1. PSIとは
- 2つのデータセット間における分布の変化の度合いを定量的に表す指標のひとつ。
- ドリフトの検知手法の一つ。
- 元論文では、クレジットスコアリングモデル(与信サービスで信用リスクを推定するモデル)の性能劣化(ドリフト)を監視するために用いられています [元論文中の参考文献13, 31]。
- 素晴らしい解説。非常に直感的に解説されています。
計算方法
PSIの計算ステップ(元論文の参考文献56,63,64参照):
- ビニング: 比較したい変数(特徴量)の値を、10個程度の区間(ビン)に分割します。カテゴリ変数の場合は、カテゴリの値ごとにグループ化します。(論文ではスコアを50のバンドに分ける例が示されています。個数は解釈しやすさとかサンプル数に応じて適当に設定してください)。
- 各ビンのレコード割合を計算: 学習データと推論データのそれぞれについて、各ビンに属するデータが全体に占める割合(%)を計算します。
- PSIの算出: 以下の式を用いてPSIを求めます。
$$\text{PSI} = \sum_{i=1}^{n} (\% \text{Actual}_i - \% \text{Expected}_i) \times \ln\left(\frac{\% \text{Actual}_i}{\% \text{Expected}_i}\right)$$
ここで、
- $n$: ビンの総数
- $\% \text{Actual}_i$: $i$番目のビンにおける現在(Actual)のデータ構成比率
- $\% \text{Expected}_i$: $i$番目のビンにおける開発時(Expected)のデータ構成比率
- $\ln$: 自然対数
解釈
一般的に以下のような閾値で運用されます。これはドリフト検知を運用する際の基準となります。実際の運用の際には0.1とか0.25のような値を、データに合わせて調整してください。(0.1, 0.25のような値は元論文中の参考文献66, 67で用いられている値です)。
- PSI < 0.1: 分布の変化は僅か。モデルは安定している。
- 0.1 <= PSI < 0.25: 分布に中程度の変化が見られる。ちょっと注意。
- PSI >= 0.25: 分布変わりすぎ。ドリフトの原因調査やモデルの再学習を検討すべき。
PSIの計算式はなぜ適切なのか
一言でいうと「KLダイバージェンスの対称化だから」ですが、数学的な説明はAppendixに回します。興味がある方は見てみて下さい。
ここでは直感的な説明にとどめます。
-
相対的な変化を重視: $(% \text{Actual} - % \text{Expected})$ の部分は単純な差分ですが、$\ln(\frac{% \text{Actual}}{% \text{Expected}})$ の項を掛け合わせることで、構成比が小さい領域での変化をより大きく評価します。
- 例: 構成比が1%から2%に変化した場合、差は1%ですが比率は2倍です。一方、40%から41%に変化した場合も差は1%ですが、比率は約1.025倍です。対数を取ることで、前者の変化の方がPSIへの寄与が大きくなり、「これまでほとんど現れなかった層が倍増した」というような重大な変化を捉えやすくなります。
- 変化の方向と大きさの両方を考慮: 式全体として、各ビンでの構成比の差(どれだけズレたか)と、その変化率(どれくらいのインパクトがあったか)の両方を組み込んでおり、分布全体の変化を一つの数値で要約できる非常に強力な指標となっています。
2. Pythonでの計算と可視化
PSIが示す「距離感」を、他の統計的指標と比較しながら直感的に理解しましょう。
2025年8月現在、sklearnのようなメジャーなライブラリにPSIの計算メソッドが実装されていないので、自前で実装する必要があります。他の統計手法(KS検定など)はscipyライブラリで提供されています。
まず、PSIやその他の指標を計算するための関数を準備します。
import pandas as pd
import numpy as np
from scipy.stats import ks_2samp, chi2_contingency, wasserstein_distance
def calculate_psi(expected, actual, bins=10):
"""2つのデータセット間のPSIを計算する関数
Args:
expected (pd.Series): 期待される分布(例:学習データ)
actual (pd.Series): 実際の分布(例:推論データ)
bins (int): 数値データの場合のビンの数
Returns:
float: 計算されたPSI値
pd.DataFrame: 計算過程の各ビンの情報
"""
# 2つのデータからビンの境界を決定する
all_values = pd.concat([expected, actual])
# quantile-based binning
breakpoints = np.quantile(all_values, q=np.linspace(0, 1, bins + 1))
# 境界値の重複を削除
breakpoints = np.unique(breakpoints)
