GYAO の kenharad です。
今回機械学習について全く知識のない自分が
いきなりAzure Machine Learning(以下AzureML)で機械学習を実践してみました。
経験なしでもさくっと機械学習を行うことが出来たので、その内容をハンズオン形式で紹介したいと思います。
目的
- Azure Machine Learning の使い方を身につける。
- 結果の良い/悪いが判断できるようにする。
概要
機械学習ではまず最初に予測があり、それを実証するために実験を行います。
今回はAzure MLを用いて、「あるWebサイトのPV数に天気が影響しているのではないか」という推測を元に
それぞれのデータの相関関係に有意性が存在するかを調べてみます。
これが実証されると、天気予報からWebサイトのPV数が推測できるようになりそうです。
前提条件
Azure のアカウントを所持しており、ログインできるものとします。
![]() Azure 自体の説明については他のサイトを御覧ください - ヤフーでAzureを検索
Azure 自体の説明については他のサイトを御覧ください - ヤフーでAzureを検索
Azure Machine Learning の起動
Azure Portal にアクセスします - https://portal.azure.com/#
AzureML 用のワークスペースを作成します。
「新規」->「Intelligence+analytics」->「Machine Learning ワークスペース」をクリック
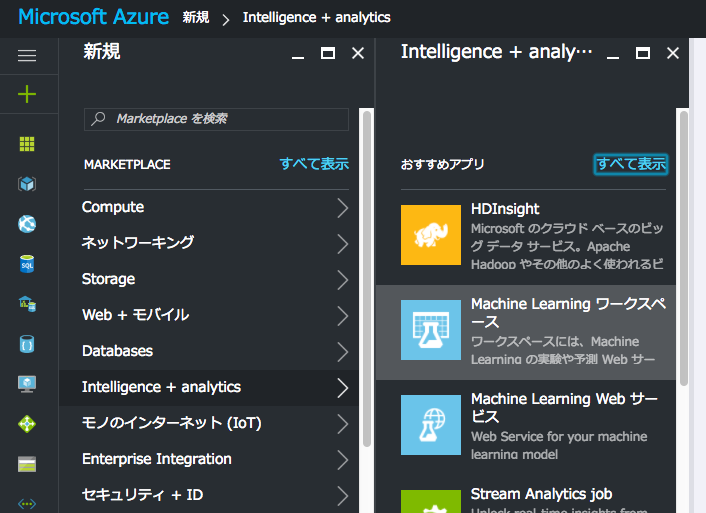
以下のように適当に項目を埋めて「作成」をクリック
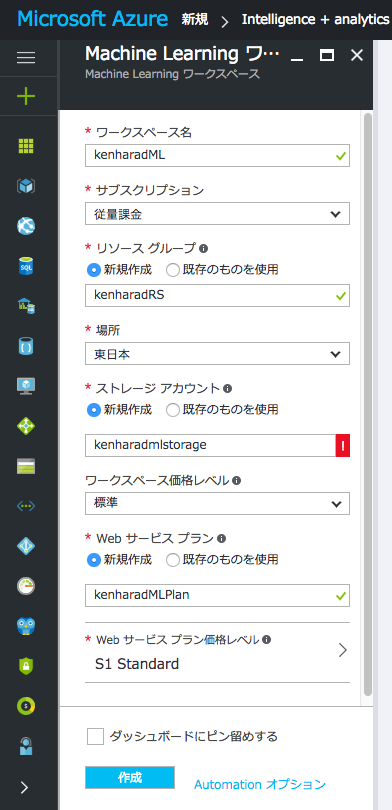
「Webサービス プラン価格レベル」については、今回はテストのため一番安いものでOKです。
作成すると毎日課金されるので、ハンズオン終了後不要であれば削除しましょう。
