はじめに
Azure Machine Learningに興味があったので、今回触ってみました。
crash.academyで公開されている勉強会の動画1を元に
Azure Machine Learningを触ってつかんだことをこの記事にまとめます。
なお、触る前に調査した内容は自身のブログにまとめています。
Azure Machine Learningの初歩の初歩
同様のテーマで先行する記事もあります:Azure Machine Learning でいきなり機械学習
前提
今回は2つのラベルでのClassification(分類)に取り組みました。
(後ほど確認する公式のドキュメントはClassificationに限って確認しています)
機械学習は実装こそしたことはありませんが、
用語や概念については学生時代の講義で多少聞きかじった立場で書いています。
Azure Machine Learningを触る上では先に紹介した勉強会の動画の他に
以下のAzure Machine Learningハンズオン資料も参考にしました。
https://github.com/kheiakiyama/isao-meetup-20170323
Azure Machine Learningは無料プランで触っています。2
動作環境
ブラウザからAzure Machine Learning Studioにアクセスしました。
- ブラウザ:Google Chrome(63.0.3239.84)
- Azure Machine Learning Studio:https://studio.azureml.net/
Azure Machine Learningの基本
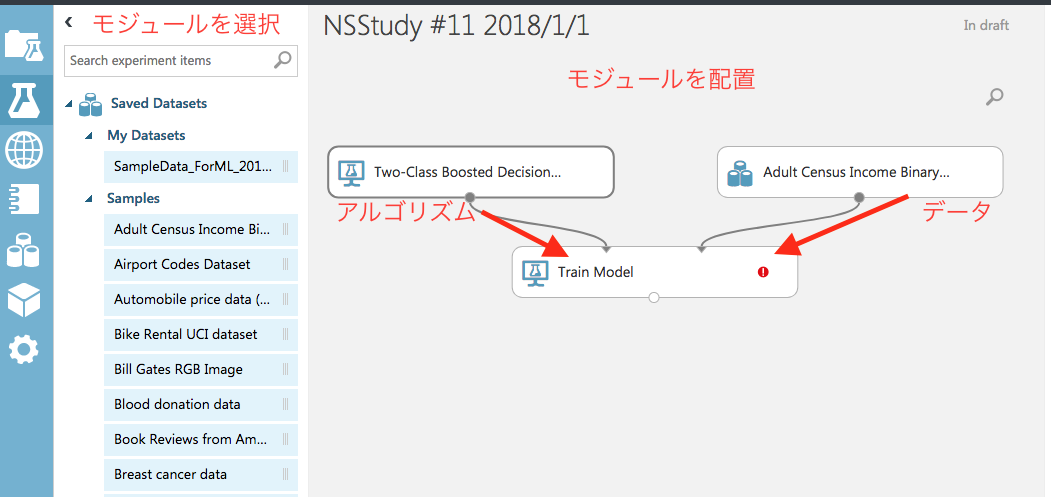
基本操作はモジュールをドラッグ&ドロップして配置していくだけです。
モジュール配置の基本形は
Train Modelモジュールにアルゴリズムを左から、データを右から渡す形です。
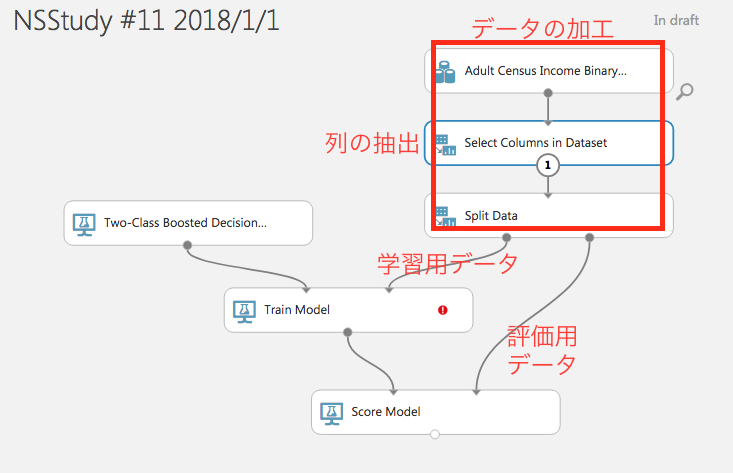
右側にあるデータは以下のように加工します。
- データのうちモデルが扱うカラムを選択する。3
- すべてのデータを学習に使うのではなく、学習用データとモデルの評価用データに分ける。
データ加工後のモジュールの配置は以下のような形になります。
(Score Modelモジュールでは、学習後のモデルで評価用データを分類します。
この図にはありませんが、Score Modelモジュールの結果を評価するために、
Evaluate Modelモジュールが必要になります)
モジュールについて
ここまでに登場したモジュールが何をやっているのかを知りたかったので、公式ドキュメントを見てみました。
A-Z List of Machine Learning Studio Modules
データを加工するモジュール
Select Columns in Dataset
データの中から後に続く操作で使うカラムを選択し、そのカラムだけからなるデータを返すモジュール
| 入力 | パラメタ | 出力 |
|---|---|---|
| Dataset | Select columns | Results dataset |
| (保持するカラムを選択) |
Split Data
データセットの行を2つに分割するモジュール
| 入力 | パラメタ | 出力 |
|---|---|---|
| Dataset | Splitting mode | Results dataset1 |
| (Splitの方法を選択) | Results dataset2 |
入力されたのが100行のモジュールで分割する割合が0.6(=60%)のとき
Results dataset1に60行、Results dataset2に40行返る。
(Results dataset1にどの列が含まれるかはSplitting modeの他の要素による)
モデルに関係するモジュール
Train Model
このモジュールを使うケース
- 教師あり学習
- Classification(分類) またはRegression(回帰)
| 入力 | パラメタ | 出力 |
|---|---|---|
| Untrained model | カラムを指定 | Trained model |