# ビニングを実施
expected_binned = pd.cut(expected, bins=breakpoints, right=True, include_lowest=True)
actual_binned = pd.cut(actual, bins=breakpoints, right=True, include_lowest=True)
# 各ビンの度数を集計
df_expected = pd.DataFrame({'expected': expected_binned.value_counts()})
df_actual = pd.DataFrame({'actual': actual_binned.value_counts()})
# 2つのデータフレームを結合
df = df_expected.join(df_actual, how='outer').fillna(0)
# レコード数
n_expected = df['expected'].sum()
n_actual = df['actual'].sum()
# 各ビンの割合を計算
# ゼロ除算を避けるため、度数が0の場合は非常に小さい値(0.0001)に置き換える
df['expected_perc'] = (df['expected'] + 0.0001) / n_expected
df['actual_perc'] = (df['actual'] + 0.0001) / n_actual
# PSIの計算
df['psi'] = (df['actual_perc'] - df['expected_perc']) * np.log(df['actual_perc'] / df['expected_perc'])
psi_value = df['psi'].sum()
return psi_value, df
分布の可視化と指標の算出
基準となる分布と、そこから少しずつ変化させた分布が、視覚的にどのように見えるか、また各指標がどのように変化するかを確認しましょう。以下のグラフでは、凡例に各分布における指標の計算結果を表示しています。
平均値をずらした場合の分布
基準となる正規分布(平均μ=0, 標準偏差σ=1)と、平均値だけを少しずつずらした分布(μ=0.1, 0.2, 0.5, 1.0)を比較します。平均値が大きくなるほど、分布の山が右に移動し、各指標の値も大きくなっている(p値は小さくなっている)のが分かります。

Pythonコード
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm, ks_2samp, chi2_contingency, wasserstein_distance
import pandas as pd
# グラフのスタイル設定
sns.set(style='whitegrid')
# シミュレーション用の基準データを生成
np.random.seed(0)
expected_data = pd.Series(np.random.normal(loc=0, scale=1, size=10000))
# --- 平均値をシフトさせた場合の分布を描画 ---
plt.figure(figsize=(14, 8))
x = np.linspace(-5, 6, 1000)
# 基準となる分布 (μ=0, σ=1) の理論曲線を描画
plt.plot(x, norm.pdf(x, loc=0, scale=1), label='Expected (μ=0)', color='black', linestyle='--')
# 平均をずらした分布
shifts = [0.1, 0.2, 0.5, 1.0]
colors = sns.color_palette("Reds_d", n_colors=len(shifts))
for i, shift in enumerate(shifts):
# 比較対象データを生成
actual_data = pd.Series(np.random.normal(loc=shift, scale=1, size=10000))
# 各指標を計算
psi_val, df = calculate_psi(expected_data, actual_data)
ks_stat, ks_pvalue = ks_2samp(expected_data, actual_data)
chi2_stat, chi2_pvalue, _, _ = chi2_contingency(df[['expected', 'actual']].values)
wasserstein_dist = wasserstein_distance(expected_data, actual_data)
# 凡例を作成
legend_label = (
f'Actual (μ={shift})\n'
f' PSI = {psi_val:.4f}\n'
f' KS p-val = {ks_pvalue:.4f}\n'
f' Chi2 p-val = {chi2_pvalue:.4f}\n'
f' Wasserstein = {wasserstein_dist:.4f}'
)
