はじめに
実際にどんなデータができるのかはこちら
実装編:オーバーサンプリング手法比較 (SMOTE, ADASYN, Borderline-SMOTE, Safe-level SMOTE)
--
異常検知などをしようとすると異常データが少なくて苦労しますよね。
シゴトでそんな不均衡データ(Imbalanced data)を取り扱うことがあったので、その際調べた中から以下の 4 つの手法のミソを紹介します。
- SMOTE (Chawla, NV. et al. 2002)1
- Borderline SMOTE (Han, H. et al. 2005)2
- ADASYN (He, H. et al. 2008)3
- Safe-level SMOTE (Bunkhumpornpat, C. at al. 2009)4
どの手法が一番効果があるかはデータ次第でしょうが、拡張方法にいろんな思想が垣間見えて大変面白かったです。
参考:Fernández, A., Garcia, S., Herrera, F., & Chawla, N. V. (2018). SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. Journal of artificial intelligence research, 61, 863-905.5
不均衡データの課題と対処法
一方のクラス(目的変数)に対して、もう片方のクラスが極端に多い、または、少ないデータのことを不均衡データ6と呼びます。
そして不均衡データを使って何らかのモデルを学習させる場合は、
- データ数の偏りを補正して均衡にする
- 少ないクラスの誤分類に重いペナルティを課すような損失関数を定義する方法7
がよくとられます。
前者の、データ数の偏りを正した体にする際に取りうる方法は当然ながら以下の 2 つのどちらか:
1-a. 多数派のクラスに属するデータをアンダーサンプリング
1-b. 少数派のクラスに属するデータをオーバーサンプリング
アンダーサンプリングについてはまた機会があれば深堀りしてみたいと思いますが、今回取り上げるのはオーバーサンプリング。
オーバーサンプリング手法: SMOTE
代表的なオーバーサンプリング手法と言えば、Synthetic Minority Over-sampling TEchnique ということで、SMOTE (Chawla, NV. et al. 2002)1 ですね。少ない方のデータをただ単にコピーするのではなく、近傍にあるデータを用いて増やします。
ただ、その方法は大変シンプルで、検出した近接データとの内挿を使って増やすというもの。手法発表した論文も 8934 回(by Google Scholar as of 2019/11/21) も引用されていて、さすがパイオニアですね。
SMOTE provides more related minority class samples to learn from, thus allowing a learner to carve broader decision regions, leading to more coverage of the minority class. (Chawla, NV. et al. 2002)1
だそうな。
簡単に図示してみました。
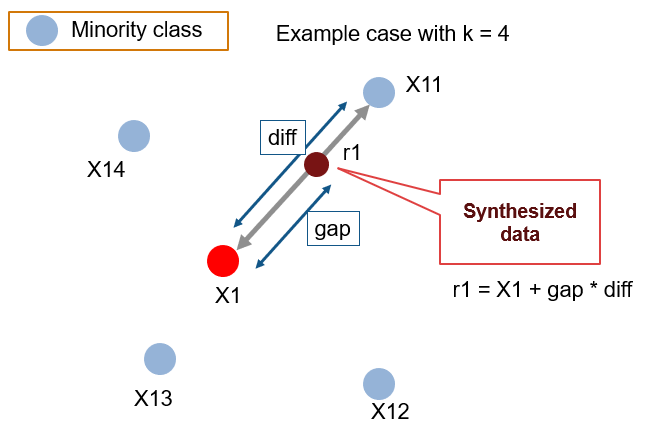
手続き
- X1 を少数派クラスのデータ点の1つだとします
- まず k 個 (例:k = 4) の近接データを用意します(図では X11~X14)
- X11~X14 の中からランダムに1つ選びます(図では X11)
- X1 と X11 の内挿で新しいデータ点とします(図では r1)
ここで、gap は 0 から 1 の乱数を使用し、diff は X11 と X1 の差分です。
この作業を少数派データのすべてに対して行います。データ量を2倍にしたければ、近接データ(X11~X14)から 2 つ選んで、3 倍にするなら 3 つ選んでそれぞれとの内挿を計算すればよし。
k は調整可能なパラメータですが、大きい値になればなるほどより「大胆な」データが作られる可能性が高いともいえるかも。遠くのデータとの内挿をする可能性が出てくるなるので。
拡張版 SMOTE
SMOTE の発表から 15 周年を記念(?)したレビューペーパー (Fernandez, A. et al. 2018) 5 では、100 以上の SMOTE の拡張版アルゴリズムが紹介されていて、「よく調査しましたね・・」というのが正直な感想。圧巻です。
その論文内で代表的な拡張 SMOTE として紹介されている 8 個の中から、微妙な違いが面白いと感じたものを挙げると・・
