この記事が読まれているということは、既に@yamato3310くんの素晴らしいphpの記事が公開されていることでしょう。
本来ならば神コンの最優秀賞の賞金でスマブラを買って楽しんでるはずですが、優秀賞にもなれなかったので大人しく勉強しています。
週末のOB会に向けて深夜にランニングを始めたことによって喜びの声を上げている体(筋肉痛)に鞭を打ち、この記事を書くとします。
はじめに
12月1日、私は渋谷ヒカリエの17階にいた。
再開発が進み多くの高層ビルが建設中の渋谷で一足早く建築・開業したこのビルは「商業施設」「文化施設」「オフィス」などで構成される、地上34階、地下4階建ての高層複合施設だ。再開発によりバイト先のビルが買われて店が潰れた恨みを私は忘れない。
通い慣れたこの街「渋谷」で、未だに訪れたことのなかったヒカリエ上層階。警備員によって厳重に入退室が管理されたオフィススペースに私は足を踏み入れた。
Python入門者向けハンズオン #8に参加するためだ。
記事を書くために参加したのか、参加したから記事を書くのか、どちらが先かは覚えていないし、今となってはどうでもいいことだ。
確かなことは、「懇親会でピザを食べまくったこと」「余った未開封のカントリーマアムを持ち帰ったこと」「隣の人がスラスラ読めるPythonとスラスラわかるPythonを勘違いしていたこと」で充分だろう。
そこで学んだ**「スクレイピング」**が、今私が記事を書ける唯一の内容である。
「そんな初歩的なもの知っとるわ!」という方は、どうかブラウザの×をそっとクリックして欲しい。
くだらない導入である程度文字数を稼げたので本題に入りたいと思います。
そもそもスクレイピングとは
Wikipedia先生によると
ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
(引用:https://ja.wikipedia.org/wiki/%E3%82%A6%E3%82%A7%E3%83%96%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0)
とのこと。
広義過ぎる気もするけど、要するにwebページから欲しい情報を抜き取るのをPythonを使ってやってみよう、ってことです。
スクレイピングで何ができるの?
天気予報ページから天気の情報・値を抜き出したり、株価の変動を抜き出したりなどして、効率よく仕事をしよう!などなどetc...
ノリと勢いとPythonでスクレイピングをやってみた
今回はガールズ&パンツァーの公式サイトのキャラクターページから、ノリと勢いとパスタの国アンツィオ高校の生徒名を抜き出してみました。
最終章の第2話が6月に1年半ぶりに公開しますね。全6話が終わるのはいつになるのでしょうか。終わるころにはリアルガルパンおじさんになってそうです。
今回こんな実用性皆無のスクレイピングを選んだのは、Python入門者向けハンズオン #8の復習を兼ねているからという言い訳をさせてください。
Q.何故ガルパン?
A.当初は学校の教員一覧から名前を取ろうとしましたが、個人情報なのであまりよろしくはないかと。そこで適当に思いついたから。ガルパンはいいぞ
Q.なぜアンツィオ高校なの?
