面白いダジャレを言うと、何が起こるでしょうか。
そうです。布団が吹っ飛びます。

今回は、ダジャレを心から愛するブレインパッドのメンバー4人が制作した、最新ダジャレAIを搭載した次世代型おもしろダジャレ検知マシン『オフトゥンフライングシステム』のご紹介をさせて頂きます。

※補足&感謝
- 面白いと布団が吹っ飛ぶという発想は日テレ系列の大喜利番組「フットンダ」のリスペクトです
- 「オフトゥンフライングシステム」という名前はボーカロイドソング、『オフトゥンフライングシステム』があまりにもイメージとぴったり合ったため、名前を使わせていただきました。こちらの曲を無限ループしながら記事を読んでいただけると、より楽しめる仕組みになっております
Product Summary
オフトゥンフライングシステムとは何か。分かりやすく説明すると、ダジャレ検知AI『Shareka』とダジャレ評価AI『Ukeruka』が搭載された、布団がふっとんだマシンです。

動作の流れ
- ブラウザ上のフォームからダジャレを入力する
- ダジャレかどうかの判別
- (ダジャレと判定された場合)ダジャレの面白さ評価
- 結果が画面に表示される
- さらにダジャレ評価が50点を超えた場合、布団が吹っ飛ぶという仕組みになっています。
- 投稿されたダジャレと評価点はGCPのdatastoreに保存
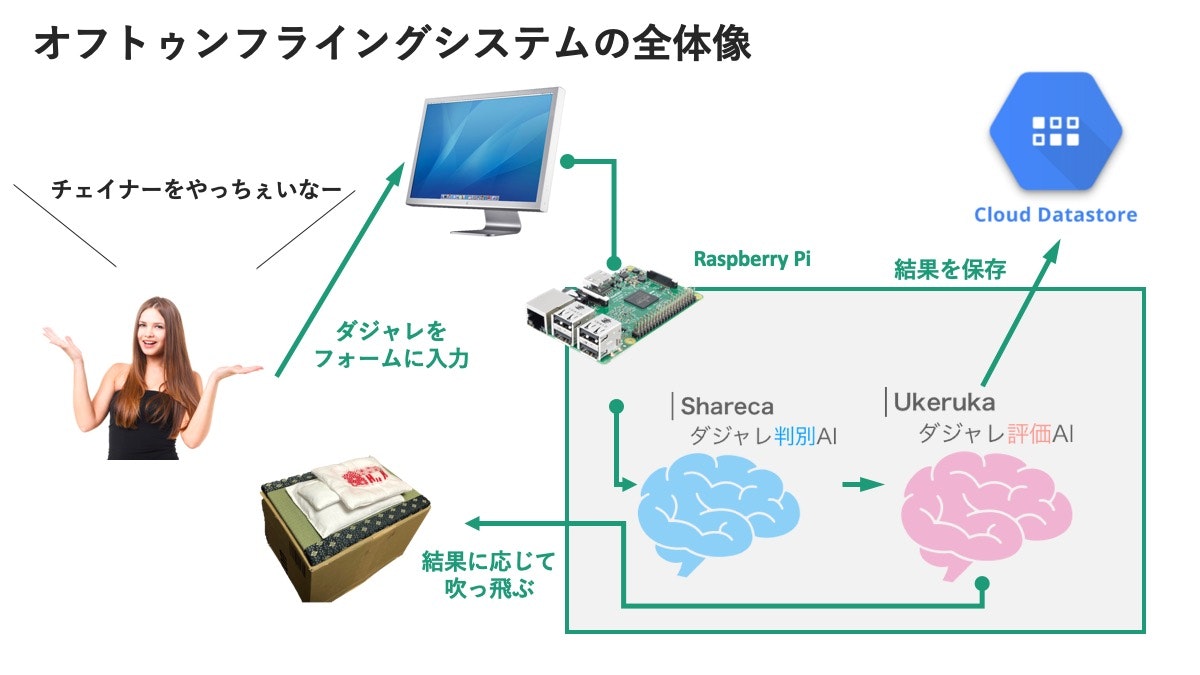
面白いダジャレ(例:裏面のラーメン)を入力した場合
表示画面
ふとん

つまらないダジャレ(例:バラバラの薔薇)を入力した場合
表示画面
ふとん

ダジャレじゃない文(例:ダジャレが思いつきません)を入力した場合
表示画面
ふとん

また、自分のスコアの下には過去の投稿ダジャレが並んでおり、過去の投稿と比較可能となっています。
そのため、より面白いダジャレを生み出すためのダジャレPDCAを高速に回すことができます。
Our Mission
『自分はこんなにもおもしろいダジャレを言っているのに、誰も笑ってくれない。。。むしろスベったみたいな空気になってる。。。』
こんなダジャレに悩むすべての人のためにオフトゥンフライングシステムは作られました。
ダジャレを言ったのに、いまいちウケないと感じたときはすぐさまオフトゥンフライングシステムにそのダジャレを入力することで、AIがダジャレの面白さを判定してくれます。
面白いと判定された場合、「AIが面白いと言っているから笑わないお前がおかしい。」と相手にマウントをとることができます。
また、ダジャレの内容関係なく そもそも布団が吹っ飛ぶことが面白い ので、相手も笑ってくれるでしょう。
え、面白く無いと判定されたときはどうすればいいかって?
「AIにもすべったわ〜ww」
と自虐ネタで笑いを取ることができます。
Our Technology