作成には数十秒〜数分程度かかります、完了まで待ちます。
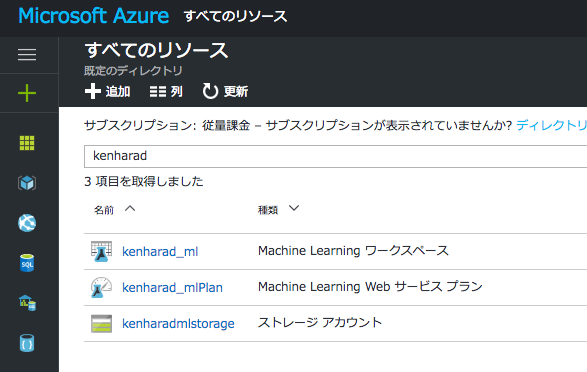
作成完了後、「すべてのリソース」から作成したワークスペースにアクセスできます。
作成したワークスペースをクリックしてください。
続けて 「概要」->「Machine Learning Studio」をクリック
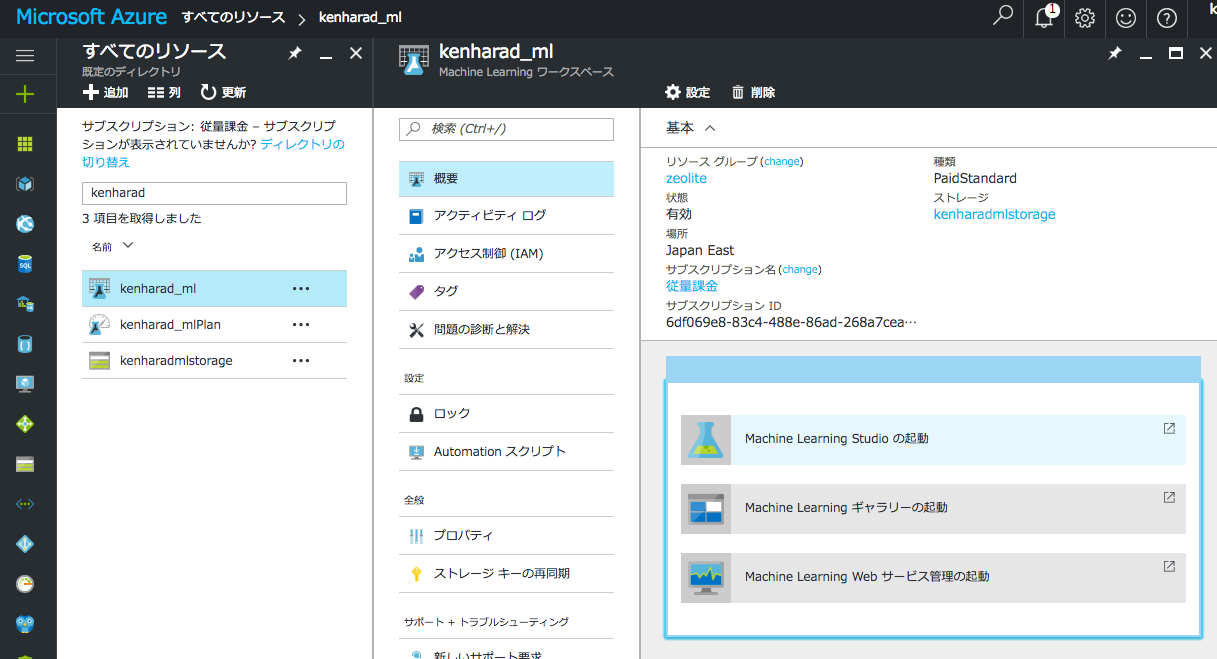
「Microsoft Azure Machine Learning Studio」がブラウザで開かれます。
ページ右上の「Sign in」をクリックし、Azure ログイン時のアカウントでサインインします。
実験の準備
実験の作成
AzureML にはいくつかの実験サンプルが用意されています。
最初のうちはサンプルの動作を確認しつつ身に付けていくのが手っ取り早いのですが、今回は1から作ってみたいと思います。
画面左下の「+New」をクリックします。
メニューが現れるので、左側から「EXPERIMENT」を選択し、「Blank Experiment」を選択します。
| 既存のサンプルをロードして必要な箇所のみ修正するほうが手間がなくスピーディーですが、 今回は1ステップずつ確認しながら構築するために、あえてブランクから作成しています。 |
以下のような画面になります。
この画面に必要なデータ、フィルタ、計算モデル等のロジックをドラッグ&ドロップで配置することにより、
実験を作成することができます。
タイトル(「Experiment Created on XXXXXXX」と書かれているところ)はわかり易い名前に変更しましょう。
データの配置
今回は概要に記したように、WebサイトのPV数と天気(雨量値)の相関関係に有意性が存在するかを調べてみることにします。
まず某サイトのPVデータを用意してみました、以下のようなCSVデータです。
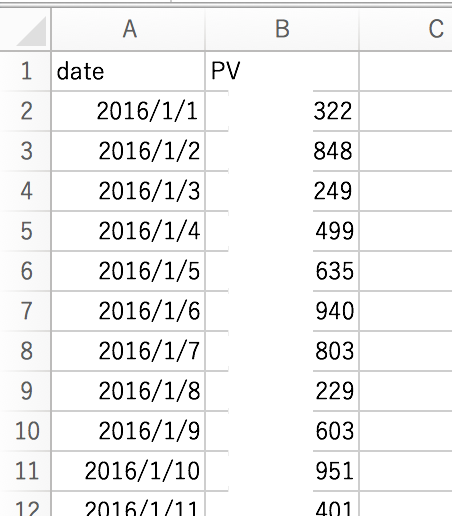
