この記事は Kubernetes Advent Calendar 2022 の9日目の記事です。
この記事では、Kubernetes ControllerをScale-Outするアーキテクチャについて考察します。(注: ここで議論されているアーキテクチャは、プロダクションに適用されているものもありますが、まだ検証段階の域を超えていないものもあります。ご注意ください。)
2022/12/22に開催されるKubernetes Meetup Tokyo #55にて本記事の内容について、もう少し詳しく実装にも踏み込んで発表(スライド)しますので、そちらも是非ご参加ください👋
(おさらい) 典型的なKubernetes Controllerのアーキテクチャ
まずは典型的なKubernetes Controllerの作りをおさらいしてみます。
Pod内部のアーキテクチャ
下図はcontroller-runtimeをつかったControllerのソフトウェアアーキテクチャの概要です。
ものすごく大まかに説明すると、Controllerは下記のような動作をします。
- Kubernetes APIをつかってリソースの変更イベントをWatchし内部のeventqueueに貯めて
- eventqueueからeventがフェッチされInfomerに渡されます
- Informerはそのeventを使ってincrementalにin-memory Cacheを更新しつつ
- Controllerが事前に
Watch()等で登録したEvent Handlerにeventを渡します - Event Handlerはeventをreconcile要求に変換しreconcile queueに詰めます
- Controllerはreconcile queueからreconcile要求をと知りだし、Reconcilerに渡します。
- Reconcilerは並列に実行できます
- Reconcilerは実際にreconcile要求を処理します
- 通常Read系のAPIはin-memory Cacheを通して行います
Pod間のアーキテクチャ
通常Kubernetes Controllerは下図のように、Deployment等をつかって複数レプリカをデプロイします。
- 複数レプリカはActive/Warm Standbyな感じでデプロイされる
- レプリカPod間でLeader Electionを行い
-
LeaderのみがReconcile を行い、
- こうする(Single Writerにする)ことで、リソースの並行更新による衝突が起きないことを保証できるためです
- FollowerはStandby(自分がLeaderになったらすぐ動き出せるように)
-
LeaderのみがReconcile を行い、
典型的なKubernetes ControllerのアーキテクチャはScale-Upしかできない
つまり、このアーキテクチャだと、Scale-Upはできるけれども、Scale-Outは出来ないアーキテクチャであると言えます。Scale-Upの限界が来るとReconcileが詰まり始める
- Pod内部は処理の並行度を上げられますが限界があります1
- 限界が来ると
- Reconcilerの処理スループットよりもReconcile要求が多くなり、
- Controller内部のqueueが詰まりはじめ、
- Reconcile間隔が長くなってReconcileされていないように見えたり、
- in-memory Cacheの内容もStaleし始めるためReconcile結果もStaleしてしましいます。
- 特に、下記のようなControllerの場合は並行度が上げられても、Reconcile自体の処理時間が長くなりがちで、すぐに詰まってしまうことがあります
- Reconcile対象のResourceのManifestサイズが大きくて、Resource数も大量にある
- Reconcilerが外部のAPI、Database、大規模なI/O等Latencyの高い処理に依存している
ControllerをScale-Outする方法
