序
Power Platform での業務効率化についてご相談を受けた際、しばしば「PDF を自動で処理したい」というご要望がよく挙がります。
いくつかのご相談の内、そもそも PDF ファイルでのやり取りをやめた方が良いパタンも見受けられましたが、連携の観点からも、そう簡単には業務を変えたり止めたりできない現実があります。
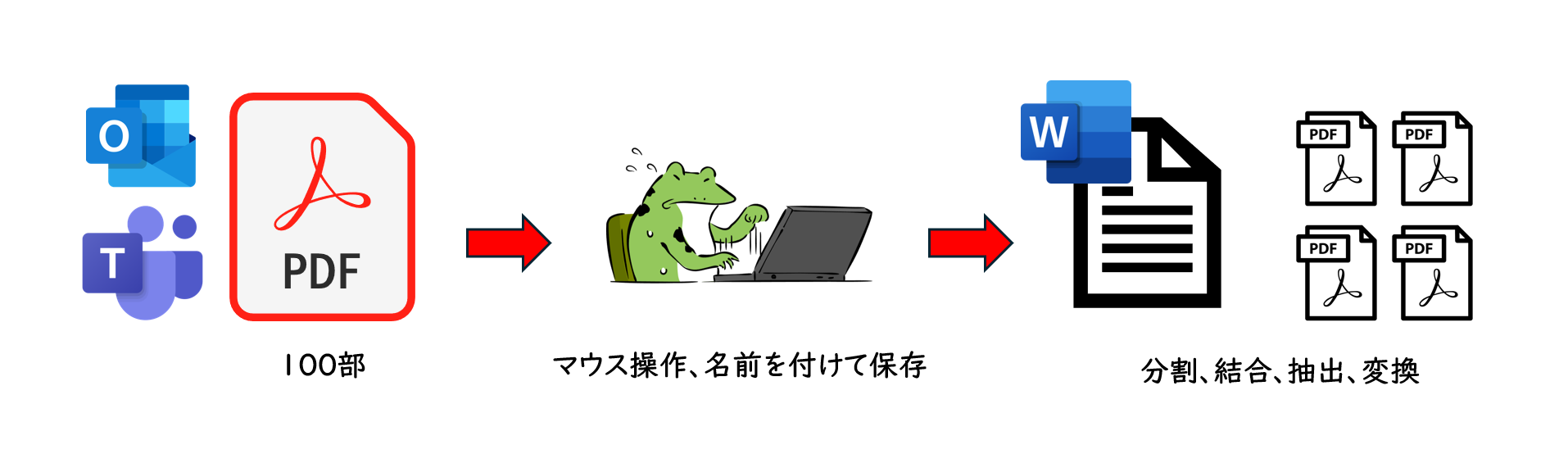
例えば、請求書の結合や分割、ガイドラインの PDF 形式のデータを Word ファイルに変換したり、特定のページを抽出したりするなど、その時限りの作業だったり少部数だったりすればまだしも、日々これらを手動で行うのは時間のかかる作業です。

そういった作業を効率化できるのが Power Automate(クラウドフロー)の Adobe PDF Services コネクタです。このコネクタを利用することで Power Automate 上で PDF を操作できるようになります。
コネクタとは、インターネット上で提供されている「あるサービスと別のサービスを連携するための窓口」のことで、今回は Power Automate と Adobe PDF Services を連携するためのものです。
このコネクタを利用するには、① Power Automate Premium ライセンスと、② Adobe PDF Services コネクタに接続するための諸準備が必要です。
この記事では、環境構築から接続方法、そして実際の活用事例までを順に紹介します。導入検討や検証の参考になれば幸いです。
当記事で記載されるコネクタや API といった専門用語は、明記しない限りは Power Automate の文脈で話しています(可能な限り誤解のないように努めます)
1. ライセンスとセキュリティ
先に挙げた通り、Power Automate の標準機能では、Adobe の PDF アクションは利用できません。まず、実際に必要となるライセンスについて整理しておきましょう。
1.1. Power Automate Premium 概要
Power Automate の Premium ライセンスは、今回使用する Adobe Premium Services コネクタだけでなく、他の Premium コネクタや AI Builder も使えるようになります。詳細はギークフジワラさんの記事に委ねます(非常に分かりやすくまとめてくださっています)
今回の主賓である Adobe PDF Services コネクタはこのカテゴリに含まれるため、Microsoft 365 ライセンスの範囲内では運用できません。
1.2. Adobe PDF Services コネクタ 概要
Adobe PDF Services コネクタは、Adobe が提供する、PDF 操作に必要な API を利用するためのコネクタです。
API とは「データそのものをやり取りするための手段」であり、あえて喩えるなら「取り決めごとが定められた契約書」です。この契約書に記載された形式でデータを交わすことで、互いのサービス間での連携を円滑に進めてくれます。