| ※ この時、1行目はカラム名を、2行目以降をデータとしてください。 カラム名には日本語も使用できますが、文字コードはUTF-8を使用してください。 データフォーマットにはCSV,TSV 等が使用できます。 |
次に天気データを用意します。
今回は天気データとしてアメダス雨量データを用いることとしました。
アメダス雨量データは以下からダウンロードすることができます。
http://www.data.jma.go.jp/gmd/risk/obsdl/index.php
ダウンロード直後のデータではそのまま使えない内容となっているので、不要な項目を削除したり、
フォーマットをあわせたりして以下のような形式にデータを整形します。
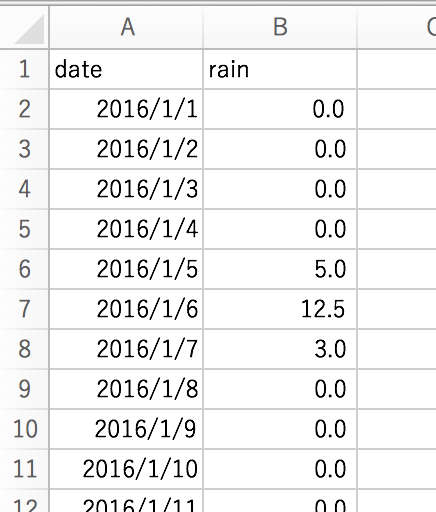
次に用意したデータのアップロードを行います。
AzureMLメニューの「DATASETS」 -> ページ下部「+NEW」 -> 「FROM LOCAL FILE」を選択し、ローカルから用意したデータをアップロードしてください。
アップロード時にはデータのフォーマットやヘッダの有り無しをオプションで指定できます。
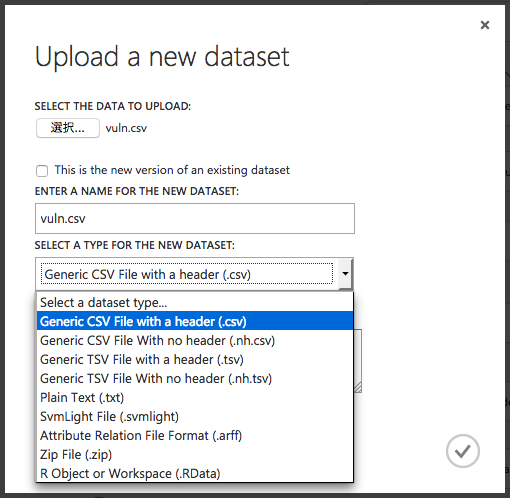
データをアップロードできたら準備完了です。
いよいよ実験を作成していきます。
画面左側「Saved Datasets」→ 「My Datasets」を選択し、その中からPVデータ、雨量データをD&Dします。
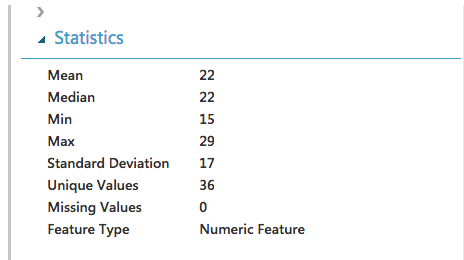
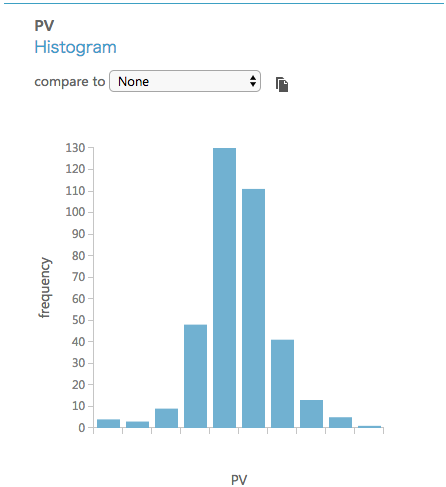
データの中身は配置後に右クリック → 「Visualize」で確認することができます。
この時点でデータの最小値、最大値、平均値、分布等を確認することができます。
データの前処理
それぞれのデータをマージするためのロジックを記述します。
画面左「Python Language Modules」→ 「Execute Python Script」を選択しD&D。