# 理論曲線を描画
plt.plot(x, norm.pdf(x, loc=shift, scale=1), label=legend_label, color=colors[i])
plt.title('Distribution Shift (Mean) with Drift Metrics', fontsize=16)
plt.xlabel('Value', fontsize=12)
plt.ylabel('Probability Density', fontsize=12)
plt.legend(fontsize='small')
plt.show()
分散(標準偏差)をずらした場合の分布
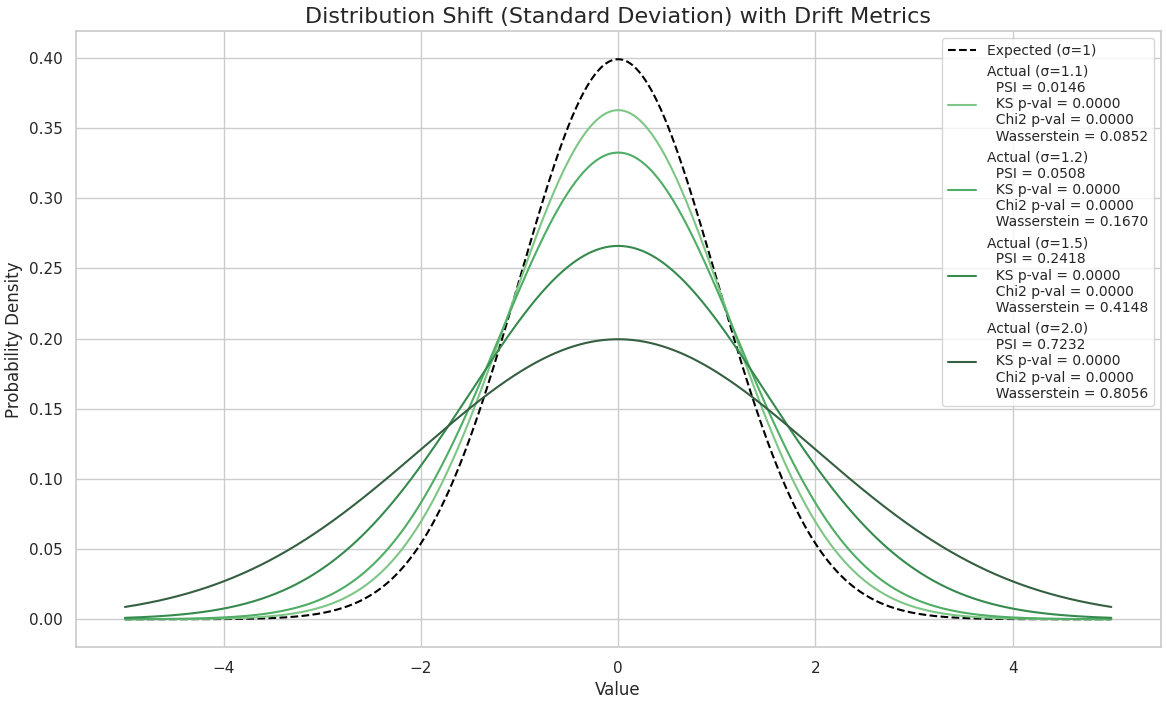
基準となる正規分布(平均μ=0, 標準偏差σ=1)と、標準偏差だけを少しずつ大きくした分布(σ=1.1, 1.2, 1.5, 2.0)を比較します。標準偏差が大きくなるほど、分布の山が低くなり裾野が広がっていくのが分かります。こちらも同様に、変化が大きくなるにつれて各指標が反応しています。
Pythonコード
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm, ks_2samp, chi2_contingency, wasserstein_distance
import pandas as pd
# グラフのスタイル設定
sns.set(style='whitegrid')
# シミュレーション用の基準データを生成
np.random.seed(0)
expected_data = pd.Series(np.random.normal(loc=0, scale=1, size=10000))
# --- 分散(標準偏差)をシフトさせた場合の分布を描画 ---
plt.figure(figsize=(14, 8))
x = np.linspace(-5, 5, 1000)
# 基準となる分布 (μ=0, σ=1) の理論曲線を描画
plt.plot(x, norm.pdf(x, loc=0, scale=1), label='Expected (σ=1)', color='black', linestyle='--')
# 分散をずらした分布
scale_factors = [1.1, 1.2, 1.5, 2.0]
colors = sns.color_palette("Greens_d", n_colors=len(scale_factors))
for i, scale in enumerate(scale_factors):
# 比較対象データを生成
actual_data = pd.Series(np.random.normal(loc=0, scale=scale, size=10000))
# 各指標を計算
psi_val, df = calculate_psi(expected_data, actual_data)
ks_stat, ks_pvalue = ks_2samp(expected_data, actual_data)
chi2_stat, chi2_pvalue, _, _ = chi2_contingency(df[['expected', 'actual']].values)
wasserstein_dist = wasserstein_distance(expected_data, actual_data)
# 凡例を作成
legend_label = (
f'Actual (σ={scale})\n'
f' PSI = {psi_val:.4f}\n'
f' KS p-val = {ks_pvalue:.4f}\n'
f' Chi2 p-val = {chi2_pvalue:.4f}\n'
f' Wasserstein = {wasserstein_dist:.4f}'
)
# 理論曲線を描画
plt.plot(x, norm.pdf(x, loc=0, scale=scale), label=legend_label, color=colors[i])
plt.title('Distribution Shift (Standard Deviation) with Drift Metrics', fontsize=16)
plt.xlabel('Value', fontsize=12)
plt.ylabel('Probability Density', fontsize=12)
plt.legend(fontsize='small')
plt.show()
各種指標の計算結果まとめ
次に、分布を少しずつずらしながら、PSIやその他の指標がどのように変化するかをテキストで確認します。
# シミュレーション用のデータを生成
np.random.seed(0)
expected_data = pd.Series(np.random.normal(loc=0, scale=1, size=10000))
# --- ケース1: 完全に一致するデータ ---
print("--- ケース1 (同一分布) ---")
# 比較対象データも同じ設定で生成
actual_data_case1 = pd.Series(np.random.normal(loc=0, scale=1, size=10000))
