こちらの記事は、Microsoft Azure Tech Advent Calender 2018 の企画に基づき、執筆した内容となります。
はじめに
なぜこのテーマにしたか。
Azure Databricks をテーマにしたのは、日本語の解説ページが少ないな、と思ったからです。
こちらの記事を始めに Azure Databricks 関連の記事を徐々に増やしていければと思っておりますが、今回の記事は Azure Databricks ってそもそも何? という方を対象に記述します。
Azure Databricks って何?
Azure Databricks はデータ サイエンティスト、データ エンジニア、ビジネス アナリストのコラボレーションを可能とする、分析プラットフォームとなります。
SCALA, Python, SQL, R を利用したデータ分析ができるだけでなく、他のデータベース製品からデータを読み取り、更に解析したデータをデータベースに書き出したり、BI ツールと連携して表示したりすることができます。
言葉で書いてもしっくりこないので、簡単なシナリオを実装してみましょう!
実施したいこと
Microsoft SQL Server に保存しているデータを、Azure Databricks 上で読込むまでのシナリオを試します。
注意事項
・ Microsoft SQL Server 2008 以上を利用している必要があります。
・ Microsoft SQL Server にインターネットからリモート接続できるように構成ください。
※ SQL Server が Azure VM 上にある場合には、こちらのドキュメント が参考になります。
実際にやってみましょう!
以下の手順を実施するのにあたり、推奨ブラウザは Chrome / Firefox となります。
1. Azure Databricks を立ち上げます
-
Azure のポータル画面から [リソースの作成] を選択します。
-
検索バーにて "Azure Databricks" と入力し、検索結果が表示されましたらアイコンをクリックし、[作成] ボタンをクリックします。
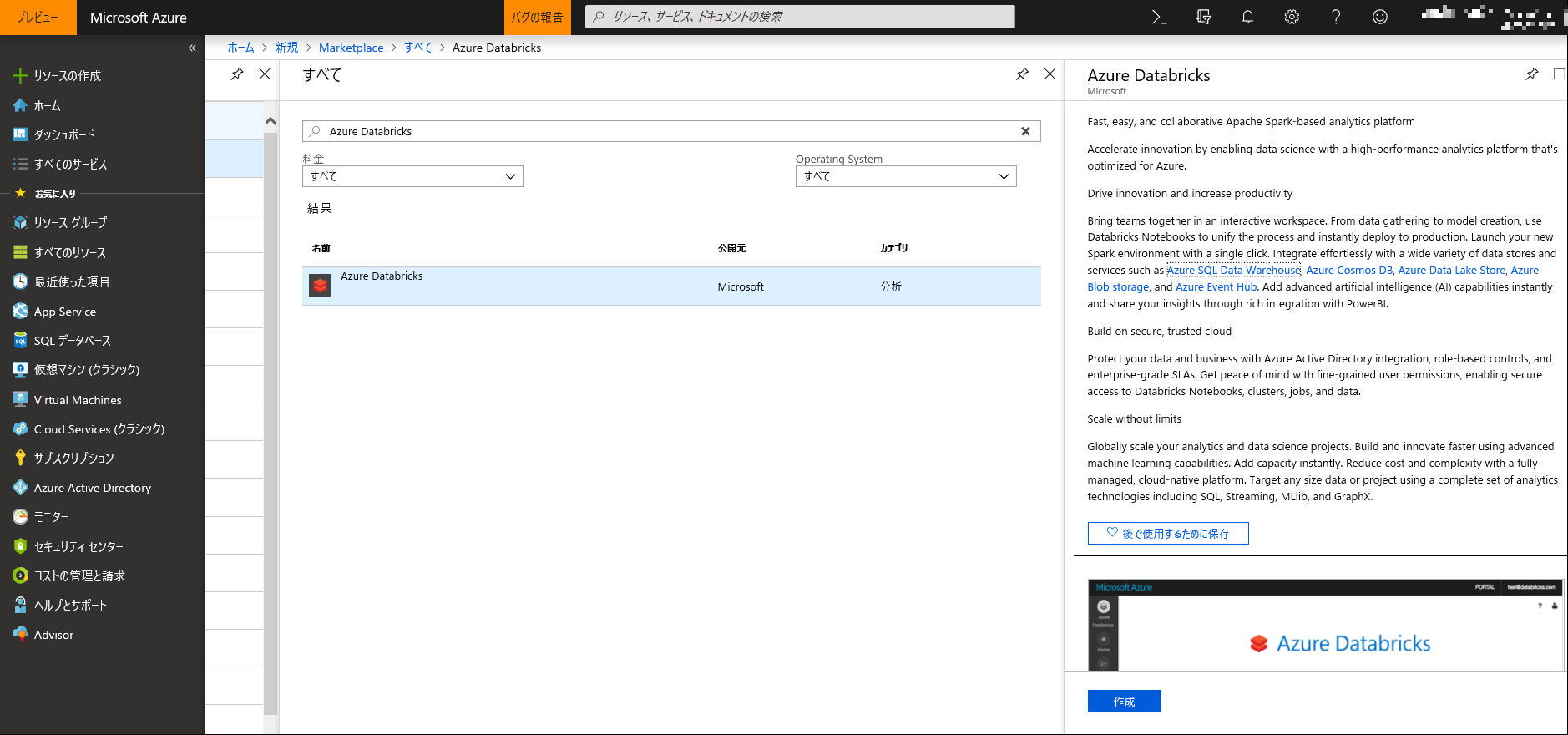
-
必要事項を入力し、[作成] ボタンをクリックします。
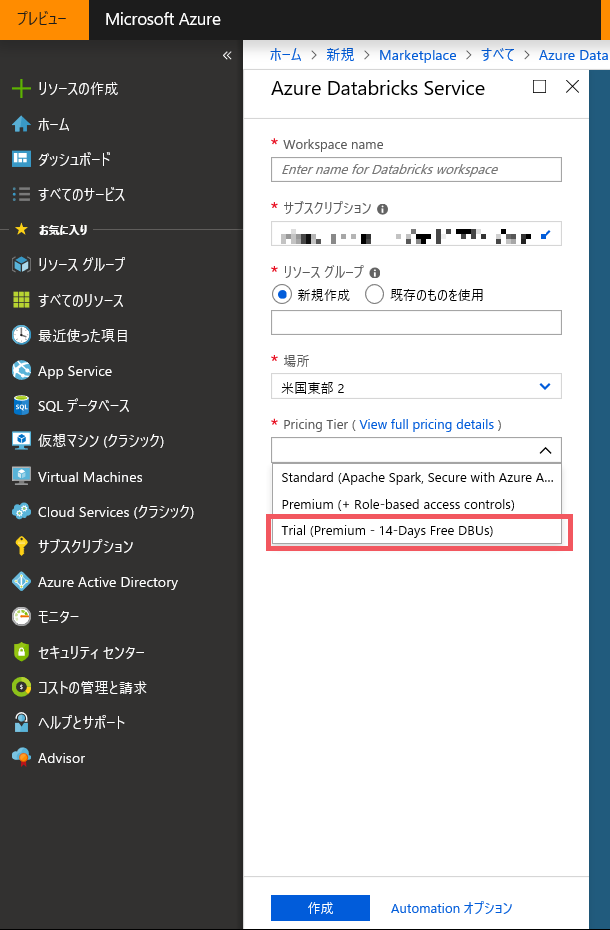
※ Pricing Tier では14 日間トライアルの "Trial (Premium - 14 Days Free DBUs)" を選択します。 -
デプロイが完了したことを知らせる通知が確認できましたら、[Go to resource] からリソースへアクセスします。
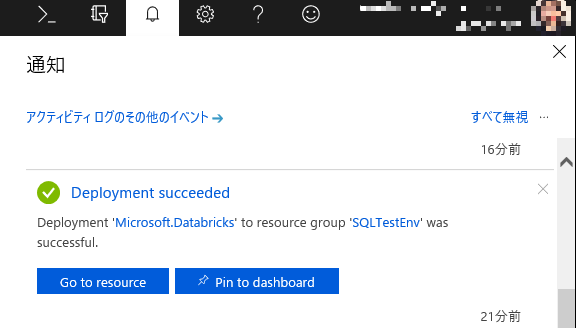
-
[Launch Workspace] をクリックし、Azure Databricks を立ち上げます。