そこで、やっぱりControllerをScale-Outさせたくなるわけです。
もともとLeaderしかReconcileしないのがやりすぎなわけですから、Controller Podを全部活用することを考えます。ただ、同じリソースを複数PodからReconcileしてしまうと、並行更新によるConflictが起きてしまうので、重複の内容になんとかしてReconcile対象のオブジェクトをController Podに割り振ってやると良さそうです。
いわゆる、シャーディングですね。
Namespace単位でControllerをDeployする
まず最初に思いつく方法が、同じ構成をNamespace単位でDeployする方法です。これなら難しい割り振り方法を考えなくても、自然に重複なく割り振ることができそうです。実際、Argo Workflowのcontrollerはnamespaceに閉じたdeployをサポートしています。
この方法の良い点としては
- 実装が簡単
- Manifestもほぼそのまま使えそう
- ControllerのServiceAccountの権限がNamespaceに閉じる2
が考えられる一方で、
- Controller Podが大量に必要3
- Namespaceの増減に対応しづらい
- Namespace間の負荷の偏りは防げない
- Cross-NamespaceなReconcileはNG
- Cluster ScopeのResourceもNG
という欠点もあります。
ということで、やはり、汎用性を考えてもリソース単位でシャーディングしたいと思いますよね。
Resource単位でシャーディングする
既に試みていらっしゃる方がいましたので、ここではそれを紹介します。@stackitcloudのエンジニアで、gardener/gardenerのメンテナでもある、Tim Ebert @timeberttさんです。彼の今年の修士論文である"Towards Horizontally Scalable Kubernetes Controllers"です(できたてほやほや!!)。彼の成果は主に下記の3つのGithub Repoに分かれています。
- timebertt/thesis-controller-sharding: 修士論文本体
- timebertt/kubernetes-controller-sharding: Shardingに対応したサンプルController実装
- timebertt/controller-runtime@v0.12.3-sharding-1: Sharding対応のcontroller-runtime
アーキテクチャ概要
下記の図は kind: Foo 向けのControllerをシャーディングするアーキテクチャの概要図です。
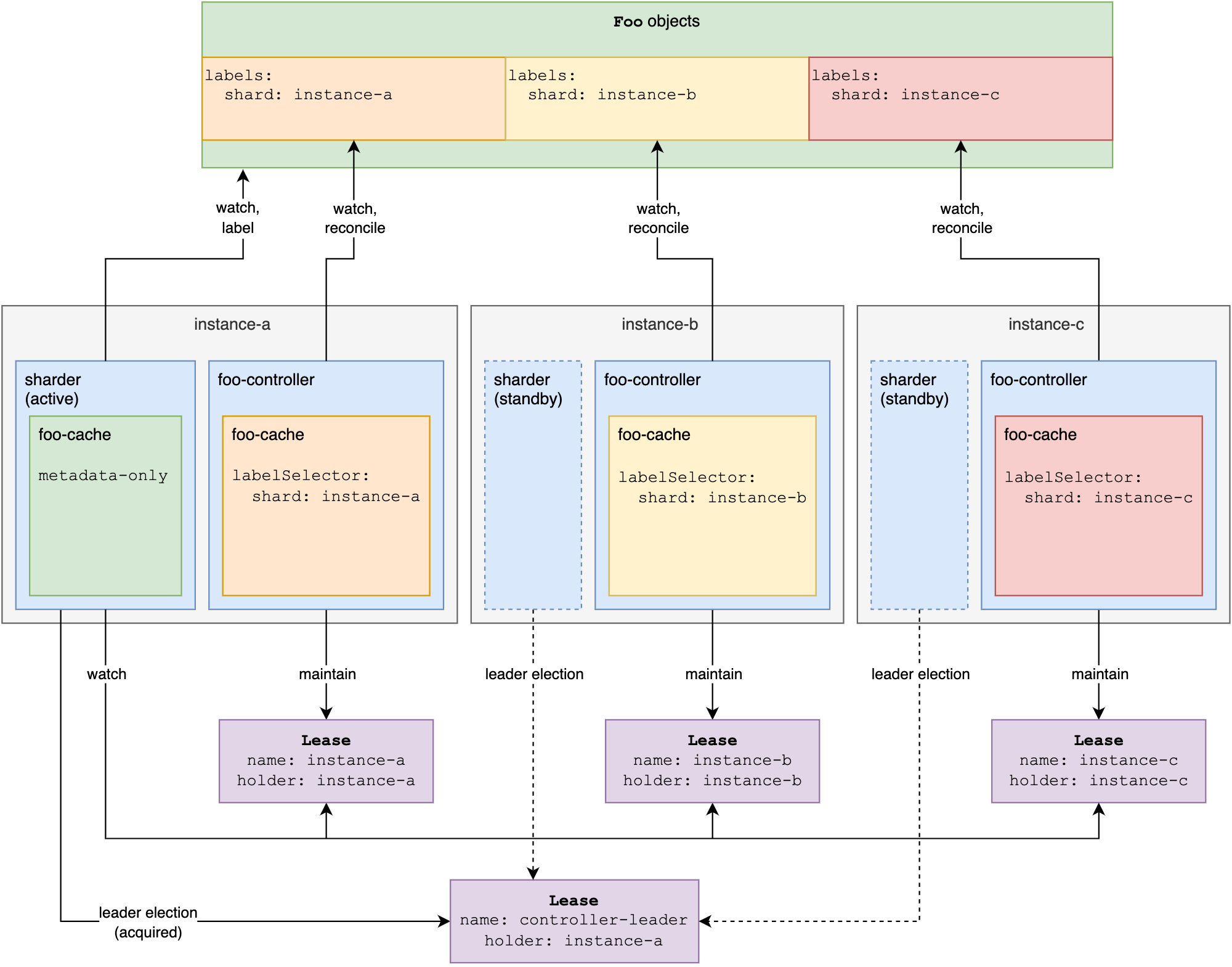
-
ShardはLeaseで定義
- Shard名 = Lease名 = Controller Pod名 4
-
Sharder (Singleton)
- Shard群をwatchして、Resource群をshardに割り振り、Reconcile対象リソース(図中だとFooに
shard:<shard名>を付与(by Consistent Hashing)
- Shard群をwatchして、Resource群をshardに割り振り、Reconcile対象リソース(図中だとFooに
-
Controller (≒Shard)
-
shard:<shard名>ラベルが付いているリソースのみをReconcile - 自身のShardのstatusをLeaseで管理(実質1podなのでheartbeatによる死活監視)
-
思ったより複雑だという感じがするかもしれません。ただオブジェクトをContistent Hashするだけなら、Controller Podを各PodからListできるのだから、そこでやればいいのではないか?と思う方も居ると思います。