# PSI
psi_val, df = calculate_psi(expected_data, actual_data_case1)
# KS検定 (p値が大きい -> 分布は同じ)
ks_stat, ks_pvalue = ks_2samp(expected_data, actual_data_case1)
# カイ二乗検定 (PSI計算時の度数分布を利用, p値が大きい -> 分布は同じ)
chi2_stat, chi2_pvalue, _, _ = chi2_contingency(df[['expected', 'actual']].values)
# ワッサースタイン距離 (値が0に近い -> 分布は似ている)
wasserstein_dist = wasserstein_distance(expected_data, actual_data_case1)
print(f"PSI = {psi_val:.4f}, KS p-val = {ks_pvalue:.4f}, Chi2 p-val = {chi2_pvalue:.4f}, Wasserstein = {wasserstein_dist:.4f}\n")
# -> PSI = 0.0041, KS p-val = 0.9990, Chi2 p-val = 0.9984, Wasserstein = 0.0101
# --- ケース2: 平均値が少しずつずれる ---
print("--- ケース2: 平均値のズレ ---")
for shift in [0.1, 0.2, 0.5, 1.0]:
actual_data_case2 = pd.Series(np.random.normal(loc=0 + shift, scale=1, size=10000))
psi_val, df = calculate_psi(expected_data, actual_data_case2)
ks_stat, ks_pvalue = ks_2samp(expected_data, actual_data_case2)
chi2_stat, chi2_pvalue, _, _ = chi2_contingency(df[['expected', 'actual']].values)
wasserstein_dist = wasserstein_distance(expected_data, actual_data_case2)
print(f"平均のズレ = {shift:.1f}: PSI={psi_val:7.4f}, KS p-val={ks_pvalue:.4f}, Chi2 p-val={chi2_pvalue:.4f}, Wasserstein={wasserstein_dist:.4f}")
# -> 平均のズレ = 0.1: PSI= 0.0144, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=0.1135
# -> 平均のズレ = 0.2: PSI= 0.0494, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=0.2168
# -> 平均のズレ = 0.5: PSI= 0.2625, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=0.5146
# -> 平均のズレ = 1.0: PSI= 1.0270, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=1.0237
# --- ケース3: 分散が少しずつ広がる ---
print("\n--- ケース3: 分散のズレ ---")
for scale_factor in [1.1, 1.2, 1.5, 2.0]:
actual_data_case3 = pd.Series(np.random.normal(loc=0, scale=1 * scale_factor, size=10000))
psi_val, df = calculate_psi(expected_data, actual_data_case3)
ks_stat, ks_pvalue = ks_2samp(expected_data, actual_data_case3)
chi2_stat, chi2_pvalue, _, _ = chi2_contingency(df[['expected', 'actual']].values)
wasserstein_dist = wasserstein_distance(expected_data, actual_data_case3)
print(f"分散の倍率 = {scale_factor:.1f}: PSI={psi_val:7.4f}, KS p-val={ks_pvalue:.4f}, Chi2 p-val={chi2_pvalue:.4f}, Wasserstein={wasserstein_dist:.4f}")