オフトゥンフライングシステムは4つのテクノロジーによって成り立っています。
ひとつずつ解説していきます。
Shareka 〜ダジャレ判別AI〜
Sharekaは入力された文章がダジャレかどうかを判定するAIです。
ダジャレとはなにか
そもそも、ダジャレとはなにか。ダジャレは一般に知られているよりも幅が広いです。

2018年12月現在、Sharekaで対応可能なダジャレは、「完全反復型」「不完全反復型」のみであり、「変形反復型」「潜在表現重複型」は対応していません。
これらに対応するためには、音韻(読み)だけでなく、語の「意味」や「知識」をモデルに入れ込む必要があり、難易度がぐっと高くなります。
利用するデータ
以降で利用するダジャレデータは以下サイトからスクレイピングで集めました。
ダジャレ・ステーション
このサイトでは、投稿されたダジャレに対して5点満点で評価する事もできるため、各ダジャレに対して評価点がついています。
結果、45,000ものダジャレとその評価点を集めることができました。
また、ダジャレ判別モデルの評価をするためにダジャレじゃないデータも集める必要があります。ダジャレじゃなければ何でも良いわけではなく、ダジャレとだいたい同じ長さの文章である必要があります。
今回は、以下のサイトで用いられている、ラノベ・小説のタイトルをダジャレじゃないデータとして用いました。
https://qiita.com/fj-th/items/3868a4aef834a9bee980
結果、全部で約50,000ものダジャレじゃない文が集まりました。
ルールベースによるアプローチ
※ルールベースは人工知能ではないと言い張る人は、第2次人工知能ブームでググってください。
手法
以下のようなルールベースで入力した文がダジャレかどうかを判別します。
1. 入力文をすべてカタカナに変える
2. 記号、長音(ー)、促音(ッ)を削除、小文字(ァ・ェ・ャ)などを大文字に変換
3. 1字ずつずらしてn文字ずつの要素を作成し、重複している要素がある場合にダジャレと判定する
例えば、布団がふっとんだという超おもしろダジャレを判別する場合、
布団がふっとんだ
↓
フトンガフットンダ
↓
フトンガフトンダ
↓
['フトン', 'トンガ', 'ンガフ', 'ガフト', 'フトン', 'トンダ']
⇒**'フトン'が重複しているため、ダジャレと判別**
コード
こちらがダジャレを分類するコード全文になります。
import MeCab
import collections
from flask import Blueprint
class Shareka:
def __init__(self, sentence, n=3):
"""置き換える文字リストが格納されたクラス変数"""