※ IE や Edge で上手く立ち上がらない場合には Chrome をお使いください。
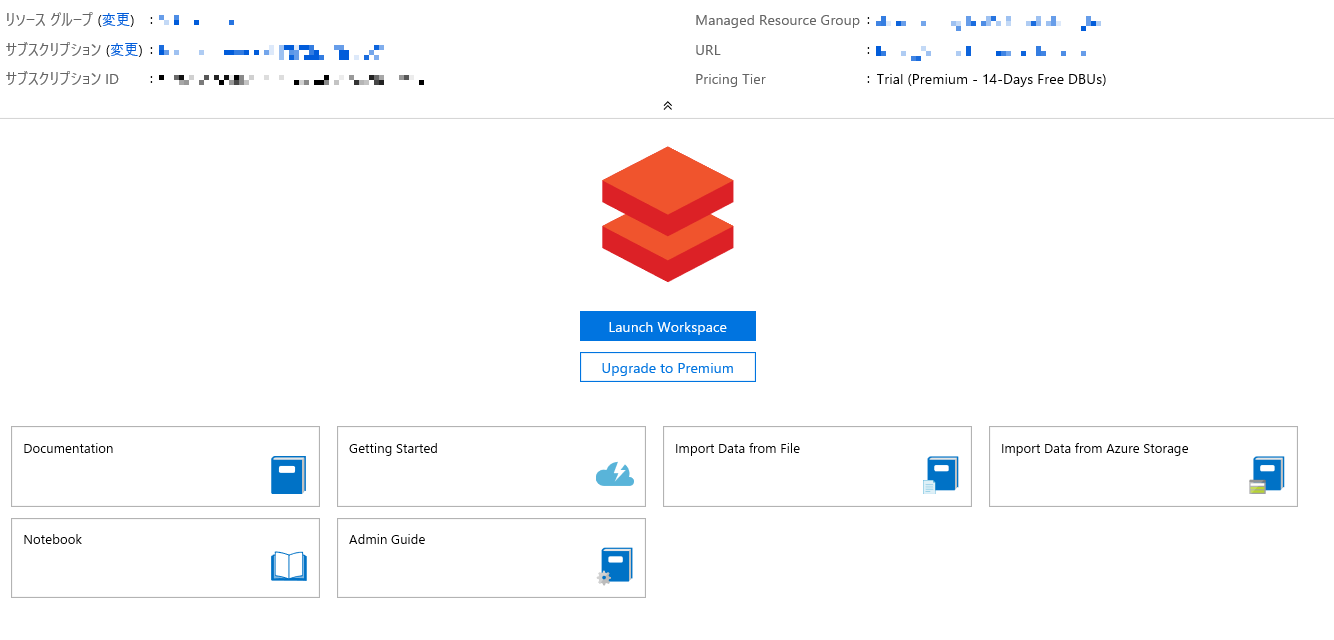
-
Azure Databricks の立ち上がりましたら、[New Cluster] をクリックし、クラスタを作成します。
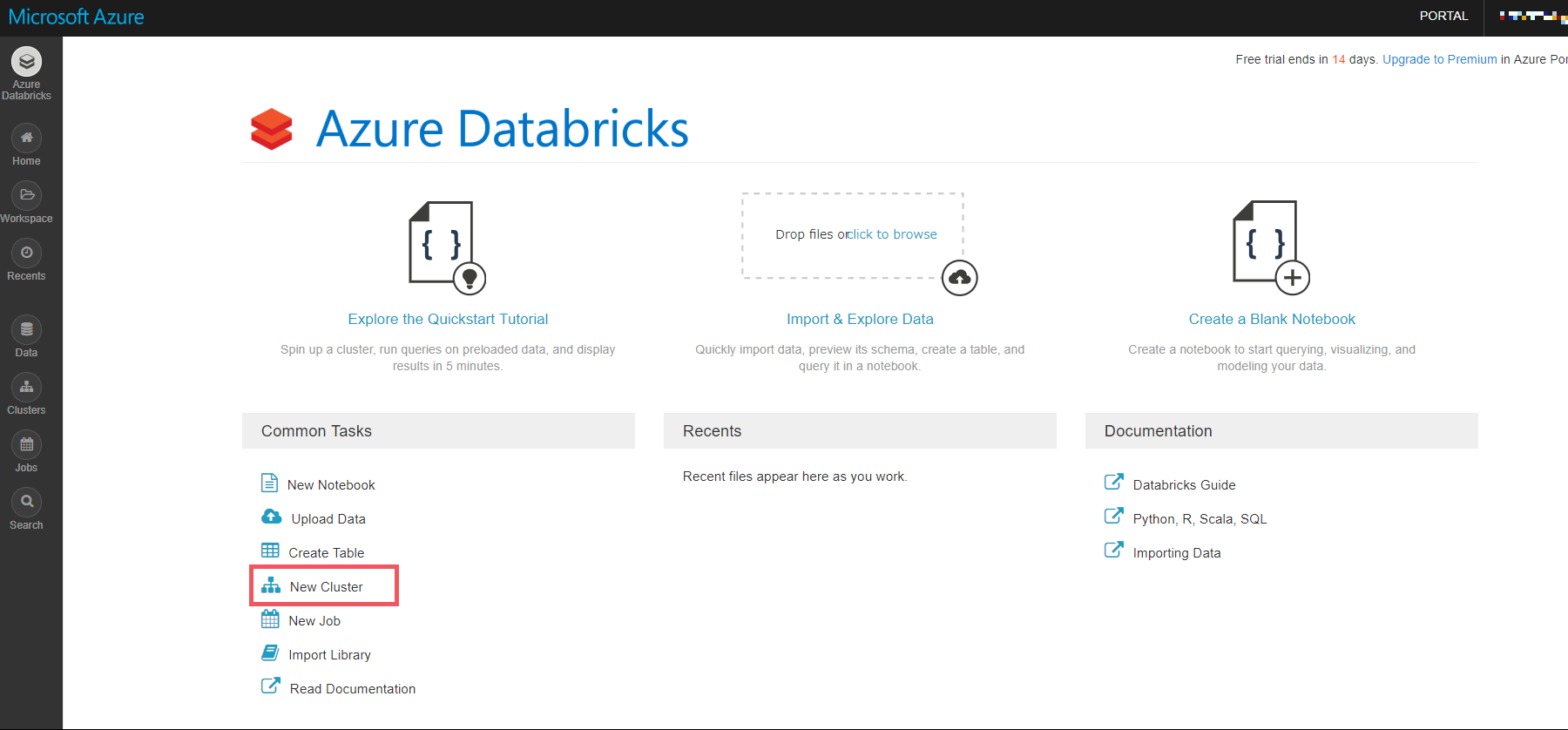
-
New Cluster の画面にて詳細を入力し、[Create Cluster] をクリックします。
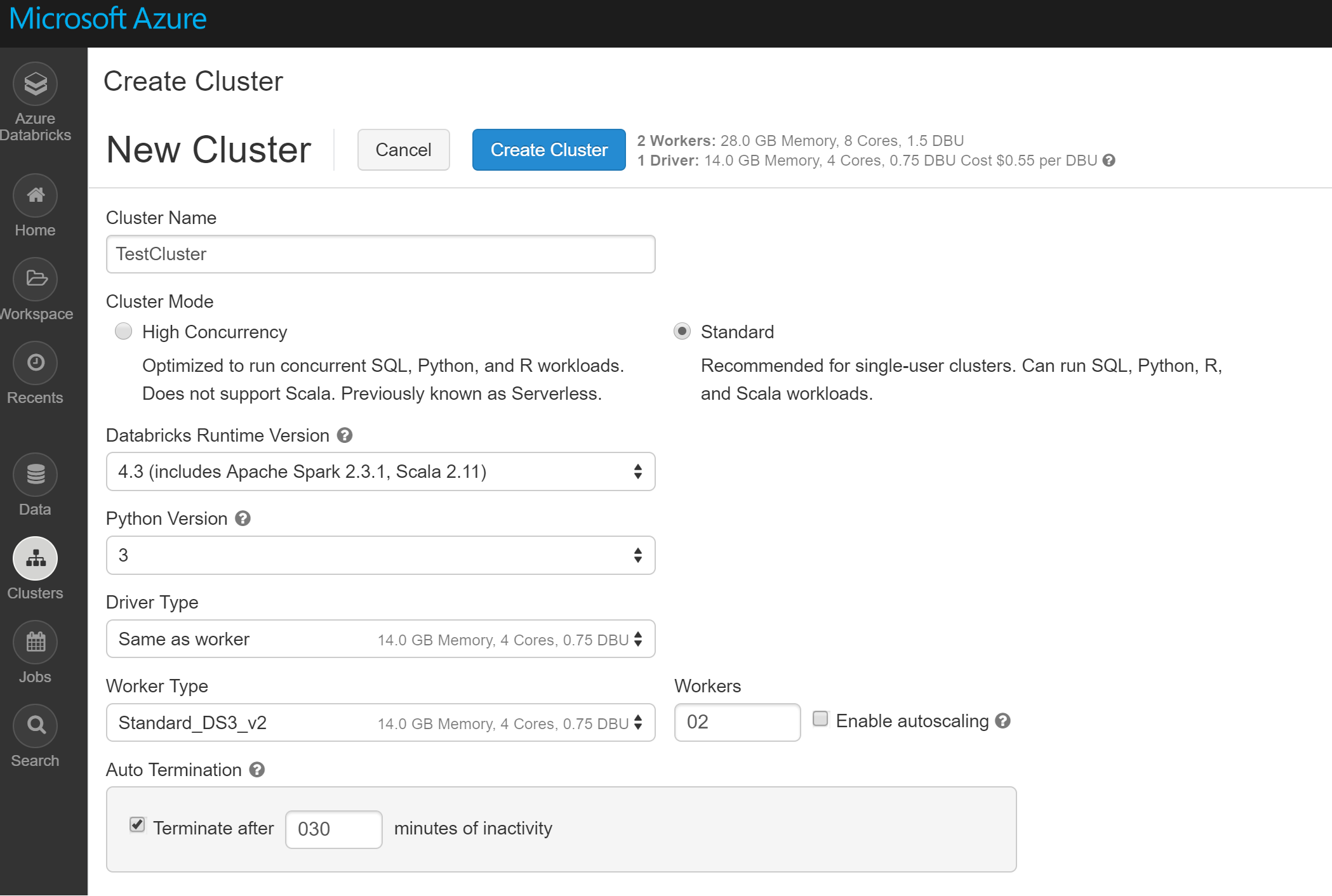
-
Clusters の画面の Interactive Cluster の画面で、作成した Cluster の Status が Running になっていたら完成です。
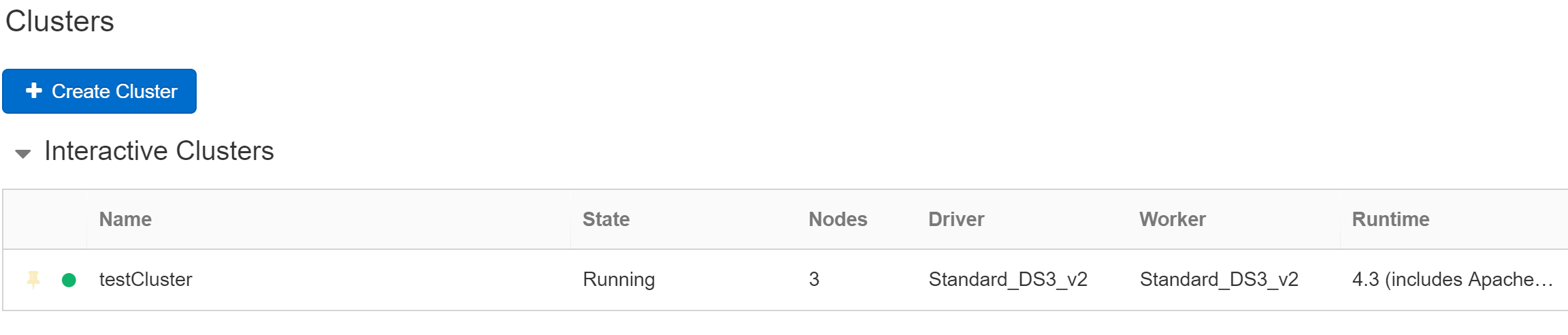
2. SQL Server に接続するためのライブラリをインポートします
SQL Server に接続する方法として JDBC を使う方法と、Spark Connector を使う方法があります。
より高いパフォーマンスがでる Spark Connector を利用して接続する方法をご紹介します。
For improved performance, you can instead use the Spark connector to connect to Microsoft SQL Server and Azure SQL Database.
