はじめに
DataDogが2016年10月にAnomaly Detectionをリリースしたようなので基本的な動作を確認してみました。日本語による解説がありますので詳しい内容はこちらをご覧ください
事前準備
DataDogの初期セットアップは既に開通済みで、Monitorがいつでも新規追加の状態とします
シナリオ
監視対象ノードに対し(DataDog Agent からデータが取り込まれている)正常状態とは明らかに異なる「なんらか状態」を起こします。今回はAzure VMを使い、通常の数倍のトラフィックを発生させ、system.net.bytes_rcvd ※1を監視対象データとします
___________________ ___________________________
| | | |
| Traffic Generator | === 打ち込み == > | Target with DataDog Agent |
|___________________| |___________________________|
|
[push]
|
// DataDog (Anomaly Detection) //
|
[notify]
|
// PagerDuty (Integration slack) //
|
[escalation]
|
// Slack //
設定
-
設定例
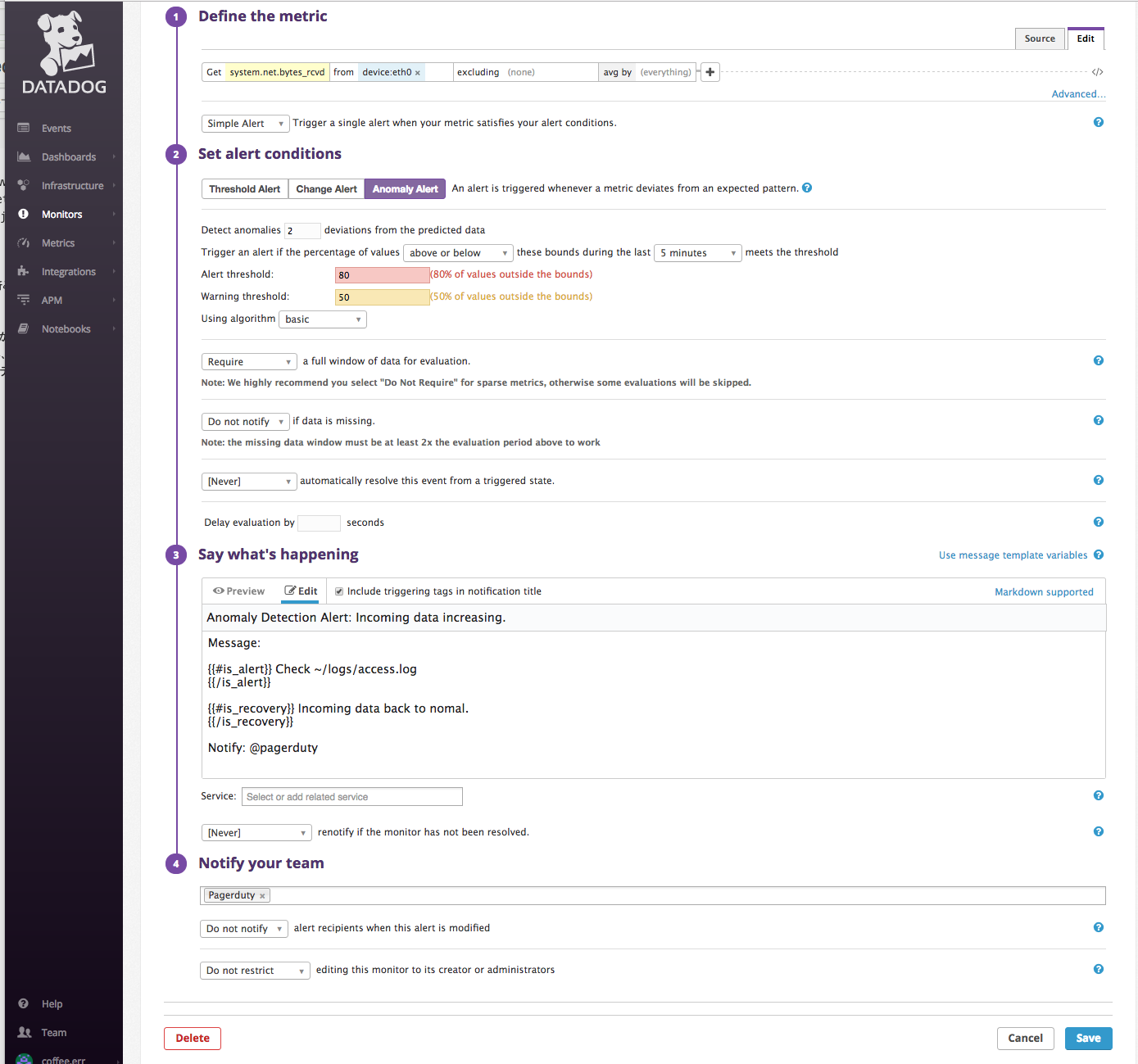
1. Define the metric : GET system.net.bytes_rcvdを選択
2. Set alert condtions : algorithm Basicを選択