self.replace_words = [["。", ""],["、", ""], [",", ""],[".", ""],["!", ""],
["!", ""],["・", ""],["「", ""],["」", ""], ["「", ""],["」", ""],["『", ""],["』", ""],[" ", ""],[" ", ""],
["ッ", ""],["ャ", "ヤ"], ["ュ", "ユ"],["ョ", "ヨ"],
["ァ", "ア"],["ィ", "イ"],["ゥ", "ウ"],["ェ", "エ"],["ォ", "オ"],["ー", ""]]
self.kaburi = n
self.sentence = sentence
mecab = MeCab.Tagger("-Oyomi")
self.kana = mecab.parse(sentence)[:-1]
self.preprocessed = self.preprocessing(self.kana)
self.devided = self.devide(self.preprocessed)
def preprocessing(self, sentence):
for i, replace_word in enumerate(self.replace_words):
sentence = sentence.replace(replace_word[0],replace_word[1])
return sentence
def devide(self, sentence):
elements = []
repeat_num = len(sentence) - (self.kaburi - 1)
for i in range(repeat_num):
elements.append(sentence[i:i+self.kaburi])
return elements
def dajarewake(self):
if len(self.devided) == 0:
return False
elif self.list_max_dup()[1] > 1 and self.sentence_max_dup_rate(self.list_max_dup()[0]) <= 0.5:
return True
else:
return False
結果(精度)
ダジャレ45,000件と、ダジャレじゃない文50,000件を上記のコードを用いて、複数パターンのパラメータでそれぞれ判別した結果、以下のようになりました。
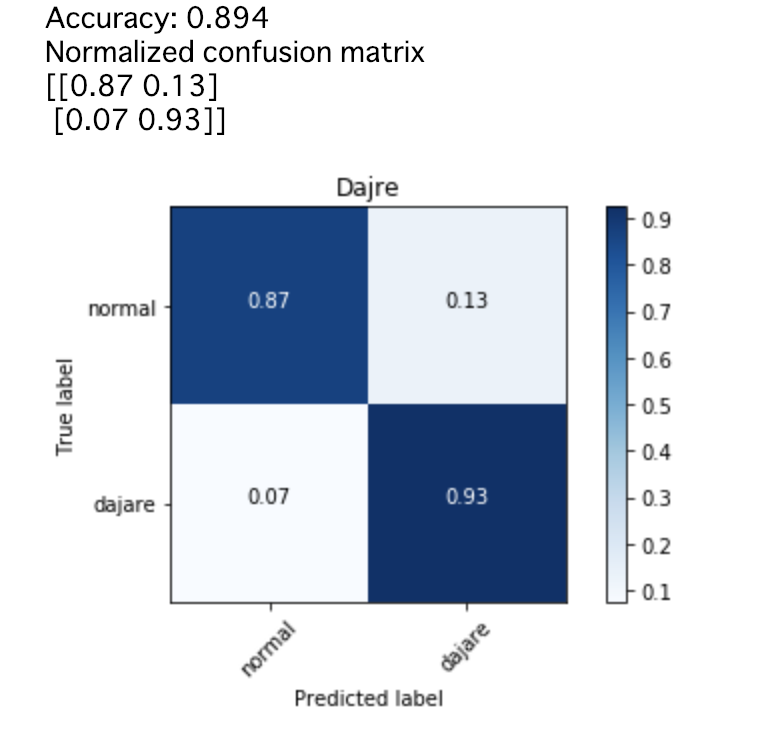
n=2(2文字以上の並びが繰り返されている場合にダジャレと判定)
全体の正解率:89%
ダジャレをダジャレと正しく判定する割合:93%
通常文を通常文と正しく判定する割合:87%
