はじめに
システム開発において、データベースに存在するテーブルの一覧やテーブルの構造を把握するために、テーブル一覧やテーブル定義書といったドキュメントは必要不可欠だと思います。
そのようなドキュメントを自動生成するツールを業務の傍ら作成してみたので、紹介してみようと思います。
作成したツール
リポジトリ
GitHubのリポジトリはこちら(exportTableDefinition)です。
使い方
ツールの使い方はGitHubのリポジトリのREADMEに記載しています
exportTableDefinition-1.0-SNAPSHOT.jarという、実行可能形式のJarファイルを実行する形で、テーブル定義書を作成します。
テーブル定義書のサンプル
テーブル定義書のサンプルはこちらです。
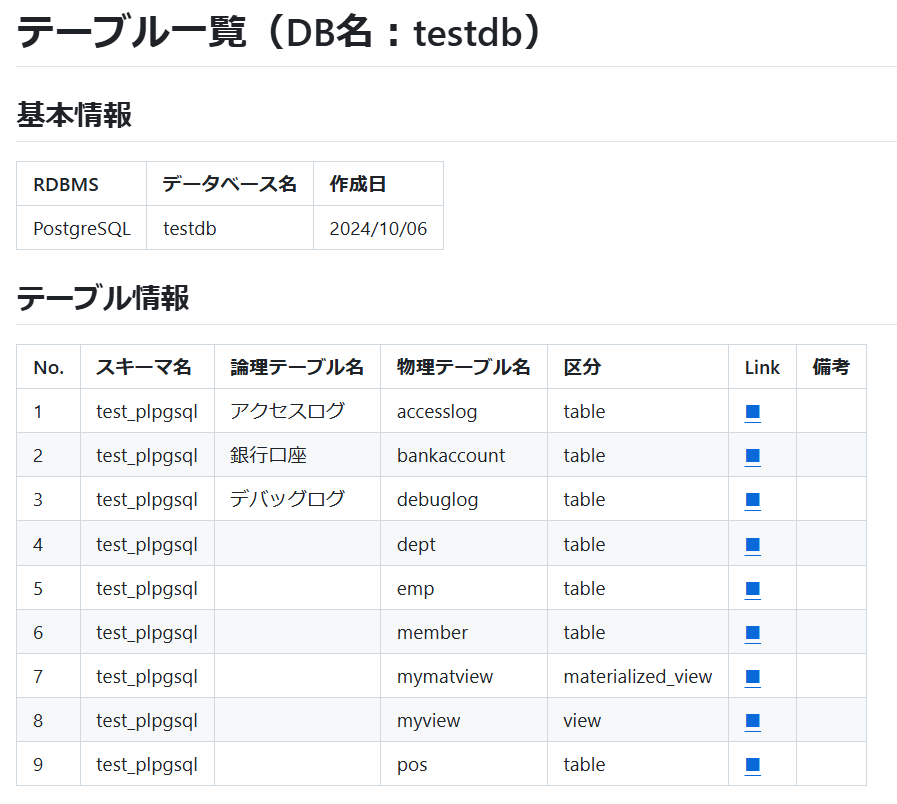
テーブル一覧
DBに存在するテーブルの一覧を出力します。
テーブル一覧から、各テーブル定義書に遷移できるリンクも用意しています。
Markdownのパース処理の関係上、テーブル数が3000を超えた場合はテーブル一覧のファイルを分割して表示します。
テーブル設計書
DBに存在するテーブルから以下の項目を出力します。
- テーブル情報(テーブル名等)
- カラム情報
- インデックス情報
- 制約情報
- 外部キー情報
出力したテーブルがどのような役割のテーブルであるか補足説明ができるよう、テーブル説明の枠も用意しています。

利用技術/ライブラリ等
- Java
- Mybatis
- PostgreSQL
- Oracle など
対象DBMS
- PostgreSQL
- Oracle(一部制限あり)
- Oracleの場合は、以下の項目の出力が不可
- デフォルト値
- view/materialized_viewのソース
- Check制約の定義
- デフォルト値
- Oracleの場合は、以下の項目の出力が不可
なんで作ったのか
- 自分が担当しているシステムにおいて、テーブル定義書が存在していなかった(!)
