はじめに
Cloud DataflowのSDKを始めて使う人向けです。
Cloud Dataflow Python SDKのサンプルコードを使ってパイプラインの実行と動作確認をしていこうと思います。
前提条件
Google Cloud Platform(GCP)が利用出来る状態で1つ以上のプロジェクトを作成済み
実行環境
GCPのGoogle Cloud Shellを使用
手順
GCPのCloud Dataflowのドキュメントにある「Pythonを使用したクイックスタート」の手順で進めていきます。
Pythonを使用したクイックスタートはこちらを参照してください。
https://cloud.google.com/dataflow/docs/quickstarts/quickstart-python
私だけなのか手順どおりに進めても途中で詰まってしまったところがあるので対応したことを書いていきます。
始める前に
ステップ1から3
手順どおり進めていけば問題なし。
ステップ4 Cloud SDKをインストール
Cloud Shellを使うのでスキップ。
ステップ5 Cloud Storageバケットを作成
バケット名はpython-test-dataflowで作成。
pip と Dataflow SDK をインストールする
ステップ1 pipをインストール
Google Cloud Shellを使う場合はスキップできると書いてあるのでスキップ。
ステップ2 最新のDataflow SDK for Pythonをインストール
Cloud Shellを起動し以下を実行。
pip install google-cloud-dataflow
以下のようなメッセージが出るのでpipのアップグレードを実施。
You are using pip version 8.1.1, however version 9.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
pipアップグレード&Dataflow SDK for Pythonインストール。
sudo pip install --upgrade pip
pip install google-cloud-dataflow
今度はSDKのインストールで以下のようなエラーが発生・・・
Command "/usr/bin/python -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-cJ1Pwd/avro/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-rqFM9W-record/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /tmp/pip-build-cJ1Pwd/avro/
色々試したところ以下のコマンドでうまくいきました。
pip install google-cloud-dataflow --user
※ --userが必要
参考:http://googlecloudplatform-japan.blogspot.jp/2016/08/cloud-dataflow-python-sdk.html
ステップ3 wordcount.py の例をローカルで実行
python -m apache_beam.examples.wordcount --output OUTPUT_FILE
上記コマンドを実行後に、以下のメッセージが出ましたがドキュメントにこのようなメッセージが出る場合があると書かれていたので気にせず先に進む。
INFO:root:Missing pipeline option (runner). Executing pipeline using the default runner: DirectPipelineRunner.
INFO:oauth2client.client:Attempting refresh to obtain initial access_token
パイプラインの例をリモートで実行する
ステップ1 環境変数の設定
Cloud Shellで以下を実行。
export PROJECT=プロジェクトID
export BUCKET=gs://python-test-dataflow
ステップ2 wordcount.py の例をリモートで実行
python -m apache_beam.examples.wordcount \
--project $PROJECT \
--job_name $PROJECT-wordcount \
--runner BlockingDataflowPipelineRunner \
--staging_location $BUCKET/staging \
--temp_location $BUCKET/temp \
--output $BUCKET/output
ステップ3 ジョブの確認
GCPコンソールのDataflowからジョブを確認。
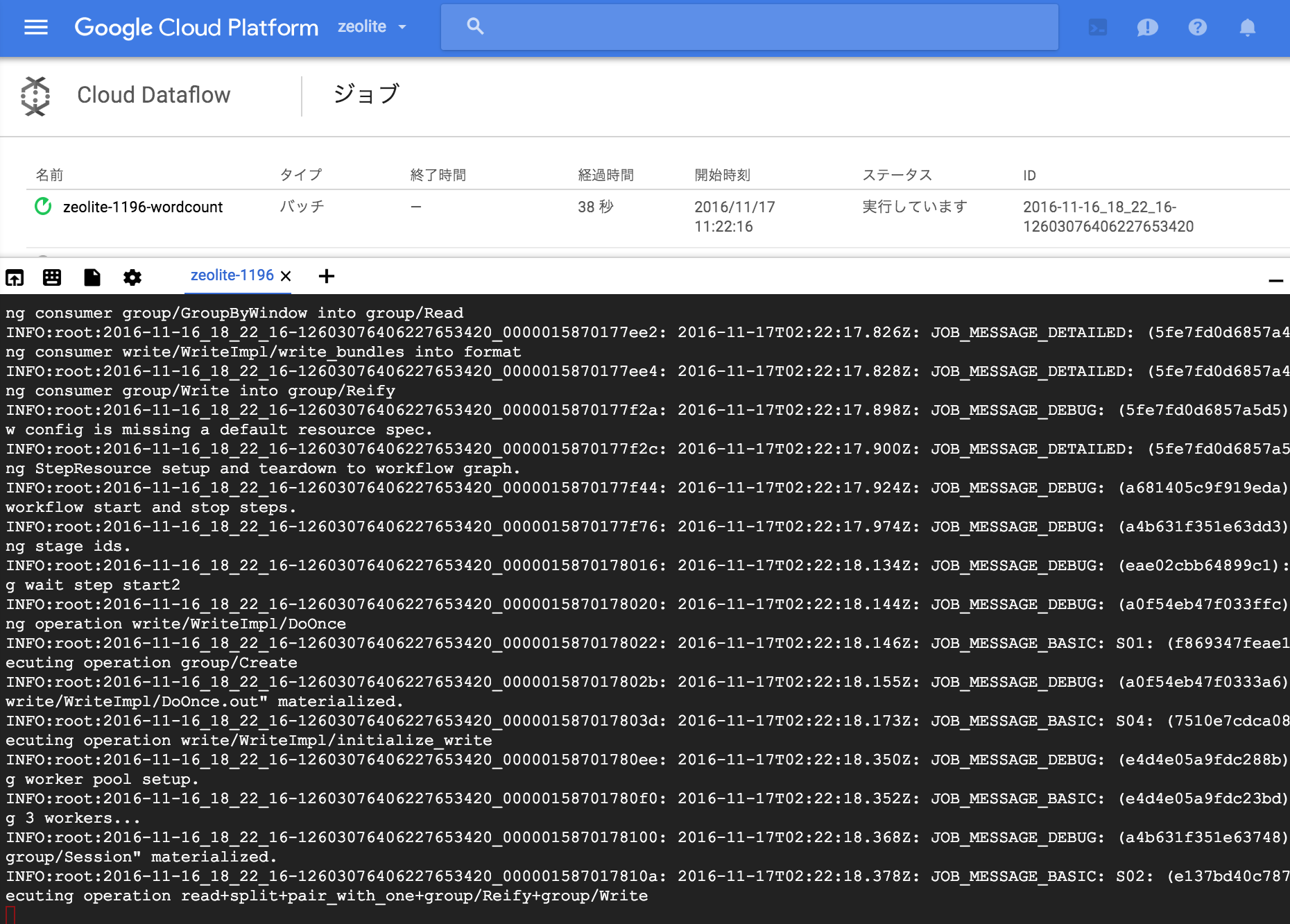
ジョブの詳細
実行したサンプルコード
https://github.com/apache/incubator-beam/blob/python-sdk/sdks/python/apache_beam/examples/wordcount.py
※サンプルコードはおそらくこれであっていると思いますが間違っていたらすみません。
# Read the text file[pattern] into a PCollection.
lines = p | 'read' >> beam.io.Read(beam.io.TextFileSource(known_args.input))
# Count the occurrences of each word.
counts = (lines
| 'split' >> (beam.ParDo(WordExtractingDoFn())
.with_output_types(unicode))
| 'pair_with_one' >> beam.Map(lambda x: (x, 1))
| 'group' >> beam.GroupByKey()
| 'count' >> beam.Map(lambda (word, ones): (word, sum(ones))))
# Format the counts into a PCollection of strings.
output = counts | 'format' >> beam.Map(lambda (word, c): '%s: %s' % (word, c))
# Write the output using a "Write" transform that has side effects.
# pylint: disable=expression-not-assigned
output | 'write' >> beam.io.Write(beam.io.TextFileSink(known_args.output))
ジョブの詳細でread,split,・・・writeの処理がどのように行われているか確認することができます。
例)read