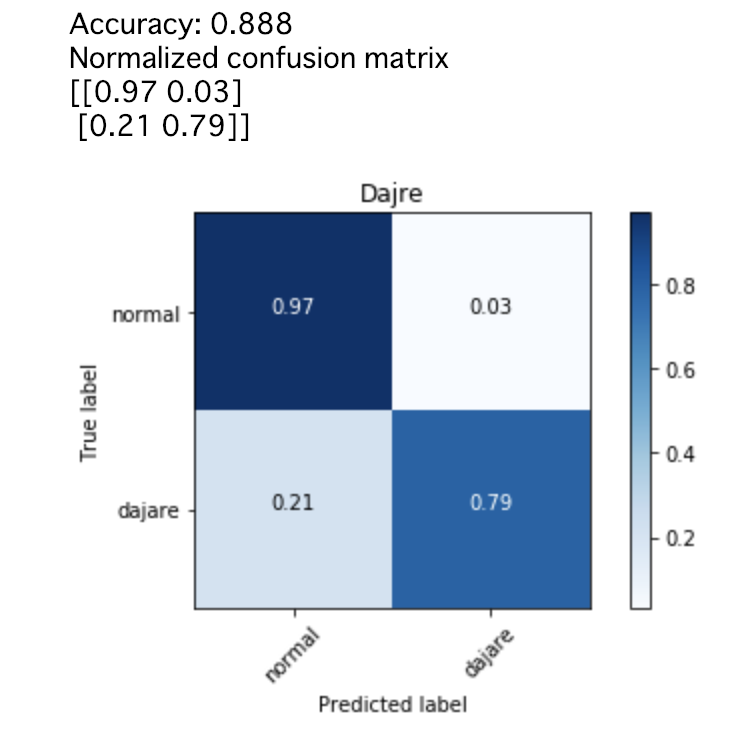
n=3(3文字以上の並びが繰り返されている場合にダジャレと判定)
(『猫が寝転んだ』はダジャレではないと判定)
全体の正解率:88%
ダジャレをダジャレと正しく判定する割合:79%
通常文を通常文と正しく判定する割合:97%
どちらも正解率はほぼ変わらず約89%となりましたが、
ダジャレ判定判定が緩い場合(n=2)、通常文をダジャレと誤判定する場合が多く、
ダジャレ判定判定が厳しい場合(n=3)、ダジャレを通常文と誤判定する場合が多くなります。
せっかくダジャレを入力したのに「ダジャレではない」と判別されてしまうのはあまりにも可哀想なので、今回はSharekaのパラメータn=2を採用しています。
Ukeruka 〜ダジャレ評価AI〜
Ukerukaは、入力されたダジャレに対して、「面白い」もしくは「面白くない」と評価をするAIです。こちらはダジャレかどうかを判別するよりもかなり難易度が高いことです。
何を面白い、何を面白くないと定義するか
難易度が高い理由のひとつに、人間でもダジャレの面白さを判定できない、という大問題があります。
今回は、ダジャレ・ステーションに投稿されたダジャレそれぞれに付いている平均評価点を「面白さ」と定義し
平均評価点3以上 ⇒ 面白い
平均評価点3未満 ⇒ 面白くない
の2値分類でディープラーニングのモデルを構築します。
手法
言語処理に対してディープラーニングを実施する際は、まず文を単語単位で区切る処理(形態素解析)を施すことが多いです。
例えば、『今日はいい天気ですね』という文を単語で区切った場合このようになります。
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ
天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ
ただし、ダジャレに対して同じことをすると問題が生じます。
例えば、『アルミ缶の上にあるみかん』に対して同じことをすると。
アルミ 名詞,一般,*,*,*,*,アルミ,アルミ,アルミ
缶 名詞,一般,*,*,*,*,缶,カン,カン
の 助詞,連体化,*,*,*,*,の,ノ,ノ
上 名詞,非自立,副詞可能,*,*,*,上,ウエ,ウエ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
ある 動詞,自立,*,*,五段・ラ行,基本形,ある,アル,アル
みかん 名詞,一般,*,*,*,*,みかん,ミカン,ミカン
のように分解されますが、「アルミ缶」と「あるみかん」が反復されているダジャレなのに、単語で分類することによってバラバラになってしまっています。
この問題を解決するため、今回はcharacter-level CNNという手法に目をつけました。