- ADASYN
- Borderline SMOTE
- Safe-level SMOTE
この 3 つを簡単に説明します。
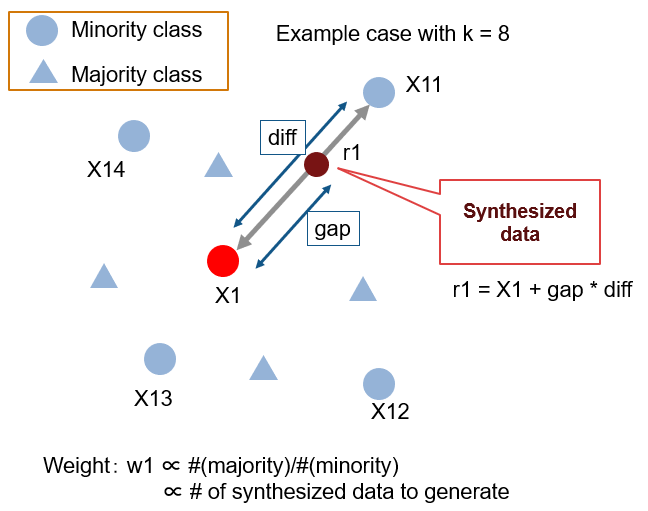
ADASYN (He, H. et al. 2008)3
Adaptive Synthetic sampling の略です。少数派クラスのデータ付近に多数派クラスがどれくらい存在するのかの情報(重み)を動的に加味して増やす手法。多数派クラスが付近に多いほど多めにデータを増やすことで、クラス境界付近に重点的にデータを増やす感じですね。X1 の近傍のクラス分布割合を使用し、周囲に多数派クラスのデータが皆無であれば新しいデータが作られません。その他は SMOTE と同じ。ちなみに論文被引用数 975 (by Google Scholar as of 2019/11/21)。
ADASYN can also autonomously shift the classifier decision boundary to be more focused on those difficult to learn examples, therefore improving learning performance. (He, H. et al. 2008)3
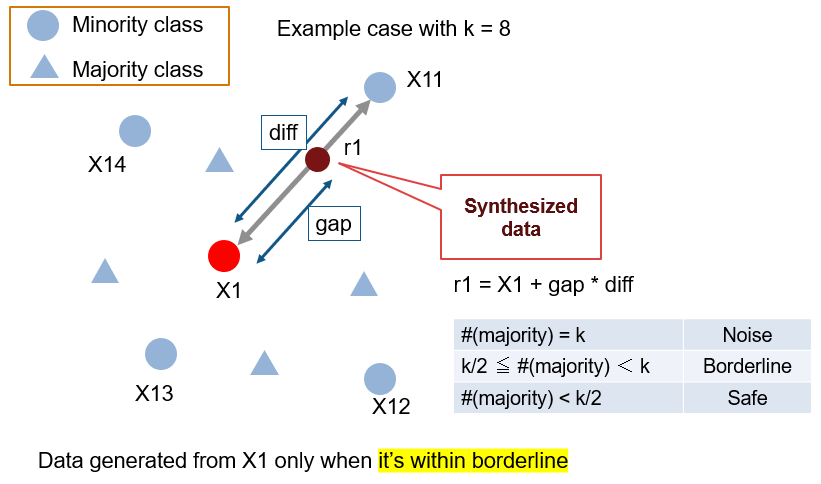
Borderline SMOTE (Han, H. et al. 2005)2
これも、それぞれのクラスのデータがどれくらいの割合で存在するかをもとにデータを増やす量を決めていますが、割合に素直に従う ADASYN と違う点としては Borderline (少なすぎず、多すぎずのいい割合) の領域を重点的に増やすという点。その他は SMOTE と同じ。クラス分類をしやすくすることに直接寄与する部分にデータを増やすことが狙いかと思います。多数派クラスが多すぎる場所にある少数派データはノイズであると捉えているのでしょうか。こちらは論文被引用数 1311 (by Google Scholar as of 2019/11/21)。
our methods only over-sample the borderline examples of the minority class, while SMOTE and random over-sampling augment the minority class through all the examples from the minority class or a random subset of the minority class. (Han, H. et al. 2005)2
と説明があります。
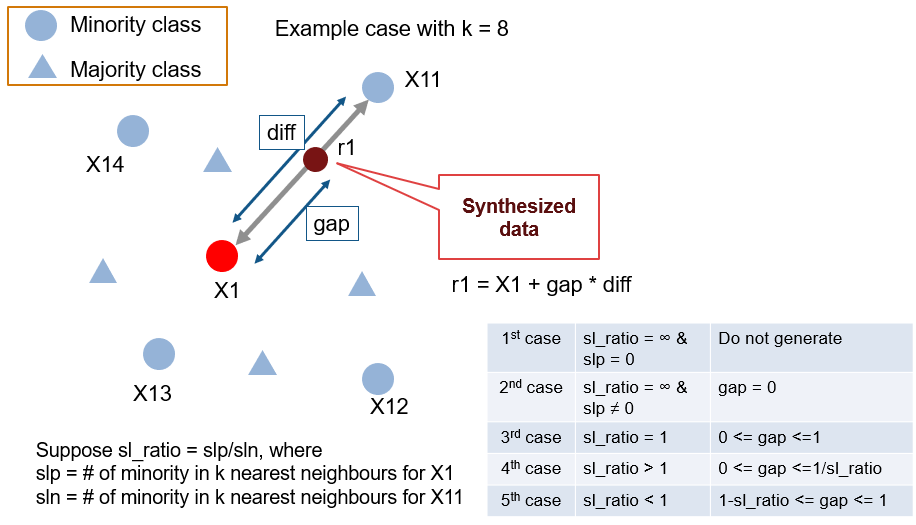
Safe-level SMOTE (Bunkhumpornpat, C. at al. 2009)4
今度は Safe-level とやらを計算します。2つのクラスがどんな割合で存在するのかに対応する指標ですが、この手法で面白いのは内挿の取り方(図でいうところの gap の値)が Safe-level に依存している点です。SMOTE、ADASYN, Borderline SMOTE はどれも内挿に関しては、毎回 gap の値を 0-1 の間でランダムに決めていますが、Safe-level では Safe-level Ratio (sl_ratio) の値によって乱数の取りうる範囲を変えます。例えば X11 の周りに他クラスのものが多い(X11 の safe-levelが低い)場合には、gap は小さめにして X11 の影響を受けにくくします。こちらは論文被引用数 351 (by Google Scholar as of 2019/11/21)。
By synthesizing the minority instances more around larger safe level, we achieve a better accuracy performance than SMOTE and Borderline-SMOTE. (Bunkhumpornpat, C. at al. 2009)4
だとか。強気ですね。
まとめ
SMOTE をはじめとするオーバーサンプリング手法を少しだけ紹介しました。どの手法が一番効果があるかはデータ次第でしょうが、拡張方法にいろんな思想が垣間見えて大変面白かったです。