このコネクタを利用するためには、Adobe アカウントを所有している他、次の 1.3. 章にて紹介するサイトから Client ID(クライアントID) と Client Secret(クライアントシークレット) と呼ばれる2種類の認証情報(=API キー)を発行する必要があります。
1.3. Adobe PDF Services コネクタ利用上の注意
次の公式文書に詳しいですが、Power Automate のフロー設計によっては Adobe 側の有償ライセンスを別途要する可能性があります。
大まかに要約すると、記事執筆時点(2025年10月時点)で、無償トライアル版の場合は1ヶ月あたりの API の呼び出しに 500 回の制限がある と記載されています。また、その回数制限についてですが、API の呼び出し1回につき1つ消費する仕様となっています。
具体的には、100ページの分割であっても、10ページの分割であっても、それぞれ呼び出しが1度であれば1回の消費とみなされます。原典では Document Transaction と表現されています。
他、ページ数制限など、どのような PDF 操作にどれほどの Document Transaction を要するのかは、先に挙げた公式文書を必ずご一読ください。
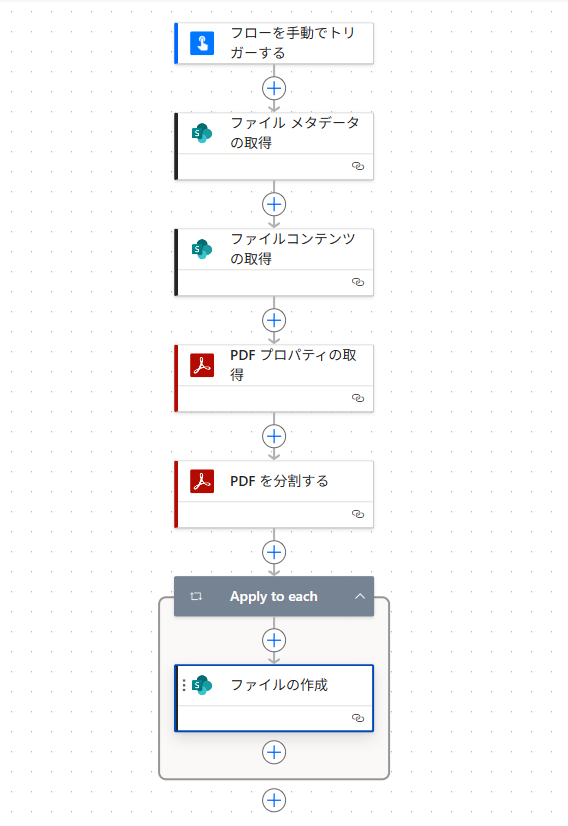
上の図は、あくまでもイメージに過ぎませんが、① PDF のプロパティ(=何ページの PDF ファイルなのか等の情報)取得、②パタン別の分割(例えば、見積書と請求書で2パタンあれば2回消費)ですので、1度のフロー実行で少なく見積もって2回の API 呼び出しを行う見込みです。
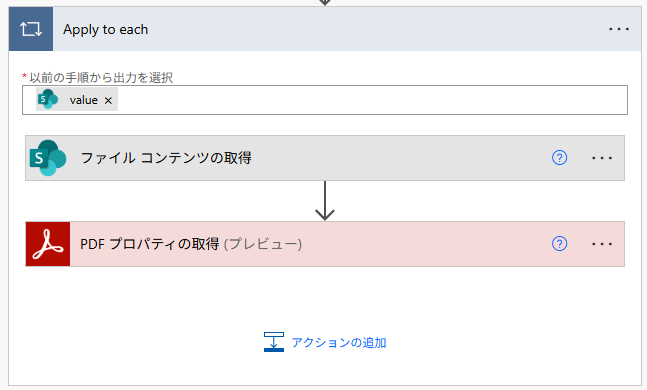
また、実際はフォルダ内に入っているファイルを一括で取得するケースが多いと考えられます。その場合は、繰り返し処理(Apply to each)を使用する観点もあり、もっと消費されるものと予想されます。まずはトライアル版でテストフローを作成し、状況に応じてライセンスを購入していくのが望ましいでしょう。
1.4. Adobe PDF Services コネクタのセキュリティについて
PDF アクションを使って処理するデータ(ファイル)に気を付けなければなりません。PDF アクションの設定の際、以下の画像のように "Region"、つまり「どの国やデータセンターで PDF 処理を実行するか」という項目が詳細オプションにあります。
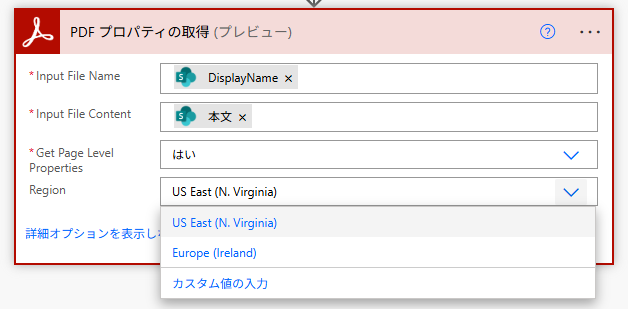
Adobe PDF Services は、複数のデータセンターで動いています。ファイルを変換したり分割したりする際、そのデータは一時的に Adobe のサーバーに送られ、処理されて結果が返って来る仕組みです。