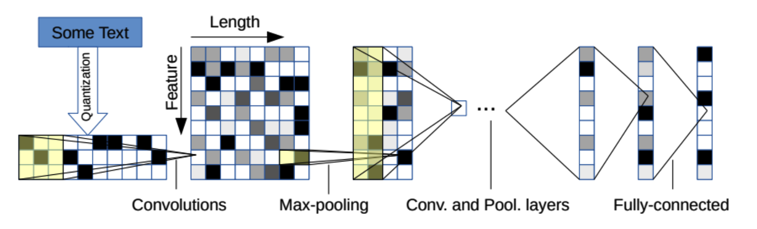
元論文
character-level CNNの特徴をズバリ説明すると、文章を単語単位ではなく、1文字単位で処理することにあります。

単語で潰さず文字単位で学習することでダジャレ特有の音韻の反復を学習することができるのではないかと考えました。
(追記)character-level CNNを利用した真の理由は、この手法の日本語名が『畳み込みニューラルネットワーク』であり、畳が使われている本システムとの相性が良いから、ということをすっかり忘れていました。上記は参考程度にお読みください。
コード
学習に用いたコードはこちらの記事を参考に作成しました。
Character-level CNNでライトノベルっぽさを定量化する
学習部のコードのみ掲載します。
# coding: utf-8
import numpy as np
import keras
from keras.optimizers import *
from keras.layers import *
from keras.callbacks import *
from keras.models import *
from numpy import *
import codecs
def create_model(embed_size=32, max_length=30, filter_sizes=(2, 3, 4, 5), filter_num=64):
inp = Input(shape=(max_length,))
emb = Embedding(0xffff, embed_size,embeddings_regularizer=regularizers.l1(0.01))(inp)
emb_ex = Reshape((max_length, embed_size, 1))(emb)
convs = []
for filter_size in filter_sizes:
conv = Conv2D(filter_num, (filter_size, embed_size), activation="relu")(emb_ex)
pool = MaxPooling2D(pool_size=(max_length - filter_size + 1, 1))(conv)
convs.append(pool)
convs_merged = Concatenate()(convs)
reshape = Reshape((filter_num * len(filter_sizes),))(convs_merged)
fc1 = Dense(32, activation="relu")(reshape)
bn1 = BatchNormalization()(fc1)