実際にkube-state-metricsでは古くから、Controller Pod内で独立してConsistent Hashingすることで負荷を分散する手法が取られています5。ただ、各Controller Podで独立してConsistent Hashingを計算すると、Controller Podの再起動やScale-Out/Inの際に各Podで計算される割当が一致しなくなり、結果としてリソースが複数のController Podに割当たる可能性が排除できません。kube-state-metricsはwatchしているmetricsをexportするだけですのでこれでもあまり問題にならないのですが、実際のControllerでは不都合があると考えられます。
そこで、このちょっと複雑に見えるアーキテクチャがなぜそうなっているのか?を次の設計ポイントに分けて解説していきます。
- Shardメンバーシップと耐障害性
- オブジェクトの振り分け
- オブジェクトの割当
- 並行Reconcileの防止
設計ポイント1: Shardメンバーシップと耐障害性
ここでは、2つの設計判断についてその背景を説明します。
- SharderがSingletonになっている
- 上で説明したようにConsitent Hashingによるオブジェクトの振り分けはReconcileの並行更新を防ぐためにController Pod群で判断のずれがあっては困ります。そこで、SharderというプロセスをController Pod群でSingletonで保持し、そこでオブジェクトの振り分けを行うこで、認識ズレが発生しないようにしています。Consistent Hashingを行うために必要なのは、resourceのUIDのみですので、オブジェクト数が多くなってもあまり問題にならないと考えられます。
- ShardがLeaseである(Podじゃない)
- 実質Controller PodがShardなんだから、わざわざLeaseを挟んでいる理由が気になるかもしれません。これは一時故障時のConstent Hashingの安定性が理由です。Shard=Podだと、Rolling UpdateやPodの障害時にShardが増減してしまい、リソース→Shardの割当に移動が生じてしまうのです。Leaseにすることで、短時間のPodの不在にたいしてRobustなリソース割当が実現できるようになっています。
設計ポイント2: オブジェクトの振り分け
これはここではあまり詳しくは説明しません。リソース➔Shardの割当に関して、Shardの増減に対して、割当の変更量を少なくするためにConsistent Hashingを使っています。
設計ポイント3: オブジェクトの割当
リソース➔Shardへの振り分けはSharderによってConsistent Hashingで決定されますが、それを各Shardを担当するController Podにどのように知らせるか?です。
ここでは リソースにshard: <shard_id>というラベルを付与する ことで実際の割当を行っています。__ラベルをつかうことで、リソースを担当するshardが高々1つ__という条件を保証でき、重複割当を防ぎ並行更新を防ぐことが出来ます。
ただし、まだこれだけでは並行Reconcileは完全には防ぎきれないので注意が必要です。あくまでラベルはSharderによるリソース割当の判断を記録したに過ぎません。実際のReconcile処理は各Controller Podがリソースをpull(watch)してReconcile処理を実行しているので、割当判断をラベルに記録したからと言ってそれがController Podに伝わっているわけではないからです。
具体的には、Shardの増減に伴って、あるリソースがshard-aからshard-bに移動した場合を考えましょう。この時、リソースのshardラベルの値はshard-aからshard-bに変更されますが、shard-a Podがこの変更を受け取っておらずReconcileを継続していたらどうでしょうか? さらに、shard-bPodが割当を検知してReconcileを始めてしまったらどうなるでしょうか?