# -> 分散の倍率 = 1.1: PSI= 0.0144, KS p-val=0.0008, Chi2 p-val=0.0000, Wasserstein=0.0842
# -> 分散の倍率 = 1.2: PSI= 0.0468, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=0.1647
# -> 分散の倍率 = 1.5: PSI= 0.2386, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=0.4149
# -> 分散の倍率 = 2.0: PSI= 0.7206, KS p-val=0.0000, Chi2 p-val=0.0000, Wasserstein=0.8113
この結果から、分布のズレが大きくなるにつれて、以下の傾向が見られます。
- PSI と ワッサースタイン距離 は、ズレに比例して上昇していきます。
- KS検定 と カイ二乗検定 のp値は、僅かなズレでもすぐに0に近くなります。これは「2つの分布が統計的に有意に異なる」ことを示唆しますが、ドリフトの「大きさ」を測るのには全く向いていません。
このように、PSIやワッサースタイン距離はドリフトの度合いを定量的に評価するのに適しており、定期的に計算することでデータ分布の変化を客観的な数値として捉えることができます。
3. PSIを用いたドリフト検知の運用案
PSIを計算するだけでは不十分で、ドリフト検知の仕組みとしてシステムに組み込み、継続的に監視することが重要です。
-
監視対象:
- モデルの入力特徴量: 全ての入力特徴量を監視対象とします。特に、モデルの予測に強く寄与する重要な特徴量(Feature Importanceが高いもの)のドリフトは、モデル精度へ直接的な影響を与えるため、重点的に監視します。
- モデルの出力スコア: モデルが出力する予測スコア自体の分布も監視します。スコア分布の変化は、入力データの変化や、コンセプトドリフト(入力とターゲットの関係性の変化)の兆候である可能性があります。
-
監視の頻度と自動化:
- モデルの予測リクエストの頻度(バッチ処理かリアルタイムか)に応じて、監視の頻度(日次、週次など)を決定します。
- 監視プロセスは可能な限り自動化し、定期的にPSIを計算・記録するパイプラインを構築します。
-
閾値の設定とアラート:
- 前述の一般的な閾値(0.1, 0.25)を出発点とします。
- 全ての変数に同じ閾値を適用するのではなく、ビジネスインパクトや特徴量重要度、変数の特性や挙動に応じて調整することも有効です。 例えば、非常に重要な特徴量にはより厳しい閾値を設定する、といった対応が考えられます。
- PSIが設定した閾値を超えた場合、担当チーム(MLエンジニア、データサイエンティスト、プロダクトマネージャーなど)に自動でアラートが通知される仕組みを構築します。
- 前述の一般的な閾値(0.1, 0.25)を出発点とします。
-
ドリフト検知後のアクションフロー:
- 原因分析: アラートが発生したら、まずどの特徴量でドリフトが起きているのかを特定します。PSIの計算過程を出力することで、どのビン(値の範囲)で特に変化が大きいのかを深掘りできます。
- 影響評価: ドリフトがモデルのパフォーマンス(精度、公正性など)にどの程度影響を与えているかを評価します。
-
アクションの決定: 分析と評価の結果に基づき、以下のようなアクションを検討します。
- 静観: 一時的な変化であり、ビジネスインパクトも軽微な場合は、監視を継続します。
- データ調査: データ収集プロセスに問題がなかったかを確認します。
- モデルの再学習: ドリフトが永続的で、モデルのパフォーマンスに悪影響を与えている場合は、新しいデータを用いてモデルを再学習します。
4. PSI vs 他のドリフト検知手法
PSIはシンプルで解釈しやすい指標ですが万能ではありません。状況に応じて他の手法と比較・検討することも重要です。
| 手法 | 概要 | 長所 | 短所・注意点 |
|---|---|---|---|
| PSI | ビン分割に基づいて分布の変化を定量化する。 | ・解釈性が高い(どのビンで変化したか分かる)。 ・ドリフトの度合いを直感的な数値で把握できる。 ・カテゴリカル/数値変数に適用可能。 |
・ビンの切り方によって値が変わる可能性がある。 ・特徴量間の相関の変化は捉えられない。 |
| KS検定 (コルモゴロフ–スミルノフ検定) | 2つのサンプルの累積分布関数の差の最大値に基づくノンパラメトリック検定。 | ・ビニングが不要。 ・分布全体の形状の差に敏感。 |
・連続変数にのみ適用可能。 ・分布の「差の有無」は分かるが「差の大きさ」は分かりにくい。 |
| カイ二乗検定 (χ²検定) | カテゴリカルデータの観測度数と期待度数の差を検定する。 | ・カテゴリカル変数の分布変化の検定に適している。 | ・期待度数が小さいセルがあると信頼性が低下する。 ・KS検定と同様、「差の大きさ」は分かりにくい。 |
| ワッサースタイン距離 | 一方の分布をもう一方の分布に変化させる際の「最小コスト」で距離を測る。 | ・分布の形状が重ならない場合でも意味のある距離を計算できる。 ・ドリフトの度合いを数学的に厳密に測れる。 |