-
Azure Databricks のホーム画面にて、 [Import Library] を選択します。
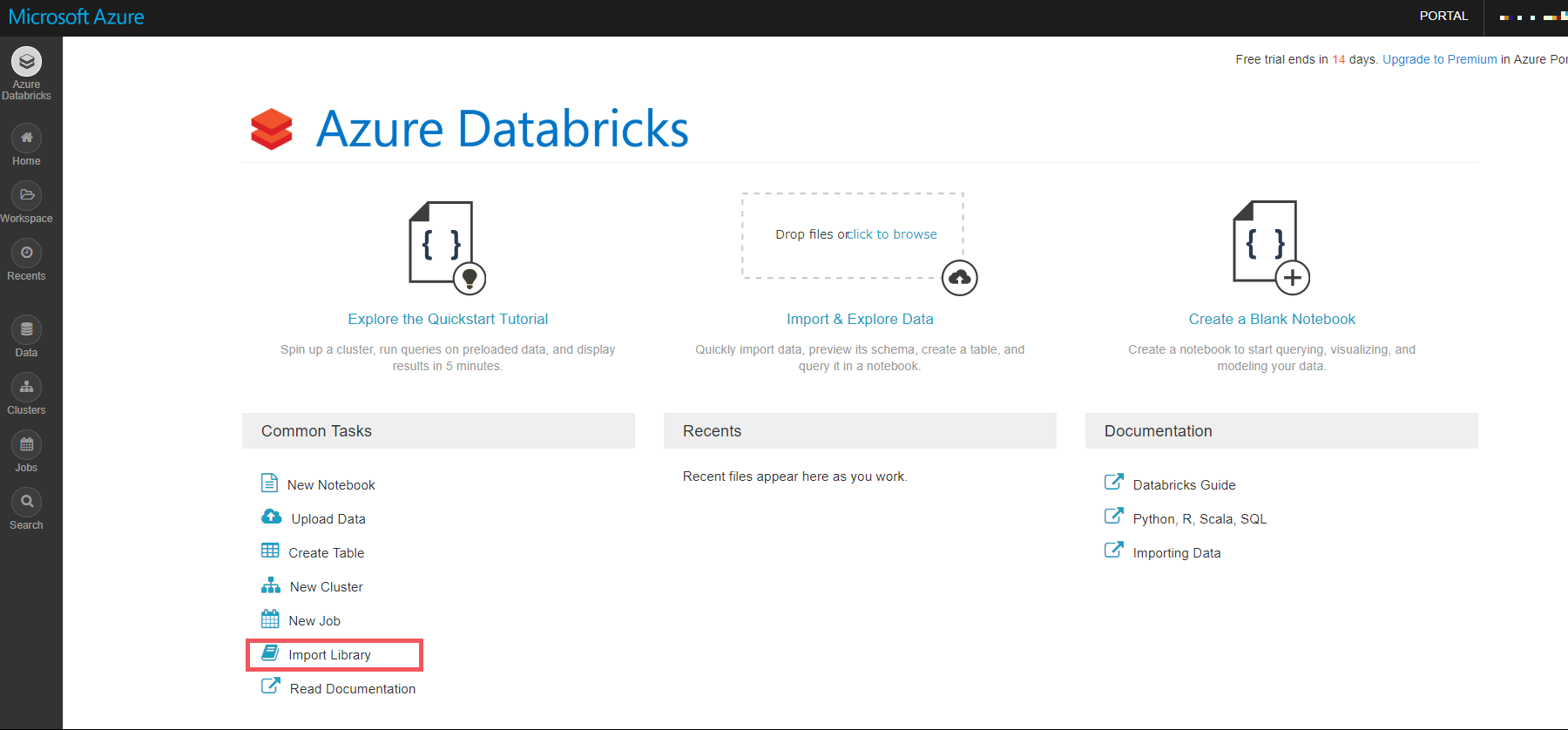
-
ライブラリの新規作成画面にて、Source について "Maven Coordinate" を選択し 、 Coordinate の項目は"com.microsoft.azure:azure-sqldb-spark:1.0.2" と入力し、 [Create Library] をクリックします。
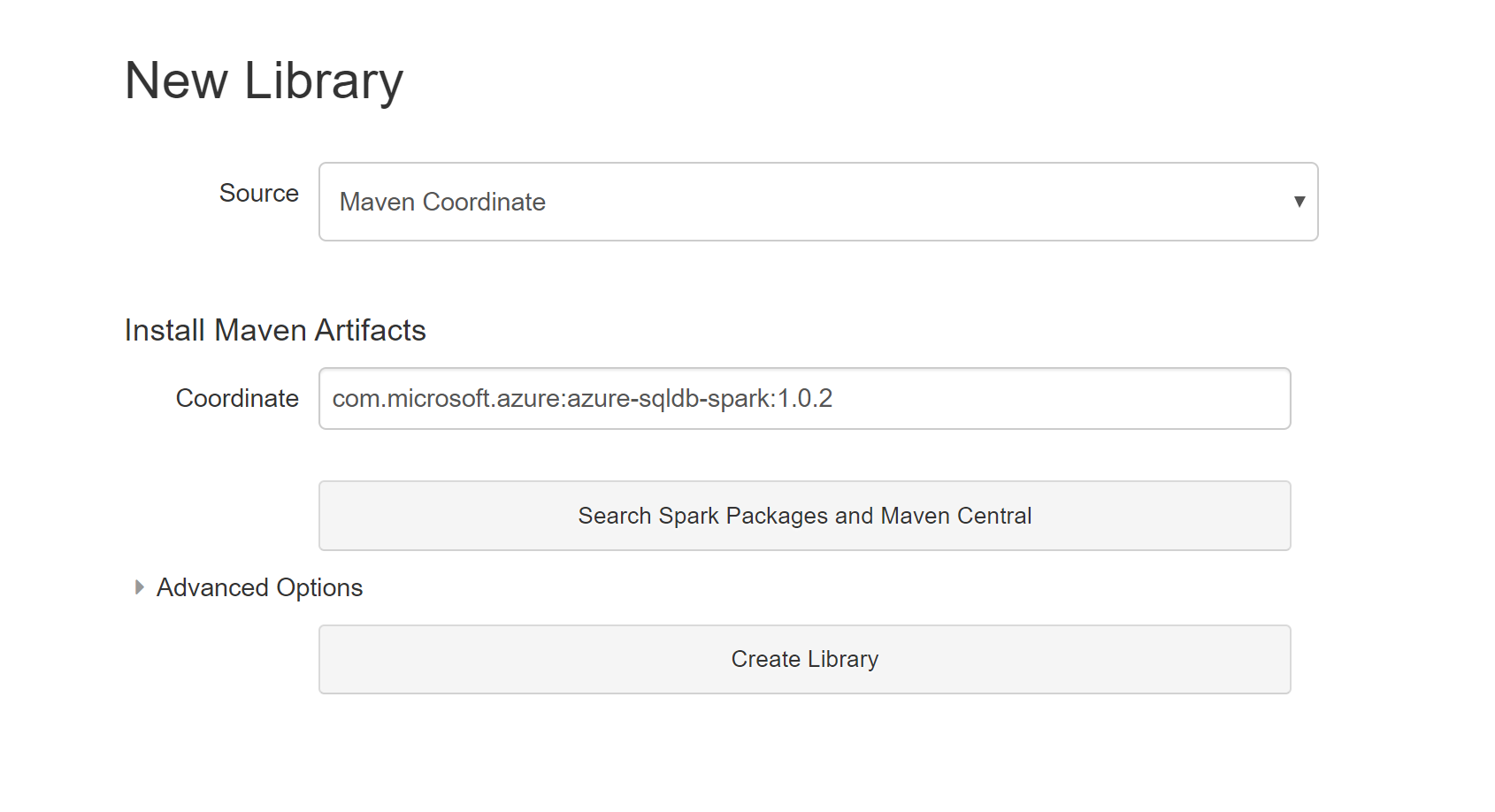
-
ライブラリが作成できましたら、Status on running clusters の項目にて、該当のクラスタにチェックを入れ、アタッチします。
※ 作成したライブラリには、ブラウザ画面左の Workspace から辿ることができます
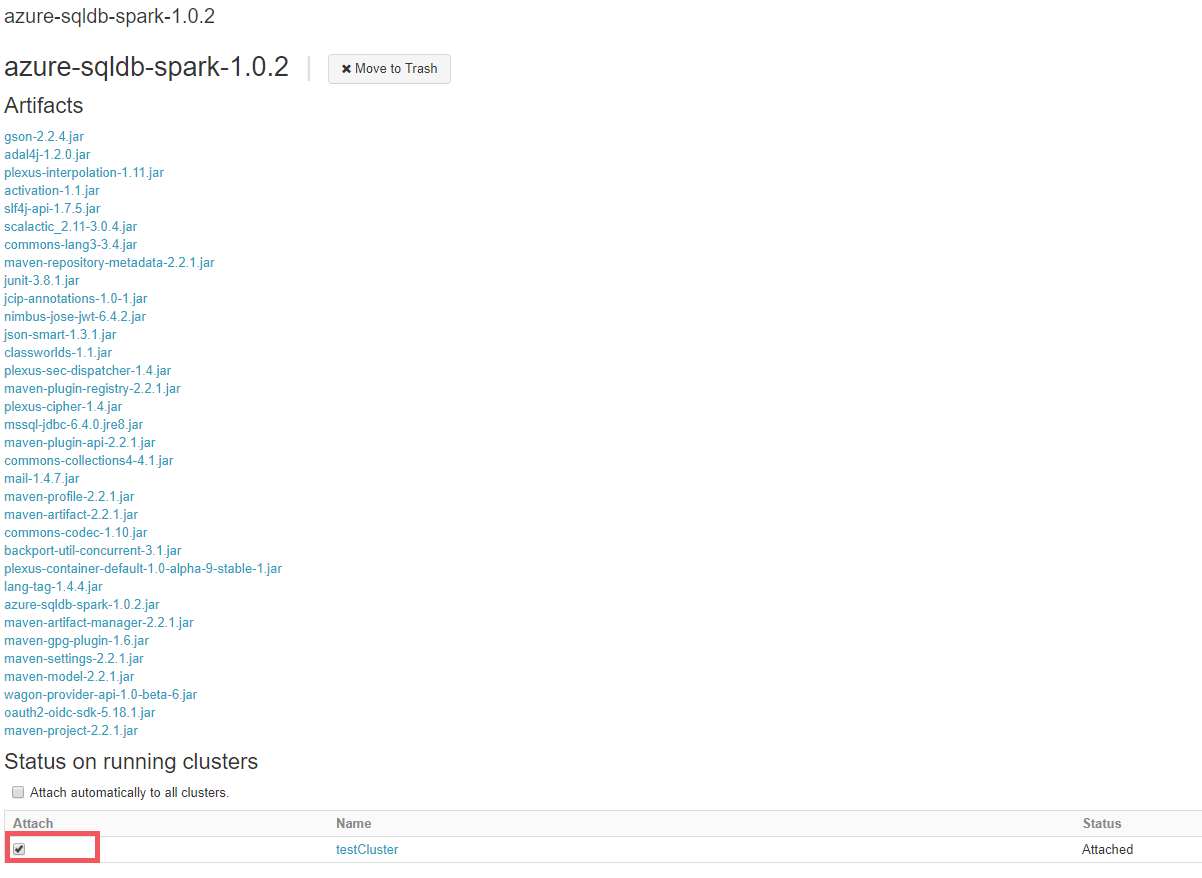
-
クラスタの画面に移動し、クラスタを再起動します。
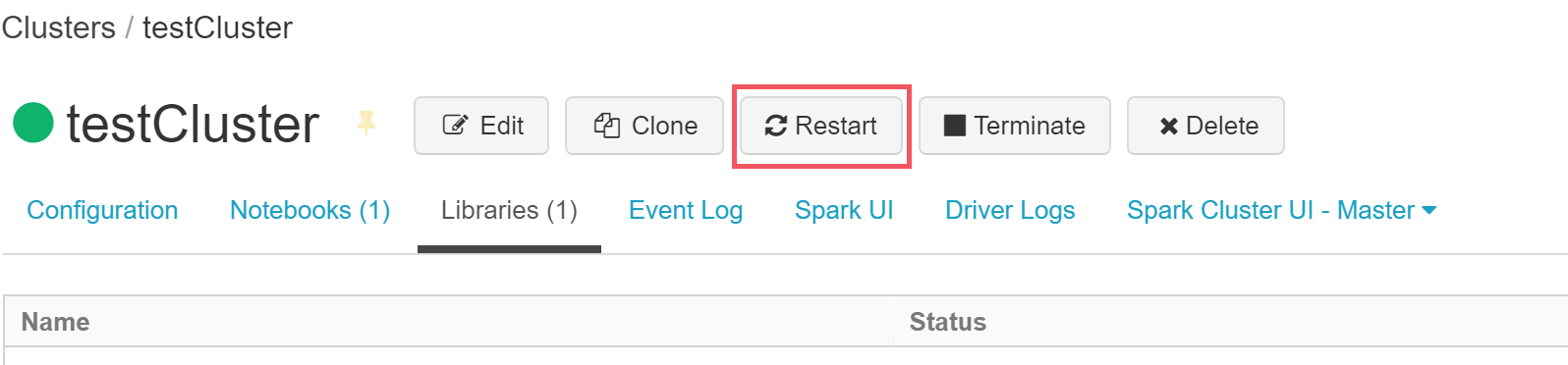
上記手順後に、Microsoft SQL Server に接続するためのライブラリがクラスタに設定されます。
次は からコネクタを利用して SQL Server のデータベースの中身を取得します。
