GYAOのtsです。
我々のチームは、オールパブリッククラウドで、Microservice Architectureを採用した次期バックエンドを設計中です。
経緯
前回の投稿で、DataFlowの前提知識をいくつかまとめたので、早速ハンズオンしてみる。
今回の目指すところ
今回もチーム内のメンバー全員でイベントチックに構築してみる。
やりたいことは以下。
- pubsubにrest形式でメッセージをpublish
- dataflowのstream modeで処理を行う
- メッセージをsubscribe
- ランダムな文字列を発行
- 発行した文字列をキーにCloudDataStoreに登録。
pubsubにrest形式でメッセージをpublishする前に、Apigeeを置いて連携したいが、それは後ほど。
準備
Cloud Storage
Cloud Storageに転送→同時にGCEのインスタンスが起動→deployのような形になっているようなので、転送先のバケットを作成する。(Eclipseからも作成可能。)
↓
↓
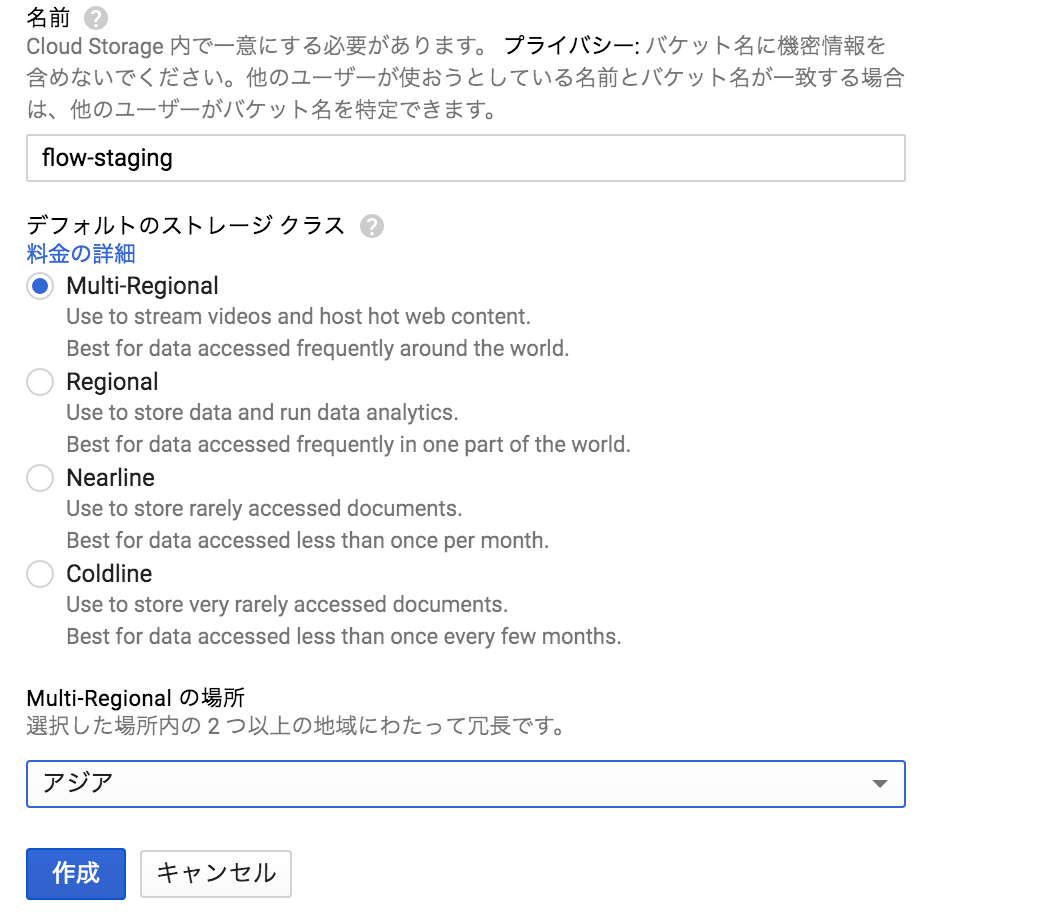
flow-stagingという名前で作成。
Cloud Pub/Sub
Cloud Pub/SubからStreamデータを購読してその内容をstoreするので、topicを作成する。
↓

↓
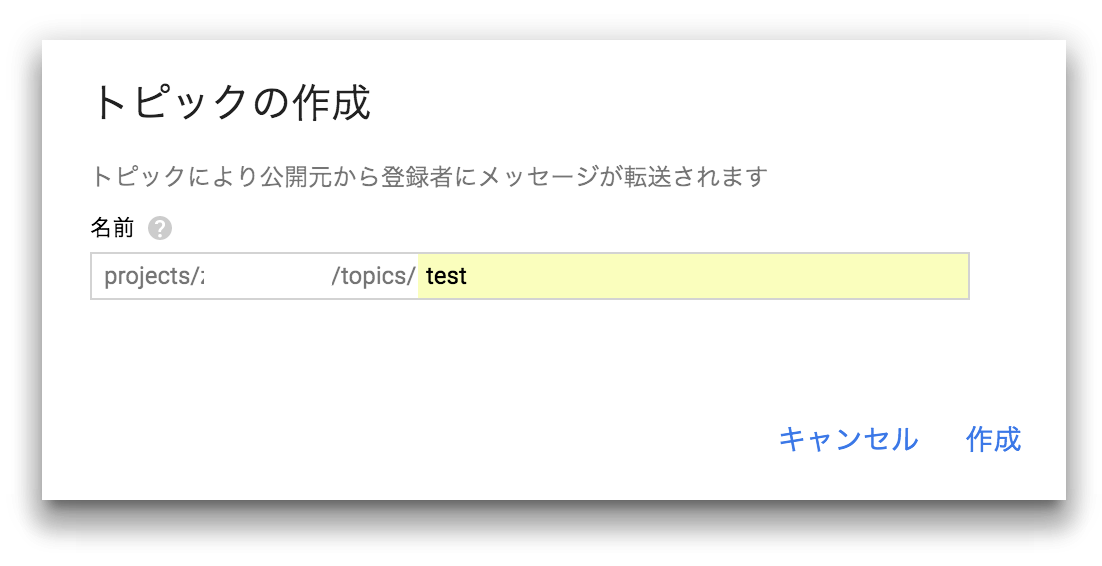
テストトピックを作成。
Cloud DataStore
特に準備の必要はなし。
setup
ここからはオフィシャルに沿ってすすめる。
Cloud SDK
 Source: https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-eclipse