| Dataset |
学習していないモデルにデータを与えて学習済みのモデルを返すモジュールと理解しています。
パラメタにある「カラムを指定」とは、モデルがどのカラムの値を予測するかを指定するということです。
Score Model
モデルを使って予測をするモジュール。
分類を扱うモデルの場合は分類の予測値とその値となる確率を返す。
| 入力 | 出力 |
|---|---|
| Trained model | Scored dataset |
| Dataset |
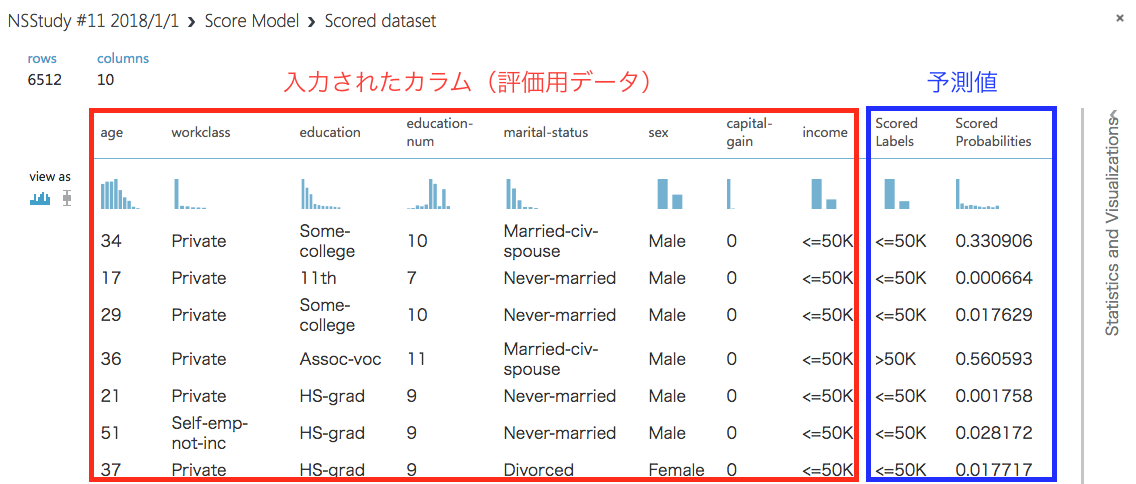
出力は以下のように、入力されたカラムとモデルの予測値(ここでは予測したラベル)が
表示されたデータセットです。
Evaluate Model
分類または回帰モデルの結果を評価するモジュール。
使い方のうちの1つが、Score Modelモジュールの出力を元にしたモデルの評価。4
| 入力5 | 出力 |
|---|---|
| Scored dataset | Evaluation results |
Evaluation resultsについては次節で扱います。
ClassificationにおけるEvaluation resultsの見方
ドキュメントを見ても何がなんだかさっぱりだった6のですが、
以下の記事の「3.評価指標」の検診の例が大変参考になりました。
【機械学習】モデル評価・指標についてのまとめと実行( w/Titanicデータセット)
検診の例で整理します。
| 用語 | 意味 |
|---|---|
| Accuracy | 全体の中で正しい予測をしたケースの割合。(正しい予測をしたケースとは、病気の人に病気と予測したケースと病気でない人に病気でないと予測したケース) |
| Precision | 病気と予測したケースのうち、実際に病気だったケースの割合 |
| Recall | 病気と予測するのが正しいケースの中で、病気と予測したケースの割合 |
Precisionはモデルが病気と予測したとき、それがどの程度正しいのか(どの程度外れるのか)ということがわかる指標であり、
Recallはモデルでの病気の見逃しがどの程度ありうるのかということがわかる指標と考えます。
(これ以上のことは今後勉強します)
終わりに
Azure Machine Learningは使い始めるのは簡単ですが、
機械学習の分野の知識を前提としており、使いこなすにはハードルが高いツールという印象です。
実装はAzure側で用意されているので、データの中のカラムの選択や
モデルに指定するアルゴリズムの選択をする上での考え方に絞ってまずは学んでいこうと思います。
今回のケースでもなぜTwo-Class Boosted Decision Treeを使っているかがわからないので
今後は以下にあたって見る予定です。
- Azure Machine Learning 分析アルゴリズムの選択
- Machine learning algorithm cheat sheet for Microsoft Azure Machine Learning Studio
脚注
-
NSStudy #11 一度はあきらめたエンジニアのための、いまさら聞けない機械学習 –Azure Machine Learning- 「本講座は会員登録を行うと無料で全編視聴できます。」と記載されています ↩
-
↩Azure Machine LearningはAzureのサブスクリプションがなくてもMicrosoftアカウントさえあればだれでも無料で利用することができます。 Azure Machine Learningを無料で始める
-
CSV形式でA,B,C,D,Eというカラムを持つデータについて、例えば、A,C,Dの3つのカラムを使って分類を行うという風に決めるということと理解しています ↩
-
Score Modelの出力を元にした使い方の他に、テストデータに対する比較と2つのモデルの比較ができるようです。 ↩
-
2つ目の入力として比較するためのdatasetも渡せるようです。 ↩
-
公式ドキュメントではAccuracyとPrecisionは何が違うのか、true resultsとpositive resultsは何が違うのかがわかりませんでした。(このあたりは前提知識があるものとしているようです) ↩