はじめに
機械学習で一番大事だけど面倒なのがアノテーション(教師ラベル作成)です。
画像認識だとVoTTなどのアノテーションツールが出ていますが、マウスでポチポチするのはやはり面倒。
ある程度ラベルを自動的に作成し、おかしいところだけ修正するようにできれば楽できそうです。
Active Learning機能 (VoTT)
そういう要望を叶えてくれる機能が実は世の中にはあって、例えばVoTTのActive Learning機能などがそうです。
VoTTのActiveLearning機能の紹介 - Qiita
ただし使用できる学習済みモデルは決まっていて、タスクによっては使えないこともあります。
私などはマルフク看板をアノテーションしたかったりするのですが、既存の物体検出用のモデルではさっぱりです。というか、だから自分でモデルを学習しようとしているのに。
というわけで、自分で好きなロジックやモデルを使って作成したラベルを、アノテーションツールで読み込めるように変換する方法をご紹介します。
例えば、OpenCVで作った以下のようなラベルをアノテーションツールで読み込み、必要なところだけ修正して深層学習に使うという方法も可能になります。

OpenCV shape detection - PyImageSearch
検証環境
- Windows 10 Home (1903)
- Python 3.6.8
- pillow==7.1.2 (pipからインストール)
- VoTT 1.7.2
記事を書いた2020年5月の時点で VoTT 2.1.0 がリリースされていますが、高機能になりすぎてプロジェクトの構造が複雑で、自分で作ったアノテーションを読み込ませるのが難しそうでした。
そのため、今回は古いバージョンである 1.7.2 で読み込みます。
手順
VoTTのインストール
VoTT 1.7.2を使います。vott-win.exe をダウンロードして、インストールしてください。
Release 1.7.2 · microsoft/VoTT
データの準備
適当な場所にフォルダを作成し、その直下にアノテーションしたい画像 (JPG or PNG) をまとめます。
ここではフォルダのフルパスを C:\foo\bar\myproj とします。
VoTT 1.7.2の場合、対応するプロジェクトファイルの名前は C:\foo\bar\myproj.json となります。
自動アノテーション結果の作成
import sys
import json
import hashlib
import urllib
from pathlib import Path
from PIL import Image # pillow 7.1.2
imgdir = Path(sys.argv[1]).resolve()
projfile = imgdir.with_suffix(".json")
if projfile.exists():
# 既存のプロジェクトを読み込む
f = open(projfile, "r+")
data = json.load(f)
else:
# プロジェクトを新規作成する
f = open(projfile, "w")
data = {
"frames": {},
"framerate": "1",
"inputTags": "mrfk", # タグリスト(カンマ区切り)
"suggestionType": "track",
"scd": False,
"visitedFrames": [],
"tag_colors": ["#0cc7ff"] # 領域の色(任意)
}
with f:
for imgfile in imgdir.glob("*.*"):
if imgfile.suffix.lower() in [".jpg", ".png"]:
if imgfile.name in data["frames"]:
# エントリがある場合はスキップ
continue
else:
# エントリがない場合、新規作成
frame = []
data["frames"][imgfile.name] = frame
# 画像のサイズを取得
img = Image.open(imgfile)
w, h = img.size
img.close()
# 自分で検出した領域を列挙する(仮)
points = [ # 頂点を辺でつながっている順に列挙する
{"x": 0.0, "y": 0.0},
{"x": w, "y": 0.0},
{"x": w, "y": h},
{"x": 0.0, "y": h}
]
box = { # 外接長方形
"x1": min(p["x"] for p in points),
"y1": min(p["y"] for p in points),
"x2": max(p["x"] for p in points),
"y2": max(p["y"] for p in points)
}
region = box.copy()
region.update({
"width": w,
"height": h,
"box": box,
"points": points,
"type": "rect",
"tags": ["mrfk"], # 領域に付与するタグリスト
})
frame.append(region)
# プロジェクトを保存
f.seek(0)
json.dump(data, f)
コマンドプロンプトから以下のように実行すると、各画像の全領域に mrfk というタグが付与されます。
python make_vott_project.py C:\foo\bar\myproj
VoTTでの編集方法
VoTT 1.7.2 を起動し、画像のアイコンをクリックし、C:\foo\bar\myproj フォルダを選択します。
プロジェクトのファイル名はフォルダ名から自動的に決まることにご注意ください。