Source: https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-eclipse
- 1~3は普通に作成、有効にする。
- 4 Eclipseで開発するマシンにCloudSDKをインストール。
- install後、下記を実行。
gcloud beta auth application-default login- eclipseからのauthの設定 こちらのオフィシャルを参照。
- install後、下記を実行。
- 5、6もその通りにEclipse Luna以上、JDK1.7以上の構成で。
Eclipse
今回はEclipse neonを使用。
jdk1.8
Eclipseにはアップデートサイトhttps://dl.google.com/dataflow/eclipse/ からプラグインをインストールしておく。
Pipeline作成
Eclipseプラグインのお陰で簡単にプロジェクトが作成できる。(Mavenでも構築可能)
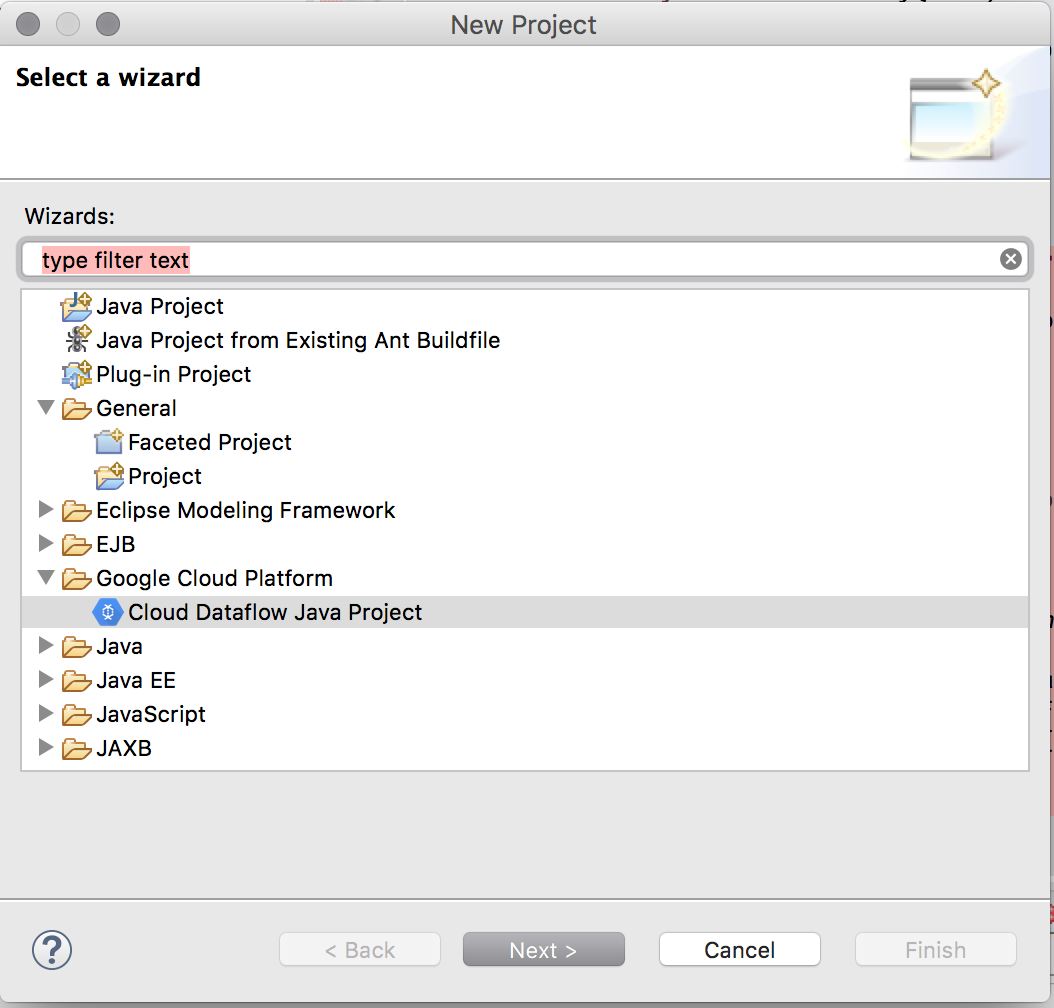
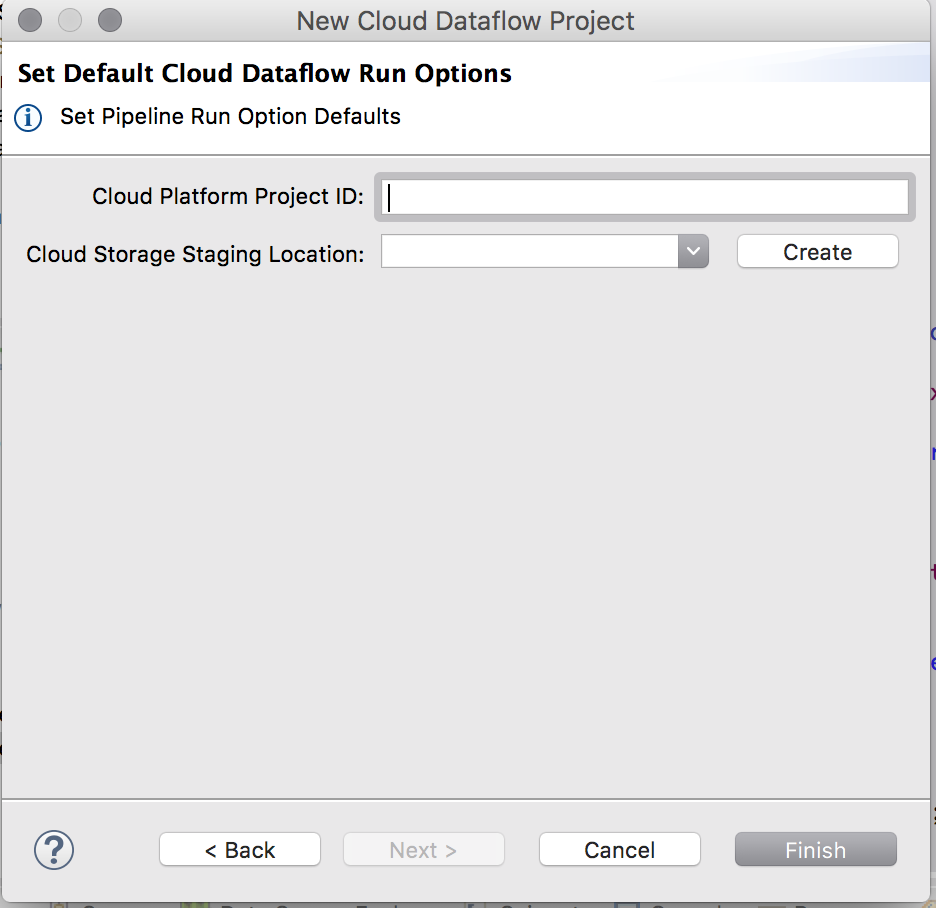
すすめるとProjectIDとLocationをの入力画面があるので、入力する。
| 項目 | 概要 |
|---|---|
| ProjectID | 自分のプロジェクトのID |
| Location | 先程作成したCloudStorageのLocation。この場合はgs://flow-staging プルダウンで出てきます。 |
Coding
Pipelineは指定されたクラスのmainメソッドの中で構築する。Google提供のサンプルを少しいじって以下のようにしてみた。