fc2 = Dense(1, activation='sigmoid')(bn1)
model = Model(input=inp, output=fc2)
return model
def load_data(filepath, targets, max_length=30, min_length=1):
titles = []
tmp_comments = []
with codecs.open(filepath, 'r', 'utf-8', 'ignore') as f:
for l in f:
label_id, title = l.split("\t", 1)
if label_id != "0" and label_id!="1":
continue
title = [ord(x) for x in title]
# 長い部分は打ち切り
title = title[:max_length]
title_len = len(title)
if title_len < max_length:
title += ([0] * (max_length - title_len))
titles.append((int(label_id), title))
return titles
def train(inputs, targets, batch_size=1000, epoch_count=1, max_length=30, model_filepath="model.h5", learning_rate=0.0005):
start = learning_rate
stop = learning_rate * 0.001
learning_rates = np.linspace(start, stop, epoch_count)
# モデル作成
model = create_model(max_length=max_length)
optimizer = Adam(lr=learning_rate)
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
#es_cb = keras.callbacks.EarlyStopping(monitor='val_loss', patience=0, verbose=0, mode='auto')
# 学習
history=model.fit(inputs, targets,
nb_epoch=epoch_count,
batch_size=batch_size,
verbose=1,
validation_split=0.2,
shuffle=True,
callbacks=[
LearningRateScheduler(lambda epoch: learning_rates[epoch]),