- A5:SQL Mk-2など、SQLクライアントかつテーブル定義を自動生成するソフトウェアは存在するが、自社PCの関係でソフトウェアのインストールがためらわれた
- Postgresqlであれば、システムカタログなどからテーブル定義書の作成に必要な情報を簡単に引っこ抜けるのではないかという安直な考え
大変だったこと
-
様々なパターンを考慮しないといけない
- 例)
- テーブルやカラムのコメントにに改行コードが含まれており、Markdownのテーブルのレイアウトが崩れる
- カラムをDropした場合において、Dropしたカラムの情報も抽出されてしまった
- 例)
-
出力対象のテーブル数が多すぎると、Markdownのパースがされなくなる
- 大体の感覚でテーブル数が4000件を超えてくると、GitHub上にコミットしたmdファイルのパースがされなくなるため、一定の件数を超えたらファイルを分割して出力する実装を余儀なくされる
抽出に利用したSQLについて
今回作成したツールにおいては、情報スキーマ、システムカタログからテーブル定義書を出力するために必要なデータをSQLで抽出しました。
実際にツールで利用したSQLとは若干異なりますが、こちらにも残しておきます。
テーブル情報を取得するSQL
WITH all_tables AS (
SELECT
coalesce(t1.schemaname, '') AS schema_name,
'table' AS table_type,
coalesce(regexp_replace(pg_catalog.obj_description(concat(t1.schemaname, '.', t1.tablename)::regclass),'\r|\n|\r\n', '', 'g'), '') AS logical_table_name,
coalesce(t1.tablename, '') AS physical_table_name,
'' AS definition
FROM pg_catalog.pg_tables t1
WHERE t1.schemaname NOT IN ('pg_catalog', 'information_schema')
UNION ALL
SELECT
coalesce(t2.schemaname, '') AS schema_name,
'view' AS table_type,
coalesce(regexp_replace(obj_description(concat(t2.schemaname, '.', t2.viewname)::regclass),'\r|\n|\r\n', '', 'g'), '') AS logical_table_name,
coalesce(t2.viewname, '') AS physical_table_name,
definition AS definition
FROM pg_catalog.pg_views t2
WHERE t2.schemaname NOT IN ('pg_catalog', 'information_schema')
UNION ALL
SELECT
coalesce(t3.schemaname, '') AS schema_name,
'materialized_view' AS table_type,
coalesce(regexp_replace(obj_description(concat(t3.schemaname, '.', t3.matviewname)::regclass),'\r|\n|\r\n', '', 'g'), '') AS logical_table_name,
coalesce(t3.matviewname, '') AS physical_table_name,
definition AS definition
FROM pg_catalog.pg_matviews t3
WHERE t3.schemaname NOT IN ('pg_catalog', 'information_schema')
)
SELECT
schema_name AS "スキーマ名"
, logical_table_name AS "論理テーブル名"
, physical_table_name AS "物理テーブル名"
, table_type AS "種別"
, definition AS "定義"
FROM all_tables
ORDER BY
schema_name, physical_table_name;
カラム情報を取得するSQL
WITH all_columns AS (
(
SELECT
t1.schemaname AS schema_name,
t1.tablename AS table_name,
row_number() over (PARTITION BY t1.schemaname, t1.tablename ORDER BY t3.attnum) AS column_num,
coalesce(substring(coalesce((t4.description), ''), '^[^\t\r\n\((]*'), '') AS logical_column_name,
t3.attname AS physical_column_name,
pg_catalog.format_type(t3.atttypid, t3.atttypmod) AS column_type,
coalesce((
SELECT '○'
FROM pg_catalog.pg_constraint c
WHERE c.conrelid = t2.oid
AND t3.attnum = ANY (c.conkey)
AND c.contype = 'p'
), '') AS primary_key,
CASE t3.attnotnull
WHEN true THEN '○'
ELSE ''
END AS not_null,
coalesce((
SELECT pg_catalog.pg_get_expr(d.adbin, d.adrelid)
FROM pg_catalog.pg_attrdef d
WHERE d.adrelid = t3.attrelid
AND d.adnum = t3.attnum
), ' ') AS default_value,
regexp_replace(coalesce(substring(coalesce((t4.description), ''), '^.*[\t\r\n\((]+(.*)'), ''), '[\\))]$', '', 'g') AS remarks
FROM
pg_catalog.pg_tables t1
LEFT OUTER JOIN pg_catalog.pg_class t2
ON t1.tablename = t2.relname
LEFT OUTER JOIN pg_catalog.pg_attribute t3
ON t2.oid = t3.attrelid
LEFT OUTER JOIN pg_catalog.pg_description t4
ON t3.attrelid = t4.objoid AND t3.attnum = t4.objsubid
WHERE
t1.schemaname NOT IN ('pg_catalog', 'information_schema')