3. Say what's happening : Subject, Message 等を埋めます
4. Notify your team : @pagerduty を使い、slackへnotifyを送ります
-
設定完了
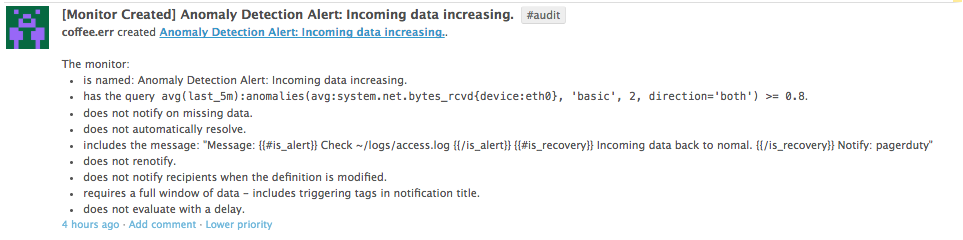
試射
[諸注意]
1. トラフィック発生の際は周りに迷惑を掛けない様、自己責任でお願いします!
3. トラフィック発生は 20% -- 45% -- 65% のように慎重に増やすことがオススメ
4. Set alert condtionsでThreasholdを決めれるので、通常の30%増し程度で十分
確認する
-
datadog
- 平坦なところに突如山が
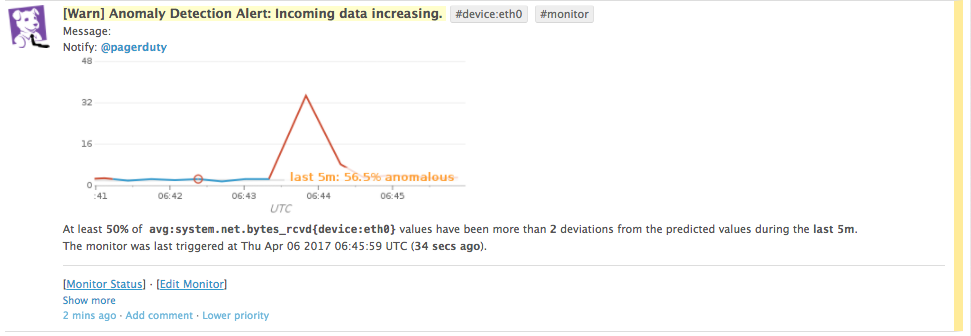
- 平坦なところに突如山が
-
Slackにも通知を確認

まとめ
- 検証期間が短く、短期的に動作確認を行いたい事もあったので、Algorithmは「Basic」を使いました
- 「Basic」は過去のデータを基に、「単純な時間差の移動分位数計算」を元に振る舞いを検知するようで、想定通りに動作を確認できました
- 意図的に発生させた「異常状態」に対して、検知、収束共に素晴らしい反応速度※2でした
- 季節性の変動、長期的な影響を考慮したい場合は「Agile」を使うようです。今回は試していません
- 「Robust」はさらにきめ細かいデータへの適応も可能な様なので、こちらも検証したらどなたか共有をお待ちしてます
※1 ... TCP/80 へのトラフィック流入検知とした為
※2 ... 比較対象はArbor / DD -> PG -> Slack連携のレスポンスという点でも(個人的な体感速度です)