IT 担当者さま向けのお話ですが、Power Platform の環境作成時のリージョンと Adobe PDF Services コネクタの処理リージョンは異なります。
この時、①どの国のサーバーで処理されるのか、②結果、データ保護法や通信法がどの国の影響を受けるのか…ということを決めるのが、この "Region" の設定です。
既定では「米国東部(N.ヴァージニア)」となっており、処理対象ファイルが請求書や学術論文のような社内の(=パブリックな)データであれば、通常、このまま設定を変える必要はない認識です。ただし、次の場合にはリージョンを指定する必要があるように思われます:
- ヨーロッパのデータ保護法に準拠したい場合
- 組織の方針(セキュリティポリシー)で地域を限定している場合
- 国内でのデータ処理を求める契約を交わしているファイルである場合
特に、国内でのデータ処理を求める契約を交わしているファイルに関しては、適用範囲や義務の強さなどは要確認で、契約内容によっては当コネクタの使用を控えなければなりません。
'Input parameter 'x-region-value' validation failed in workflow operation 'PDF_プロパティの取得': The API operation 'PDFProperties' requires the property 'x-region-value' to be set to one of its defined enum values '["-ue1","-ew1"]' but is set to 'apac'.'
カスタム値の入力は一応できるようですが、試しに "apac"(アジア太平洋)と入力してみてもエラーを吐いたので、この点、Adobe 側の更新を待つなどの必要がありそうです。
2. 方法
前置きが長くなりましたが、概要を整理したところで、実際に Power Automate で Adobe PDF Services コネクタを使うまでの流れを紹介しましょう。手順はざっと3段階です。
- Adobe アカウントを取得する
- Client ID と Client Secret を取得する
- Power Automate に接続する
2.1. Adobe アカウントを取得する
まず、Adobe ID(通常のアカウント)を作成します。すでに Lightroom や Photoshop といった Adobe Creative Cloud 製品や Acrobat 製品を利用経験がある場合は、このステップは省いて大丈夫です。
新規に登録する場合、上に引いた作成方法を参考にメールアドレスで登録します。
会社のメールアドレスで新規アカウント登録しないようご注意ください。通常、PDFファイルの操作業務で行っていれば会社アカウントがあるはずですが、一度、担当部門へのお問い合わせいただくのが無難です(個人アカウントでの作業が認められる企業もあるようです)
2.2. Client ID と Client Secret を取得する
