概要
はじめに
これは、「富士通クラウドテクノロジーズ Advent Calendar 2019」の14日目の記事です。
昨日は@213さんの今年起こした障害の話でした。
213さんは果たして、13日の金曜日を無事に乗り切ったのでしょうか。気になるところです。
本題
ふとしたときに人は本を読みたくなるものですが、その時の気分によって明るい内容だったり暗い内容だったり読みたい本の傾向って変わりますよね。
けど、書店でいちいち手に取ってあらすじや内容を確認する時間はないですし、ネット上でフリーで公開されている青空文庫にはあらすじは存在しないので読んでみないとどんな作品なのか把握できません。
だったら内容を確認せずともぱっと見で本の内容が分かるようにしましょう。
作ったもの
人類がぱっと見で内容を理解するためにはやはり、本の内容を図示する必要があります。
そのため、本の内容を感情分析してレーダーチャート化してみました。
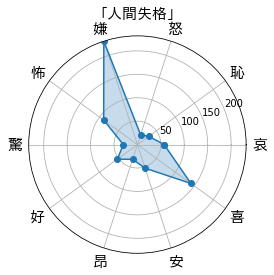
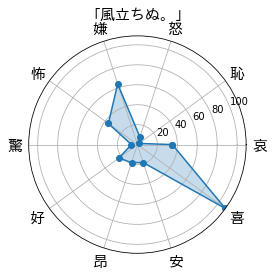
「人間失格」は嫌成分が多くて、「風立ちぬ。」は喜成分が多いみたいですね。
実装
目的
青空文庫の作品URLが与えられると、感情を軸にとったレーダーチャートが出力されるようになる
作業環境
Google colaboratory
実作業
日本語の図示ができるようにする
デフォルトだと、google colabratory上でmatplotlibを使った日本語ラベルは文字化けしてしまいます。そのため、日本語をプロットできるようにフォントのダウンロードとキャッシュの削除を行いました。削除後はいったんランタイムを再起動すると反映されます。
!apt-get -y install fonts-ipafont-gothic
!rm /root/.cache/matplotlib/fontlist-v310.json
!rm /root/.cache/matplotlib/fontList.json
# ランタイムを再起動
感情辞書のダウンロード
次に今回感情表現を抽出するために使用する感情辞書のダウンロードを行いました。こちらはML-Askにて公開されている、The 3-Clause BSD Licenseに則ったオープンソースの辞書になります。
!wget http://arakilab.media.eng.hokudai.ac.jp/~ptaszynski/ccount/click.php?id=3 -O emotions.zip
!unzip emotions.zip
zipファイルをダウンロードして、展開が終了すると以下のような出力が表示されます。こちらを確認すると作業ディレクトリ下のemotionsディレクトリ下に複数のテキストファイルが保存されていることがわかります。それぞれが、**"哀", "恥", "怒", "嫌", "怖", "驚", "好", "昂", "安", "喜"**に対応していて、ファイル内にはその感情に該当する語句が保存されています。
Archive: emotions.zip
creating: emotions/
inflating: emotions/aware_uncoded.txt
inflating: emotions/haji_uncoded.txt
inflating: emotions/ikari_uncoded.txt
inflating: emotions/iya_uncoded.txt
inflating: emotions/kowa_uncoded.txt
inflating: emotions/odoroki_uncoded.txt
inflating: emotions/suki_uncoded.txt
inflating: emotions/takaburi_uncoded.txt
inflating: emotions/yasu_uncoded.txt
inflating: emotions/yorokobi_uncoded.txt
aware_uncoded.txtの内容を確認してみると、各行に「哀」に分類された単語が記述されていることがわかりました。
!head emotions/aware_uncoded.txt
胸が引き裂ける
しゃくりあげる
涙に掻き暮れる
顔を曇らせる
じいんと来る
泣き分かれる
泣きじゃくり
泣きじゃくる
しゃくり泣き
しゃくり上げ
感情辞書データの読み込み
それでは、無事に辞書のダウンロードができたことを確認したので、python上で扱えるようにデータを読み込みます。そのために以下のような関数を定義しました。
各感情ごとに分かれた語句群を1つのdict形式に変換して返します。
def get_emotional_words():
emotions = ["aware", "haji", "ikari", "iya", "kowa", "odoroki", "suki", "takaburi", "yasu", "yorokobi"]
emotional_words = {}
for emotion in emotions:
emotional_words[emotion] = []
with open("emotions/" + emotion + "_uncoded.txt", "r") as f:
for line in f:
line = line.replace('\n','')
emotional_words[emotion].append(line)
return emotional_words
青空文庫の作品データの取得
さて、次は内容を確認したい作品データを引っ張ってきます。
青空文庫のデータはgitでも公開されているのですが、今回はhtmlからデータを取得してきました。
2年ほど前の自分の記事での経験を生かして前処理をある程度施してデータを取得できるようにしています。
def get_txt_from_aozorabunko(url):
html = urllib.request.urlopen(url=url)
