はじめに
- これは、「富士通クラウドテクノロジーズ Advent Calendar 2019」 の13日目の記事です。
ところで
今日は12月13日、金曜日です。
こういう日には本番系へのメンテナンスをしてはいけません。
-
13日だから
- いいえ、特にサービスとして制約がない限り、月半ばのメンテナンスは月初月末のそれに比べスケジュールとして適切です。
-
12月だから
- はい、年末に大きなメンテナンスを行うことは多くの場合忌避されます。
- ただし、年末の利用者が減少するタイミングをあえて指定される場合もあります。
-
金曜日だから
- はい、土日のお休みを目前とする時に急を要さないメンテナンスを行うべきではありません。
- そもそも、急を要すメンテナンスなんて大抵ろくなもんじゃないので潔く週明けにずらすべきでもあります
-
13日の金曜日だから
- はい!
- こんな不吉な日にメンテナンスをやるなんてもっての外です!
- だめ!
- さっさと仕事を切り上げてフレックス退社して肉を焼くのが吉です
- 僕らのチームは今日、忘年会です。障害が起きませんように!
-
ちなみに令和元年12月13日 は先負です
- だからといって午後にメンテすればいいわけではありません
余談ですが
- みなさんの職場ではスピリチュアルエンジニアリングは採用されていますでしょうか?
- 例: 13日の金曜日を避ける
- 例: 六曜を気にする
- 例: 障害が続くとお祓いに行く
- ただしIT情報安全守護の御利益に対しては懐疑的である
- 例: 本番環境を触る時に神に祈る必要がある
- 例: IPペイロードにありがとうという言葉を入れるとドロップされないんですよ!
- 例: あいつがスイッチにログインするといつも壊れる
- 例: 障害はいつも夜中に起こる
- 例: 実際に確かめたわけでもないのに宇宙線を障害原因にした
ここまで全て、記事のテーマとは関係ありません。
主題
- この記事では、自分の担務において、今年発生した障害のうち一番影響が大きくかつ印象に残った件について振り返り、また社内でどのような対応と対策をしてきたか、まとめたいと思います。
- 注
- この記事は、事実と個人の感想が入り交じった、いち運用担当者の振り返りと感想まとめです。
- 事実については公開済みの情報に沿って記載しますので、機種名や根本原因のロジック、具体的な対策など重要な部分が詳述できていないと感じると思われます。
- 突然記事の内容が変わるかもしれません。
- 本記事のカレンダー枠は
"今年起こした障害の話を書きます 怒られたら剣盾の進捗でも書きます"として確保しています。ちなみにこの前ガラル地方のポケモンマスターになりましたのでそちらについても記載できたらよいですね。
概要
- 件の障害とは、 この件 です。
- 発生時間
- 2019/03/22(金)11:32 ~ 2019/03/23(土)11:13
- 影響箇所(サービス)
- パブリック型クラウドサービス「ニフクラ」の east-3 リージョン全体
- 発生箇所(基盤)
- ネットワーク機器を集約するコアスイッチにおける故障
- 影響内容
- 仮想サーバ(VM)の通信不可
- NAS, RDB等各種サービスの利用不可
- コントロールパネル / API利用不可
- 原因
- 影響1 に対して
- コアスイッチのハードウェア故障
- 影響2, 3 に対して
- 長時間の通信断発生に起因するクラウド基盤の動作異常の発生
- 影響1 に対して
- 発生時間
発生
- 発生時刻としている2019/3/22 11:32 の4分前、コアスイッチ の片系に故障が発生し、縮退稼働となる
- 4分後の11:32、残った片方においても故障が発生し、両系停止となったことから通信疎通不可が発生。east-3 リージョン全体においてサービス利用不可となる。
ニフクラの リージョン についてはニフクラ公式サイトの リージョン/ゾーン を参照ください。
他のパブリッククラウドと同様に、マルチリージョン対応となっており、東日本では4拠点展開しております。
今回の障害では、東日本4拠点のうちのひとつであるeast-3 において、サービス全停止が発生しました。
で、この障害に真っ先に着手したのが自分なんですが、慌てて社内Slackに叩き込んだ文章が下記になります。
助詞が変なところに焦りが見えるんですが、後述の振り返りプレゼンでもたくさんこのpostが引用されてて恥ずかしかったです。

対応
- 11:32の障害発生を確認し次第、機器交換を準備
- 11:41 にInformationとして障害情報を掲載
- 14:57 機器の交換が完了し、通信の復旧を確認
- 以降翌日11:13 まで、長時間の通信断によるサービス基盤への異常発生有無や復旧作業を実施し、各種サービスが段階的に復旧
ニフクラの可用性としては、 ニフクラの可用性向上への取り組み のページに記載しているように、ネットワークを含めた全ての構成コンポーネントについて冗長構成を取っています。
本件については、この冗長を乗り越えてくる両系断障害が発生したため、長時間のサービス停止となりました。
