はじめに
以前、不均衡データの補正方法としてのオーバーサンプリングの手法から以下の4つを紹介しました1。今回は MATLAB で実装してみたのでご紹介。
- SMOTE (Chawla, NV. et al. 2002)2
- Borderline SMOTE (Han, H. et al. 2005)3
- ADASYN (He, H. et al. 2008)4
- Safe-level SMOTE (Bunkhumpornpat, C. at al. 2009)5
コードはこちらから -> Github: Oversampling for Imbalanced Data
本記事で紹介するのは Github に置いてある example.mlx の内容なので、もし自分で結果を再現したい場合は活用ください。実行結果を見るだけであれば example.pdf もどうぞ。
環境
MATLAB R2019b6
Statistics and Machine Learning Toolbox7
本記事のポイント
ポイント 1.
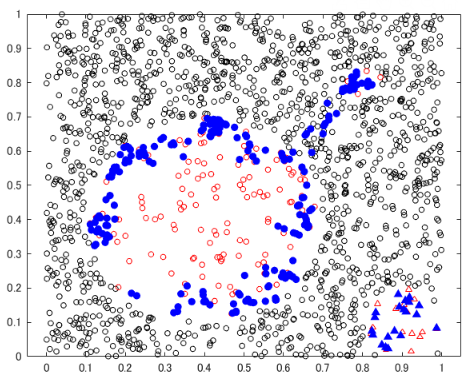
どの手法が良いのかは結局データ次第・・予測精度の比較に触れる前に、どんなデータが実際に出来上がるのかを可視化するヒントになれば嬉しいです。以下は Borderline-SMOTE の結果例。あまり嬉しくない領域にもデータが生成されています。
ポイント 2.
Github に挙げたコードでは、少し色気を出して入力パラメーターの候補を表示したり補完したりする機能もつけてみました。
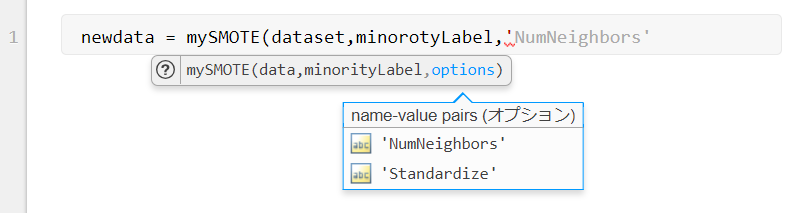
MATLAB R2019b から、Function Argument Validation で自作の関数にも簡単に導入できるようになりました。
参考:MATLAB公式ブログ:入力引数の検証~隠された便利機能
関数仕様
コードはこちらから:https://github.com/minoue-xx/oversampling4ImbalancedData
例えば SMOTE であれば以下のように実行します。
[newdata,visdata] = mySMOTE(dataset,minorityLabel,num2Add,...
"NumNeighbors",k, "Standardize", true);
入力引数
- dataset: table 型で定義されたもともとのデータ(2つ以上のクラス対応可)
- minorityLabel: オーバーサンプリングするラベル名
- num2Add: 何個新しいデータを作るか
- NumNeighbors: (オプション)参照する近傍数 (default: k = 5)
- Standardize: (オプション)近傍検出の際に各変数を正規化した距離尺度を使うかどうか (default: false)
出力引数
- newdata: minorityLabel の新しいデータ
- visdata: (オプション)可視化(デバッグ)用データ
ADASYN、BorderlineSMOTE、SafeLevelSMOTE でも同じです。
検証用データ
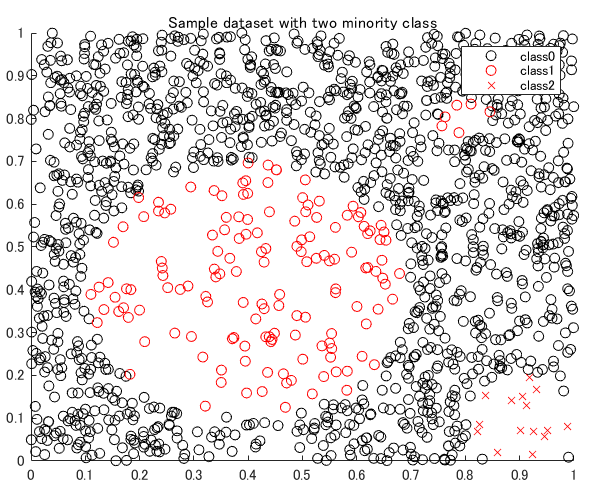
今回は Borderline SMOTE (Han, H. et al. 2005)3 をマネしたデータにしてみました。class 0 が majority class(多数派)、minority(少数派)class として class 1/class 2 の 2 種類用意してみました。class 1 が飛び地になっていて、ここがどう処理されるかが気になります。
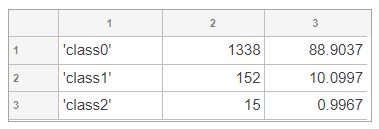
データ点数も 1338個 vs 152個 vs 15個 と良い感じに imbalanced です。
検証用データ作成コード
Ndata = 2000;
data = rand(Ndata,2);
x = data(:,1);
y = data(:,2);
Define the two minority class in three circles.