AND t2.relkind = 'r'
AND t3.attnum > 0
AND t3.attname NOT LIKE '%pg.dropped%'
ORDER BY
t1.schemaname, t1.tablename, t3.attnum
)
UNION ALL
(
SELECT
t1.schemaname AS schema_name,
t1.viewname AS table_name,
row_number() over (PARTITION BY t1.schemaname, t1.viewname ORDER BY t3.attnum) AS column_num,
coalesce(substring(coalesce((t4.description), ''), '^[^\t\r\n\((]*'), '') AS logical_column_name,
t3.attname AS physical_column_name,
pg_catalog.format_type(t3.atttypid, t3.atttypmod) AS column_type,
coalesce((
SELECT '○'
FROM pg_catalog.pg_constraint c
WHERE c.conrelid = t2.oid
AND t3.attnum = ANY (c.conkey)
AND c.contype = 'p'
), '') AS primary_key,
CASE t3.attnotnull
WHEN true THEN '○'
ELSE ''
END AS not_null,
coalesce((
SELECT pg_catalog.pg_get_expr(d.adbin, d.adrelid)
FROM pg_catalog.pg_attrdef d
WHERE d.adrelid = t3.attrelid
AND d.adnum = t3.attnum
), ' ') AS default_value,
regexp_replace(coalesce(substring(coalesce((t4.description), ''), '^.*[\t\r\n\((]+(.*)'), ''), '[\\))]$', '', 'g') AS remarks
FROM
pg_catalog.pg_views t1
LEFT OUTER JOIN pg_catalog.pg_class t2
ON t1.viewname = t2.relname
LEFT OUTER JOIN pg_catalog.pg_attribute t3
ON t2.oid = t3.attrelid
LEFT OUTER JOIN pg_catalog.pg_description t4
ON t3.attrelid = t4.objoid AND t3.attnum = t4.objsubid
WHERE
t1.schemaname NOT IN ('pg_catalog', 'information_schema')
AND t2.relkind = 'v'
AND t3.attnum > 0
AND t3.attname NOT LIKE '%pg.dropped%'
ORDER BY
t1.schemaname, t1.viewname, t3.attnum
)
UNION ALL
(
SELECT
t1.schemaname AS schema_name,
t1.matviewname AS table_name,
row_number() over (PARTITION BY t1.schemaname, t1.matviewname ORDER BY t3.attnum) AS column_num,
coalesce(substring(coalesce((t4.description), ''), '^[^\t\r\n\((]*'), '') AS logical_column_name,
t3.attname AS physical_column_name,
pg_catalog.format_type(t3.atttypid, t3.atttypmod) AS column_type,
coalesce((
SELECT '○'
FROM pg_catalog.pg_constraint c
WHERE c.conrelid = t2.oid
AND t3.attnum = ANY (c.conkey)
AND c.contype = 'p'
), '') AS primary_key,
CASE t3.attnotnull
WHEN true THEN '○'
ELSE ''
END AS not_null,
coalesce((
SELECT pg_catalog.pg_get_expr(d.adbin, d.adrelid)
FROM pg_catalog.pg_attrdef d
WHERE d.adrelid = t3.attrelid
AND d.adnum = t3.attnum
), ' ') AS default_value,
regexp_replace(coalesce(substring(coalesce((t4.description), ''), '^.*[\t\r\n\((]+(.*)'), ''), '[\\))]$', '', 'g') AS remarks
FROM
pg_catalog.pg_matviews t1
LEFT OUTER JOIN pg_catalog.pg_class t2
ON t1.matviewname = t2.relname
LEFT OUTER JOIN pg_catalog.pg_attribute t3
ON t2.oid = t3.attrelid
LEFT OUTER JOIN pg_catalog.pg_description t4
ON t3.attrelid = t4.objoid AND t3.attnum = t4.objsubid
WHERE
t1.schemaname NOT IN ('pg_catalog', 'information_schema')
AND t2.relkind = 'm'
AND t3.attnum > 0
AND t3.attname NOT LIKE '%pg.dropped%'
ORDER BY
t1.schemaname, t1.matviewname, t3.attnum
)
)
SELECT
schema_name AS "スキーマ名",
table_name AS "テーブル名",
column_num AS "No",
logical_column_name AS "論理名",
physical_column_name AS "物理名",
column_type AS "データ型",
primary_key AS "PK",
not_null AS "NOT NULL",
default_value AS "デフォルト値",
remarks AS "備考"
FROM
all_columns
ORDER BY
schema_name, table_name, column_num;
インデックス情報を取得するSQL
WITH all_indexes AS (
SELECT
t5.schemaname AS schema_name,
