この記事はNTT ドコモソリューションズ Advent Calendar 2025 の 21 日目の記事です。
はじめに
こんにちは、NTT ドコモソリューションズ 技術革新本部 クラウドテクノロジセンタの木村です。普段は生成 AI に関する業務に従事しています。
【AWS re:Invent 2025】初参加で役立った持ち物「3種の神器」と英語・予約攻略ハック 3 選 に続き、re:Invent 2025 へ参加した総括を記事にいたします。
2025 年に AWS 認定資格の 12 冠を達成し、ラスベガスで開催された AWS re:Invent 2025 に初参加してきました。今年の re:Invent は、生成 AI が単なる「新しい技術トレンド」から「クラウドコンピューティングの核」へと完全にシフトしたことを象徴するイベントでした。
自身のテーマは 「AI 基盤のSelf-Hosted LLM × AWS Managed AI」の知見獲得 です。
Bedrock のようなマネージドサービスは強力ですが、特殊な要件に合わせた LLM の Self-Hosted が必須のケースに向けては、EKS や Ray、そして AWS 独自チップ(AWS Trainium)を組み合わせた「下回り(インフラ層)」の知識が不可欠だからです。
5 日間で 10 セッション(Jam やワークショップを含む)に参加し、講師やサポーターを質問攻めにして得た「ドキュメントにはない現地情報」 を中心に、次世代 AI プラットフォームのアーキテクチャを主軸に受講セッションを紹介します。
本記事は、セッションで伺った内容をもとに、筆者の理解・解釈を加えてまとめています。
そのため、登壇者の意図と異なる部分や誤りが含まれる可能性があります。あらかじめご了承ください。
re:Invent 受講セッション
re:Invent のセッションは 3,000 以上あり、うち 1,000 以上は AI/ML 関連のセッションです。1/3 程度は AI 関連のセッションになります。現地に 6 万人以上が集まり、オンラインでは 200 万人近くが視聴していました。

出典:Google LLC, NotebookLM生成スライド(参照日:2025年12月11日)
自身が re:Invent で受講したセッションの一覧です。
全てのセッションはレベル 300 - Advanced(上級) 以上です。
AWS のコンテンツレベルは、100(初級)、200(中級)、300(上級)、400(専門家/エキスパート)があります。
| Day | タイトル | 時間 | 概要 |
|---|---|---|---|
| 1-1 | Build and scale agents with Amazon Bedrock AgentCore & Strands Agents | 2h | Strands SDK と Amazon Bedrock AgentCore を用いたエージェント開発、認証管理、オブザーバビリティの実装 |
| 1-2 | Build production-ready AI solutions with Claude in Amazon Bedrock | 2h | セキュリティ・信頼性・コスト最適化を考慮したエンタープライズ向けAI設計 |
| 1-3 | Paper to production: Hosting LLMs on Amazon EKS using NVIDIA GPUs | 2h | EKS上でのMistral-7B運用。vLLMとRay Serveによる分散推論、Nvidia ツールでのオブザーバビリティ |
| - | Opening Keynote with Matt Garman | 2.5h | Matt Garman 氏によるオープニング基調講演 |
| 2-1 | Inference on AWS Trainium and Amazon EKS using vLLM | 2h | AWS Trainium と EKS 上での vLLM 推論最適化。AWS Neuron ハードウェアによるスループットとコスト効率の最大化 |
| 2-2 | Accelerate AI model fine-tuning and deployment with SageMaker HyperPod | 2h | SageMaker HyperPod を用いた Qwen 3 モデルの微調整と、推論オペレーターによる EKS デプロイ |