public static void main(String[] args) throws IOException {
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
options.setDataset("xxxxxx"); //ProjectId
options.setKind("data"); //Datastoreのkind
options.setNamespace("default"); //Datastoreのnamespace
options.setJobName("store-job"); //Deployされたあと、一覧に出るJobの名前。
options.setStreaming(true); //streamingモードの有効化
Pipeline pipeline = Pipeline.create(options); //パイプライン作成
PCollection<String> input;
LOG.info("Reading from PubSub.");
input = pipeline.apply(PubsubIO.Read.named("subscriber").topic("projects/xxxxxxxxx/topics/test")) //Pub/Subの購読をapply
.apply(Window.<String>into(SlidingWindows.of(Duration.standardMinutes(1)).every(Duration.standardSeconds(10)))); //pubsubのinputはunboundedなので、boundedの処理を行うためにwindowを使用(1分間間隔のwindow。10秒毎に新しいwindowを生成)
input.apply(ParDo.of(new CreateEntityFn(options.getNamespace(), options.getKind()))) //
.apply(DatastoreIO.v1().write().withProjectId(options.getDataset()));
pipeline.run();
}
CreateEntityFnは下記の通り
static class CreateEntityFn extends DoFn<String, Entity> {
private final String namespace;
private final String kind;
private final com.google.datastore.v1.Key ancestorKey;
CreateEntityFn(String namespace, String kind) {
this.namespace = namespace;
this.kind = kind;
ancestorKey = makeAncestorKey(namespace, kind);
}
public Entity makeEntity(String content) {
Entity.Builder entityBuilder = Entity.newBuilder();
Key.Builder keyBuilder = makeKey(ancestorKey, kind, UUID.randomUUID().toString());
if (namespace != null) {
keyBuilder.getPartitionIdBuilder().setNamespaceId(namespace);
}
else {
//do nothing.