% center = (0.4,0.4), radius = 0.3
idx1a = (x-0.4).^2 + (y-0.4).^2 < 0.3^2;
% center = (0.8,0.8), radius = 0.05
idx1b = (x-0.8).^2 + (y-0.8).^2 < 0.05^2;
% center = (0.9,0.1), radius = 0.1
idx2 = (x-0.9).^2 + (y-0.1).^2 < 0.1^2;
% decrease the number of samples for two minority class
undersampleRate = 4; % Undersample rate
data1 = data(idx1a|idx1b,:);
data1 = data1(1:undersampleRate:end,:);
data2 = data(idx2,:);
data2 = data2(1:undersampleRate:end,:);
% delete those from the original datset
data(idx1a|idx1b|idx2,:) = [];
% plot
figure(1)
scatter(data(:,1),data(:,2),'black','o');
hold on
scatter(data1(:,1),data1(:,2),'red','o');
scatter(data2(:,1),data2(:,2),'red','x');
hold off
title("Sample dataset with two minority class")
legend("class0","class1","class2")
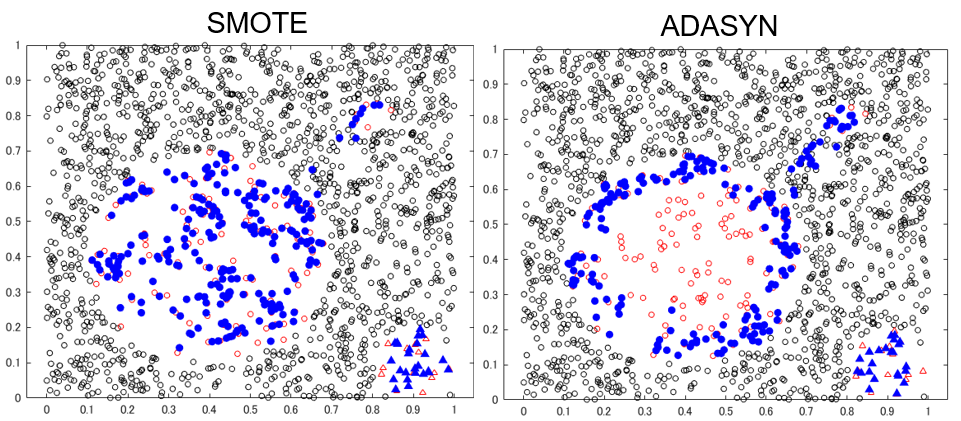
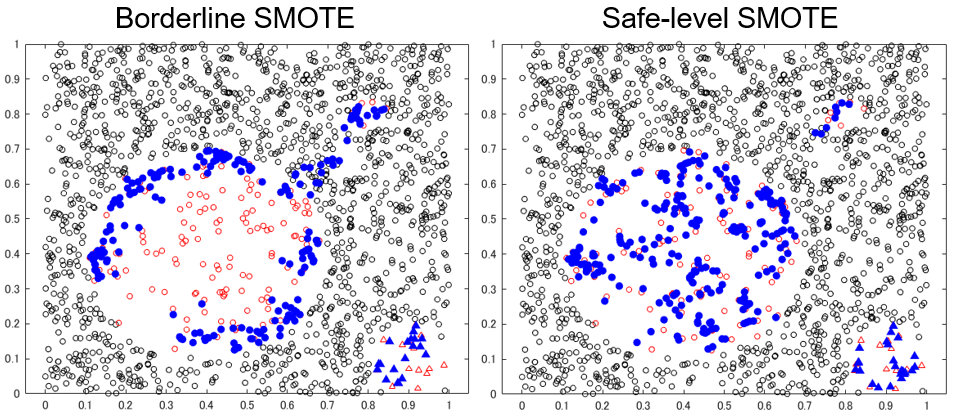
生成データ比較
k = 10 で実行しました。青い点が各手法で生成されたデータ点ですが、class 1 を 200 個、class 2 を 20 個、データを生成しています。class 2 (△) についてはどれも大差ないですが、class 1 (赤〇) では、アルゴリズムの特徴が顕在化していますね。
データ生成実行コード
% Synthesize data
% Define the number of data point to synthesize and algorithms to use.
num2Add = [0,200,20];
algorithm = "Safe-level SMOTE";
% Defile the number of neighbors to use
k = 10;
newdata = table;
visdataset = cell(length(uniqueLabels),1);
% for each class
for ii=1:length(uniqueLabels)
switch algorithm
case "SMOTE"
[tmp,visdata] = mySMOTE(dataset,uniqueLabels(ii),num2Add(ii),...
