asyncioって?
asyncio は async/await 構文を使い 並行処理の コードを書くためのライブラリです。
asyncio は、高性能なネットワークとウェブサーバ、データベース接続ライブラリ、分散タスクキューなどの複数の非同期 Python フレームワークの基盤として使われています。
asyncio --- 非同期 I/O — Python 3.9.0 ドキュメント
import asyncio
async def main():
print('Hello ...')
await asyncio.sleep(1)
print('... World!')
# Python 3.7+
asyncio.run(main())
なにこれ、C#の async/await みたいなノリじゃないですか…。
Python使いなのに、恥ずかしながらこの前まで知りませんでした。
たまにC#のコードも書きますが、async/await 周りを触るたびに、これPythonにも欲しいなーと思っていました…。
C# での非同期プログラミング | Microsoft Docs
Pythonで非同期処理といえば
threading.Threadmultiprocessing.Process
あたりのイメージでした。
並行実行 — Python 3.9.0 ドキュメント
これからはasyncioも選択肢に入ってくるのでしょうか。
検証環境
- CentOS 7 (x64)
- Python 3.8.6
Hello World!
冒頭のサンプルは上記公式ドキュメントに載っていたコードです。まずはこれを動かしてみます。
コードのコメントにもありますが Python 3.7以降 で動きます。
追加ライブラリのインストールなどの事前準備は特に必要ありません。
import asyncio
async def main():
print('Hello ...')
await asyncio.sleep(1)
print('... World!')
# Python 3.7+
asyncio.run(main())
$ python3 helloworld.py
Hello ...
... World!
Hello... が出てから ... World! が出るまでに1秒の間があることをご確認ください。
ポイントとしては以下があります。
-
main()に相当する処理をasync付きの関数として書く(コルーチン) -
async付きの関数の中ではawaitができる -
asyncio.run(main())を1回だけ呼び出す
でもこれだけだと何も嬉しくないですよね?非同期処理でもなんでもないし。
ちゃんと非同期処理する例
ではこれだとどうでしょうか?
import asyncio
async def func1():
print('func1() started')
await asyncio.sleep(1)
print('func1() finished')
async def func2():
print('func2() started')
await asyncio.sleep(1)
print('func2() finished')
async def main():
task1 = asyncio.create_task(func1())
task2 = asyncio.create_task(func2())
await task1
await task2
asyncio.run(main())
実行してみると、func1() と func2() がほぼ同時に始まって、1秒後に func1() と func2() がほぼ同時に終わっていることが分かります。
func1() started
func2() started
func1() finished
func2() finished
await というのは、ざっくり言えば**「他人に順番を譲って自分は待つ」**というイメージです。ここで「他人(の仕事)」にあたるものが Task で、以下のいずれかの方法で作ることができます。
-
asyncio.sleep()のようにあらかじめ定義された処理を指定する -
asyncio.create_task()でasync付きの関数の戻り値(コルーチンオブジェクト)をラッピングする
という方法があります。
ここで、単に func1() と書くだけでは何も起こりませんが、asyncio.create_task(func1()) のように使うことで、func1() を動き始められる状態にスタンバイさせることができます。あくまで「スタンバイさせる」というだけで、すぐに動き始めるわけではありません(後述)。
asyncio.sleep?
