DeepLearningの力を借りて、マイクラのプレイ中、ゲームに関係のある文章を読み上げてくれるソフトを作った。
↓こんなやつ
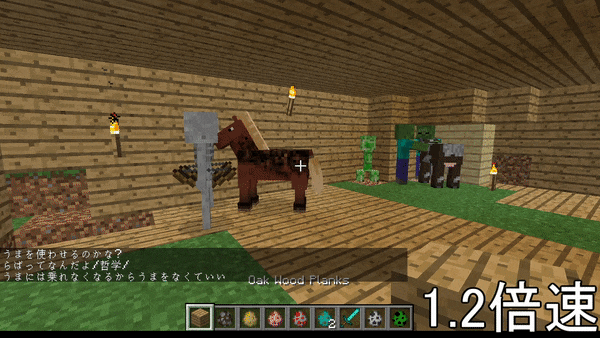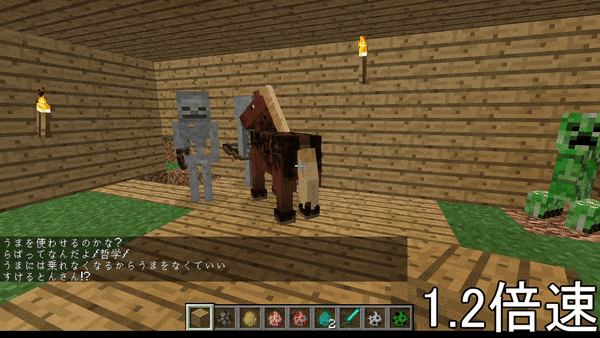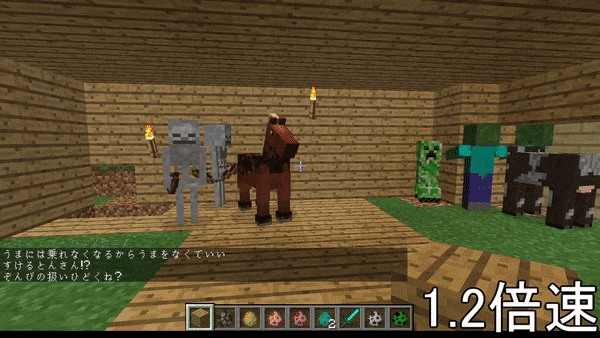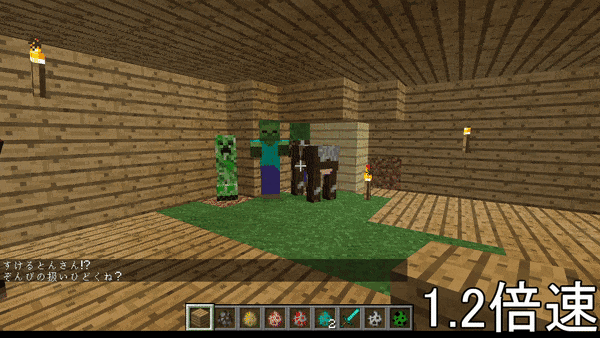
1つの記事にまとめるのが困難なため、いくつかの記事に分けます。
ここでは、データを用意する部分について説明します。
↓他の記事
欲しいデータ
ゲーム中に表示・読み上げされると嬉しいテキスト。
ゲーム内のオブジェクト(ゾンビ、クリーパー、等など)に関連したテキスト。
スクレイピング
サイトにあたりをつける
まずは、Google先生に聞いてみる。
Google検索で、「ゾンビ マインクラフト」など調べる。
検索結果の上位サイトのテキストを集めれば良さそう。
ついでに、検索結果の下に出る、関連ワードでも検索。
↓を使えばいい感じに出来た。
【Python】Googleの検索結果をアクセス制限なしで取得する
サイトのテキストをダウンロード
取得したいwebサイトのURLを入手したので、
みんな大好きSeleniumにて、じゃんじゃか取得。
しかし、アクセスするURLの中身をきちんと確認したわけではない。
読み込み時にエラーが起きるとプログラムが止まってしまう。
それ以外は、とりあえず飛ばす!!
そして、html をじゃんじゃか保存。
それから、BeautifulSoup など使って html からテキストを取り出す。
文字の先頭が日本語でも【】でもないやつは捨てた。
消せなかったタグとか日付等を消したかった。
ニコニココメントデータセット
こちらで配布されている、データセット。
ニコニコのコメントが10年分くらいまとまっている。
コメントだけでなく、名前・タグ・説明文などのメタデータもついてくる。
やったぜ! 早速解凍して......
終わらない解凍処理。本当に終わらない。
ファイル数がとにかく多い。これは待てない。
いや、待てよ。
使いたいデータはマイクラに関係ありそうなコメントだけだ。
メタデータのタグを見て、マイクラ関連の動画のコメントだけ解凍 or 解凍せずに処理できないか?
zipfileを使えば出来た。
ちょっと加工
ニコニコデータセットのおかげもあって、大量にデータが手に入った!!
とりま、単語分割
GiNZA を使った。
↓こんな感じで単語分割できる。
import spacy
nlp = spacy.load('ja_ginza')
with open(path, mode='r', encodeing='utf-8', errors='ignore'):
text = list(f.read().split('\n'))
docs = nlp.pipe(text, disable=['ner'])
for doc in docs:
for sent in doc.sents:
for word in sent:
# hogehoge
nlp.pipe()のdisableでいらない機能を停止できる。
学習に不要なゴミを取り除く
- 語数が3単語以下の文を削除
- 正規表現で日本語(
r'[あ-んア-ン一-鿐]')を含む単語が1個の文を削除 - set を使って、同じ単語だけの文を削除
- 漢字のみ・ひらがなのみ、の文章も正規表現で削除
[Python] 正規表現の表記方法のまとめ(reモジュール)
まとめ
データ集めは大変。
使えるデータにするために、色々工夫できそう。
余談
テキストアドベンチャーのまとめサイトを学習させた、AI Dungeon 2 なるものがある。
自動で物語を生成しながら遊べて、すごい。
日本語で、スクレイピングできるテキストアドベンチャーサイトないかなぁ。