アカウントを作成したら、上の Web ページにアクセスします。英語の画面が続きますが、内容はシンプルです。以下の画像のように必要事項を入力して "Create credentials" をクリックすると、すぐに認証情報のページが表示されます。
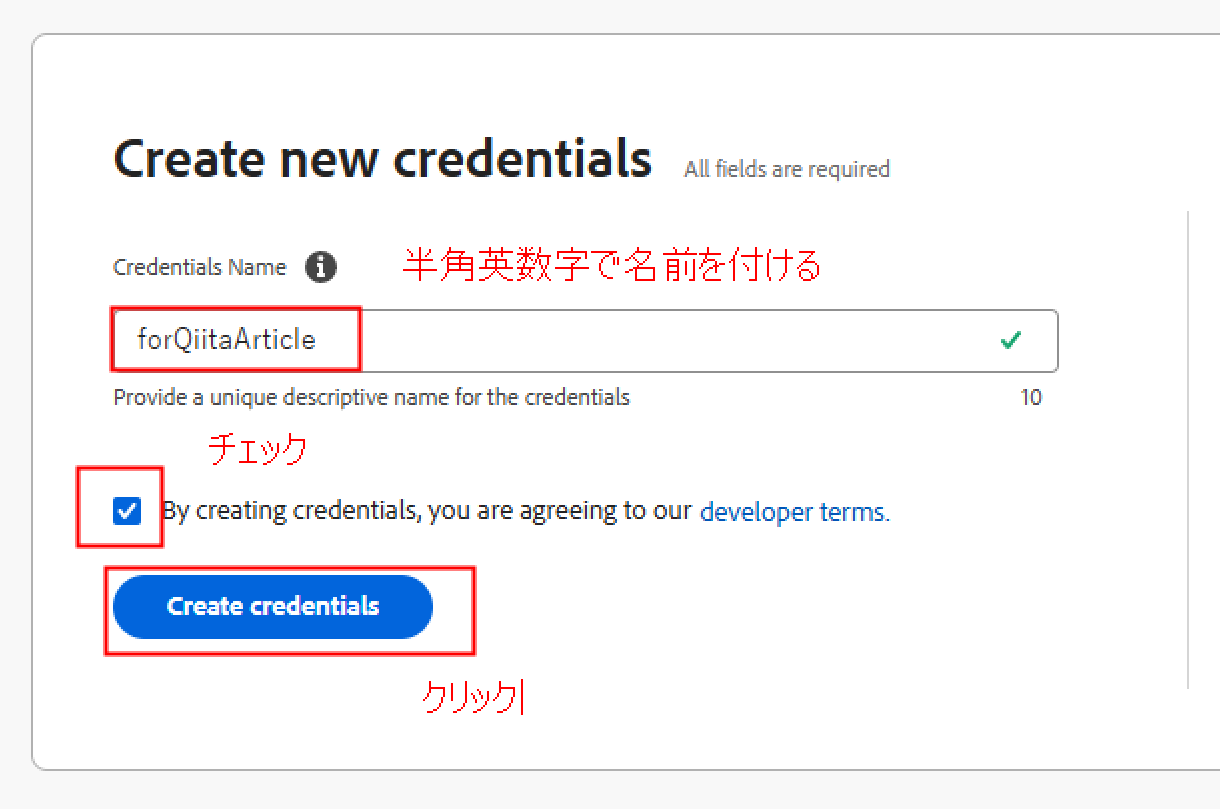
次の3つの ID の内、Client ID と Client Secret の2つを Power Automate での接続時に入力します。Client Secret は、"Retrieve client secret" と書かれたボタンを押すことで取得できます。タブを開いたままにしておくか、安全な場所にコピーして保管しておくのを忘れないようにしてください。
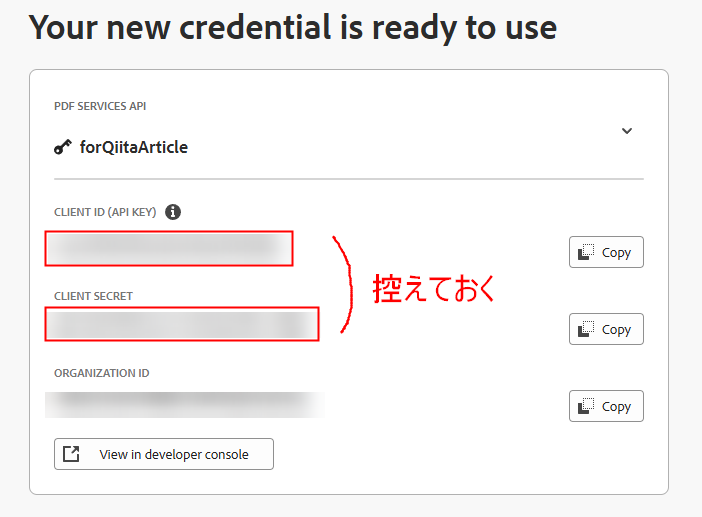
なお、取得したキーは、Adobe Developer Console にて、プロジェクトごとに管理されています。これら ID が漏洩すると第三者が利用できるようになってしまうため管理に注意してください(特にスクリーンショットを添える際はモザイク処理等を忘れないようにしましょう)
2.3. Power Automate に接続する
準備が整ったら、Power Automate 側で Adobe PDF Services コネクタを設定します。接続が成功すると各アクションが利用可能になります。導線は2つあるのでそれぞれ紹介します。
2.3.1. 接続タブから設定する場合
Power Automate を開いたら「接続」をクリックします。この「接続」が見つからない場合は「⋯ 詳細」をクリックすると現れます。
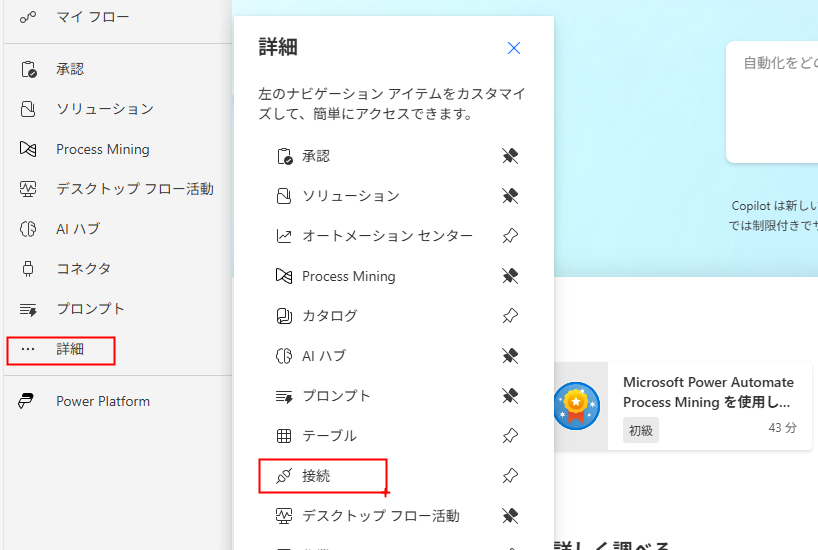
次に、クリックした先の画面で「+新しい接続」をクリックし、Adobe PDF サービス の + アイコンをクリックします。
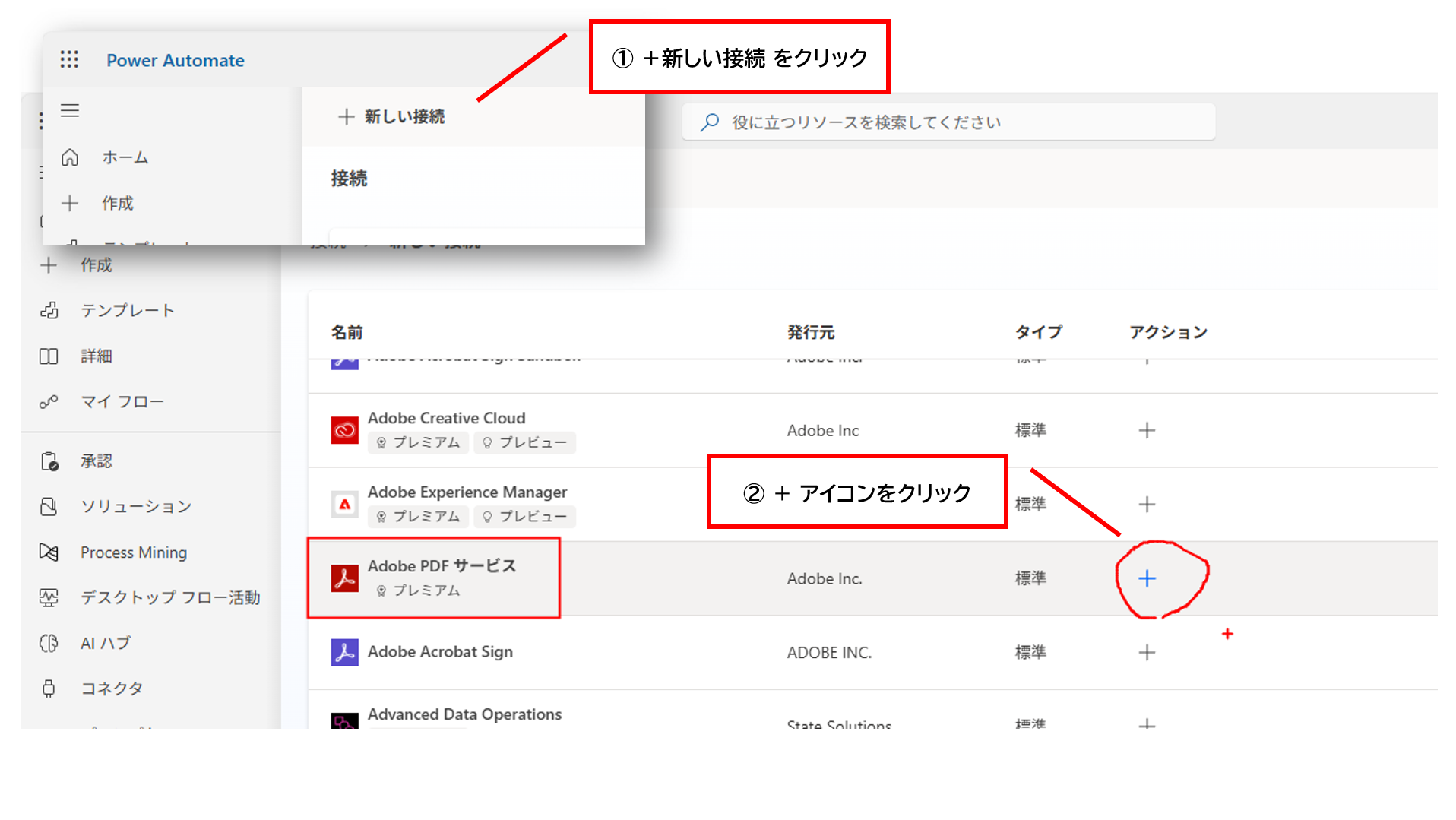
最後に、先ほど取得した Client ID と Client Secret を入力して「作成」をクリックして準備完了です。
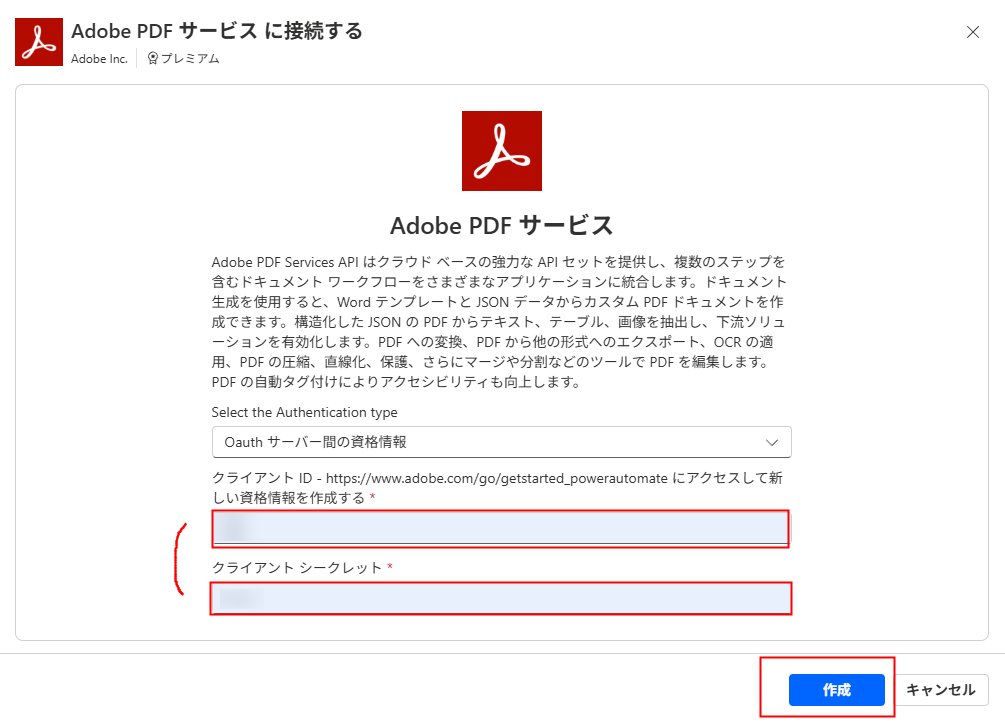
2.3.2. フロー作成時(アクションの配置時)に設定する場合
実際にフローを作成する段階であれば、Adobe PDF Services コネクタの任意のアクションを配置する時に、取得した Client ID と Client Secret をそれぞれ入力します(※次の画像は Microsof Learn からの引用です。Client Secret は、"Retrieve client secret" ボタンを押すことで表示されます)
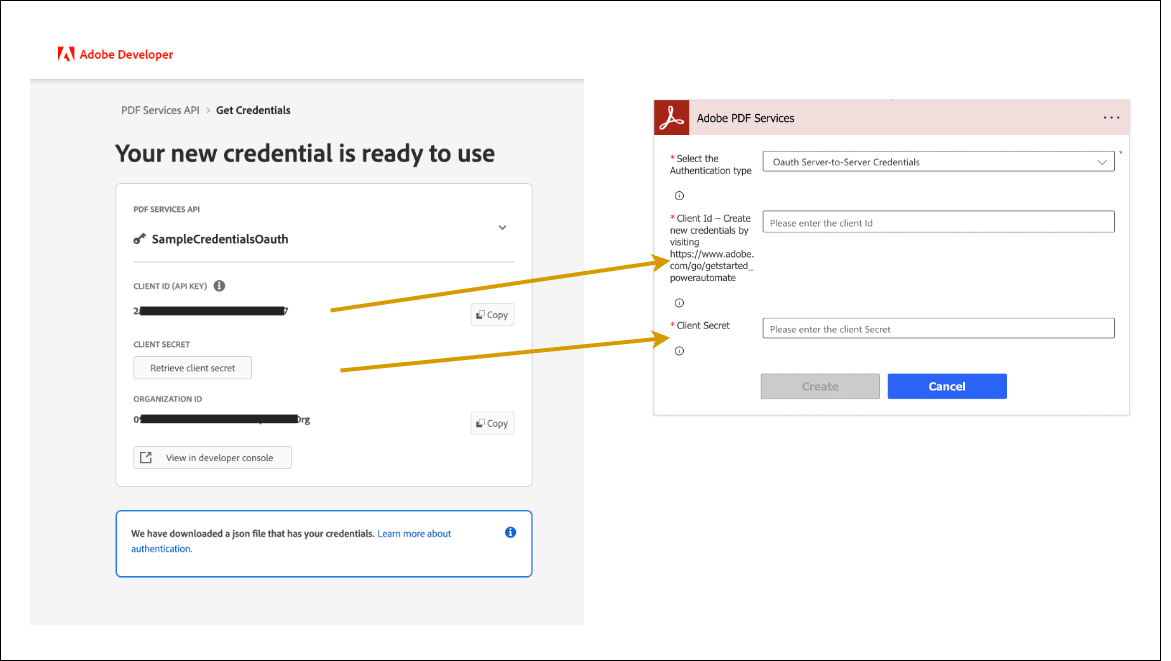
ここまで設定できれば、あとは通常のフロー構築です。初回接続時に上手く動作しない場合、そのほとんどが Secret の入力ミスやコピー&ペースト時の空白文字が原因です。一度、入力内容を削除するなどして再接続してみると改善します。
