非力なPCで第一原理計算(DFT)のお勉強をしているが、もう限界
書籍を使って第一原理計算のお勉強をしているが、使っているPCのスペックが低いからか、ちょっと動かすたびに計算の待ち時間が生じて、ちょっと辛い状態に。
今は、Ubuntuのapt-getで簡単にインストールできるQuantum Espressoを使っている状態。
そうだ!コンパイラやライブラリを変えたら速くなる!?
ということで、フリーで入手できるコンパイラ/ライブラリの組み合わせで、Sourceからインストールした記録を示します。
お役に立てたらLGTMお願いいたします。
PCのスペック、実行環境
- CPU : AMD Phenom II X2 1065T (化石!?)
- メモリ :12GB (DDR3-1333)
- ストレージ :Samsung SSD 860 EVO
- OS : Ubuntu 20.04 on wsl2 on Windows10
※CPU補足。10年以上前の2010年頃に発売された2.9GHzで6コアのAMD製45nmプロセスCPU。2022年現在も、普通にPCを使う分には困らずに稼働しております。。。。
ベンチマーク結果
早速ですが、ベンチマーク結果を示します。
CPUコアを変えて実施、各コアで3回実施して平均値(±最大/小値)をプロットしてます。
縦軸は、計算にかかった時間。下にある方が高速、という結果です。
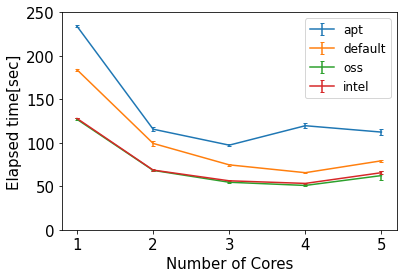
フリー系のoss(次項参照)とintel系でのコンパイルが同じ、というかossの方が気持ち速い!!
Intel系使わなくてもここまで速くなるとは思ってませんでした。
fftw3の寄与が大きそうな感じなのと、古い&AMDCPUを使っているので、intelOneAPIの恩恵を十分に受けられていない可能性はありますが。
とはいえ、私のPCの場合、oss使って4コア計算で、apt-getよりも2倍速くなりました。
ちなみに、6コアPCですが、計算速度が、コア4→5で悪化してきたので6コアは行わず。5コアの時点でばらつきも少し大きくなってきている感じが。wsl使ってるからでしょうか。
利用したQuantum Espresso
Quantum Espresso 6.8を下記のインストール/コンパイルしたもの
- apt: apt-getコマンドでインストールしたQE
- default: Sourceを、オプションなどつけず、GCC系(+デフォルトのOpneMPI)でコンパイルしたもの
- intel : intelOneAPIを用いて、intelコンパイラ、intelMKL(intel_fftw3ラッパー有)、IntelMPIでコンパイルしたもの。ver._2021.1。2022系を使ったがうまくコンパイルできなかった。
- oss : GCC, OpenMPI, OpenBLAS(BLAS,LAPACK,CBLAS), ScaLAPACK(withOpenBLAS), FFTW3のOpenSourceたちを使ってコンパイル。ちなみに、OpenBLAS、ScaLAPACK、FFTW3自体のコンパイルもGCCを使用。すべてoss。
計算は、セルにSi3O6を含んだSiO2のSCF計算です
並列計算はMPIで実施(OpenMPはオフ)
QEのコンパイルコマンド
備忘録もかねて、コンパイルのコマンドも載せておきます。
ライブラリを適切にリンクするのって難しい。
oss
$ ./configure DFLAGS='-D__FFTW3 -D__MPI -D__SCALAPACK' IFLAGS='-I$(TOPDIR)/include -I$(TOPDIR)/FoX/finclude -I/path_OpenBLAS/include -I/path_FFTW3/include' BLAS_LIBS='/path_OpenBLAS/libopenblas.a' LAPACK_LIBS='/path_OpenBLAS/libopenblas.a' SCALAPACK_LIBS='/path_ScaLAPACK/libscalapack.a' FFT_LIBS='/path_FFTW/libfftw3.a'
intel
$ ./configure DFLAGS='-D__OPENMP -D__DFTI -D__MPI -D__SCALAPACK' IFLAGS='-I$(TOPDIR)/include -I$(TOPDIR)/FoX/finclude -I/path_mkl/include' FFT_LIBS='/path_intel_fftw3/***.a' LAPACK_LIBS='-lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5 -lpthread -lm' BLAS_LIBS='-lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5 -lpthread -lm' SCALAPACK_LIBS='-lmkl_scalapack_lp64 -lmkl_blacs_intelmpi_lp64 -lmkl_core -liomp5 -lpthread -lm' BLACS_LIBS='-lmkl_scalapack_lp64 -lmkl_blacs_intelmpi_lp64 -lmkl_core -liomp5 -lpthread -lm' --enable-openmp
# 上記コンパイルではOpenMPは有効。計算実行時にOpenMPは1コアを指定して実行。
最後に
フリーで偉大なるソフトウェアを公開・維持してくださっている方々に心から感謝→QE(GNUGPL)、OpenMPI(NewBSD)、OpenBLAS(BSD-3)、ScaLAPACK(modified BSD)、FFTW(GNUGPL)。そして、最近は最新版を無償利用させてくれているIntelさんにも感謝。
ASEとQuantum Espresso関連の投稿記事リンク
ASEとQuantum Espressoを使って、
- 手動でCuの単位格子最適化して、平衡体積弾性率を見積る
- Ptが単純立方構造、fcc、hpcのいずれの構造をとるかを調べる
- 六方晶Hfの格子定数aとcを最適化する
- H2Oなどの3原子分子を構造を最適化して、安定構造を見つける
- (表面系とかもそのうちアップ予定)
他