・計算コストが比較的高くなる場合がある。 ・PSIに比べて値の解釈が直感的ではない場合がある。 |
Appendix. A. PSIの数学的定義とその解説
一言でいうと、PSIはKLダイバージェンスを対称化したものです。対称化されたKLダイバージェンスは、Jeffreysダイバージェンス(J-ダイバージェンスとも)として知られています。このことを以下で解説します。
ある確率変数(論文の文脈ではクレジットスコア)のとりうる値の空間を、互いに素な $K$ 個の集合(ビン、あるいはカテゴリ) $B_1, B_2, \dots, B_K$ に分割します。
- 参照分布 (Reference Distribution): モデル開発時("Development population")の確率分布を $P$ とします。この分布において、観測がビン $B_i$ に属する確率を $p_i = P(B_i)$ とします。当然、$\sum_{i=1}^{K} p_i = 1$ かつ $p_i > 0$ です。
- 現在分布 (Current Distribution): 比較対象となる現在("Current population")の確率分布を $Q$ とします。同様に、観測がビン $B_i$ に属する確率を $q_i = Q(B_i)$ とします。$\sum_{i=1}^{K} q_i = 1$ かつ $q_i > 0$ です。
このとき、Population Stability Index (PSI) は次式で与えられます。
$$
\text{PSI}(Q, P) := \sum_{i=1}^{K} (q_i - p_i) \ln\left(\frac{q_i}{p_i}\right)
$$
実務上、確率 $p_i, q_i$ は、それぞれの母集団から得られたサンプルにおける各ビンの相対度数によって推定されます。
カルバック・ライブラー(KL)ダイバージェンスとの関係
2つの確率分布 $P, Q$ が与えられたとき、分布 $Q$ の分布 $P$ に対するKLダイバージェンス $D_{\text{KL}}(Q | P)$ は以下で定義されます。
$$
D_{\text{KL}}(Q | P) := \sum_{i=1}^{K} q_i \ln\left(\frac{q_i}{p_i}\right)
$$
ギブスの不等式から $D_{\text{KL}}(Q | P) \ge 0$ であり、等号成立は $Q=P$ のときに限られます。対称性 ($D_{\text{KL}}(Q | P) \neq D_{\text{KL}}(P | Q)$) や三角不等式を満たさないため、厳密な意味での距離計量(metric)ではありません。なのでダイバージェンス(乖離度)と呼ばれます。
さて、PSIの定義式を変形すると以下が成り立ちます:
$$
\begin{aligned}
\text{PSI}(Q, P) &= \sum_{i=1}^{K} (q_i - p_i) \ln\left(\frac{q_i}{p_i}\right) \\
&= \sum_{i=1}^{K} q_i \ln\left(\frac{q_i}{p_i}\right) - \sum_{i=1}^{K} p_i \ln\left(\frac{q_i}{p_i}\right) \\
&= \sum_{i=1}^{K} q_i \ln\left(\frac{q_i}{p_i}\right) + \sum_{i=1}^{K} p_i \ln\left(\frac{p_i}{q_i}\right) \\
&= D_{\text{KL}}(Q | P) + D_{\text{KL}}(P | Q)
\end{aligned}
$$
つまり、PSIはKLダイバージェンスを対称化したものです:
$$
J(Q, P) := D_{\text{KL}}(Q | P) + D_{\text{KL}}(P | Q) = \text{PSI}(Q, P)
$$
PSIの指標としての妥当性
上で述べた通り、PSIは本質的にKLダイバージェンスと同じものを測っているので、確率分布間の乖離度合いを測る指標としてはそこそこ妥当なものです。もう少し詳しく言うと、以下の性質があるので、わりと直感的に安心して計算・運用が可能です:
- KLダイバージェンスという情報理論の根幹をなす概念に由来するので理論的正当性が高い。
- 対称性があり、2つの分布間の「隔たり」を直感的に捉えることができる。
- PSIを構成する各項が分布変化への寄与度として解釈可能であり、モデル劣化の原因究明に繋げやすい。
参考文献
- Karakoulas, G. (2004). Empirical Validation of Retail Credit-Scoring Models. The RMA Journal, 87, 56–60.
- Coralogix. (n.d.). A Practical Introduction to Population Stability Index (PSI). [Online]. Available: https://coralogix.com/ai-blog/a-practical-introduction-to-population-stability-index-psi/