それぞれのデータから線を引っ張りスクリプトへのインプットとします。
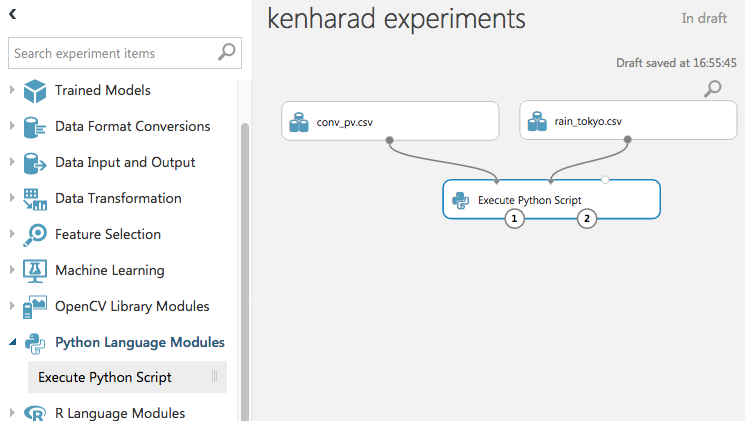
スクリプトモジュールをクリックし、既設関数内に以下のコードを追加します。
# date をキーとしてデータをマージ
dataframe1 = dataframe1.merge(dataframe2,on='date')
ここでは例えばPVが10以上のものだけを使う
# PV が10以上のものだけを取得
dataframe1 = dataframe1[dataframe1.PV >= 10]
などのコードを記述することができます。
データ分割
マージしたデータを学習データとテストデータに分けるモジュールを配置します。
| 学習データはデータから有意性を見出すもので、テストデータは見出された有意性に合致しているかどうかを判断するためのものです。 このように一定量のデータからパターンを導き出し、それ以外のデータがパターンに沿っているかを確認する手法を「教師あり学習」といいます。 |
画面左「Data Transformation」→ 「Sample and Split」→ 「Split Data」をD&D。
スクリプトモジュールから線を引っ張りインプットとします。
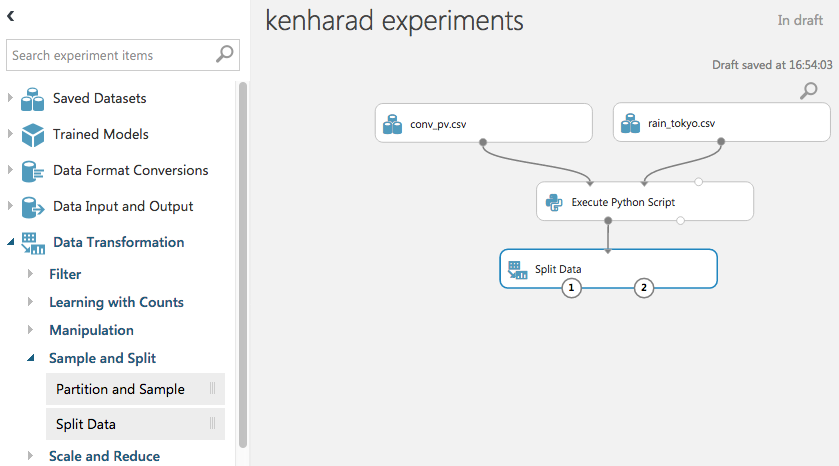
画面右の「Fraction of rows in the first output dataset」にて学習データとテストデータの割合を変更することができます。
ここまでの流れを一度実行してみましょう。
実行前に画面下部「Save」をクリックし実験内容を保存します(エラーがあると保存できないこともあります)
「Run」をクリックすると実験が実施されます、エラーがあると途中で停止するので適宜修正してください。
| マウスで一つ以上のモジュールを選択し、「Run selected」を選択することで、指定したモジュールのみ再実行できます。 |