補足ですが、会社の Microsoft アカウントで Adobe PDF Services に接続する時、データが外部に流出するのを防止する設定が施されている場合があります(=DLP ポリシー)。利用目的などをご説明の上、接続できるように設定してもらう必要があります。
3. 活用事例
最後に、活用事例です。PDF の処理はどれも基本的に同じ「ファイルの取得 → Adobe PDF Services アクション → 出力ファイル保存」という流れで構築できます。
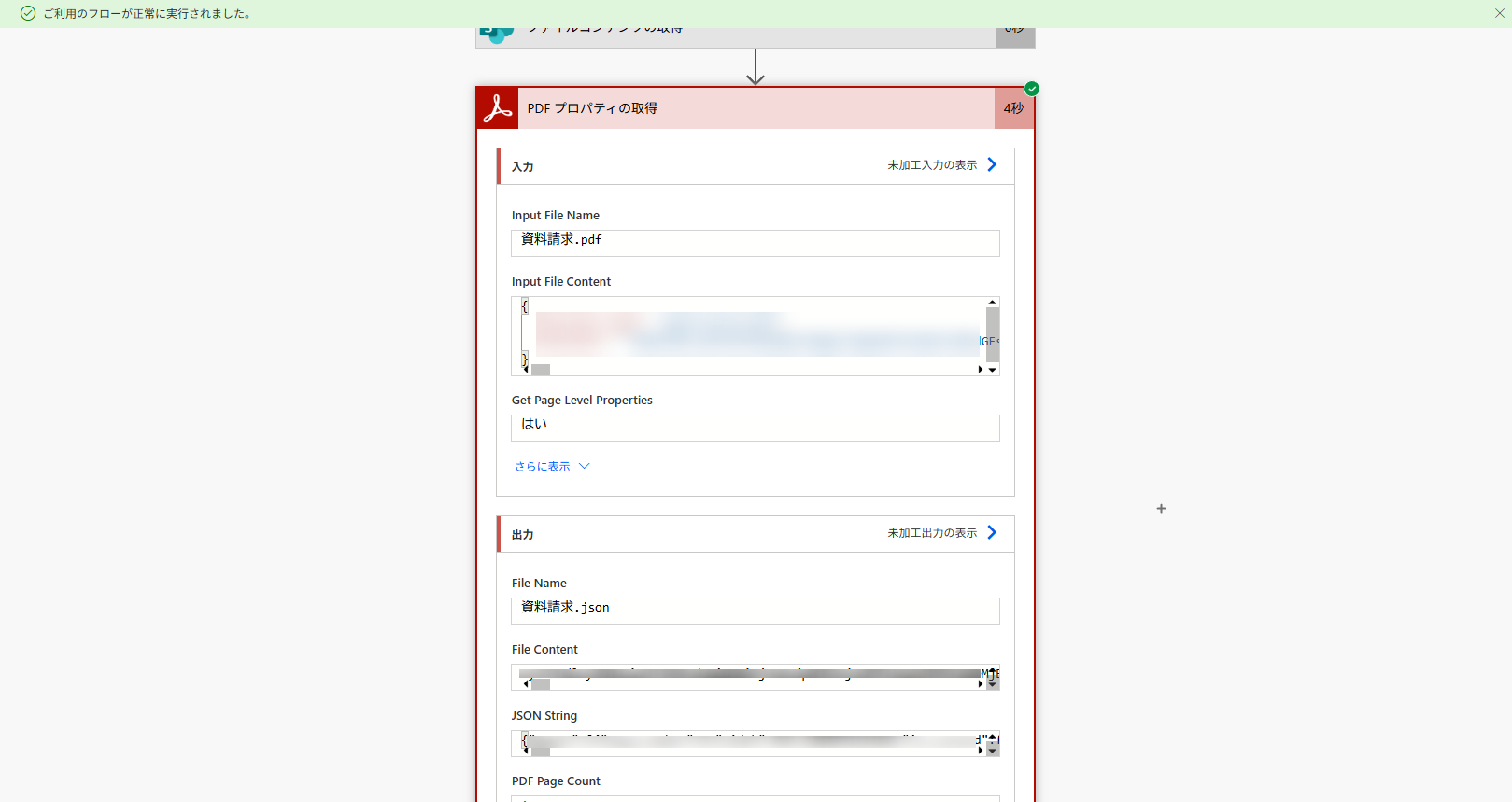
ページ数の指定は置いておいて、2つに分割したり、1つにまとめたり、単純に1件だけ情報を取得したりしてみるなど、簡単なケースから始めると感覚を掴みやすいので手を動かしてみましょう。1件だけ情報を取得するフローは以下のとおりです。
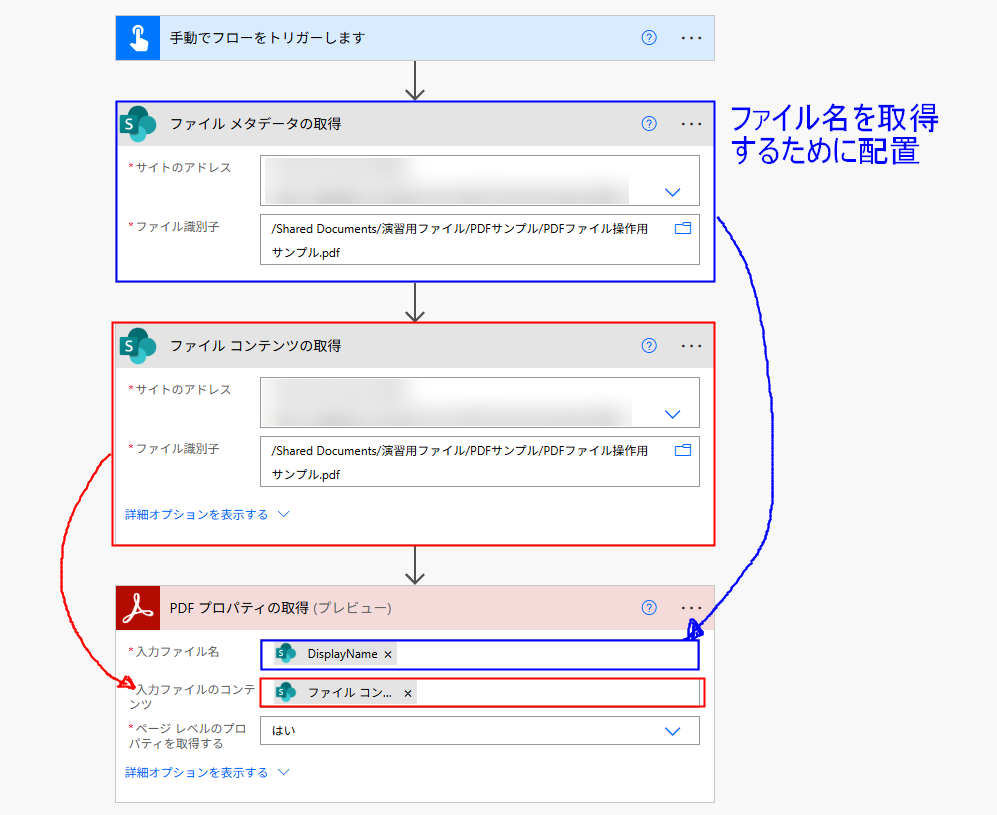
ファイル名には DisplayName、ファイルコンテンツには「本文」をそれぞれ動的な値から選択して配置し、フローを実行するとファイル名やページ数などを取得でき、後続のフローで活用できるようになります。
トリガーには今回「手動でフローをトリガーします」を配置していますが、ファイルが保存されたのをトリガーにしたり、Outlook メールを受信したのをトリガーにすることもできます。その場合は「ファイル メタデータの取得」アクションを配置しなくてもファイル名を取得できます。
「PDF プロパティの取得」アクションでは PDF ファイルの本文を取得できません。本文を抽出したい場合は、AI Builder を活用することになるでしょう。
3.1. PDF ファイル操作の前に
PDF ファイル操作の前に、ファイルの保存場所を整備しておく必要があるでしょう。今回のように、SharePoint 上にファイルを保存する場合は、結合対象のファイルを1箇所にまとめたり、ファイルメタデータを付与したりすることで Power Automate 上での操作を単純化できます。

当記事では活用事例の紹介に焦点を当てているため「フォルダ」で分けています。しかし、推奨なのは SharePoint の強みを活かした「ファイルメタデータ」を付与することです。
容量の節約に繋げられますし、フォルダの階層構造を最小に留められます。さらに、ファイルのステータスを管理しやすくなるなど(目立たないものの)業務効率化を期待できます。
また、昨今注目されている Copilot によるドキュメント検索や情報収集が便利になります。委細は、上に引いたコルネさんのスライドをご一読ください。
3.2. PDF ファイルの結合
複数の PDF を1つにまとめたい場合は「PDF のマージ(英:Merge PDFs)」アクションを使います。OneDrive for Business や SharePoint に保存された複数ファイルを配列として読み込み、結合対象に指定できます。
3.2.1. フロー概要