ここで気になるのが await asyncio.sleep(1)。意味合いは分かりますが、「n秒待つ」といえば time.sleep() が定番ですよね。というわけでこっちに変えてみたらどうなるでしょう。
import asyncio
async def func1():
print('func1() started')
#await asyncio.sleep(1)
time.sleep(1)
print('func1() finished')
async def func2():
print('func2() started')
#await asyncio.sleep(1)
time.sleep(1)
print('func2() finished')
async def main():
task1 = asyncio.create_task(func1())
task2 = asyncio.create_task(func2())
await task1
await task2
asyncio.run(main())
残念ながら func1() が終わるまで func2() は開始されません。
func1() started
func1() finished
func2() started
func2() finished
2つの処理を並列に動かすためには、await asyncio.sleep(1) で処理を止めることが必要になります。
coroutine asyncio.sleep(delay, result=None, *, loop=None)
delay 秒だけ停止します。
result が提供されている場合は、コルーチン完了時にそれが呼び出し元に返されます。
sleep() は常に現在の Task を一時中断し、他の Task が実行されるのを許可します。
この「常に現在の Task を一時中断し、他の Task が実行されるのを許可します。」というのがポイントです。
asyncio.sleep() を呼び出して待機する場合には、**待っている間に他の人の仕事が入ってきたら順番を譲ります。**言い換えれば、ただ時間の掛かる処理をさせるだけでは、他の処理が入ってくることはできません。
もうひとつ混乱しそうな例。
import asyncio
import time
async def func1():
print('func1() started')
await asyncio.sleep(1)
print('func1() finished')
async def func2():
print('func2() started')
time.sleep(2)
print('func2() finished')
async def main():
task1 = asyncio.create_task(func1())
task2 = asyncio.create_task(func2())
await task1
await task2
asyncio.run(main())
func1() では asyncio.sleep() を使って待機しますが、func2() では time.sleep() を使っています。そして func2() のほうがスリープ時間が長いのです。
果たしてこの実行結果は…
func1() started
func2() started
func2() finished
func1() finished
こうなります。1秒しか寝ないはずの func1() が、なぜか func2() よりも後に終わっています。
ここで先ほどのドキュメントの説明をもう一度見てみましょう。
sleep() は常に現在の Task を一時中断し、他の Task が実行されるのを許可します。
asyncio.sleep() で他人に順番を譲ることはできても、自発的に割り込むことはできません。asyncio.sleep() で寝ている間に新しい処理が入ってきたらそちらに切り替わりますが、スリープ時間が終わったからといって、実行中の(asyncio.sleep() 中ではない)処理を中断して制御を戻す、ということはないわけです。
先ほどの例であれば、func1() で1秒待機した後、まだ func2() が動いているので、無理に順番を奪い取ることはしません。func2() が終わるのを待ってから、続きの処理に取り掛かります。律儀ですね。1
ここまでを踏まえて図解
うまく並列処理できている async_sleep1.py の処理を図解するとこんな感じでしょうか。
色を塗っているところが、実際に制御を持っている時間を表します。
なお、以下では asyncio.sleep() を aio.sleep() と略しています。
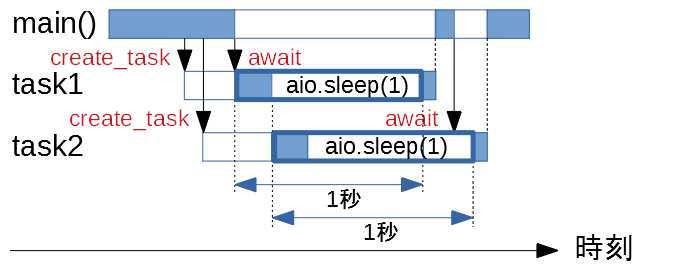
-
main()はcreate_task()でtask1とtask2をスタンバイさせる。task1とtask2はすぐには開始されずに待機する。 -
awaitによって、main()は制御を手放し、task1が終わるまで待つ。task1が制御を受け取る。 -
task1はasyncio.sleep(1)を実行することにより、制御を手放し、1秒間待つ。task2が制御を受け取る。 -
task2はasyncio.sleep(1)を実行することにより、制御を手放し、1秒間待つ。実行できる処理がない状態になる。 -
task1が1秒間待ったので、制御を受け取る。 -
task1の処理が終了したので、main()が制御を取り戻す。 -