3 つとも安全なところ(検出が容易そうなところ)には手間をかけないという点は共通しています。ただ、ADASYN は少数派と多数派の境界を重点的に攻めますが、Borderline SMOTE はいい塩梅のところだけ。少数派が孤立しているところは、ノイズだと諦める潔さがあります。Safe-level SMOTE はもう少し拡張して、内挿相手(X11~X14)の状況まで加味する気遣いあり。
ここで触れられたのはごく一部ですので、興味がわいた方は是非 Fernandez, A. et al. (2018) 5 をあたってください。もし「これも面白いぞ!」「これよく使っている!」などお勧めがあればコメントで共有ください。お待ちしています。
File Exchange で検索すると既に MATLAB コードが複数見つかりますが、自分でも MATLAB で実装してみてまた結果を報告してみたいと思います。
おまけ:MATLAB で SMOTE
Chawla, NV. et al. (2002)1 で紹介されている疑似コードを MATLAB にすると以下の通り。このままで関数としてつかうにはあまりに UI が不便ですが、、knnsearch (要 Statistics and Machine Learning Toolbox) を使うとすっきりです。
function smotedata = mySMOTE(features, T, N, k)
% Input
% features: 少数派クラスの特徴量
% T: 少数派クラスのデータ数
% N: 200 の場合、少数派クラスのデータを2倍
% k: 探す近傍数
%
% Output
% smotedata: 少数派クラスを増やした結果
if N < 100
T = (N/100)*T;
N = 100;
end
N = ceil(N/100);
smotedata = zeros(T*N,size(features,2));
newindex = 1;
for ii=1:T
y = features(ii,:); % X1
[nnarray, ~] = knnsearch(features,y,'k',k); % 近傍検出(X11~X14)
for kk=1:N % 欲しいデータの数だけ繰り返す
nn = datasample(nnarray, 1); % 近傍から1個選択
diff = features(nn,:) - features(ii,:);
synthetic = features(ii,:) + rand.*diff; % 内挿
smotedata(newindex,:) = synthetic;
newindex = newindex + 1;
end
end
-
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357. ↩ ↩2 ↩3 ↩4
-
Han, H., Wang, W. Y., & Mao, B. H. (2005). Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing (pp. 878-887). Springer, Berlin, Heidelberg. ↩ ↩2 ↩3
-
He, H., Bai, Y., Garcia, E. A., & Li, S. (2008). ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE International Joint Conference on Neural Networks (pp. 1322-1328). IEEE. ↩ ↩2 ↩3
-
Bunkhumpornpat, C., Sinapiromsaran, K., & Lursinsap, C. (2009). Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Pacific-Asia conference on knowledge discovery and data mining (pp. 475-482). Springer, Berlin, Heidelberg. ↩ ↩2 ↩3
-
Fernández, A., Garcia, S., Herrera, F., & Chawla, N. V. (2018). SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. Journal of artificial intelligence research, 61, 863-905. ↩ ↩2 ↩3
-
【ML Tech RPT. 】第4回 不均衡データ学習 (Learning from Imbalanced Data) を学ぶ(1) ↩
-
MATLAB だと後者は
Costパラメータで設定するだけなのでお手軽です。 ↩