冒頭で述べたように、今回は「手動でフローをトリガーします」をトリガーにしています。特に PDF 結合の場合は複数のファイルが用意されている前提があるためです。
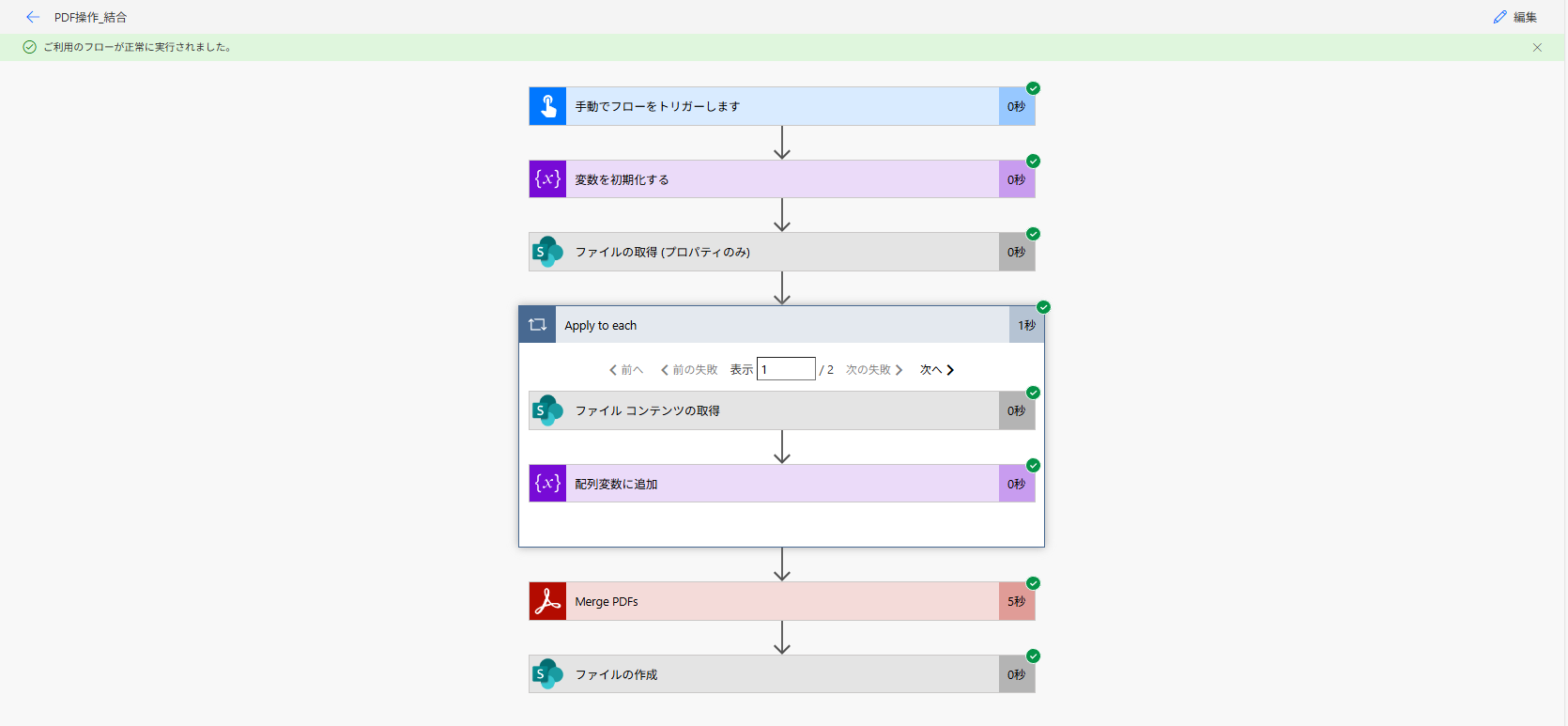
配列変数(種類:アレイ)を使うことで、取得してきたファイルを1つにまとめることができ、後続アクションでの PDF アクションを使用する際の「実行回数」の消費を1回に抑えられます。
PDFアクションで結合したファイルは、.json で戻ってくるので、SharePoint コネクタの「ファイルの作成」アクションで、任意の場所(今回は「結果」というフォルダを用意しています)に保存することで作業完了です。
3.2.2. 設定内容
まず、PDF という名前のアレイ型変数を作成します。名前は自由です。値には [](ブラケット)を入力しておきます。このブラケットは「アレイ」を合図します。
まずはざっくりと理解しておけばよいですが、アレイとは「配列」を意味しており、配列とは「表形式のデータ」を意味します。後続の「配列変数に追加」アクションで、この表の中身を埋めていくためのアクションです。
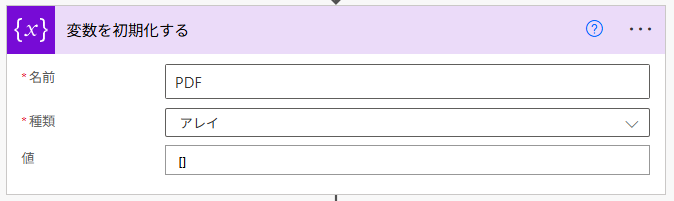
「変数を初期化する」アクションを設定したら、今度は SharePoint の「ファイルの取得(プロパティのみ)」を配置し、結合したいファイルを保存しているフォルダを指定します。今回は「結合」というフォルダに、その対象のファイルが保存されています。
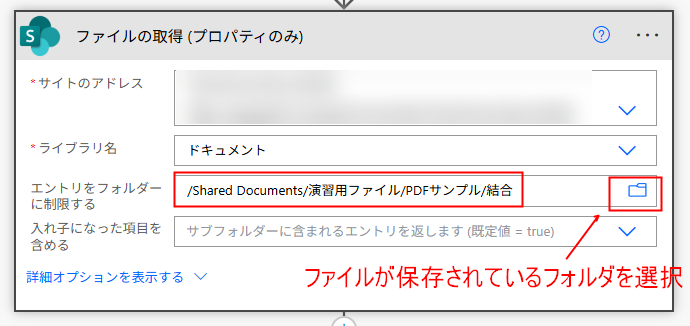
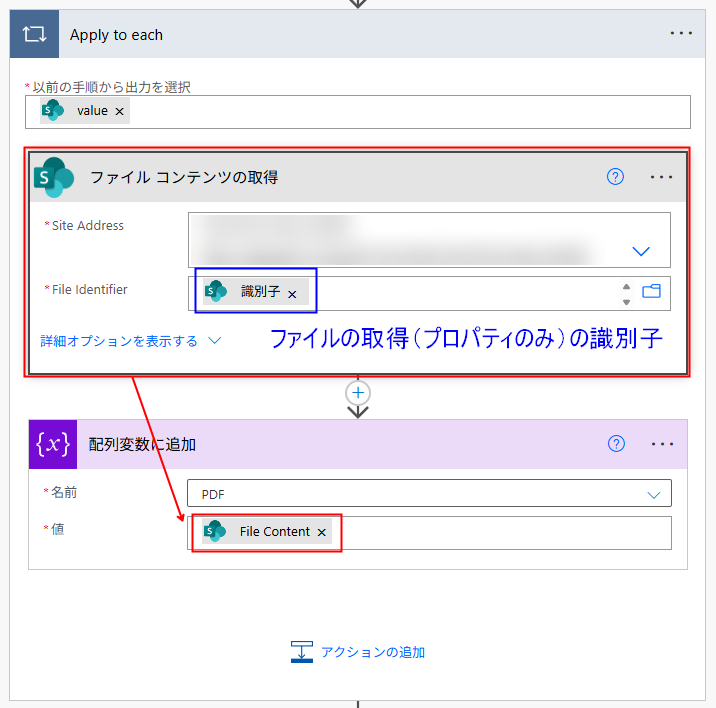
SharePoint の「ファイル コンテンツの取得」アクションを配置し、動的な値から、先ほど設定した「ファイルの取得(プロパティのみ)」の「識別子」を選択します。すると、Apply to each が自動的に置かれます。
その Apply to each アクションの枠内の「アクションの追加」をクリックして「配列変数に追加」を挿入します。設定した変数名が選べるようになっているのでそれを選択し、直前の「ファイル コンテンツの取得」アクションの動的な値(ファイルコンテンツ)を値にセットします。
今度は、Apply to each の外側に「PDF のマージ」アクションを配置します。配置したら、結合後の PDF ファイルの名前を拡張子付きでベタ打ち入力し、右手にある T のアイコンをクリックして入力モードを切り替え、PDF の変数をセットします。
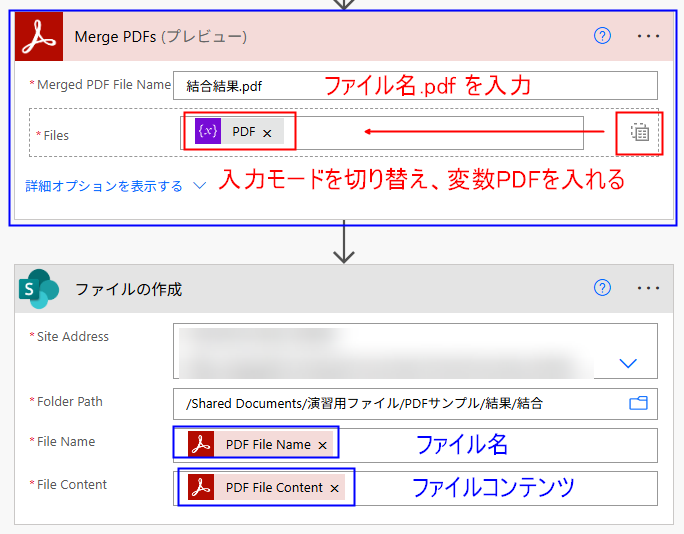
最後に、SharePoint のファイルの作成アクションで、上アクションで結合したファイルを指定のフォルダに保存して作業完了です。
3.2.3. 補足