つまり、ラベルを使うことでリソース➔Shardの割当は高々1にできるけれど、shard移動時にはより細かなケアが必要であることがわかります。
設計ポイント4: 並行Reconcileの防止
Shardの増減が起きる典型例はController PodのScale-Out/In時です。この時にどのような処理が必要になるかを説明します。
- Scale-Out時
-
shard-bが出現し、Sharderはshard-a➔shard-bに再割当てを行う場合 - いきなりラベル値を変更するのではなく、
drain: "true"ラベルをリソースに付与します -
shard-aPodはdrainラベルによってSharderが再割り当てをしようとしていることを検知し、 - その応答として、
shardラベル、drainラベルを削除します(当然この段階で当該ResourceのReconcileを放棄します) - Sharderが、すべてのラベルが消えたことを確認後
shard: shard-bへの割当を行います
-
- Scale-In時
-
shard-aが居なくなる(つまりLeaseがexpireした場合)、 - (この時
shard-aも自身がLeaseにheartbeatを送れずexpireしたことを検知しているはずなのでReconcile処理は止まっています) - ので、Sharderは安全にラベル値を付け替えるだけで良いので単純に
shard: shard-bに書き換えます
-
注意: Kubernetes自体にはScale制限がある
こうして、Controller自体は水平スケールできることがわかったわけですが、Kubernetesの状態はすべてKubernetes APIを経由して行われるのでKubenetes自体のスケーラビリティも考慮しなくてはなりません。
ただ、残念ながら、Kubernetesは無限にスケールするようには出来ていません。Kubernetes公式ドキュメントのConsiderations for large clusters には、上限値の明記があります。
- No more than 110 pods per node
- No more than 5000 nodes
- No more than 150000 total pods
- No more than 300000 total containers
また、Kubernetesのストレージであるetcd自体、すべての書き込みを直列処理するため、更新はScale-Outしないストレージとなっています6。
となると、せっかくController Scale-Outしても意味ないのでは!?😇と思う方もいるかも知れません。
ControllerをShardingして嬉しい時
Kubernetesクラスタ、特にetcdはScale-Out出来ないわけですが、etcdのScale-Up限界の範囲内で、それ以外のところにボトルネックがある時はShardingが有効な場合があります。上でも書いたとおり、
- 外部のAPI, Database, I/O等に依存していて1回のReconcileに時間がかかる場合
- リソースが多い場合すぐにScale-UpしてもControllerだけが詰まる傾向にあります
- (1回のReconcileが長い場合には並行数を増やしてもまたすぐ詰まってしまう場合が多いと考えられます)
- Reconcile対象リソースのサイズも量も多い場合
- リソースサイズが大きいとReconcile時間が伸びる傾向(Ser/DeSer処理が重い)があり、加えてリソース数も多いとControllerだけが詰まる傾向にあります
まとめ
- Kubernetes Controllerの基本的なアーキテクチャはScale-Upしかできない
- ControllerにShardingを適用したScale-Outなアーキテクチャが提案&検証がされている
- まだForkedなtimebertt/controller-runtime@v0.12.3-sharding-1でのみのサポートなので検証段階ですが今後とても楽しみ
- ただしKubernetes自体のScale Limitには注意が必要
- Reconcile自体に時間がかかるようなControllerの場合は効果ありそう
-
最近は非常に多くのコアを搭載した高性能サーバもあったりするので実際問題あまり問題にならないかもしれませんが。 ↩
-
Namespace間のIsolationが大切な時は良さそう ↩
-
Kubernetes的にはPodもリソースでnode単位にdeployできるPod数の上限があります ↩
-
StatefulSetだとShard名を安定させられますね ↩
-
詳しくはTechFeed Experts Night (25) / Kubernetesオブジェクトのメトリクスを提供する「kube-state-metrics」で使われているシャーディング手法で詳しく解説されているので参照してください。 ↩
-
--etcd-servers-overridesでgroup/resource単位でetcd更新負荷をOffload/分離可 ↩