3. Spark コネクタを利用して Microsoft SQL Server に繋ぎます
-
Azure Databricks のポータル画面に、New Notebook をクリックします。
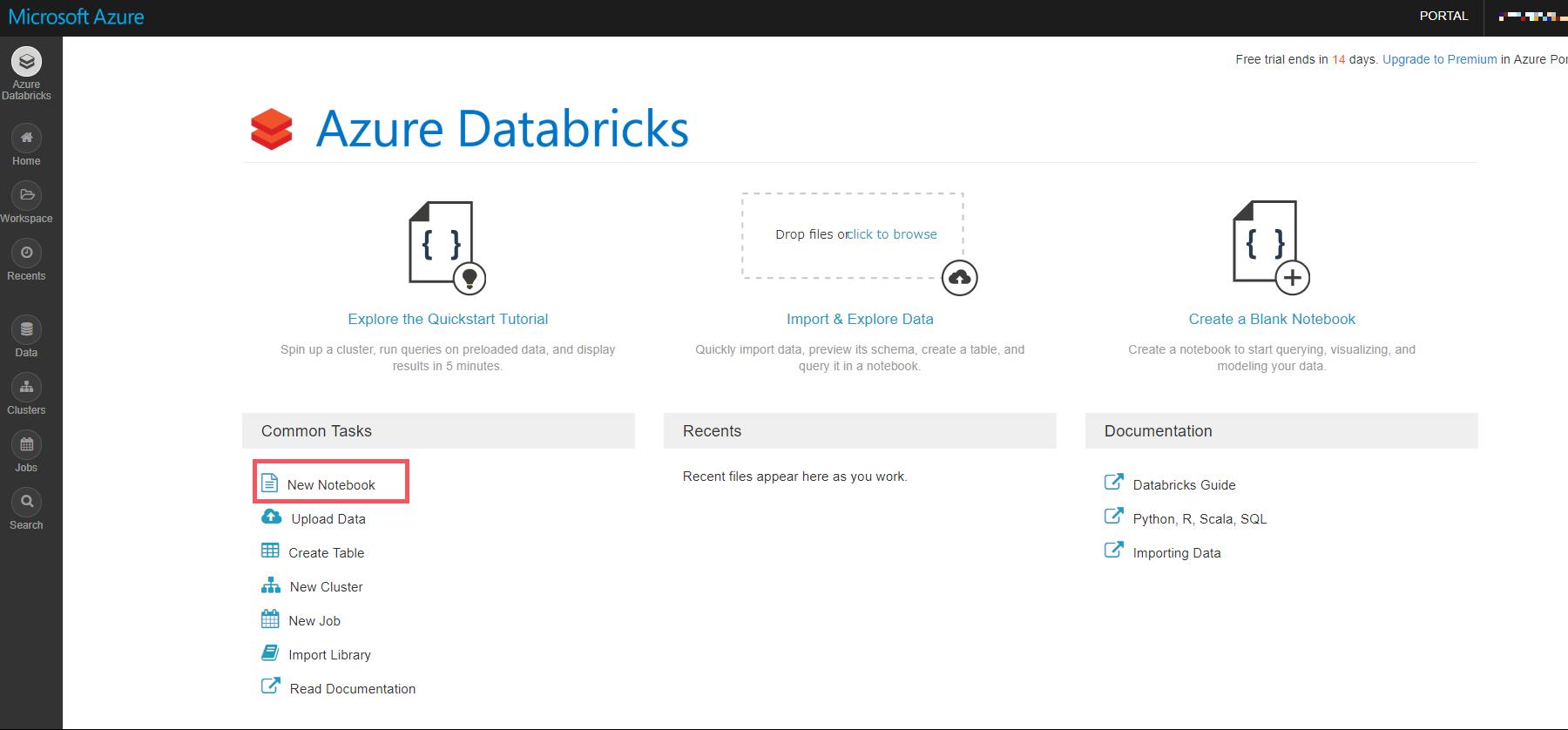
-
Create Notebook の画面にて任意のファイル名を入力し、Language に利用したい言語を選択し、[Create] を実行します。
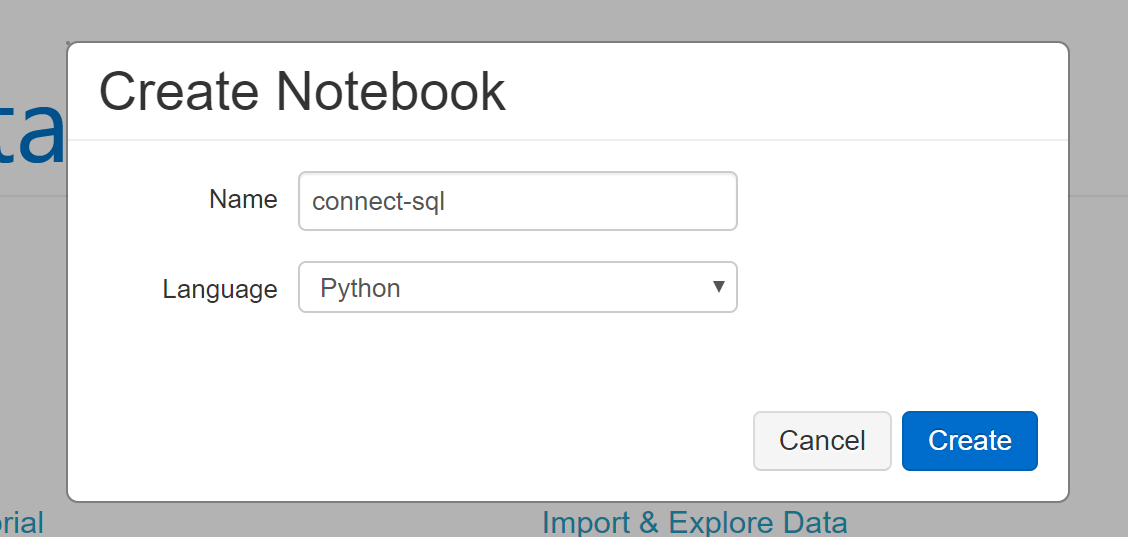
-
Notebook が作成されましたら、画面上部の Detached から作成したクラスタを選択し、Notebook にクラスタをアタッチします。
※ クラスタが起動していない場合 (クラスタ名の横の○アイコンの色がグレーの場合) はコードを実行することができません。
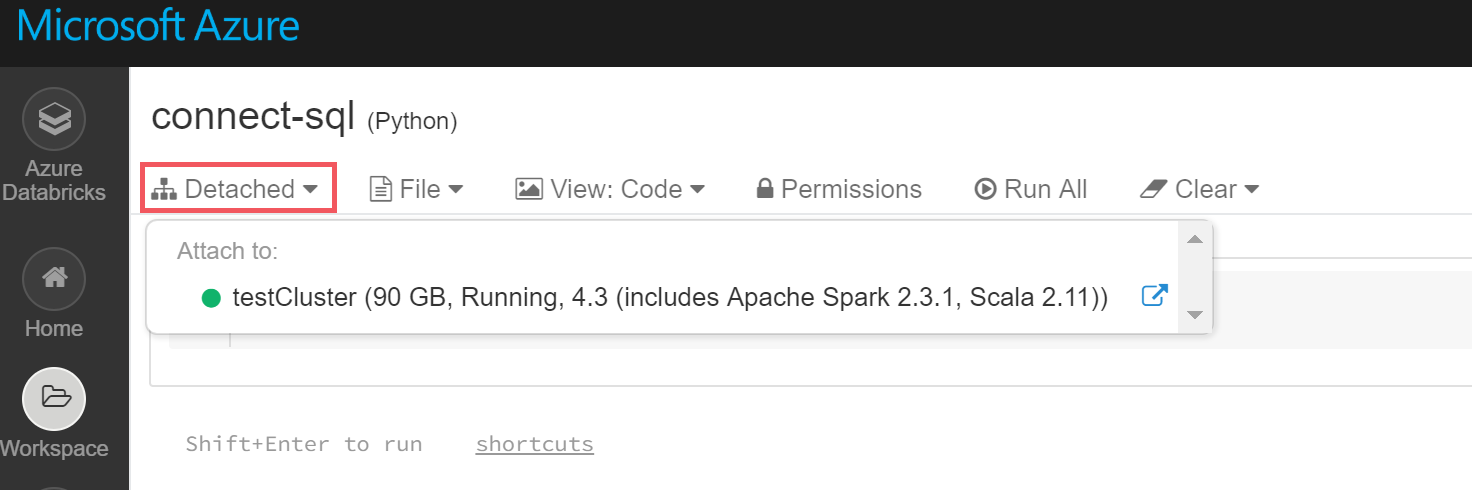
-
Notebook のセルに以下の内容を入力し、[Ctrl + Enter] キーで実行します。
%scala
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "<データベース名>",
"dbTable" -> "<スキーマ名.テーブル名>"
"user" -> "<SQL Server 認証時のユーザー名>",