}
entityBuilder.setKey(keyBuilder.build());
entityBuilder.getMutableProperties().put("content", makeValue(content).build());
LOG.info("create Entity included content : " + content);
return entityBuilder.build();
}
@Override
public void processElement(ProcessContext c) {
c.output(makeEntity(c.element()));
}
}
Deploy
EclipseのRun→Run Configurationsで下記を作成
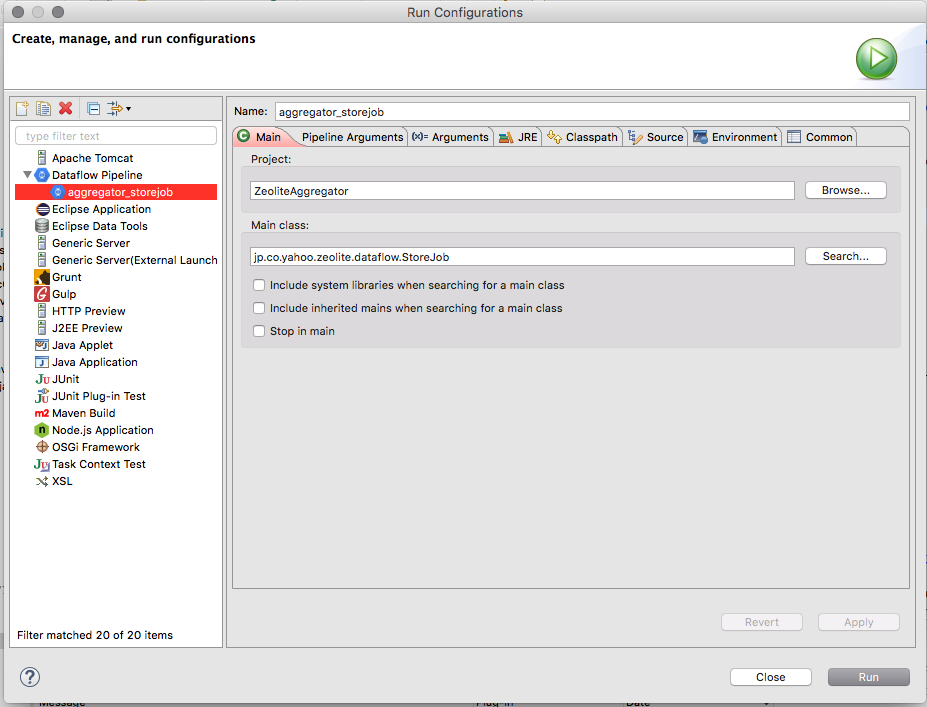
MainClassを指定。
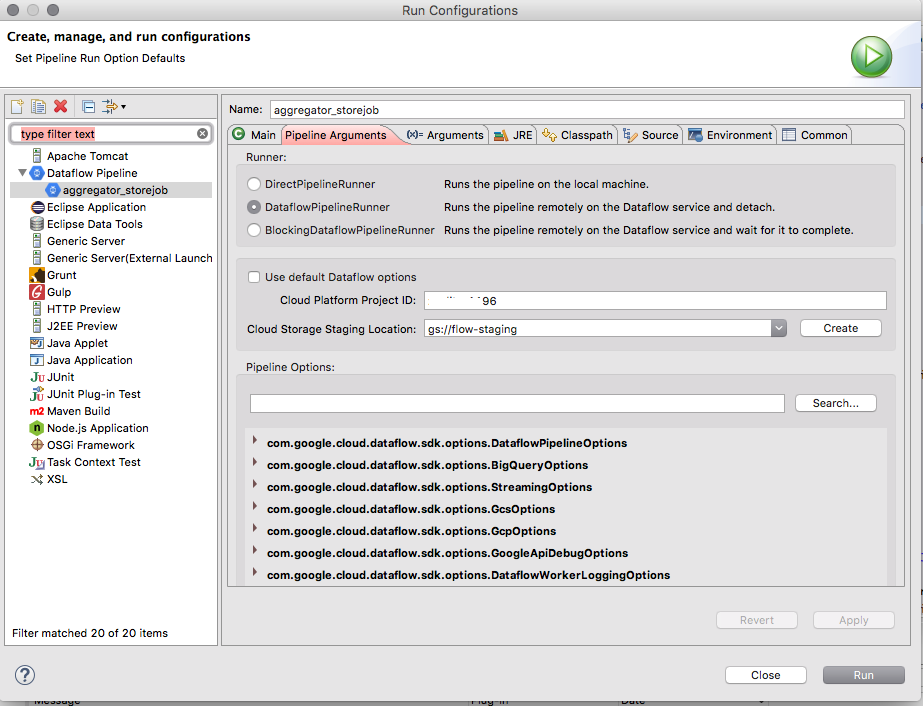
projectIdと
staging Locationを指定。
DataflowPipelineRunnerを使用する。PipelineRunnerに関しては前回の投稿を参照
Run。以上。