"NumNeighbors",k, "Standardize", true);
case "ADASYN"
[tmp,visdata] = myADASYN(dataset,uniqueLabels(ii),num2Add(ii),...
"NumNeighbors",k, "Standardize", true);
case "Borderline SMOTE"
[tmp,visdata] = myBorderlineSMOTE(dataset,uniqueLabels(ii),num2Add(ii),...
"NumNeighbors",k, "Standardize", true);
case "Safe-level SMOTE"
[tmp,visdata] = mySafeLevelSMOTE(dataset,uniqueLabels(ii),num2Add(ii),...
"NumNeighbors",k, "Standardize", true);
end
newdata = [newdata; tmp];
visdataset{ii} = visdata;
end
Visualize results
figure(2)
gscatter(dataset.Var1,dataset.Var2,dataset.label,'krr','oo^',4,'off');
hold on
h = gscatter(newdata.Var1,newdata.Var2,newdata.label,'bb','o^',5,'off');
for n = 1:length(h)
color = get(h(n),'Color');
set(h(n), 'MarkerFaceColor', color);
end
hold off
こちらの記事でも触れましたが、SMOTE はとりあえず均等にデータを作りますが、ADASYN/Borderline SMOTE は多数派が周りに多い箇所を重点的に生成されていることが見て取れます。Borderline SMOTE は孤立した少数派は捨てますが、今回のデータでは ADASYN との違いは出ていませんね。
今回の Borderline SMOTE と ADASYN の結果で注目すべきは、本来 class 1 があるべきではないところ(飛び地の真ん中)にデータが生成されてしまっている点です。使用する k (近傍数) の値を小さくすれば避けられますが、要注意点です。飛び地の向こう側まで近傍データを探しに行って、境界が存在しないところに無理やりデータを作ってしまわないよう注意が必要です。Safe-level SMOTE では今回の例においてはその現象は見られませんが、必ずしも避けられるわけではなさそうです。
Borderline SMOTE/ADASYN の、データの境界を集中的に攻めるのは分類精度を上げるうえではよさそうに感じますが、あくまで現在手に入っているデータから見える境界に過ぎないという点にも注意が必要ではないかと感じました。
まとめ
SMOTE, ADASYN, Borderline-SMOTE, Safe-level SMOTE の 4 手法を実装して、1 つのサンプルデータに対して適用してみました。
