset_ops.py:3350: UserWarning: Even though the tf.config.experimental_run_functions_eagerly option is set, this option does not apply to tf.data functions. tf.data functions are still traced and executed as graphs.
"Even though the tf.config.experimental_run_functions_eagerly "
実行した結果は、以下のとおりです。前回から変わり映えはしません。
>> おはよう!
うん。
>> 今何してる?
うん。
>> ご飯食べた?
うん。
>> こんにちは。
うん。
>> それでは御免蒙りまするでござります。
うん。
6. おわりに
以上、Bidirectional多層LSTMによるseq2seqを実装してみました。次回は、Attentionの実装にチャレンジします。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2018/10/15 | - | 初版 |
| 2 | 2020/10/19 | 3-2節 | Google Colaboratory対応による記述内容見直し |