A.イタリアが好きだからです。アイコン見ればわかるかと思います。カルパッチョ可愛いよカルパッチョ。
とりあえずコード
import requests
from bs4 import BeautifulSoup
def main():
url = 'http://girls-und-panzer-finale.jp/chara/'
response = requests.get(url)
content = response.content
soup = BeautifulSoup(content, 'html.parser')
schools = soup.find_all('section', class_='chara-list-section')
anzio = schools[5].find_all("figcaption")
for name in anzio:
print(name.get_text().strip())
if __name__ == '__main__':
main()
短い簡潔に纏められた素晴らしいコードですね。
順々にコードを見ていきます。
事前準備
仮想環境設定
RemoteSigned に変更する

venv の作成
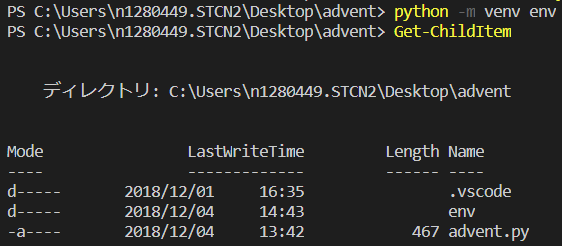
仮想環境の有効化

プロンプトマークが変わればOKです。
パッケージのインストール
今回使うのは
Webからデータを取得するためのrequestsと