awaitによって、main()は制御を手放し、task2が終わるまで待つ。実行できる処理がない状態になる。 -
task2が1秒間待ったので、制御を受け取る。 -
task2の処理が終了したので、main()が制御を取り戻す。 -
main()の処理が終了する。
対して、async_sleep3.py の処理を図解すると以下のようになるでしょう。
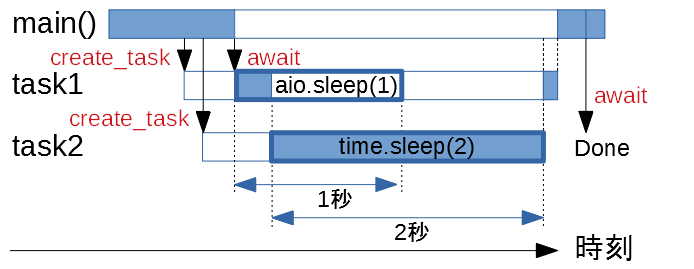
time.sleep() を使う場合は、task2 が制御を持ち続けてしまっています。そのため、task1 は1秒待ったにもかかわらず、task2 が終わるまで再開できません。
さて、このあたりで我々は気づいてしまいます。
CPUで計算を回している間に並行して別の処理をする、という使い方はできないということに…。
複数の処理が同時に回っていることはありません。こいつは実はシングルスレッドなのです。
例えば、threading.Thread ベースであれば以下のような処理ができるでしょう。2
import threading
def func1():
print('func1() started')
x = 0
for i in range(1000000):
x += i
print('func1() finished:', x)
def func2():
print('func2() started')
x = 0
for i in range(1000000):
x += i * 2
print('func2() finished:', x)
def main():
thread1 = threading.Thread(target=func1)
thread2 = threading.Thread(target=func2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
main()
func1() started
func2() started
func1() finished: 499999500000
func2() finished: 999999000000
asyncioという名前をよく見ると
io ですね。つまりはじめからI/O(入出力)待ちが中心の処理で(見かけ上)並列処理をさせるための仕組みといえます。
ただ、合間に他の処理をさせるためには専用の関数を使って待機する必要があり、time.sleep() さえも使えないのです。
よく登場するI/O待ちといえばネットワークの送受信とかだと思うのですが、ここまでの結果から推察するに、threading.Thread などと違って普通に入出力のコードを書いても並列処理にはなりそうもないわけで、いったいどうやって使っていけばよいのでしょう…?
入出力を並列化するには
ここまでで分かることは、入出力を非同期で(見かけ上並列に)行うためには**「入出力で待っている間に他の処理に順番を譲る」という処理が必要だ**、ということです。
そこで、sleep のように、入出力の待ち時間に順番を譲るような処理をする関数が、asyncio の中に用意されています。
以下のドキュメントにある、ソケット通信を行う例を試してみます。
Streams — Python 3.9.0 ドキュメント
import asyncio
import urllib.parse
import sys
async def print_http_headers(url):
url = urllib.parse.urlsplit(url)
if url.scheme == 'https':
reader, writer = await asyncio.open_connection(
url.hostname, 443, ssl=True)
else:
reader, writer = await asyncio.open_connection(
url.hostname, 80)
query = (
f"HEAD {url.path or '/'} HTTP/1.0\r\n"
f"Host: {url.hostname}\r\n"
f"\r\n"
)
writer.write(query.encode('latin-1'))
while True:
line = await reader.readline()
if not line:
break
line = line.decode('latin1').rstrip()
if line:
print(f'HTTP header> {line}')
# Ignore the body, close the socket
writer.close()
url = sys.argv[1]
asyncio.run(print_http_headers(url))
以下のようにコマンドライン引数にURLを付けて実行すると、HTTPヘッダが返ってきます。
$ python3 stream.py https://www.google.com/
HTTP header> HTTP/1.0 200 OK
HTTP header> Content-Type: text/html; charset=ISO-8859-1
(以下略)
ただ、これだけだと非同期でも何でもなくて面白くないので、待っている間にCPUを使う処理を裏で走らせておきましょう。
import asyncio
import urllib.parse
import sys
async def print_http_headers(url):