"password" -> "<SQL Server 認証時のパスワード>",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = spark.read.sqlDB(config)
collection.show()
※ 上記スクリプトの <日本語記述> について、お使いの環境に合わせてご変更ください。
※ %language(小文字) と記述することで、Notebook の既定言語以外のコードを実行できます。
(実行環境の言語が SCALA の場合には、1行目の "%scala" は不要です。)
5.コードの実行が成功すると次のように、スクリプト内で指定したテーブルが表示されます。
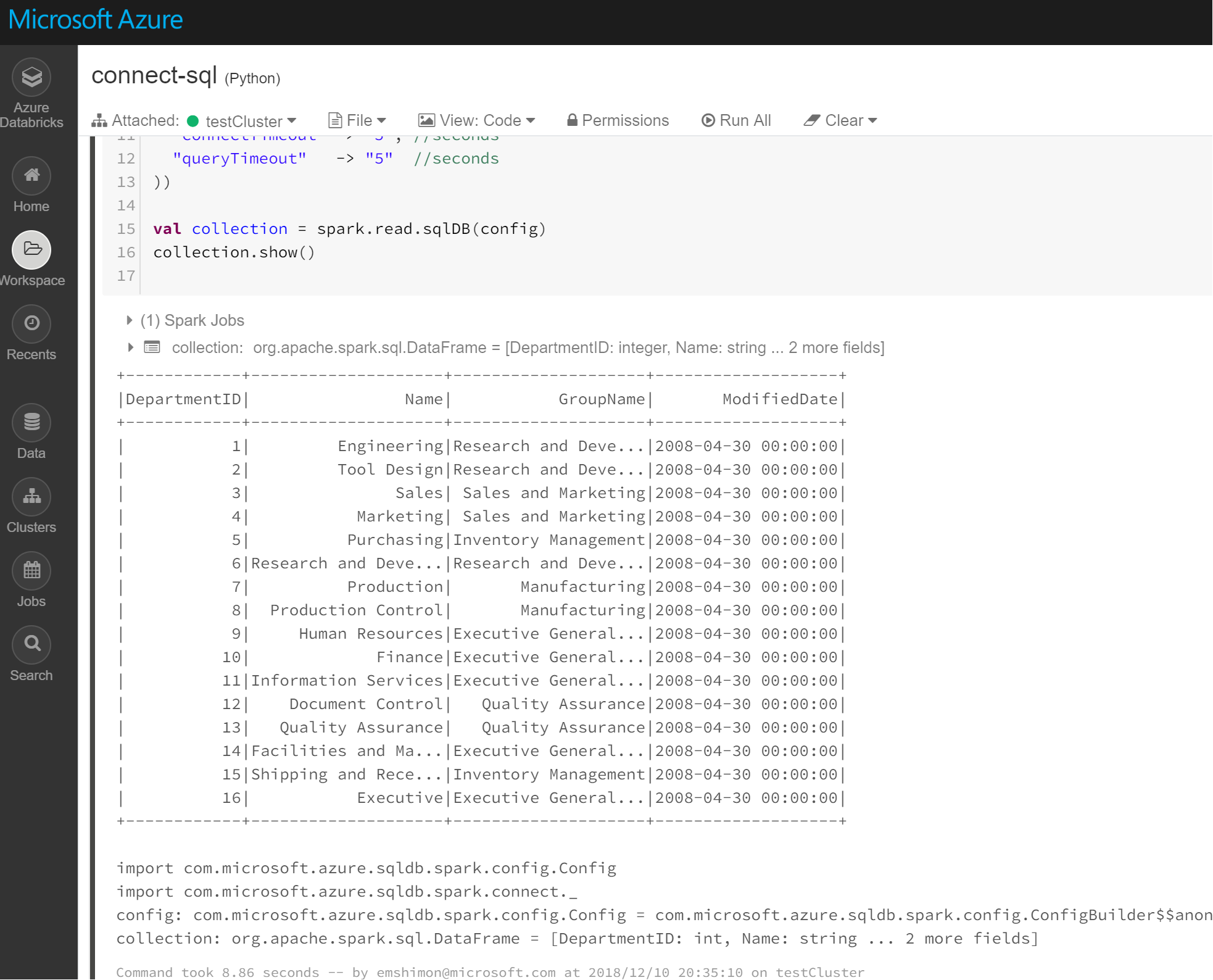
※ この例では AdventureWorks2017 内のテーブルを呼び出しています。
※ AdventureWorks2017 のサンプルデータはGitHubのページから入手できます。
Scala 以外で操作したい場合には、Azure Databricks 内のデータベースに格納しないと操作できないので、一旦テーブルに保存します。
%scala
collection.write.saveAsTable("Department")
※ 上記スクリプトでは Department というテーブルでデータを保存しました。
6.次のような形で Department テーブルのデータを呼び出すことができます。
SQLの場合