HTMLを解析するためのBeautifulSoup4 (おいしそう)


BeautifulSoupについては@itkrさんの記事に詳しく書かれています。
コード内容
インストールしたパッケージのインポート
>>> import requests
>>> from bs4 import BeautifulSoup
変数にスクレイピングしたいサイトのURLをいれる
>>> url = 'http://girls-und-panzer-finale.jp/chara/'
requestsでサイト内の情報を抜き取る
>>> response = requests.get(url)
response から HTML 部分(content) を取得
>>> content = response.content
BeautifulSoup に content を渡して解析の準備をする
>>> soup = BeautifulSoup(content, 'html.parser')
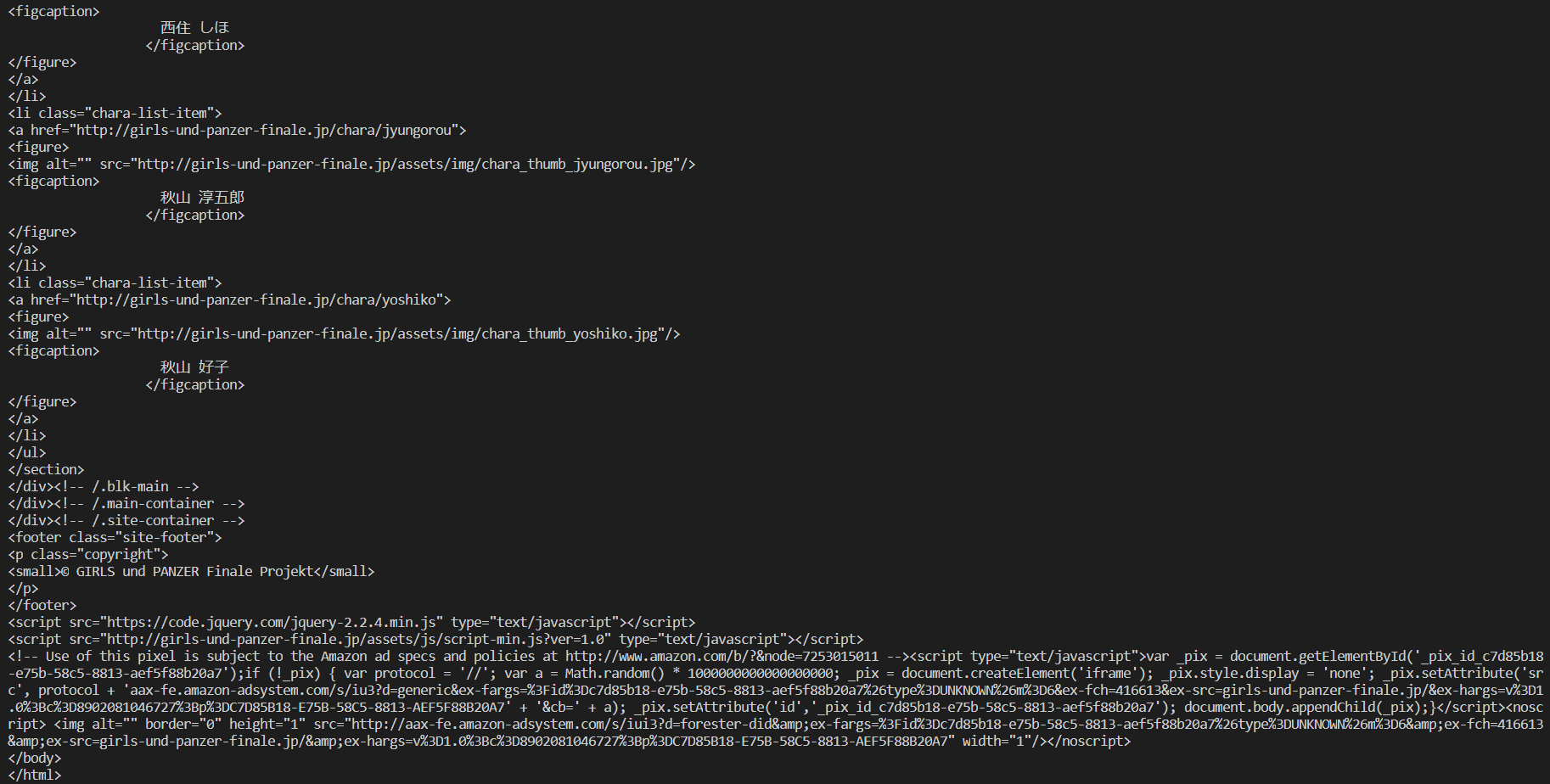
変数soupの中身はこのように、HTML内の情報が丸まる入っています。(画像は一部)
ここからタグなどを指定して、欲しい情報を抜き取ります。
学校ごとの情報を取り出す
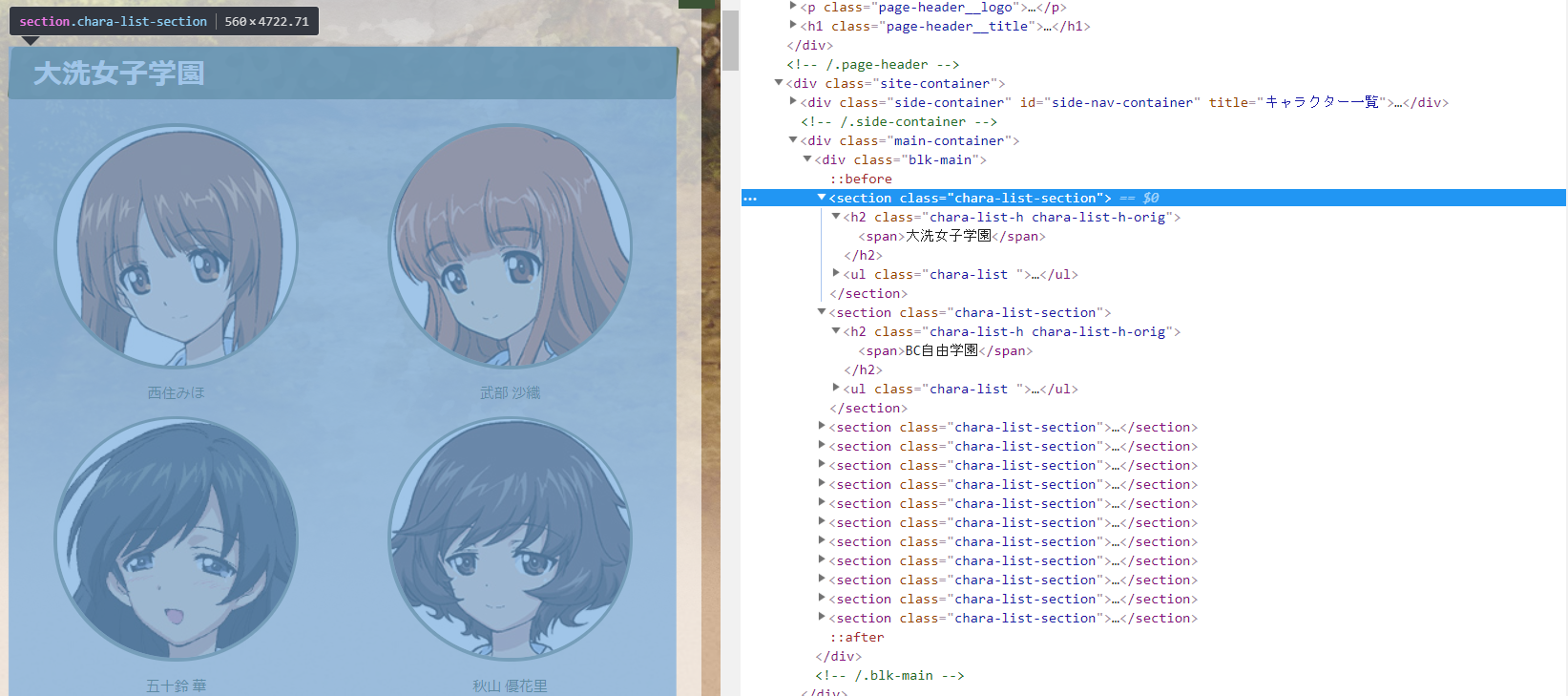
デベロッパーツールを見てみると、学校ごとの情報はsectionタグでclass名「chara-list-section」で分けられていることがわかります。