url = urllib.parse.urlsplit(url)
if url.scheme == 'https':
reader, writer = await asyncio.open_connection(
url.hostname, 443, ssl=True)
else:
reader, writer = await asyncio.open_connection(
url.hostname, 80)
query = (
f"HEAD {url.path or '/'} HTTP/1.0\r\n"
f"Host: {url.hostname}\r\n"
f"\r\n"
)
writer.write(query.encode('latin-1'))
while True:
line = await reader.readline()
if not line:
break
line = line.decode('latin1').rstrip()
if line:
print(f'HTTP header> {line}')
# Ignore the body, close the socket
writer.close()
async def cpu_work():
x = 0
for i in range(1000000):
x += i
if i % 100000 == 0:
print(x)
await asyncio.sleep(0.01)
async def main(url):
task1 = asyncio.create_task(print_http_headers(url))
task2 = asyncio.create_task(cpu_work())
await task1
await task2
url = sys.argv[1]
asyncio.run(main(url))
以下のように、サーバーから応答が返ってくるまでは裏で計算を進めておき、返ってきたらその処理をして、その処理が終わったら残りの計算をする、といった動きをします。
0
5000050000
20000100000
45000150000
80000200000
HTTP header> HTTP/1.0 200 OK
HTTP header> Content-Type: text/html; charset=ISO-8859-1
(中略)
125000250000
180000300000
245000350000
320000400000
405000450000
open_connection() や readline() は、応答が返ってくるまで制御を手放して他の人に順番を譲ります。順番を譲ってもらった cpu_work() (task2) はCPUを使って計算をするのですが、定期的に他の人に順番を譲ろうとします。誰も来なかったら続きの計算をして、誰かが来れば順番を譲り、相手の仕事が終わるまで待ちます。
ここで cpu_work() の中で await asyncio.sleep(0.01) と書くのがポイントでして、これを忘れると、計算中にサーバーから応答が返ってきても処理することができません。
いにしえのVisual Basic 6.0にあった DoEvents() を彷彿とさせます。重いループ処理をするときに、ループの中で呼んでおかないとウィンドウが応答なしで固まっちゃうというやつですね。ピンと来ない方はお家の人に聞いてください。
本当に並列処理したい
とはいえ、ここまでは所詮シングルスレッド。CPUを回す処理を複数同時に実行するために await で書きたくなることもあると思います。また、入出力待ちが絡む処理であっても、read や write のたびに await を意識するのは割と面倒なので、楽したくなることもあると思います。
そのための方法として、run_in_executor() を使って処理をプロセスプール(またはスレッドプール)に投入する方法があります。
import asyncio
import concurrent.futures
def func1():
print("func1() started")
s = sum(i for i in range(10 ** 7))
print("func1() finished")
return s
def func2():
print("func2() started")
s = sum(i * i for i in range(10 ** 7))
print("func2() finished")
return s
async def main():
loop = asyncio.get_running_loop()
with concurrent.futures.ProcessPoolExecutor() as pool:
task1 = loop.run_in_executor(pool, func1)
task2 = loop.run_in_executor(pool, func2)
result1 = await task1
result2 = await task2
print('result:', result1, result2)
asyncio.run(main())
これを実行すると、以下のように func1() と func2() が同時に動いていることが分かります。3
func1() started
func2() started
func1() finished
func2() finished