t1.relname AS table_name,
t2.relname AS index_name,
coalesce(array_to_string(array_agg(t4.attname ORDER BY t4.attnum), ','), '') AS column_names
FROM
pg_class AS t1
LEFT OUTER JOIN
pg_index AS t3 ON t1.oid = t3.indrelid
LEFT OUTER JOIN
pg_class AS t2 ON t2.oid = t3.indexrelid
LEFT OUTER JOIN
pg_attribute AS t4 ON t4.attrelid = t1.oid AND t4.attnum = ANY(t3.indkey)
LEFT OUTER JOIN
pg_tables AS t5 ON t1.relname = t5.tablename
WHERE
t3.indisprimary = false
AND t3.indisunique = false
AND t1.relkind = 'r'
AND t5.schemaname NOT IN ('pg_catalog', 'information_schema')
GROUP BY
t5.schemaname, t1.relname, t2.relname
)
SELECT
schema_name AS "スキーマ名",
table_name AS "テーブル名",
index_name AS "インデックス名",
column_names AS "カラムリスト"
FROM
all_indexes
ORDER BY
schema_name, table_name;
制約情報を取得するSQL
WITH all_constraints AS (
SELECT
t3.nspname AS schema_name,
t2.relname AS table_name,
t1.conname AS constraints_name,
CASE t1.contype
WHEN 'c' THEN 'CHECK'
WHEN 'f' THEN 'FOREIGN KEY'
WHEN 'p' THEN 'PRIMARY KEY'
WHEN 'u' THEN 'UNIQUE'
ELSE NULL
END AS constraints_type,
pg_get_constraintdef(t1.oid) AS constraints_definition
FROM
pg_catalog.pg_constraint t1
LEFT OUTER JOIN pg_catalog.pg_class t2
ON t1.conrelid = t2.oid
LEFT OUTER JOIN pg_catalog.pg_namespace t3
ON t2.relnamespace = t3.oid
WHERE
t1.contype in ('c', 'f', 'p', 'u')
AND t3.nspname NOT IN ('pg_catalog', 'information_schema')
)
SELECT
schema_name AS "スキーマ名",
table_name AS "テーブル名",
constraints_name AS "制約名",
constraints_type AS "制約種類",
constraints_definition AS "制約定義"
FROM
all_constraints
ORDER BY
schema_name, table_name, constraints_type, constraints_name;
外部キー情報を取得するSQL
WITH all_foreignkeys AS (
SELECT
t1.constraint_name AS foreignkey_name,
t2.table_schema AS schema_name,
t2.table_name AS table_name,
coalesce(array_to_string(array_agg(DISTINCT t2.column_name), ','), '') AS column_names,
t3.table_schema AS reference_schema_name,
t3.table_name AS reference_table_name,
coalesce(array_to_string(array_agg(DISTINCT t3.column_name), ','), '') AS reference_column_names
FROM
information_schema.table_constraints AS t1
LEFT OUTER JOIN information_schema.key_column_usage AS t2
ON t1.constraint_name = t2.constraint_name
AND t1.constraint_catalog = t2.table_catalog
AND t1.constraint_schema = t2.table_schema
AND t1.table_name = t2.table_name
LEFT OUTER JOIN information_schema.constraint_column_usage AS t3
ON t2.constraint_name = t3.constraint_name
AND t2.table_catalog = t3.constraint_catalog
AND t2.table_schema = t3.constraint_schema
WHERE
t1.constraint_type = 'FOREIGN KEY'
AND t1.constraint_schema NOT IN ('pg_catalog', 'information_schema')
GROUP BY
t1.constraint_name, t2.table_schema, t2.table_name, t3.table_schema, t3.table_name
ORDER BY
t1.constraint_name, t2.table_schema, t2.table_name, t3.table_schema, t3.table_name
)
SELECT
schema_name AS "スキーマ名",
table_name AS "テーブル名",
foreignkey_name AS "外部キー名",
column_names AS "カラムリスト",
reference_schema_name AS "参照先スキーマ名",
reference_table_name AS "参照先テーブル名",
reference_column_names AS "参照先カラムリスト"
FROM
all_foreignkeys
ORDER BY
schema_name, table_name;
おわりに
テーブル定義書を自動生成するツールを自作してみてわかりましたが、A5:SQL Mk-2のテーブル定義書の作成機能はすごい・・・。
機能を考えるときに参考にしていたのですが、出力の内容について詳細に設定することができるので、便利だなと・・。