イントロ
Kerasを使ってなんかやろうということで題材を探していたところ、こんな記事がありました。
京極夏彦「ライトノベルの定義は非常に曖昧ですが、現在ラノベと呼ばれているジャンルとは違うものと考えたほうがいいです」「ラノベは、今やラノベです」への反応
ライトノベル、特にそのサブジャンルとしてのいわゆる「ラノベ」は、往々にして書名が特徴的な場合が多いです。例えば、もっともメジャーなレーベルである電撃文庫のウェブサイトから、2018年7月の新刊のタイトルを列挙すると、
- エロマンガ先生(10) 千寿ムラマサと恋の文化祭
- 俺を好きなのはお前だけかよ(9)
- GENESISシリーズ 境界線上のホライゾンXI〈上〉
- 勇者のセガレ3
- 魔王学院の不適合者2 〜史上最強の魔王の始祖、転生して子孫たちの学校へ通う〜
- 迷宮料理人ナギの冒険3 〜開かない窓の向こうの故郷〜
- リア充にもオタクにもなれない俺の青春2
- 不死者(ぼく)と暗殺者(かのじょ)のデスゲーム製作活動
- はじらいサキュバスがドヤ顔かわいい。 〜ふふん、私は今日からあなたの恋人ですから……!
- この世界がゲームだと判明して100年が過ぎた Project【venturum saeculum】
- アルビレオ・スクランブル
これらがライトノベルであろうことは、人間であればほとんど直ちに判断できます(アルビレオ・スクランブルに関してはハヤカワっぽいかもしれない)。Kerasで判定してみましょう。
何をするのか
今回は、こちらの記事
character-level CNNでクリスマスを生き抜く
を参考にさせていただき、Character-level Convolutional Neural Network (CNN)を使って、書名からライトノベルっぽさを推定するものを作ります。
Character-level CNNを使う理由は、Kerasを使うことありきだったからデータの前処理がほとんど必要ないという楽さです。ライトノベルのタイトルは新語だらけですし、そもそも日本語として成立していないケースもしばしばある気がします。形態素解析をしたり辞書を作ったりは面倒そうです。性能の追及ではなく、Kerasに触れてみること自体が目的なので、お手軽に実行できるものを採用しましょう。
学習データ
今回は、「ライトノベル系レーベルの作品っぽいか」で判定することにします。
ライトノベル系、非ライトノベル系のレーベルから書名を取得し、学習データを作ります。
学習データの取得には、国会図書館データベース NDL-Bibを用います。
レーベルで検索して出てきた署名をライトノベル/非ライトノベルに振り分けます。
ライトノベル系レーベルとして、
- 電撃文庫
- MF文庫
- ガガガ文庫
- 角川スニーカー文庫
- 角川ビーンズ文庫
- ファミ通文庫
- アルファポリス
- 富士見ファンタジア文庫
非ライトノベル系レーベルとして、
- 新潮文庫
- 岩波文庫
- 岩波新書
- ちくま学芸文庫
- ハヤカワSF
を選びました(加えて、非ライトノベルのデータとして青空文庫からデータを取得しました)。
書名とライトノベルか否かのラベル(0 or 1)の組をデータとして与えて学習させます。
本来、シリーズものは一回だけカウントするべきかもしれませんが、そのあたりの前処理が面倒なのでとりあえずそのまま流し込んでいます。
取得したデータ数
ライトノベル: 18851タイトル
非ライトノベル: 37088タイトル
結構集まりました。国会図書館と青空文庫様様です。
コード
結果
CNNのパラメータはほぼヤマ勘です。本来はいろいろ試すべきなのでしょうが、面倒なので。
手元のラップトップでサクッと回る程度に抑えています。
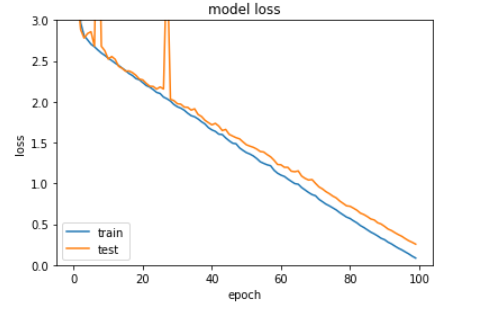
Loss
accuracy
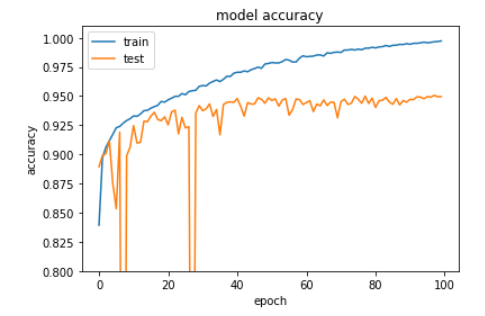
Lossはtrain, validationともに下がり続けており、過学習の傾向はみられません。一方でaccuracyについてはtrainについてはほぼ100%(99%超)ですが、validationは95%程度の正解率でサチっている感じです。まだlossは収束してなさそうですが、あまりPCをいじめるのもなんなのでこの辺でやめておきましょう。
こちらのブログ
PyCon mini OsakaでCharacter-Level CNNについて話してきた。
などを見ていた感じ、まあ90%正解できればいいかなと思っていましたが、想定以上にいい感じです。