| 3-1 | AWS GameDay: AI-Assisted Developer Experience ft. New Relic | 4h | 取り組んだ課題:Amazon Q と CloudWatch を用いたトラブルシューティング演習(Amazon Q の限界と手動解析の重要性を確認) |
| 3-2 | AWS Jam: Generative AI - Sponsored by Nvidia | 3h | 取り組んだ課題:Kiro を用いたコード脆弱性診断や、PCI DSS 要件(個人情報マスク)の実装課題 |
| 4 | Compact yet powerful: Exploring model distillation with AWS Trainium | 1h | AWS Trainium と AWS Neuron SDK を用いたモデル蒸留。大規模 MoE モデルから小規模モデルへの知識転移(チェス予測) |
| 5-1 | Build a multi-agent financial research assistant with Amazon Bedrock | 2h | スーパーバイザーと専門エージェントを組み合わせた、金融リサーチアシスタントの構築 |
| 5-2 | Build a multi-agent AI solution with Amazon Aurora & Bedrock AgentCore | 2h | MCPとLangGraph、Aurora PostgreSQLを用いた、レガシーアプリ近代化のための協調型 AI 構築 |
Keynote を除くと 10 セッション受講しました。
全て AI に関するハンズオンで、内訳の 40 % ほどは Self-Hosted 基盤 LLM に関するセッションで、40% はマネージドの AI サービス、残る 20% は GameDay や Jam といった与えられた課題をクリアしながら学習する競技形式のハンズオンを受講しました。

出典:Google LLC, Google Gemini生成画像(参照日:2025年12月11日)
Day 1: Amazon Bedrock AgentCoreでのエージェント開発とEKS × Rayによる分散推論
ラスベガスにいる間は早起きでした。
普段も朝活派で、夜 9 時には寝ています。
1日目のスケジュールです。初日はワークショップを 3 つ受講しました。

Day1-1. Build and scale agents with Amazon Bedrock AgentCore & Strands Agents
【エピソード】
今回のワークショップ環境は SageMaker AI JupyterLab で行われました。Bedrock の基礎から触り、ハンズオン内容 + 気になるところを確認しながら作業を進めました。隣に座っていた参加者が、講師に「Amazon Bedrock AgentCore のオブザーバビリティ」について質問をしていました。しかし、質問が多く、時間の兼ね合いで詳細はスキップされてしまいました。
少し消化不良そうな様子でしたので、自身が先回りして事前に調査していたポイントをレクチャーしたところ、非常に喜んでもらえました。面白いもので、そこから意気投合し「次のセッションはどれに行くんだ?」と聞かれ、最終的にその彼を含めた 2 人が、自身の次の受講セッションについてきました。
言葉や国境を超えて、技術という共通言語で繋がれるのも、現地参加ならではの醍醐味だと感じた瞬間でした。
【セッションの内容】
内容自体は、Strands SDK と Amazon Bedrock AgentCore を用いたエージェント開発、認証管理、オブザーバビリティの実装を行いました。 5 つの Lab を通して学びました。自身は Agent Core をこのときに初めて触りましたので、マネジメントコンソール上でランタイムを確認しつつ行いました。Amazon CloudWatch と AWS X-RAY のメトリクス確認もしました。ハンズオンでは JupyterLab 側の画面しか使いませんでしたが、個別にマネジメントコンソールで設定内容を確認しながら作業を進めたのが良かった点です。 図の通り、内容は盛りだくさんです。
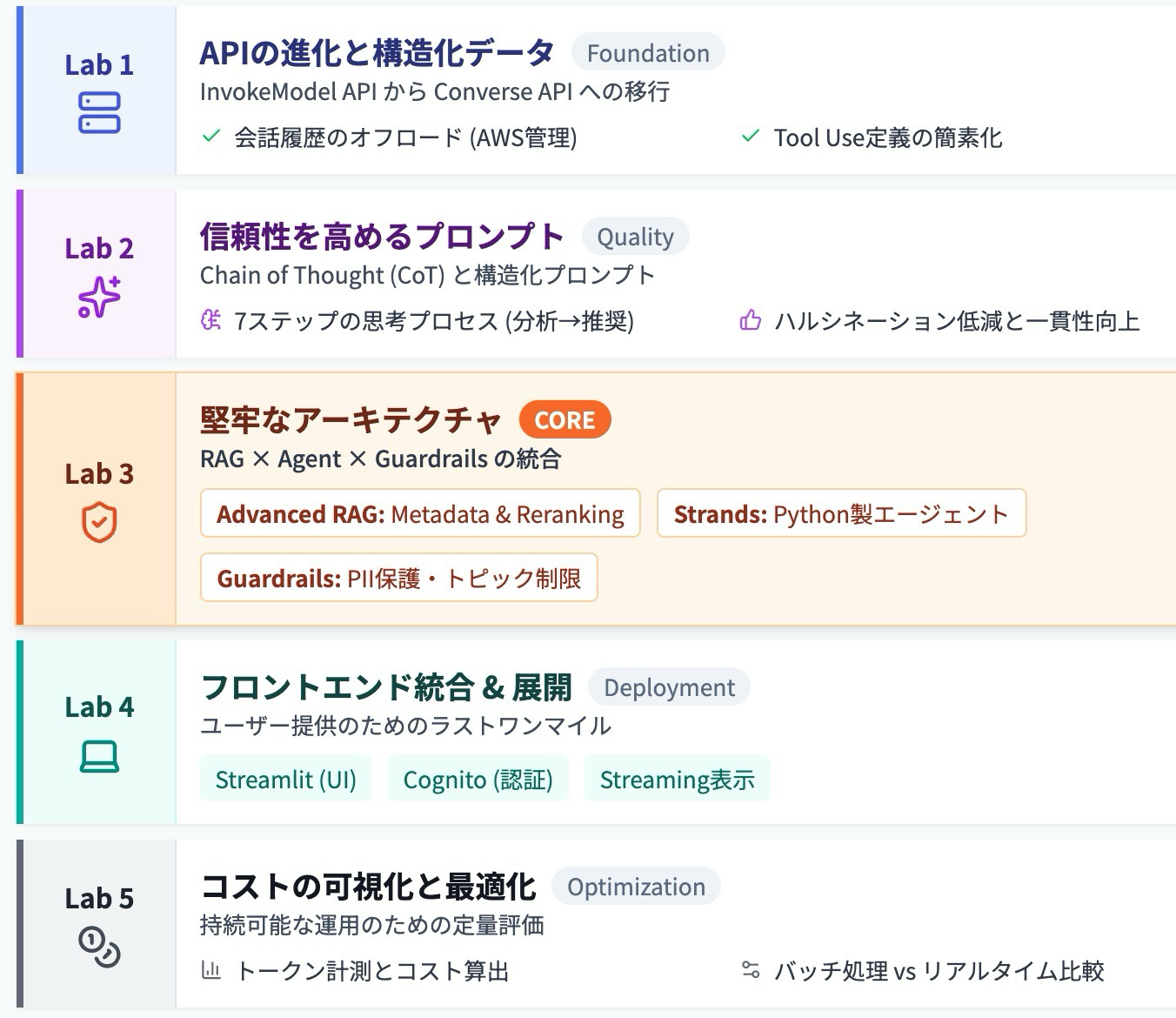