11時半の発生から15時の通信復旧まで3時間半と長時間に及びましたが、ネットワーク機器のハードウェア障害ということから物理交換が必要となり、機器手配から環境投入まで最速で進めた結果このような時間となりました。
機器故障について
リージョン毎に若干の差異はありますが基本的には、お客様がご利用になるVMが稼働する物理サーバとそのデータを格納する物理ストレージ、それをつなげるネットワーク機器という構成になっています。
下図の通り、この障害ではそれらをつなげる機器が両系故障したため、物理サーバにとってマウント先のストレージが消失したように見え、異常な状態になったことから物理レイヤから仮想レイヤまでに至り正常性確認と復旧作業に時間を要し、全サービスの完全復旧まで丸1日を費やすこととなりました。
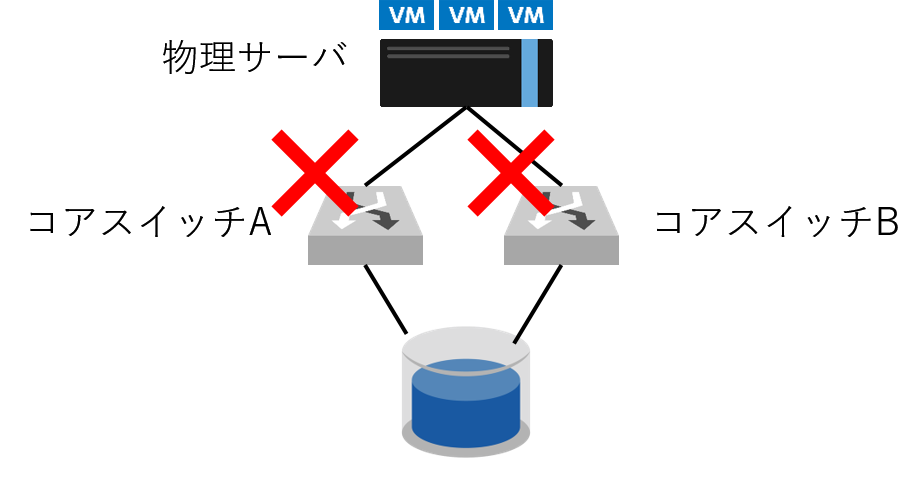
完全に余談ですがこの図のようなアイコンは、 ニフクラ アイコン&シンボルについて のページで公開されています。いい感じの構成図を作るのが楽にできて好きです。
根本原因と対策
後日の詳細解析の結果、スイッチ内部のハードウェア故障による処理異常と判明しました。
ベンダーと協力し継続した調査の結果、この故障に対するソフトウェア観点での抑制方法が判明しましたが、ニフクラとしては初めての発生となった両系故障を重く受け止め、ハードウェアの予防交換を実施し、さらに従来の冗長構成よりさらに安全性の高い構成の実現を推進しています。
振り返りの実施
本障害のような重大障害に限らず、発生した障害やトラブル未遂事象については常に運用チーム内外で追跡と振り返りを行っております。
一方で本件は過去に例を見ない大障害であったことから、事後対応も少しずつ収束してきた2ヶ月後に社内全体での振り返りの場が設けられました。
弊社では定期的に社内でのLT大会を行っています。
テーマは業務内容に限らず(関係ないことの方が多い)、また発表者聴講者も担務や役職に分け隔てありません。
この回のテーマは障害であることからいつもよりすこし真面目な雰囲気はありましたが、ピザを片手にいろいろな立場からの当日の対応や振り返りを共有したことでそれぞれの視点での発生当日の状況を振り返ることができたと感じました。
(運用系の発表テーマは公開できないので塗りつぶしちゃいましたが、技術の話だけによらない、事業全体としての発表が行われていることが読み取れると思います)
(ちなみにLT大会は業務時間として扱われています)
障害対応訓練
この障害が発生する以前からの話ではあるのですが、弊社では重大障害を想定した障害対応の訓練を定期的に行っています。
基盤・プラットフォーム・サポート・セールス・広報といった会社全体で、実働部隊とマネージャー、取締役も参加する規模の大きな訓練です。
大規模障害が発生すると、運用担当は当然復旧作業に集中するわけですが、これに固執してしまうとしばしば状況や進捗の社内外への展開が不足し、内部連携もインフォメーションの公開も遅れることになり、ユーザーの皆様からは対応が見えないとしてお叱りを頂くことになってしまいます。
技術者は復旧対応に専念し、それでいて情報の吸い上げや展開が迅速に行われるような理想的な対応の実施や体制作りに、この訓練は寄与していると思います。
次回の訓練実施は仕事納め直前です!
本気の障害で年を越す羽目にならないよう、訓練で総まとめしたいと思っています。
障害について
この節は完全に感想です。
弊社に限らず、今年はクラウド系サービスの大規模障害により世間へ大きな影響を与えたニュースが多かったように思います。きっと今も、復旧のために継続対応している方々がいるんだろうと思います。
2019年のハイプサイクルでは2018年と同様、クラウドコンピューティングは啓蒙活動期に位置していましたが、最近では公共系や金融系といったような社会・生活インフラそのものにもクラウドが採用されるニュースが散見され、このような分野で当然にクラウドが用いられるようになっていると改めて感じました。
インフラはクラウドであり、クラウドはインフラであるという世の中において、その安定稼働が使命である我々は、今回記載したような障害をはじめとした経験から振り返りを得て、未来の運用につなげていくことを継続していくことこそが大事だと思っています。
その一方で、運用する側としても利用する側としても、障害は起こるもの、という認識を持った上で、サービスの重要度に応じて対策や回避策を設計していくことが、もしもの時に影響を極小化することにつなげられると思います。ニフクラにおいても、 サービスレベル目標(SLO) の定義や品質保証制度(SLA) の案内を行っています。
最後に
今日は13日の金曜日です。
きっとなにも起きないとは思います。
が、ろくでもないことに巻き込まれる前にさっさと帰ることにいたしましょう。
とは言えそれでも対応せざるを得ないなら、とっととしばいていきましょう。安定稼働万歳!
本日もご安全に!

明日の記事のテーマは @e10persona の 青空文庫を使って言語処理系の記事書きます とあります。
全然関係ないんですが、彼の社内Slackのアイコンは焼き肉の写真でして、見る度に犯罪的だと思って僕は憤慨しています。
あと、今日はホロライブの百鬼あやめちゃんの誕生日です。
飲み会に行っとる場合ではないぞ!