soup = BeautifulSoup(html, "html.parser")
# 本文を取得する → <div class="main_text">~本文~</div>
sentences = soup.find("div","main_text")
# 文字部分のみを抽出する
sentences = sentences.get_text().replace("\r", "").replace("\n", "").replace("\u3000", "")
# 全角の括弧に囲われた文字と括弧を除去(ルビが括弧文字として存在するため)
sentences = re.sub("(.*?)", "", sentences)
return sentences
感情分析
さて、辞書の読み込みと作品のテキストデータの取得が可能になったので、感情分析の関数を作成します。
今回は辞書ベースの手法を採用して、比較的簡易的な手法で感情分析を実施しました。
具体的には、作品のテキストデータ内に感情辞書内に含まれている単語数をカウントするというものです。
実際のコードがこちらになります。
def count_emotional_words(sentences, emotional_words):
count_emotions = [0] * len(emotional_words.keys())
for idx, emotion in enumerate(emotional_words.keys()):
for word in emotional_words[emotion]:
count_emotions[idx] += sentences.count(word)
return count_emotions
レーダーチャートにする
最後に取得された感情表現単語の出現頻度をレーダーチャート化するコードを作成します。コード作成にあたりこの記事がかなり参考になりました。ありがとうございます。
labelsに感情名のリスト、valuesにcount_emotional_words関数で受け取った感情表現単語の頻度を入力します。
def plot_polar(labels, values, title):
jp_font = {'fontname':'IPAGothic'}
angles = np.linspace(0, 2 * np.pi, len(labels) + 1, endpoint=True)
values = np.concatenate((values, [values[0]])) # 閉じた多角形にする
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, values, 'o-') # 外枠
ax.fill(angles, values, alpha=0.25) # 塗りつぶし
ax.set_thetagrids(angles[:-1] * 180 / np.pi, labels, fontsize=15, **jp_font) # 軸ラベル
ax.set_rlim(0 ,max(values))
ax.set_title("「" + title + "」", fontsize=15, **jp_font)
実行
最後にmain関数で実行します。このmain関数に青空文庫のURLと作品名が与えられると、冒頭のようなレーダーチャートが出力されます。
def main(url, title):
sentences = get_txt_from_aozorabunko(url)
emotional_words = get_emotional_words()
count_emotions = count_emotional_words(sentences, emotional_words)
emotional_kanji = ["哀", "恥", "怒", "嫌", "怖", "驚", "好", "昂", "安", "喜"]
labels = list(emotional_kanji)
values = count_emotions
plot_polar(labels, values, title)
実行例
実際に、太宰治作「人間失格」を入力してみました。
# 青空文庫の作品URL
ningen_shikkaku = "https://www.aozora.gr.jp/cards/000035/files/301_14912.html"
main(ningen_shikkaku,"人間失格")
無事作品の感情の傾向をレーダーチャート化することができました!
結果
作品ごとの傾向
冒頭の出力例を再度確認してみましょう。
「人間失格」を軸にすると、「風立ちぬ。」はかなり明るい作品であるという印象を受けますね。
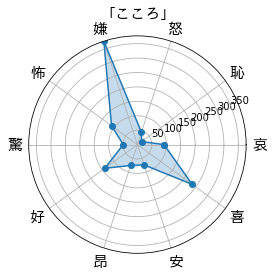
いっぽう「こころ」は全体的な雰囲気は「人間失格」と似ていますが、好成分が大きいので恋愛成分が強めかもしれません(どちらも色恋の話は出てきますが、「こころ」のほうが素直な感情表現であったきがします)。
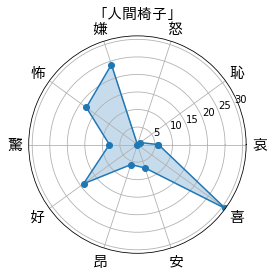
一方、江戸川乱歩作「人間椅子」は、その不気味な世界観からか怖成分が他の作品より大きい傾向にあることが推測できます。
終わりに
所感
いろんな作品のレーダーチャートを見るの楽しい(走れメロスは哀成分が意外と多かったりします)
辞書ベースの簡易な手法でも分析できた
日本語感情辞書少ない(今回利用したものとSNOWくらい)
これもしたかった
Webツール化(ブラウザから実行できるとかっこよかったなって)
辞書の再編(10種類の感情表現は若干多いので5種類くらいにまとめたものを作る)
物語の序盤と終盤での違いを可視化してみる(物語の展開が見えてきそう!)
次のアドベントカレンダーは
明日はyoshitsugumiyazakiさんで「AI関連気になることをまとめる可能性が高い」とのことです。
引き続きAIネタですね。どんな内容がまとめられるのか楽しみです!