青空文庫で隠れた人気作品を見つけたい
きっかけ
現在,青空文庫(https://www.aozora.gr.jp/) 上では様々な著者の著作権切れの作品を無料で読むことが可能になっている.私自身手元に新しい本が無いときなど頻繁に利用している.ある時,私は青空文庫にアクセス数ランキングがあることを知り,
「これをどうにかして解析すれば知る人ぞ知る作品にたどり着けるのではないか?」
と考え実行に移した.
目標
青空文庫のアクセスランキングはhtml版とtxt版に分かれており,月ごとの結果と年間を通しての結果が保存されている.2018年4月現在では2017年通年のランキングが最新のものとなっている.例えばhtml版にもtxt版にもランキングに上がっている作品は比較的著名な作品であると考えることができる.そのため,とりあえず最新のアクセス数ランキングから重複しない作品をhtml版とtxt版それぞれから抽出することを検討した.
作業環境
OS:windows10
言語:Python3
Jupyter上でコマンドは実行
ついでに作品の長さも知りたい
そもそも,青空文庫にはそれぞれの作品がどの程度の長さなのかは明示されていない.一応ファイルサイズは表記されているのだが読者としては大体何分で読み終わるのかを知りたい.そのため,まず作品のhtmlファイルへのリンクから本文のテキスト量を抽出して推定読書時間(分)を出力するプログラムもpythonで作成した.
# coding: utf-8
def exp_length(url):
import urllib.request
from bs4 import BeautifulSoup
import re
# アクセスするURLを決定しhtmlデータを取得する.下のリンクは入力例
#url = "http://www.aozora.gr.jp/cards/000148/files/789_14547.html"
response = urllib.request.urlopen(url)
data = response.read()
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(data, "html.parser")
try:
# 本文を取得する → <div class="main_text">~本文~</div>
sentences=soup.find("div","main_text")
# 文字部分のみを抽出する
sentences=sentences.get_text().replace('\r','').replace('\n','')
# 想定読了時間(分)に整形する
Time=round(len(sentences)/300)
except:
Time=None
finally:
return Time
ランキングデータの取得
次にランキングデータを取得する.とりえあず2017年通年のアクセスランキングから題名と著者,ランキング,アクセス数,推定読了時間をcsvファイルにして出力するプログラムを作成した.
# coding: utf-8
import urllib.request
from bs4 import BeautifulSoup
import re
from exp_length_v2 import exp_length
import pandas as pd
aozora_url="http://www.aozora.gr.jp/cards/"
# アクセスするURLを決定しhtmlデータを取得する
ranking_url='http://www.aozora.gr.jp/access_ranking/2017_xhtml.html' # 2017 html
# ranking_url='http://www.aozora.gr.jp/access_ranking/2017_txt.html' # 2017 txt
response = urllib.request.urlopen(ranking_url)
data = response.read()
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(data, "html.parser")
# それぞれの作品のテーブルを抽出
tables=soup.body.findAll(valign='top')
tables=tables[1:]
# 題名,著者,順位,アクセス数,推定朗読時間をリストにして保存
Lists=[]
count=0
for table in tables:
count=count+1
print(count)
link=table.find('a').get('href')
title=table.findAll('td')[1].get_text().replace('\n','')
author=table.findAll('td')[2].get_text()
rank=table.findAll('td')[0].get_text()
access=table.findAll('td')[3].get_text()
check_cards=link.find('/cards/')
# 作品リンクのみ抽出
if check_cards>-1:
story_cards_url=link
# アクセスするURLを決定しhtmlデータを取得する
response = urllib.request.urlopen(story_cards_url)
data = response.read()
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(data, "html.parser")
Cand=soup.find('table',summary='ダウンロードデータ').findAll('a')
for cand in Cand:
if cand.get('href').find('.html')!=-1:
story_url=story_cards_url[:37]+cand.get('href')[2:]
Lists.append([title, author, rank, access, exp_length(story_url)])
# pandasのデータフレーム形式に変換してcsvファイルで出力する
df=pd.DataFrame(Lists,columns=['題名','著者','ランキング','アクセス数','推定読了時間'])
df=df.sort_values(by='推定読了時間',ascending=True)
df.to_csv("Ranking2017html_v2.csv", index_label=None,index=None,encoding="utf-8")
# ユニコードの特殊文字があるので,excelで開く際にはデータのインポートから行う
print('done')
実際にデータを見てみる
さて,実際に取得したデータを見てみよう.まずデータを図示できるように整形した.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 保存した2017年のアクセスランキングのデータをhtml版,txt版取得する
df1=pd.read_csv("Ranking2017html_v2.csv", header=None, encoding="utf-8").dropna()
df2=pd.read_csv("Ranking2017txt_v2.csv", header=None,encoding="utf-8").dropna()
# データ型をfloatへ変換
htmls=df1[4].values
htmls=htmls[1:]
htmls_a=df1[3].values
htmls_a=htmls_a[1:]
for idx,html in enumerate(htmls):
htmls[idx]=float(html)
htmls_a[idx]=float(htmls_a[idx])
txts=df2[4].values
txts=txts[1:]
txts_a=df2[3].values
txts_a=txts_a[1:]
for idx,txt in enumerate(txts):
txts[idx]=float(txt)
txts_a[idx]=float(txts_a[idx])
次に縦軸をアクセス数,横軸を想定読了時間にしてそれぞれの作品を散布図上にマップしてみた.