以下の画面はそのまま Continue でOK

ラベルが画像全体に対してついています。左向き三角2個・右向き三角2個のボタンで画像を切り替えられます。

ラベルの修正をしたい場合は、左上の Regions Manipulation を選択してから、領域の四隅をドラッグ&ドロップします。

メニューの File → Save で上書き保存できます。
更新されたjsonファイルを読み込んで、適当に学習データを作ればよいですね。
カスタマイズ
OpenCVなど外部で作ったアノテーションを読み込ませる
# 自分で検出した領域を列挙する(仮)
の部分で、points に検出結果を入れてください。
領域の各頂点の座標を、辺でつながっている順番に指定していきます。
例えば以下のチュートリアルのコードを流用するなら
OpenCV shape detection - PyImageSearch
frame = []
# loop over the contours
for c in cnts:
(略)
points = [{"x": p[0], "y": p[1]} for p in c]
(略)
frame.append(region)
のようにすれば作れます。
多角形の領域を指定する
長方形ではない複雑な領域を指定したい場合は
region.update({
"width": w,
"height": h,
"box": box,
"points": points,
"type": "rect",
"tags": ["mrfk"], # 領域に付与するタグリスト
})
この部分を
region.update({
"width": w,
"height": h,
"box": box,
"points": points,
"type": "polygon", # ここを変更
"tags": ["mrfk"], # 領域に付与するタグリスト
})
に変更するだけです。
こうすると、1つの頂点を動かしたときに他の頂点が動かなくなります。以下のように、長方形ではない形状を作れます。

タグを複数作る
まず、以下の inputTags のところに名前をカンマ区切り文字列で指定して
data = {
"frames": {},
"framerate": "1",
"inputTags": "mrfk,chst,wide", # タグリスト(カンマ区切り)
"suggestionType": "track",
"scd": False,
"visitedFrames": [],
"tag_colors": ["#0cc7ff"] # 領域の色(任意)
}
各領域の tags にはタグのリスト(カンマ区切り文字列ではなく、Pythonのリスト)を指定します。
region.update({
"width": w,
"height": h,
"box": box,
"points": points,
"type": "rect",
"tags": ["mrfk", "chst"], # 領域に付与するタグリスト
})
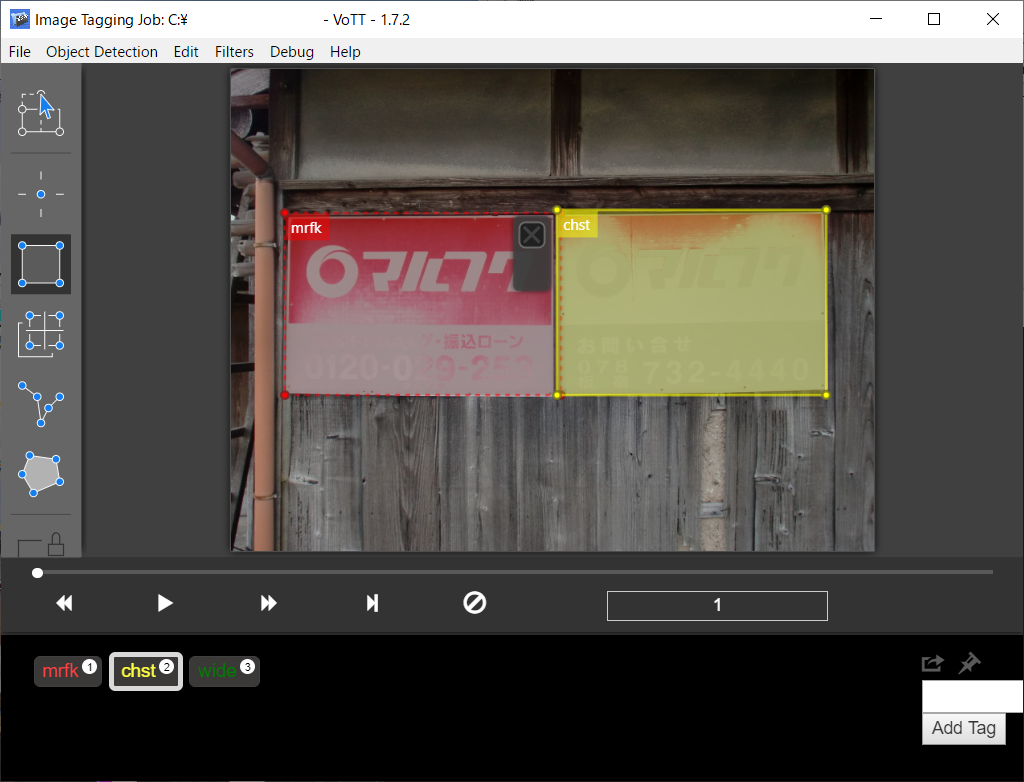
ご覧のように、ウィンドウ左下と画像のツールチップに反映されています。

既存の物体検出結果のクラスをさらに細分化したいといった場合には、inputTags だけを増やしておいて、各領域のクラス(タグ)はVoTTで編集するという使い方も可能です。
タグの色を変える
領域の色や左下のタグリストの文字色を変えたい場合は、以下の tag_colors に色のリストを指定すればOKです。
data = {
"frames": {},
"framerate": "1",
"inputTags": "mrfk,chst,wide", # タグリスト(カンマ区切り)
"suggestionType": "track",
"scd": False,
"visitedFrames": [],
"tag_colors": ["#ff4040", "#ffff40", "#008000"] # 領域の色(任意)
}
以下のように好きな色で出せるようになります。(画像は自分でアノテーションを編集した後のものです)