例)split

ジョブによって作成されたファイルを確認。
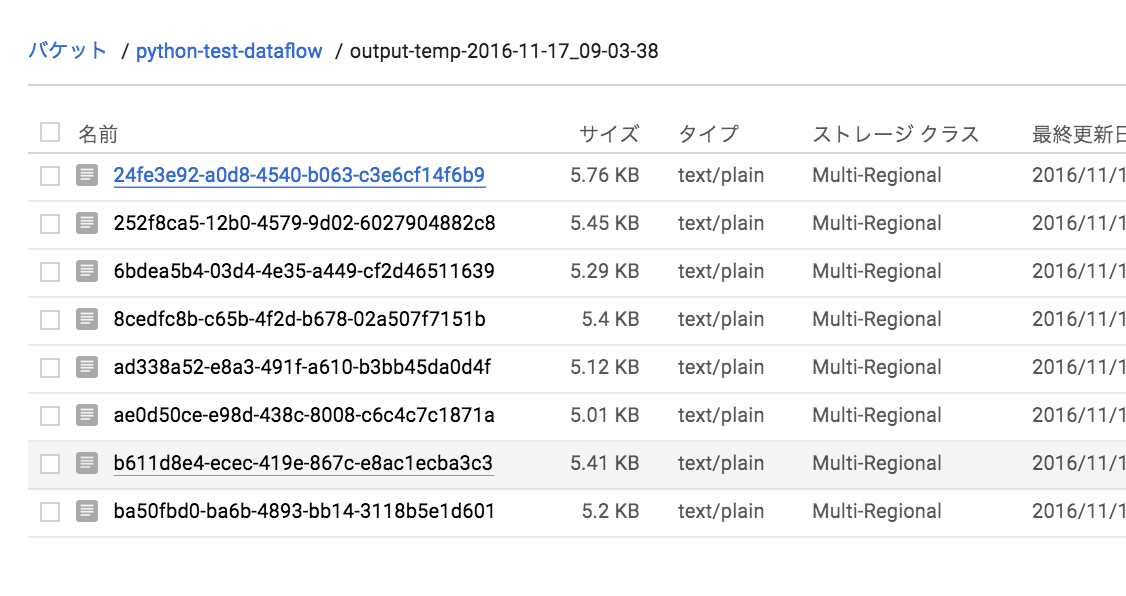
ファイルの中身。

おわりに
Cloud ShellとCloud Dataflow Python SDKでDataflowの流れを確認することができました。
Cloud Dataflow Python SDKはまだベータ版のようなので実際に使うにはJava SDKの方がいいかもしれません。
Dataflowのドキュメントに次のように書かれてました。
重要: このドキュメントには、制限なし PCollection とウィンドウ処理の情報が含まれます。
これらの概念は Dataflow Java SDK のみに該当します。
Dataflow Python SDK ではまだ使用できません。
2016/11現在、Python SDKではストリーム処理はできないようです。
Java SDKを使ってストリーム処理を試してみたいという方はこちらをご覧ください。
GoogleCloudで汎用Database構築2 - DataFlow2 -