%sql
SELECT * FROM Department
Python の場合
departments = spark.table("Department")
display(departments.select("*"))
departments = spark.sql("select * from Department")
display(departments.select("*"))
他の言語はこちらのドキュメントを参照ください。
最後に
上記作業が完了しましたら、クラスタを停止しましょう。
そのためには、Azure Databricks ワークスペースの左側のウィンドウで、[クラスター] を選択し、クラスタの [アクション] 列の下にある[終了] アイコンを選択します。
なお、クラスター作成時に Auto Termination を有効にしている場合には、非アクティブな状態がフォームで指定した時間経過した場合に、自動で停止します。
(スクリーンショットと同じ手順で作成いただいた場合には、Auto Termination が有効になっています。)
まとめ
Microsoft SQL Server に Spark Connector を利用して、データをAzure Databricks に読み込むことができました。
また、読み込んだデータをデーターベース上に置くことで、色々な言語で参照したりすることもできることがを確認できました。
次回は、実際にデータを加工し、加工後のデータをBI ツールなどで表示するための手順についてご紹介いたします!
参考資料
本ブログを執筆するのにあたり、以下の情報を参照しました。
Azure Databricks のドキュメント
https://docs.microsoft.com/ja-jp/azure/azure-databricks/
※ ステップ バイ ステップのチュートリアルは分かりやすいです!
Azure Databricks の公式ドキュメント (英語資料)
https://docs.azuredatabricks.net/index.html
※ 困ったらこちらのサイトで検索すると答えがでてきます。
Azure Databricks を使ってみよう
https://blogs.msdn.microsoft.com/dataplatjp/2018/06/19/azure-databricks/
※ 日本マイクロソフト Data Platform Tech Sales チームで作成している Azure Databricks に関する紹介ブログです。
Azure での SQL Server 仮想マシンへの接続
https://docs.microsoft.com/ja-jp/azure/virtual-machines/windows/sql/virtual-machines-windows-sql-connect
※ SQL Server にインターネット経由で接続する方法が紹介されています。