結合される順番は(おそらく)結合元ファイルが保存されているフォルダ内の並び順になっているため、上の画像の Sort 列のように、あらかじめ「ファイルメタデータ」を付与しておき、Power Automate に取り込む段階で昇順に並べ替え、結合する順番を制御することになります。
3.3. PDF ファイルの分割
分割には「PDF の分割(英:Split PDF)」アクションを使用します。指定したページ範囲ごとに新しい PDF を生成できるため「受領書と仮伝票」や「見積書と請求書」のように構成の決まった帳票の仕訳に良いでしょう。
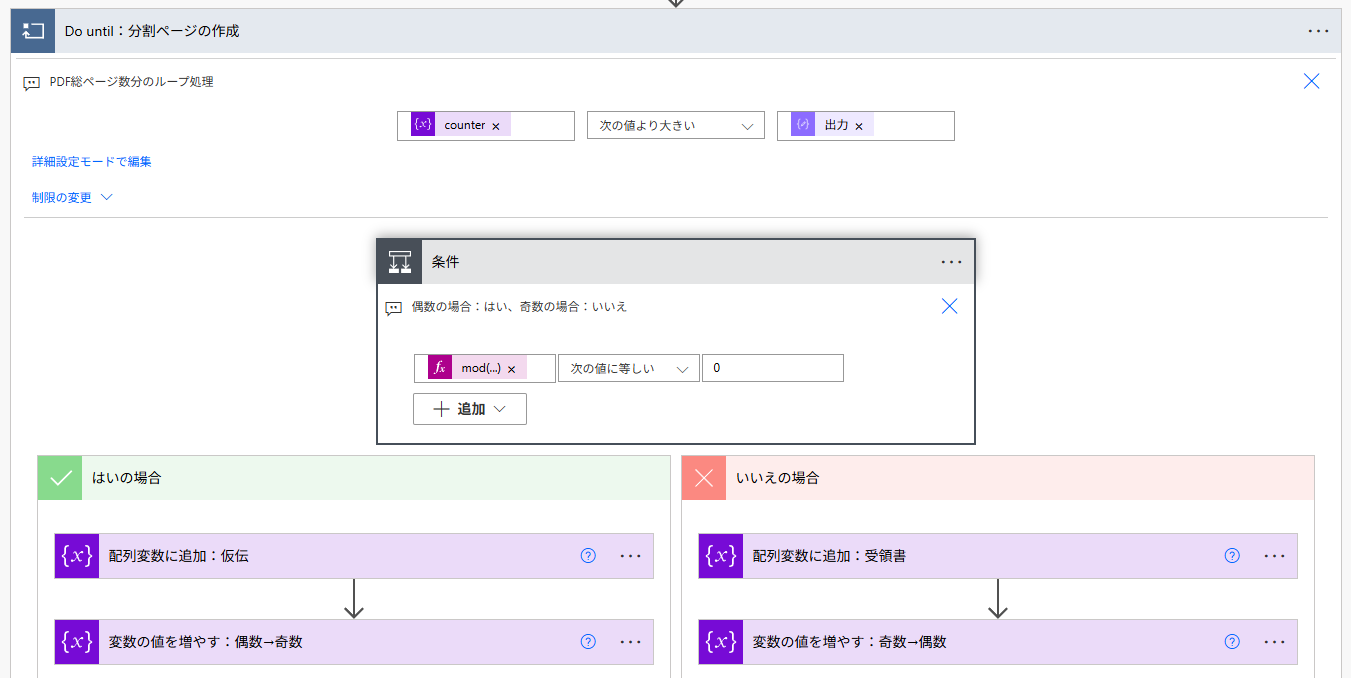
例えば、奇数ページに受領書、偶数ページに仮伝票(受領控)が存在する法則性のある PDF ファイルの場合、まず「PDF プロパティの取得(英:Get PDF Properties)」で総ページ数を取得し、その値に応じて分岐処理を設けることで条件ごとの分割も可能です(以下に Power Automate での様々な数列の作り方を引いておきます)
こういった法則性がない場合、AI Builder と組み合わせてレイアウト検出を行うことも可能です。特定の情報をキーにして、ページ分割用の数列を生成するプロンプトを作成することで実装できそうです。
とはいえ、まずは固定ページ単位での分割から試してみると「何がフローに必要なのか」といった理解が進むと思います。応用については稿を改めることとし、今回は「3.2. PDF ファイルの結合」で結合したファイルを、表紙と本文の2つに分割してみましょう。
3.3.1. フロー概要
今回は、1ページ目が表紙、2ページ目から4ページ目の計3ページが本文の PDF ファイル1件を扱います。また、トリガーは「手動」となっていますが、SharePoint ライブラリに特定のフォルダが保存されたのを契機にフローを実行することも可能です。
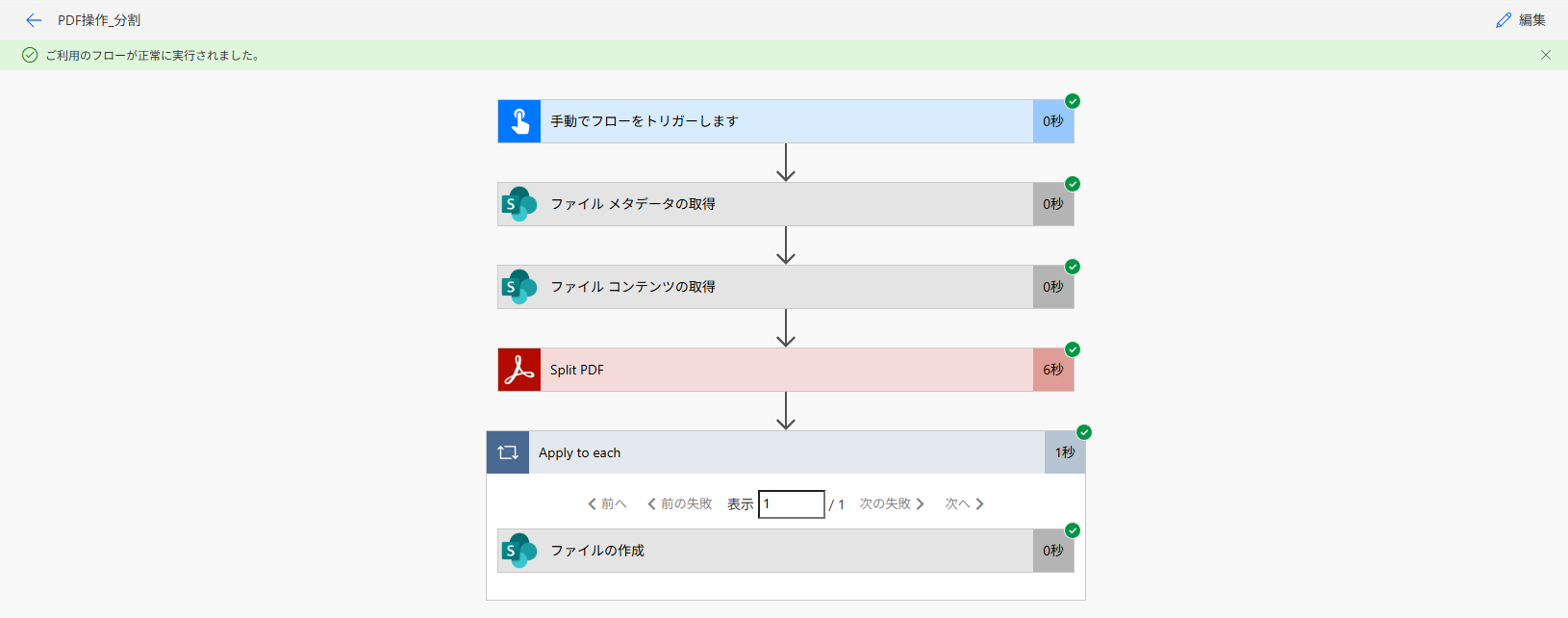
ファイルを1件、SharePoint コネクタの「ファイル メタデータの取得」を配置し、後続アクションの「ファイル コンテンツの取得」アクションに必要な「識別子」を取得します。
その後、どのように分割するのかを「PDF の分割」で設定し、最後に分割したファイルを指定の SharePoint フォルダ内に保存する流れです。
3.3.2. 設定内容
ファイルを取得してくる手順としては、3.2. と同様です。後続アクションの「ファイル コンテンツの取得」で分割ファイルを取得してくることができれば、どのアクションで配置しても構いません。
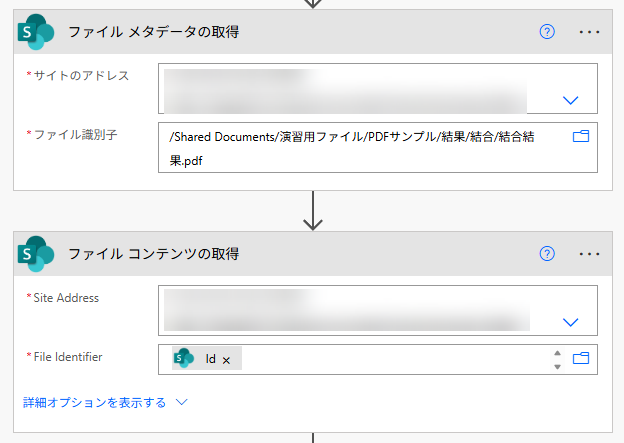
「PDF の分割」アクションを配置し、ファイル名に「拡張子付きの名前」を入れます。動的なコンテンツの「表示名(DisplayName)」を入れ、分割の種類を「ページ範囲の配列」とし、分割の構成を 1, 2-4 と設定し、最後に「ファイル コンテンツの取得」から得た動的な値を入れます。
なお、分割の種類については以下をご参考ください。Microsoft Learn には記載されていないのですが恐らくこの解釈で大丈夫です。実際に触りながら調整していただけますと幸いです。