CloudStorageの指定バケットにStagingとして保存される。
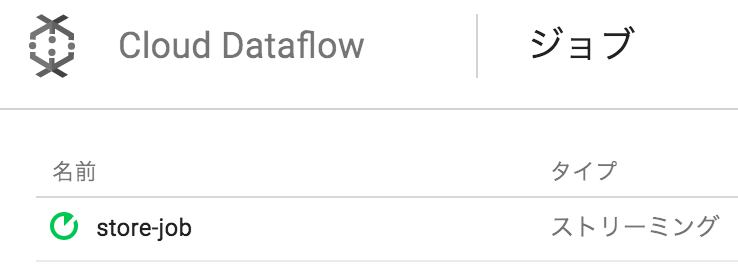
Dataflowのコンソールでjobを確認することができる。
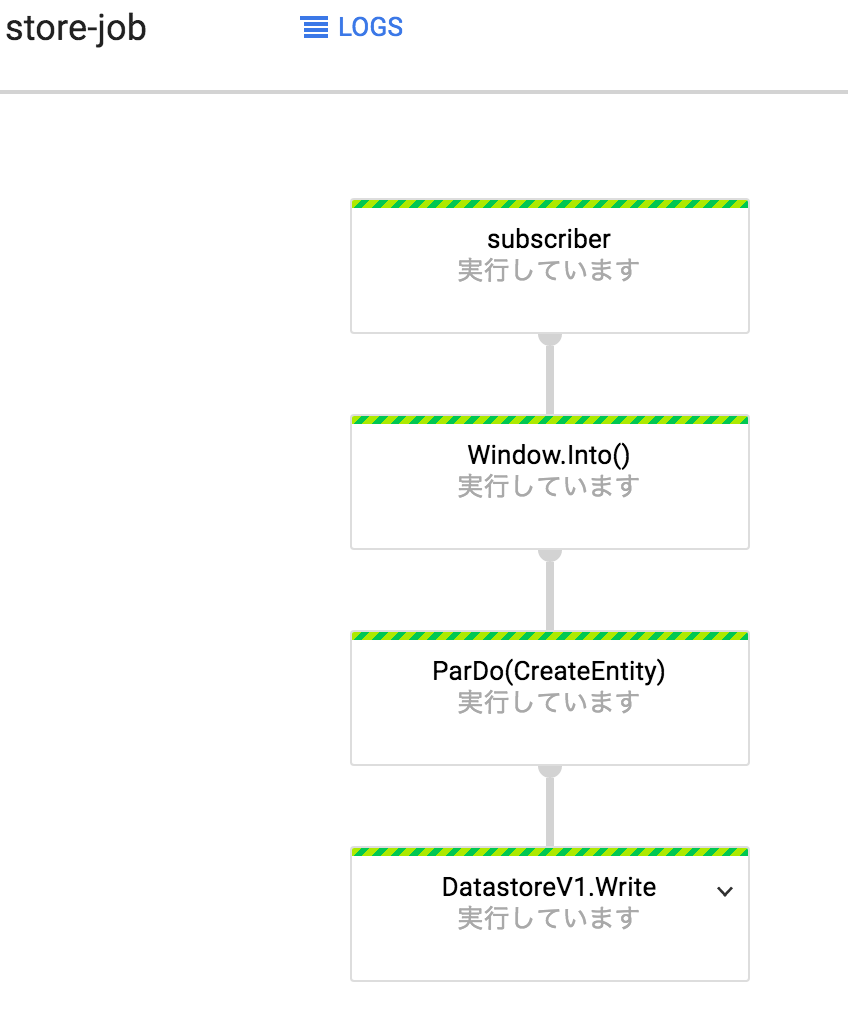
実行

pubsubのtopicを見ると、subscriptionが登録されているのがわかる。
それでは実際にpubsubにpushしてみる。
 公開ボタンから
公開ボタンから
 適当にメッセージング
適当にメッセージング
 Dataflowの画面では要素数がリアルタイムで1にかわる。
Dataflowの画面では要素数がリアルタイムで1にかわる。
 Logs→ワーカーログでログを見てみると、Entityが作成されたのがわかる。
Logs→ワーカーログでログを見てみると、Entityが作成されたのがわかる。
 データストアのdefault名前空間を見てみると、data kindに
データストアのdefault名前空間を見てみると、data kindに
 保存を確認。
保存を確認。
次回
前回の投稿で、Cloud Pub/Subで順序性が保証されないことに気付いたので、設計を少し変えようかと。