Lossは下がり続けているにもかかわらず、accuracyがサチっているあたり、95%ぐらいが限界なのかもしれません。有川浩氏や桜庭一樹氏のように、ライトノベル作家から一般小説作家へ(少なくともレーベルの上で)転身した方々の存在や、レーベルを変えて再出版される本の存在などを考えると、書名だけで判断するのはどこかで限界が来ます。
実験
学習済みモデルを使っていくつか試してみましょう。
まず、最近のラノベこと、アルフレッド・べスターの「虎よ!虎よ!」を入れてみます。
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "虎よ!虎よ!"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽくない: 10.809969902 %
ちゃんと判定できています。ハヤカワSFは学習データに入れているのでまあ当たり前ですが。
学習データに入れていない出版社ではどうでしょうか。河出書房より、ダグラス・アダムス「銀河ヒッチハイク・ガイド」を入れてみます。生命、宇宙、そして万物についての究極の疑問の答えでお馴染みの作品ですね。
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "銀河ヒッチハイク・ガイド"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽくない: 0.118213891983 %
うまくいきました。
創元SFから、J. P. ホーガン「造物主(ライフメーカー)の掟」を入れてみます。タイトルにルビがふられており、ライトノベルと判定されそうな気がします。
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "造物主(ライフメーカー)の掟"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽくない: 3.95872592926 %
判定は非ライトノベル。ちゃんと正解できています。
ものすごくライトノベルっぽいタイトルではどうでしょうか。自作小説投稿サイト小説家になろうの人気作品ランキング一位(執筆時点)の、眞下洋佑氏「二重スパイの最強賢者~勇者パーティを追放された陰の実力者~」を入れてみます。
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "二重スパイの最強賢者~勇者パーティを追放された陰の実力者~"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽい: 99.9886076694 %
妥当ですね。
ライトノベルかどうかきわどいレーベルではどうでしょうか。新本格推理小説の親玉である一方、メフィストを主宰し、西尾維新らを輩出した講談社ノベルスから、汀こるもの氏の「パラダイス・クローズド」、「完全犯罪研究部」、「ただし少女はレベル99」を入れてみます。
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "パラダイス・クローズド"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽい: 96.7934861779 %
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "完全犯罪研究部"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽくない: 1.60030126572 %
def predict(titles, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(titles)
return ret
if __name__ == "__main__":
raw_title = "ただし少女はレベル99"
title = [ord(x) for x in raw_title]
title = title[:20]
if len(title) < 20:
title += ([0] * (20 - len(title)))
ret = predict(np.array([title]))
predict_result = ret[0][0]
if predict_result > 0.5:
print("ラノベっぽくない:", 100-predict_result * 100,"%")
else:
print("ラノベっぽい:", 100-predict_result * 100,"%")
ラノベっぽい: 99.9545533123 %
大体納得のいく結果ではないでしょうか。レーベル的に学習データに推理小説系が少なかった気がするので、創元推理文庫あたりを食わせておくべきだったかもしれません。
以上。