最後まで動作したら「Split Data」を右クリック → Visualize で確認してください。
二つのデータがdateをキーとしてマージされたことが確認できると思います。
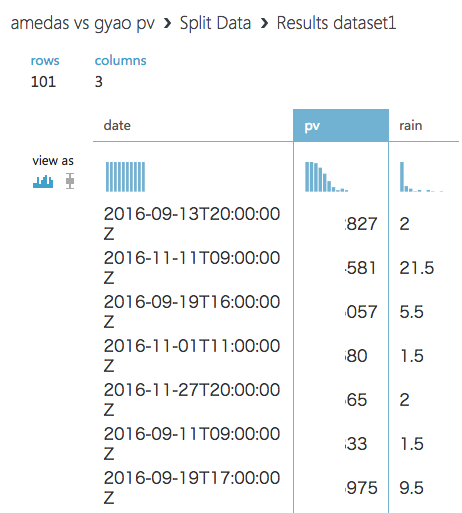
※ この時 rows が元データより少ないのは、データが二つに分割されているためです。
トレーニング
学習データが用意できたので、学習モジュールに突っ込みます。
今回モデルは線形回帰を使います(機械学習はとりあえず線形回帰で有意性が出るかどうかを確かめるのがいいそうです)
機械学習の種類については他のサイトを参照してみてください。
「Machine Learning」→「Initialize Model」→「Regression」→「Linear Regression(線形回帰)」をD&D
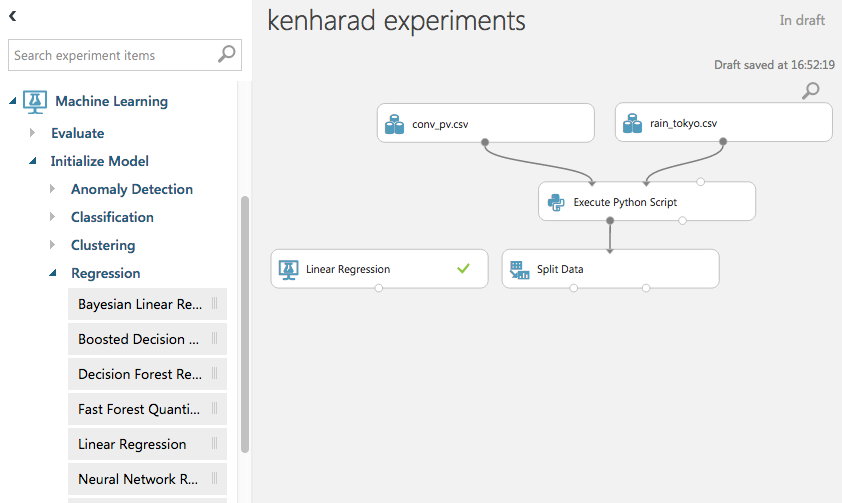
「Machine Learning」→「Train」→「Train Model」をD&D
※ 線形回帰はこれを用いますが、クラスタリングや異常検知の場合は他のトレーニングモデルになります。
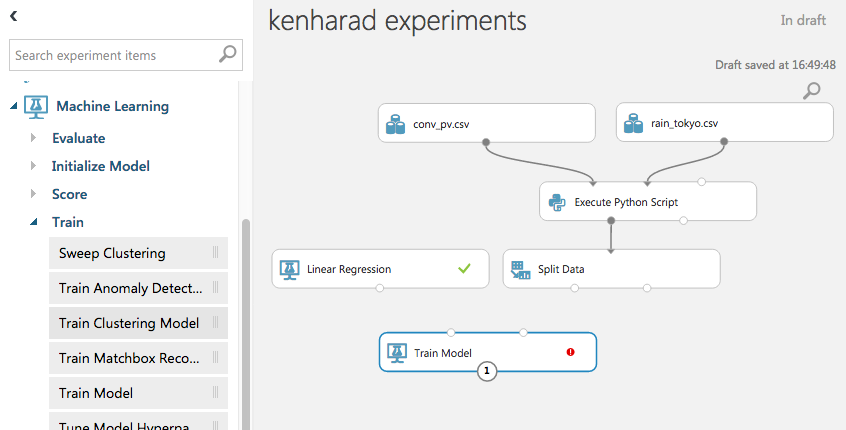
「Linear Regression」と「Split Data」をそれぞれ「Train Model」に接続し、画面右の「Launch Column Selector」から
任意の「抽出したい値」を指定します(今回はPVにしておきます)

評価
トレーニング →スコアリング→評価 の流れは基本的なものでどの実験でもこの流れとなります。
よって以降は特に意識せずそのままモジュールを配置してください。
「Machine Learning」→「Score」→「Score Model」をD&D
「Machine Learning」→「Evaluate」→「Evaluate Model」をD&D
それぞれのモジュールを線でつなぐ