結果を見ると、よさげな手法だからと闇雲に使って精度が上がった・下がったという議論の前に実際にどんなデータが作られたかの検証はしたほうが良いなと感じました。
レビューペーパー8 を改めてパラパラ眺めていると、特徴量空間ではなく主成分における近傍点を使う方法とかあったりして、今回挙げたような懸念点にも挑戦した手法なんて既に提案されていそうな気もしますね。また気持ちがのれば調べてみます。(お勧めがあれば教えてください!)
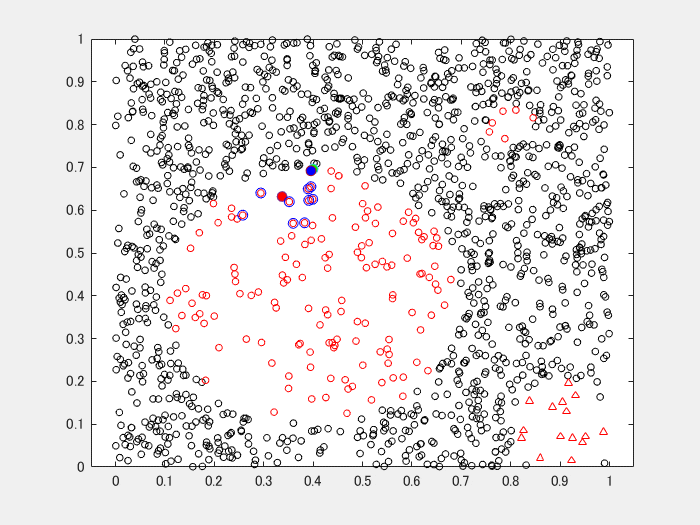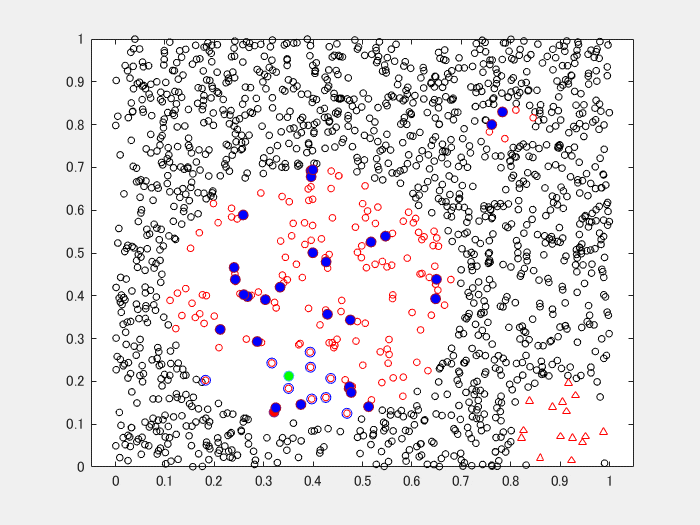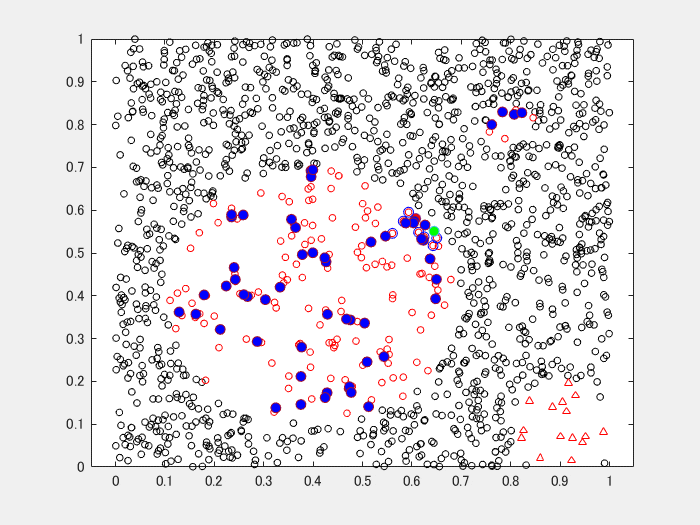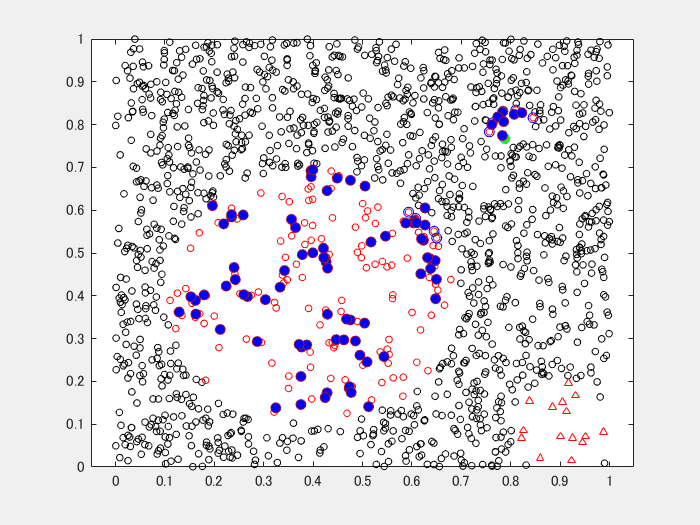
おまけのアニメーション
Safe-Level SMOTE のケース。
青丸(中空)が使用した近傍点、赤丸(中心となる点)と緑丸(近傍点から選ばれた1点)の内挿で求まるのが、青丸の生成されたデータです。
-
オーバーサンプリング手法解説 (SMOTE, ADASYN, Borderline-SMOTE, Safe-level SMOTE) ↩
-
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357. ↩
-
He, H., Bai, Y., Garcia, E. A., & Li, S. (2008). ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE International Joint Conference on Neural Networks (pp. 1322-1328). IEEE. ↩ ↩2
-
Han, H., Wang, W. Y., & Mao, B. H. (2005). Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing (pp. 878-887). Springer, Berlin, Heidelberg. ↩
-
Bunkhumpornpat, C., Sinapiromsaran, K., & Lursinsap, C. (2009). Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Pacific-Asia conference on knowledge discovery and data mining (pp. 475-482). Springer, Berlin, Heidelberg. ↩
-
Function Argument Validation 部分を消せば R2019a 以前でも動くはず。 ↩
-
knnsearchを使っています。k近傍を探す部分を自作すれば MATLAB 本体だけで OK です。 ↩ -
Fernández, A., Garcia, S., Herrera, F., & Chawla, N. V. (2018). SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. Journal of artificial intelligence research, 61, 863-905. ↩