| 分割の種類 | 意味 | 向いているケース |
|---|---|---|
| ページ範囲の配列 | 明示的に「1–1」「2–2」のようにページ範囲を指定して分ける | 奇数ページ・偶数ページなど、規則的 or 手動指定したい場合(今回の用途) |
| ページ数 | たとえば「2ページごとに分割」など、固定ページ数で切る | 各文書が一定ページ数の場合 |
| 分割ファイルの数 | 全体を N 分割したい場合(ページ数で自動計算) | ページ数が不明でも、ざっくり N 等分したい場合 |
| カスタム値の入力 | Power Automate 式などで動的に分割条件を生成する | ループ処理や変数利用時に使う上級向け |
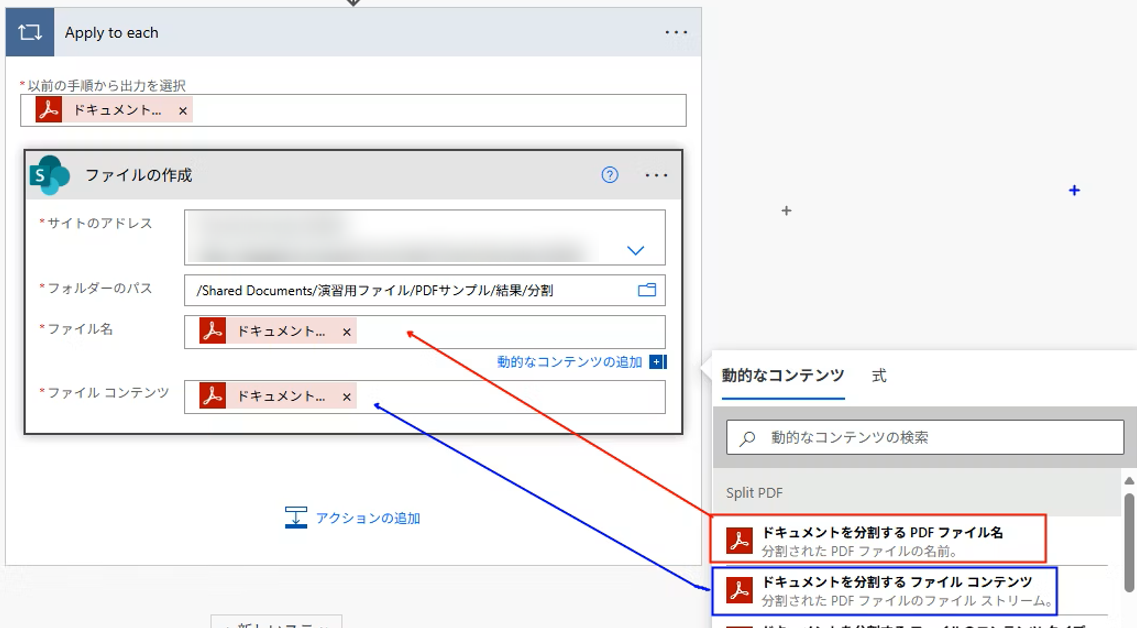
最後に、分割されたファイルを指定のフォルダに保存することで作業完了です。今回、複数ファイルが存在するため「ファイルの作成」アクションに PDF アクションから得た動的な値をセットした時に Apply to each が自動挿入されます。
3.3.3. 補足
PDF 分割フローのポイントは、ページ区切り(ページ範囲)の設定とファイル名の設定です。実際の業務を想定した場合、その多くが PDF ファイル内の文書に記載されている何かしらの情報を頼りにファイル名を付けるはずです。
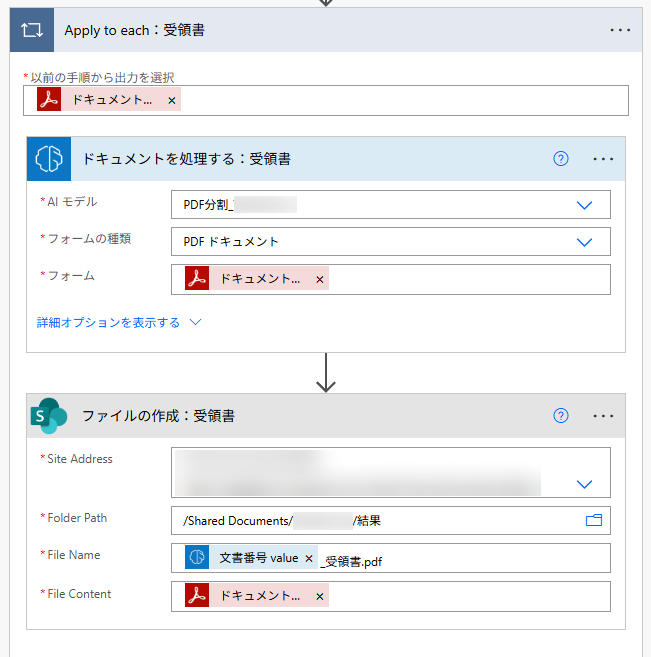
そういった場合は、上の図のように AI Builder を利用するなどして文書内を読み取り、読み取った内容を元にファイル名を付けることもできます。
AI Builder も色々ですが、OCR や「カスタムプロンプト」を使用すると良いです。OCRを活用する場合は事前に「学習」させる必要があるので、まずは気楽に「カスタムプロンプト」から試すと良さそうです。作成方法は、一旦、次の記事をご参考ください。
色々検証中なのですが、ある程度法則性がある場合は、AI Builder を使うよりも、別途、ファイル名を「作成」アクションや「変数」アクションなどで定義しておく方が安定するかもしれません(いずれにせよ、詳細は稿を改めます)
結
Power Automate と Adobe PDF Services の連携は、Power Automate Premium ライセンスを前提としている以上、導入のハードルこそ少し高いものの、運用に入るとその効果は非常に大きいと感じます。
PDF 分割もさることながら、分割した PDF ファイルの一件々々に名前を付けて保存していく作業もかなりの時間を要します。自由に PDF 処理を自動化できれば、業務の生産性を確実に高められるのではないでしょうか。この記事が導入検討や検証の参考になれば幸いです。
Adobe PDF Services コネクタは、記事執筆時点(2025年10月時点)では実験的機能(プレビュー)です。念のため、影響範囲の小さい業務でお試しください。