DeepLearningの力を借りて、マイクラのプレイ中、ゲームに関係のある文章を読み上げてくれるソフトを作った。
↓こんなやつ
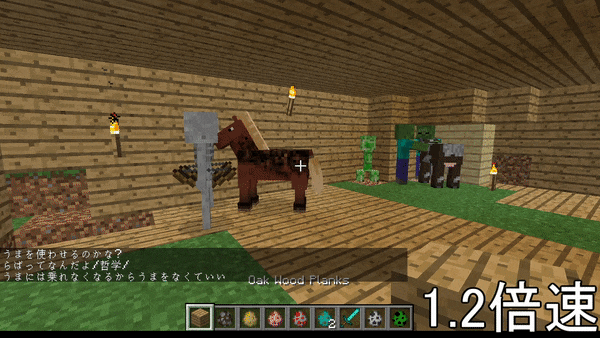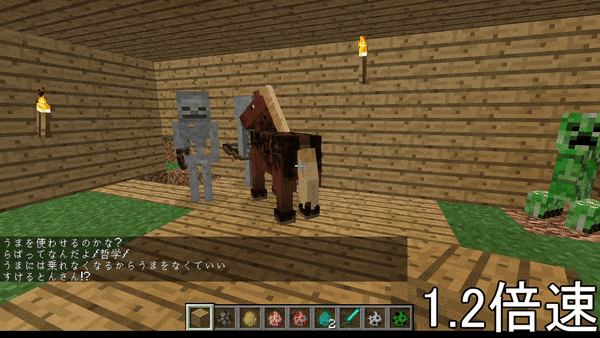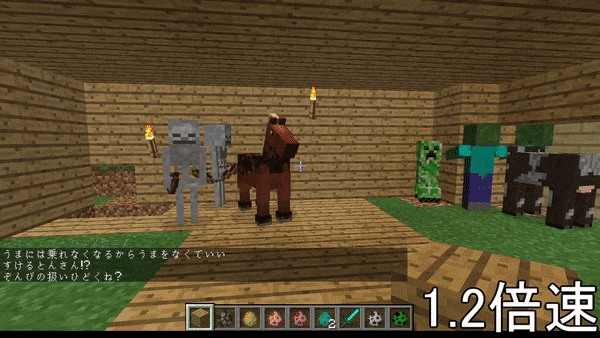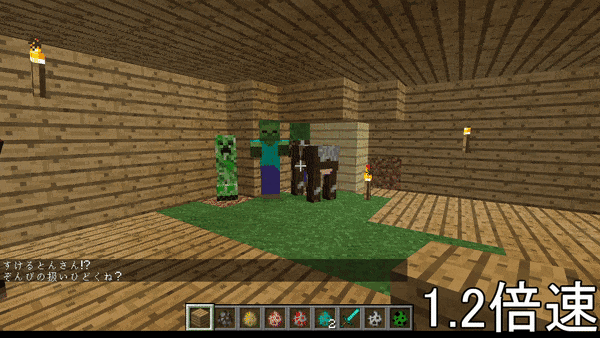
1つの記事にまとめるのが困難なため、いくつかの記事に分けます。
ここでは、DeepLearningする部分について説明します。
↓他の記事
DeepLearning を使っていい感じのテキストを持ってくる。
脳死で BERT を使った。
みんな大好き、huggingfaceのライブラリで楽々実装。
(直接コードについて説明している部分は少ないが 2020/02/28 時点のリポジトリを参照
huggingface のライブラリは結構な頻度で改良されているので、常に最新版を使うことを推奨する)
-
BERT を Masked Language Model で学習。
-
BERT がいい感じに、文章のベクトル表現を学習する。
-
反応して欲しい単語のベクトルと、文章のベクトルの内積からcos類似度を出す。
-
ゾンビや、クリーパーに関連した文章を取り出す。
データの前処理
- 同じ単語が、カタカナとひらがなで別の単語だと認識されると困る。
- 数字やその他記号は区別する必要なし。
-
wだけで構成される単語はすべて草の意味なので同じ単語として扱う。 - 特に、クリーパーについて、匠と表記されることが多い。これも同じ単語として扱う。
とりあえずやったこと
-
jaconvを使って、表現を統一
- カタカナをひらがなに統一
- 全角アルファベットを半角に統一
-
すべての数字を
'0'に置換。 -
?や!以外の記号を/に置換。 -
匠をくりーぱーに置換。- その他、反応して欲しい単語に関して、同義語置換。
[Python] 正規表現の表記方法のまとめ(reモジュール)
語彙ファイル
Deep Learning 系の自然言語処理では、文章を単語に分割して、それぞれの単語にidを振り分けて入力する。
そのために、扱う単語が改行区切りで並んだファイルを用意した。
最初の5つは、BERT に文の区切りを教えたり、後述のマスク用の特殊なトークン。
6つめ以降は、データセットの中の単語を出現頻度順に並べてある。
学習について
本来、BERTは2つのタスクで学習させる。
-
Next Sentence Prediction(NSP)
- 文を2つ並べて入力する。
- 2つ目の文が、1つ目の文の続きの文か判定。
-
Masked Language Model(MLM)
- 入力文の単語を、ランダムにmaskトークンに置換する。
- 穴抜きの文から、元の文を推測する。
ニコニコ動画のコメントは、時系列に並んでいる。
しかし、似たようなコメントが続いたり、時間が空いていたりするので、NSP するのに向いていない。
今回は、MLM だけで学習させた。
MLM では、
全体の15%の単語を置換する。
そのうち、
- 80% を mask トークンに
- 10% をランダムなトークンに
置換し、
- 残り 10% は置換しない。
実装
huggingfaceのライブラリには
- BERT のモデル
- 基本的な学習コード
があるので、データを用意して、データセットクラスを用意すれば動かせる。
データセットクラス
データを読み込んで、必要な形に直して学習コードで取り出せればいい。
-
入力
-
input
それぞれの単語を対応するIDに置き換えたID列
文の最初と最後に特殊トークン
固定長で、長さを合わせるために、0で埋める。
input を穴抜きにする関数に通す
[2, 6, 7, 8, 3, 0, 0, ..., 0] -
mask
処理しなくていい部分を教える
(読み込まない部分を0, 読み込む部分を1)
[0, 1, 1, 1, 0, 0, 0, ..., 0]
-
-
正解データ
input を穴抜きにする関数 の返り値のlabelsを使った。
ハイパラ変更
モデルの設定を変えたいときは、