なのでこの条件に合う情報を抜き出してみます。
>>> schools = soup.find_all('section', class_='chara-list-section')
schoolsには配列でclass名が「chara-list-section」の内容が順番に入っています。
アンツィオ高校は6番目なので、確かめてみるとしっかり抜き取れていることがわかるかと。
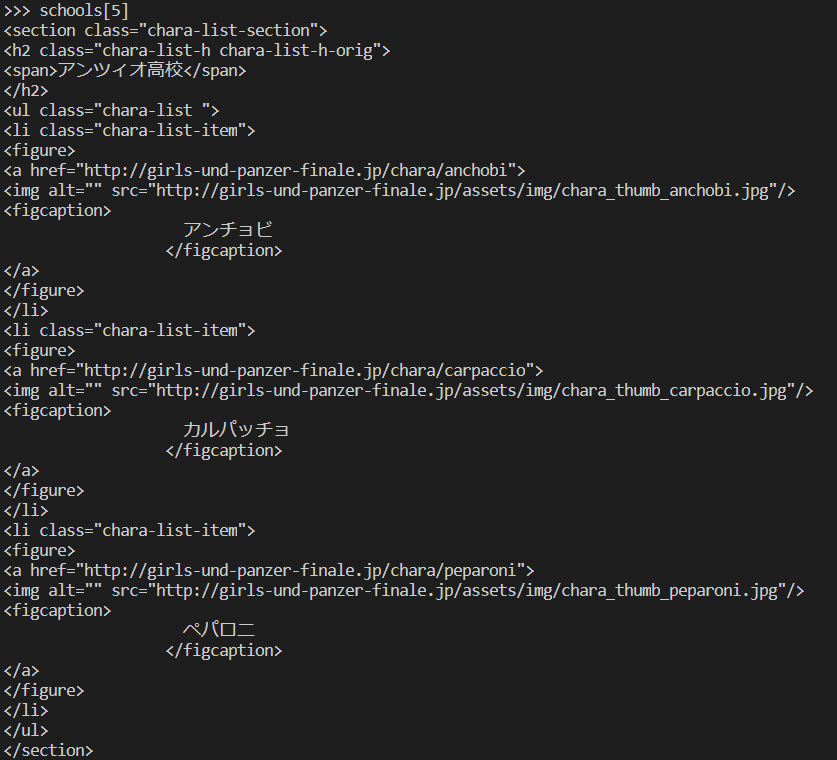
名前を取り出す
生徒の名前はfigcaptionタグに挟まれていることがわかります。
なので
>>> anzio = schools[5].find_all("figcaption")
でfigcaptionタグのみを取り出します。
変数anzioには
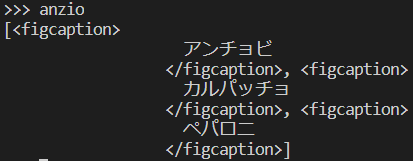
無事に名前のみが入っています。
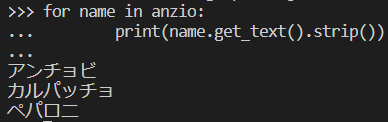
余計な空白などを取り除きつつ表示
最後に純粋に名前だけを取り出して終了です。
あとがき
初歩的な技術を冗長して書いた記事ですねこれ。だって書けることが無かったんだもの…。
明日は@fumihumiさんが素晴らしくかつ為になる深イイ記事を書いてくれるはずなので、楽しみにしましょう。
また、@moya0423くんの記事はこれの上位互換らしいので、それも併せて楽しみにしましょう。