以下のようになると思います。
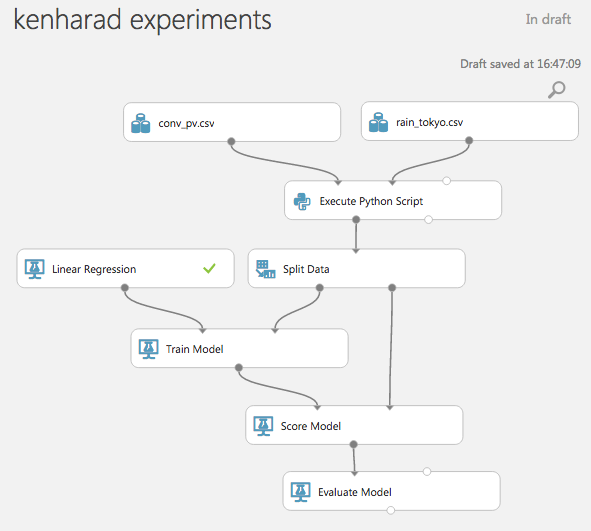
モジュールの追加
データ内の date カラムが集計結果に影響を与えていたため、計算内容から除外するモジュールを追加しました。
「Data Transformation」→「Manipulation」→「Select Columns in Dataset」モジュールです。
date以外の集計に必要なデータ(PV, rain)だけに絞ります。
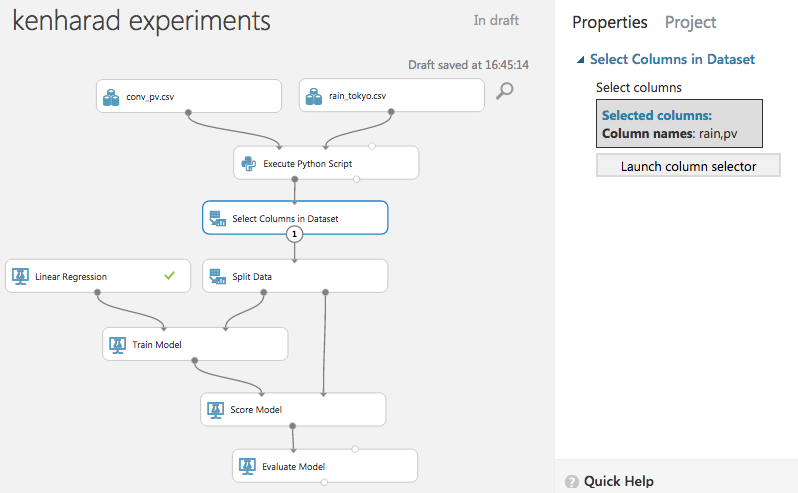
実験
実行してみます。
エラーが発生した場合は適宜修正してください。
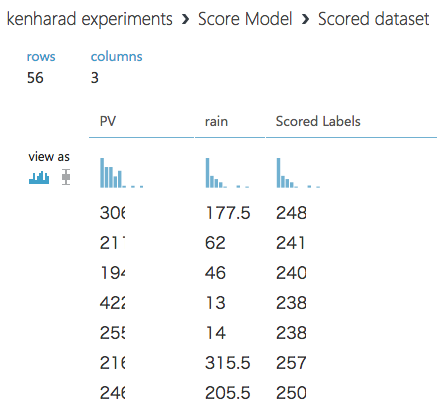
最後まで実行が終わったら、「Score Model」のアウトプットをVisualizeで確認します。
入力データとそれに対するスコア(予想値)です。
このケースでは雨量値(2列目)に対し予想されるPV数(3列目)がスコア値として表示されています。
この結果から、学習結果としては雨量が高いほどPVが高くなるという結果になっているようですが、
実際のPV値(1列目)と予測値(3列目)を見ると乖離があるようです。
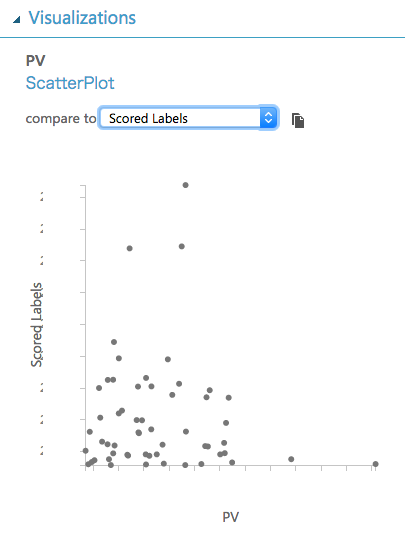
上記画面で適当な列をクリックすると画面右にプロットグラフが表示されます。
以下ではPV列を選択した後、プロットグラフ上で「compare to Scored Labels」を選択しています。
PV と予測値(Scored Labels)は予測が当たっていれば近似値をとなるはずなのですが、ばらばらに見えます。
実験の精度は「Evaluate Model」モジュールをクリックし、「Visualize」で確認することができます。
一番下の項目が1に近いほど精度が高いといえるそうです。
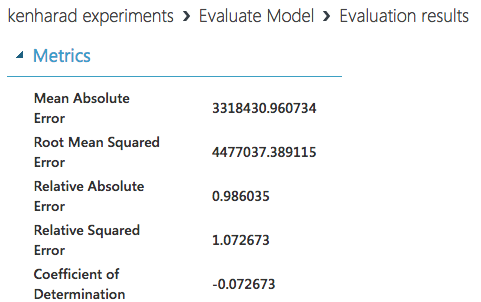