])
# モデルの保存
model.save(model_filepath)
return history
if __name__ == "__main__":
comments = load_data("../data/preprocessed_dajare.tsv",[0])
np.random.shuffle(comments) # shuffle the data (note: validation_split does not shuffle the data before the splitting)
input_values = []
target_values = []
for target_value, input_value in comments:
input_values.append(input_value)
target_values.append(target_value)
input_values = np.array(input_values)
target_values = np.array(target_values)
history=train(input_values, target_values, epoch_count=250)
結果(精度)
学習の過程を可視化したものがこちらになります。
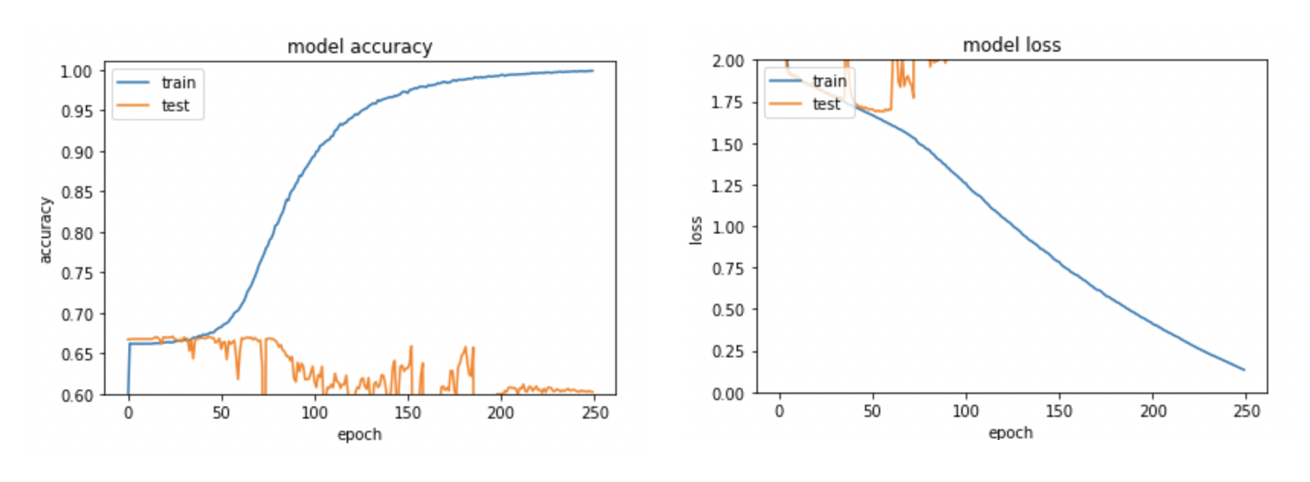
左の図の見方を説明すると、右に行くほどモデルを反復して学習していることを示し、オレンジの線が上に行くほど正解率が高くなっていることを示します。
つまり、驚くほど学習できていません!!!!
正解率が67%付近からびた一文上がりません!!!!
もともと『面白い』とラベルが付けられているデータの割合が65%程度なので、ほぼランダムと変わらないということになります。
character-level CNN以外にも、以下のような特徴量を作成してlightGBMで学習もしてみましたが結果は同じく、全く学習できませんでした。
- 全体の文字列の長さ
- 分かち書きされたときの要素数
- 全体の文字列の長さに対してかかっている文字数の割合
- かかっている文字数
- 何回かかっているか
考察
ここまで、読みの情報(つまり音)のみで判別、評価を行ってきました。判別に関しては89%と、高い精度で予測できていたのですが、評価に関しては全く予測できないという結果になりました。
これらの結果から、ダジャレかどうかの判別に最も重要な要素は**「音」であるが、面白いかどうかの評価に「音」は重要ではなく、「意味」「知識」が重要である**という知見が得られました。(下記図参考)
これらはダジャレで得た(ダジャレデータ)知見です。
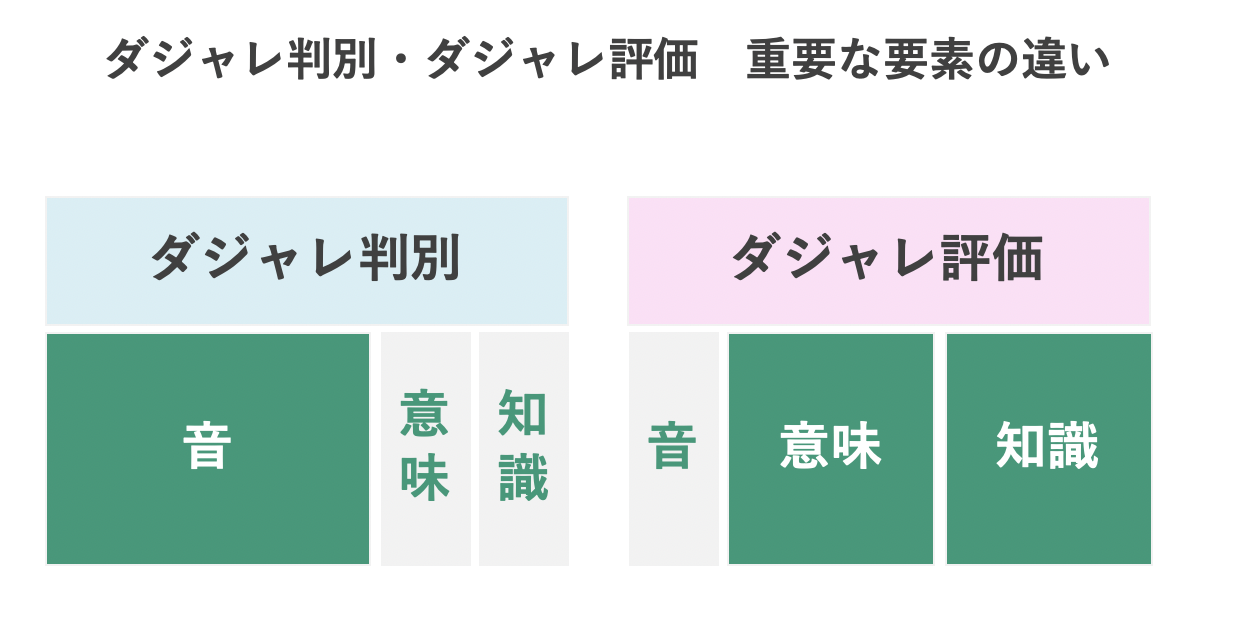