%matplotlib inline
# アクセス数と文章量(推定読了時間)を軸にした散布図
plt.scatter(htmls,htmls_a)
plt.scatter(txts,txts_a)
plt.xlabel('Estimated reading time')
plt.ylabel('The number of access')
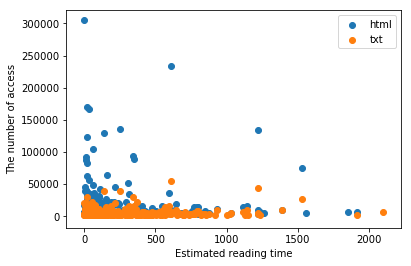
短編作品が比較的人気なようだ.
次にそれぞれのランキングにしか存在しない作品を取得した.
# 二つのランキングで片方にしか存在しない作品を抽出
# HTML版にしか存在しない作品
independ1 = df1[~df1[0].isin(df2[0])].dropna()
# txt版にしか存在しない作品
independ2 = df2[~df2[0].isin(df1[0])].dropna()
とりあえずランキング上位5つを表示してみる.
html版
independ1.sort_values(by=2,ascending=False)
| title | author | ranking | access | reading time |
|---|---|---|---|---|
| 星めぐりの歌 | 宮沢 賢治 | 73 | 17720 | 0 |
| 戦争責任者の問題 | 伊丹 万作 | 51 | 24004 | 24 |
| ダゴン | ラヴクラフト | ハワード・フィリップス | 500 | 3447 |
| 内田百間氏 | 芥川 竜之介 | 499 | 3455 | 2 |
| 愛の詩集02 愛の詩集のはじめに | 北原 白秋 | 498 | 3459 | 24 |
html版でしかあまり読まれていない長編作品があるのかも見てみる.
independ1.sort_values(by=2,ascending=False)
| title | author | ranking | access | reading time |
|---|---|---|---|---|
| パソコン創世記 | 富田 倫生 | 262 | 6141 | 1854 |
| 土 | 長塚 節 | 387 | 4334 | 1557 |
| イーリアス03 | イーリアス ホーマー | 371 | 4463 | 1264 |
| 小桜姫物語03 小桜姫物語 | 浅野 和三郎 | 417 | 3961 | 867 |
| 万葉秀歌 | 斎藤 茂吉 | 412 | 3992 | 831 |
意外にもかなり長い作品が浮上した.年間6000回はアクセスされているようだ.
気になりますね.「パソコン創世記」.
txt版
まずはアクセス数の多い順で見てみる.
independ2.sort_values(by=3,ascending=False)
| title | author | ranking | access | reading time |
|---|---|---|---|---|
| あさましきもの | 太宰 治 | 39 | 10757 | 6 |
| 三国志04 草莽の巻 | 吉川 英治 | 55 | 8402 | 548 |
| 三国志06 孔明の巻 | 吉川 英治 | 67 | 7856 | 592 |
| 三国志05 臣道の巻 | 吉川 英治 | 70 | 7808 | 573 |
| 三国志07 赤壁の巻 | 吉川 英治 | 73 | 7685 | 595 |
まさかの太宰治の短編作品がランクイン.「あさましきもの」覚えました.他作品は三国志のようだ.
一方でtxt版でしか読まれていない短編作品はどのような作品があるだろうか.
independ2.sort_values(by=4,ascending=True)
| title | author | ranking | access | reading time |
|---|---|---|---|---|
| レ・ミゼラブル03 序 | ユゴー ヴィクトル | 245 | 3275 | 1 |
| 断腸亭日乗01 〔はしがき〕 | 永井 荷風 | 494 | 1996 | 1 |
| 『吾輩は猫である』下篇自序 | 夏目 漱石 | 273 | 3064 | 2 |
| 大切な雰囲気01 序 | 谷崎 潤一郎 | 435 | 2224 | 2 |
| 兄貴のような心持——菊池寛氏の印象—— | 芥川 竜之介 | 493 | 1998 | 3 |
前書きが多い様子.
結論
アクセスランキングデータを比較することでhtml版やtxt版のそれぞれで限定的に人気な作品を抽出することができた.
特に,html版はブラウザ上で読むことができるので短編作品ばかりが人気かと思いきや,「パソコン創世記」や「土」のような長編作品もランクインしている.
一方txt版では一度ダウンロードして他の媒体で読むことが可能なため,長編作品ばかりが人気かと思いきや「あさましきもの」が堂々のトップアクセスを飾っていた.
ランキングデータを取得してみると意外と面白い発見ができたのであった.
今後の予定と雑記
実は「あさましきもの」が何故あそこまでtxt版で人気なのか気になって仕方がなかったので,少し解析してみたものを次回まとめる予定.
pandasで出力した表を打ちなおすが非常に手間だったので簡単にコピーできないか検討中.
今回が初投稿です.ご意見ご質問お待ちしています.