BertConfigクラスに jsonファイルの path を渡せばいい。
今回、長いテキストを読み込む必要なないので、"max_position_embeddings"を 128 に変更。
それに合わせて、attention の head と隠れ層の数を適当に下げてみた。
{
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 128,
"num_attention_heads": 8,
"num_hidden_layers": 12,
"vocab_size": 47981
}
config = BertConfig.from_json_file("ここに設定を書いた json ファイルの path")
model = BertForMaskedLM(config)
学習コード
ライブラリ付属のサンプルコードを参考に、ごちゃごちゃした部分を削った。
BertForMaskedLMクラスではlabelを渡せば、lossも計算してくれる。
output = model(input_ids=input, attention_mask=mask, masked_lm_labels=labels)
# output = masked_lm_loss, prediction_scores, (hidden_states), (attentions)
類似度をとる
Bert からベクトル表現をとる
学習したモデルを BertModelクラスに読み込む
model = BertModel.from_pretrained("セーブしたモデルのパス")
とりあえずは、BertModelのpooled_outputを使えばいいっぽい。
output = model(input_ids=input, attention_mask=mask)
# output = sequence_output, pooled_output, (hidden_states), (attentions)
あとは、反応して欲しい単語1語だけの文と、実際のテキストデータの文を Bert に入れて、pooled_outputを得る。
hidden_size次元のベクトルが得られるので、いわゆるcos類似度をとる。
あとは、どの単語に近いか判定して、ファイルに分けて保存する。
テキストを出す
実際にマインクラフトで動かしているときは、あらかじめ保存した類似度で文章を選ぶ。
類似度の高い方から、8つ取り出して、その中からランダムに1つ選んで表示した。
生成させてみる
ctrl での文書生成も試した。
デモ動画は文書生成をしている。
(ctrl なのは、文書スタイルを変更できるらしかったから
~~めんどくさかったので、~~結局ただのTransformerのDecorder的に使った)
学習
実装はもちろん huggingface。
- テキストデータを入れて、文のそれぞれの時点で、次の単語を予測させる。
- labels 引数に input と同じものを入れると、内部で左に1つずらしてlossを出してくれる。
model = CTRLLMHeadModel(config)
output = model(input_ids=input, attention_mask=mask, labels=input)
# outputs = loss, lm_logits, presents, (all hidden_states), (attentions)
実際に生成
学習させた後は、generate 関数を使えば簡単に生成をしてくれる。
今回は、類似度順に取り出した文の先頭の単語だけ渡して、残りを生成させた。
- generate に渡す input は 0埋めしない。
- max_length 個だけ 単語IDが並んだものが返ってくるので、文の終わりを示すトークンまで切る。
- ID列を単語に置換し直す。
output = model.generate(input_ids=input, max_length=128)
最後に
Transformer は huggingface のライブラリを使えば脳死で使えた。
便利すぎて自分でモデルの実装をしなくなるので、Transformer分からんになりやすいので注意。
データの形など分からなくなったら、こちらの記事が分かりやすかった。