この結果から察するに、天気がPVに及ぼす影響は低く、
それ以外の外部要因の方が影響度が高いと予想されます。
また、今回はデータからノイズを除去する作業を行っていないため、実験内容を精査することで、
違った結果が出てくる可能性もありそうです。
![]() 出力結果の意味と値
出力結果の意味と値
| 名前 | 概要 |
|---|---|
| Mean Absolute Error | 平均絶対誤差、0に近いほど良い |
| Root Mean Squared Error | 予測値が正解値からどれだけ離れているかを示す。0に近いほど良い |
| Relative Absolute Error | 相対誤差 |
| Relative Squared Error | ルート相対二乗誤差 |
| Coefficient of Determination | 決定係数、特徴ベクトルが正解値をどれだけ説明できているか。高いほど良い |
考察
今回は予測と異なる結果となりましたが、予測と異なる = 失敗ではありません。
「予測していた結果と違った」ということが分かっただけでも収穫ですし、この結果を参考に実験の内容を磨き込みしていくことで
より実験の精度を高めていくことが出来ると思います。
今回の例では、サイトのPV数と天気という単純なものでしたが、
以下のようにノイズとなりそうな要因を見つけ出し、1つずつ排除していくことでより指向性の高い数値が出てくると思います。
- 特定の地域のPVと天気に絞る。
- 日中の活動時間帯だけに絞る。
- 曜日を考慮し平日は除外する。
- 気温も考慮に入れてみる。
- 季節要因を加味する。
- 外部イベント的な要因を排除する(重大事件が起こった日、外部サイトからの流入が極端に多い日等)
また、天気以外のデータ(曜日等)とPV数の相関関係を見るのもおもしろそうですね。
今回はここまで。
AzureMLが用意しているサンプルにはもっと複雑な多くの実験がありますので、興味を持った方はサンプルを動かしてみると良いと思います。