ここで言う意味・知識とは以下のようなものです。
「布団」の意味:布製の寝具
「布団」の知識:入ると暖かい・通常吹っ飛ぶものではない など
確かに、「布団が吹っ飛んだ」というダジャレでなぜ人が笑うのかを考えてみると、
音が反復している点に加え、布団が吹っ飛ぶという日常ではありえない光景を思い浮かべて笑うと想像できます。このことからも、「意味」「知識」を加えることは必要だと考えます。
Kurohige 〜次世代型布団ふっとばしエンジン〜
ここから先はハードウェアの話になります。
布団を吹っ飛ばすエンジンとして、今回は「黒ひげ危機一発」ライブラリを改変し、次世代型ふっとばしエンジン、Kurohigeを作成いたしました。
装置の外枠を外すと、内側には黒ひげ危機一発の樽先にローソンの割り箸がついた装置が入っています。
ローソンの割り箸が布団を押し出すことで、布団が吹っ飛ぶ仕組みになっています。
まさに、寝具larityの到来です。

更に中を解剖すると、剣を刺す代わりにモーターが動くことで、スイッチが起動して棒が飛び出ることがわかります。モーターの土台には黒ひげ危機一発の剣を用いるため、装置との相性がかなり良くなっています。


モーターはRaspberry Piから制御できるようになっています。
配線は以下の通りです。

(参考):http://windvoice.hatenablog.jp/entry/2016/01/10/224043
"AI"rWeave 〜ふっとぶとん
ふっとぶとん**"AI"rWeaveは通常のふとんよりも250倍吹っ飛びます。(独自調べ)
もちろん、手縫いで作成しています。弊社は裁縫力**の高いデータサイエンティストが多数存在します。
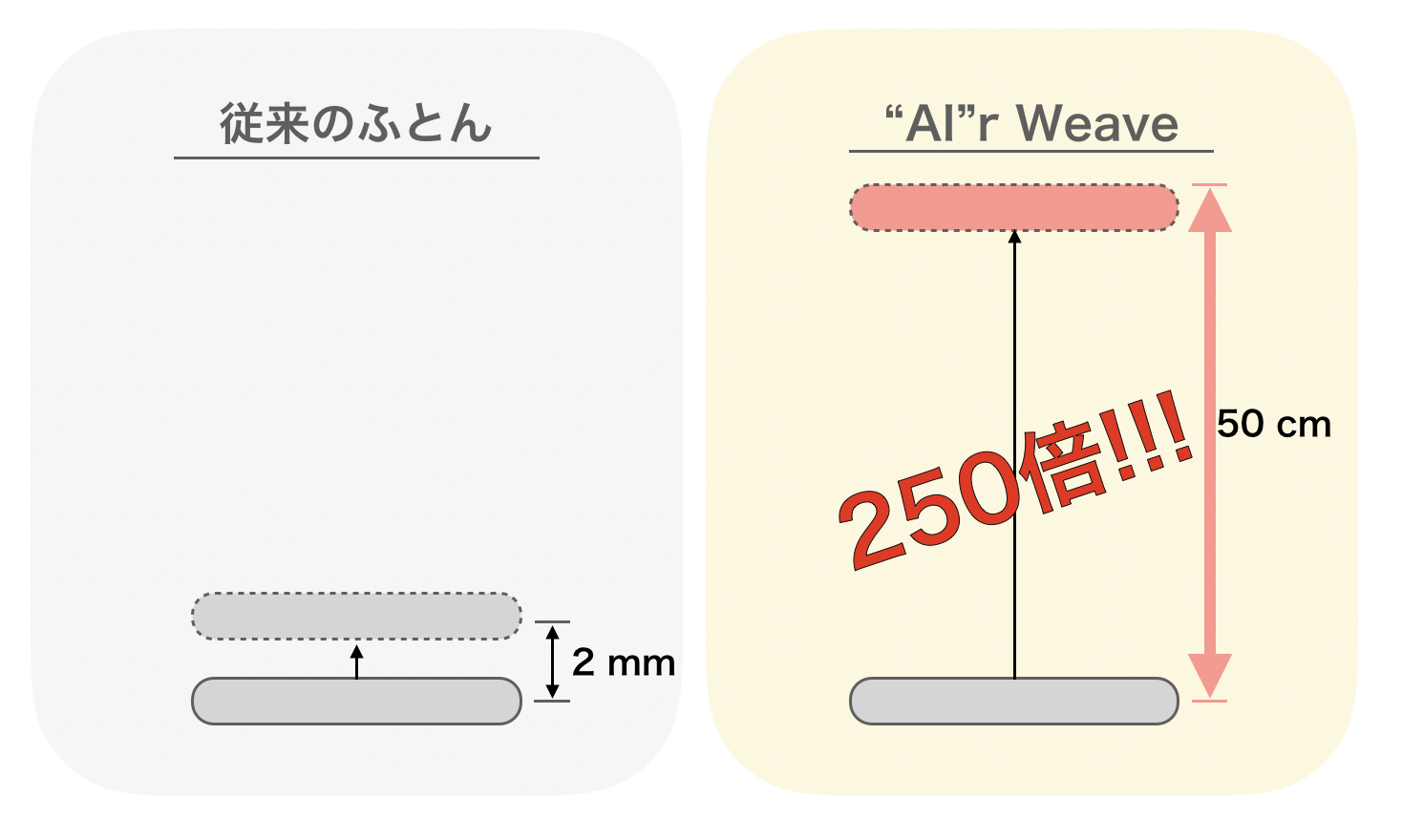
格段に吹っ飛ぶ秘密は、独自開発の内部構造にあります。
敷布団の底に「板紙を多層構造で強靭にし、包装資材などに使用できるよう加工した板状の紙製品」を入れ込むことで、柔らかい寝心地を保ちつつ、吹っ飛ぶ高さを何倍にも引き上げています。

今後の発展
今後は以下のような機能をアップデートしていきたいと考えております。
- ダジャレの評価ができるようになる(最重要)
- ダジャレ判別の精度を上げる
- WEBブラウザで誰でもアクセスできるようにする
- 吹っ飛ばすパワーをさらに上げる
制作チームについて
今回の制作チームは、会社非公認slackに密かに存在する「思いついたダジャレを投稿し、全力で褒め合うチャンネル」#who_says_dajare(邦訳:ダジャレを言うのは誰じゃ)で呼びかけたことから始まりました。
※画面に写っている4人が制作メンバー
「ダジャレをたくさん思いつくんだけど、誰にも褒めてもらえない(´;ω;`)」という人はぜひブレインパッドで一緒に働きましょう!