result: 49999995000000 333333283333335000000
実は、「プロセスプール」という仕組みを使って、複数の仕事を同時に走らせることができるのです(プロセスプール自体は asyncio が出てくる以前からあります)。いくつかのプロセスをあらかじめ確保しておき、それを使い回して並列処理をさせる方法です。
ここで func1() と func2() には async がついていないことに注意してください。あくまで普通の関数です。
今までは asyncio.create_task() で処理を入れていたところ、loop.run_in_executor() を使っています。
これまでは main() も含めて1人しか仕事をすることができず、さらに順番を譲ってもらえない限り新しい仕事を始めることができませんでした。asyncio.create_task() を実行した段階では main() 自身が制御を持っているので、投入した処理はすぐには開始されません。
一方、**プロセスプールを使うことにより、複数の仕事を同時に動かせるようになります。しかも main() とは別枠なので、loop.run_in_executor() を呼び出した時点で処理はすぐに開始できます。**そして確保してあるプロセス数の範囲内であれば、複数の仕事を同時に実行できます。
「確保してあるプロセス数」のデフォルト値は、CPUのプロセッサ数(ハイパースレッディングを含めた論理コア数)です。試しに
with concurrent.futures.ProcessPoolExecutor() as pool:
この部分を
with concurrent.futures.ProcessPoolExecutor(max_workers=1) as pool:
に変えてみてください。func1() が終わるまで func2() が始まらなくなるでしょう。
今までの面倒な仕組みを思えば、かなり便利に使えるようになりました。これなら使いたいと思えるのではないでしょうか(個人差があります)。もはや io じゃないというツッコミはやめてあげましょう。
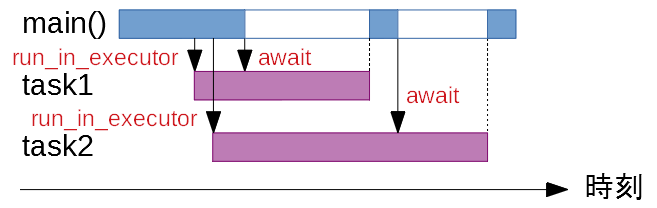
図解すると
以下のような感じです。青が main() がデフォルトのスレッドで、紫がプロセスプールで動いている処理になります。main() とは別に、紫の処理を max_workers またはプロセッサ数まで同時に実行することができます。
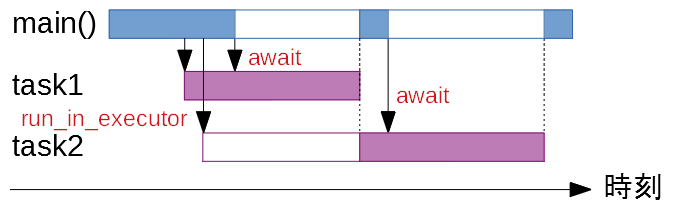
max_workers=1 のときはこんな感じですかね。紫の処理は同時に1つまでなので、task1 (func1()) が終わるまで次は動きません。
その他Tips
処理の戻り値を取得したい
先ほどの executor.py の例でも使いましたが、非同期で実行している関数の戻り値は、await 文の戻り値として取得することができます。
import asyncio
async def func1():
await asyncio.sleep(1)
return 12345
async def main():
task1 = asyncio.create_task(func1())
ret = await task1
print(ret) # 12345
asyncio.run(main())
複数の処理を同時に await したい
1個ずつ待つのではなく、全部終わるまで待ちたいときは asyncio.gather を使います。
先ほどの executor.py の例ならこんな感じです。
result1, result2 = await asyncio.gather(task1, task2)
タイムアウト
asyncio.wait_for() を使うと、一定時間で処理が終わらなかったときに処理を中断することができます。
以下の例では func1() finished は実行されずにプログラムが終了します。
import asyncio
async def func1():
print("func1() started")
await asyncio.sleep(10)
print("func1() finished")
async def main():
task1 = asyncio.create_task(func1())
try:
ret = await asyncio.wait_for(task1, 1)
print(ret)
except asyncio.TimeoutError:
print("timeout...")
asyncio.run(main())
最後に
必要になったらドキュメントを見て調べることにして、とりあえず始めてみましょう。
asyncio --- 非同期 I/O — Python 3.9.0 ドキュメント
-
もちろん、
func2()がasyncio.sleep()で順番を譲ってくれていたらfunc1()は動き出すことができます。 ↩ -
このコードでは2つの処理が(見かけ上)並列に動作しますが、GILがあるために、合計の処理時間が短くなるわけではありません。マルチコアで高速化したければ
multiprocessing.Processのほうがよいですね。→ Pythonで並列処理をするなら知っておくべきGILをできる限り詳しく調べてみた - Qiita ↩ -
論理コア数が2以上の場合に限ります。もっとも今どきVPSやAWSなどのクラウドサービスを使っているのでない限り、ほぼ確実に2コア以上はあるでしょうが。 ↩