アーキテクチャです。Amazon Bedrock AgentCore で長期記憶や認証、オブザーバビリティを実装しました。フロントは Streamlit です。
Day1-2. Build production-ready AI solutions with Claude in Amazon Bedrock
【エピソード】
前のセッションの 2 名が Walk-in(当日枠)の列で待っていました。自身は Reserved(予約済み) でしたので、手を振って軽く挨拶して一足先に着きました。その後も LinkedIn で、その方から受講セッション情報について求められ、情報を共有していました。
このセッションでは、日本人の方が 2 名同じテーブルにいました。Amazon Bedrock AgentCore を実務で具体的にどう使えると考えられているか、意見交換をできました。「ハードウェアメーカーの売り切り型ビジネスとSaaSのビジネスモデルのギャップ」や「言葉の揺らぎ補正へのエージェント活用」など、それぞれの立ち位置から異なるリアルな悩みやユースケースを共有できたのも現地ならではの収穫でした。
また、午前の類似セッションを受けたため、同じサポーターと顔を合わせました。サポーターが自身の顔を覚えており、声をかけてくれました。セッションが始まるまでの間で、前のセッションの Q&A を行いました。類似セッションを受けると、サポーターとも仲良くなれて、質問もしやすく有益でいい感じです。前のセッションと今回受講セッションの類似点の質問をできます。別セッションであっても、シームレスにセッションを受けることができて有益です。
【セッションの内容】
Amazon Bedrock と Claude で構築する本番運用レベルの AI ソリューションについてのワークショップです。独自に作成した MCP サーバで、Cognito 認証が必要な社内システムへ安全に接続するハンズオンです。Supervisor が Amazon Bedrock AgentCore Gateway 経由で Specialist Agents を呼び出す最新の構成です。
生成 AI 活用の本丸である「エージェント」については、「Supervisor-Specialist(監督者と専門家)」 というアーキテクチャパターンが標準になりつつあります。

MCP (Model Context Protocol) と Amazon Bedrock AgentCore
以下の構成で外部ツールと連携する実装を行いました。
- Strands SDK: Pythonコード数行でエージェントのロジックを定義
- MCP (Model Context Protocol): 外部ツール(DBやAPI)を標準化されたインターフェースで接続。AWS Lambdaを用いてMCPサーバーを実装し、Cognito認証が必要な社内システムへの安全なアクセス経路を確立しました
- Amazon Bedrock AgentCore Gateway: 複数の専門エージェント(Specialist)を束ね、監督エージェント(Supervisor)から動的に呼び出せるようにする「ハブ」の役割を果たします
Day1-3. Paper to production: Hosting LLMs on Amazon EKS using NVIDIA GPUs
【エピソード】
このワークショップが、今回受講したセッションの中で最も難易度が高いと感じました。難しすぎて、サポーターを 30 分ほど確保して学習に努めました。英語で質問攻めにしました。翻訳ツールを最も駆使した会になりました。Tips の記事に翻訳ツールについてまとめた記載もありますので、翻訳ツールの活用法についてはre:Invent攻略ガイド の記事も併せてお読みください。ワークショップで vLLM を使っており、自身も vLLM が Ollama よりよいと理解していますが、敢えて Ollama ではダメなのかを質問しました。ディスカッションした結果、Ollama は SLM を扱う上では良いが、スケーリングできないため LLM には向かないという結論にいたりました。Karpenter と Ray の違いなども質問しました。超絶難易度が高いワークショップでしたが、クラウドネイティブな LLM プラットフォームの最前線を感じることができました。
【セッションの内容】
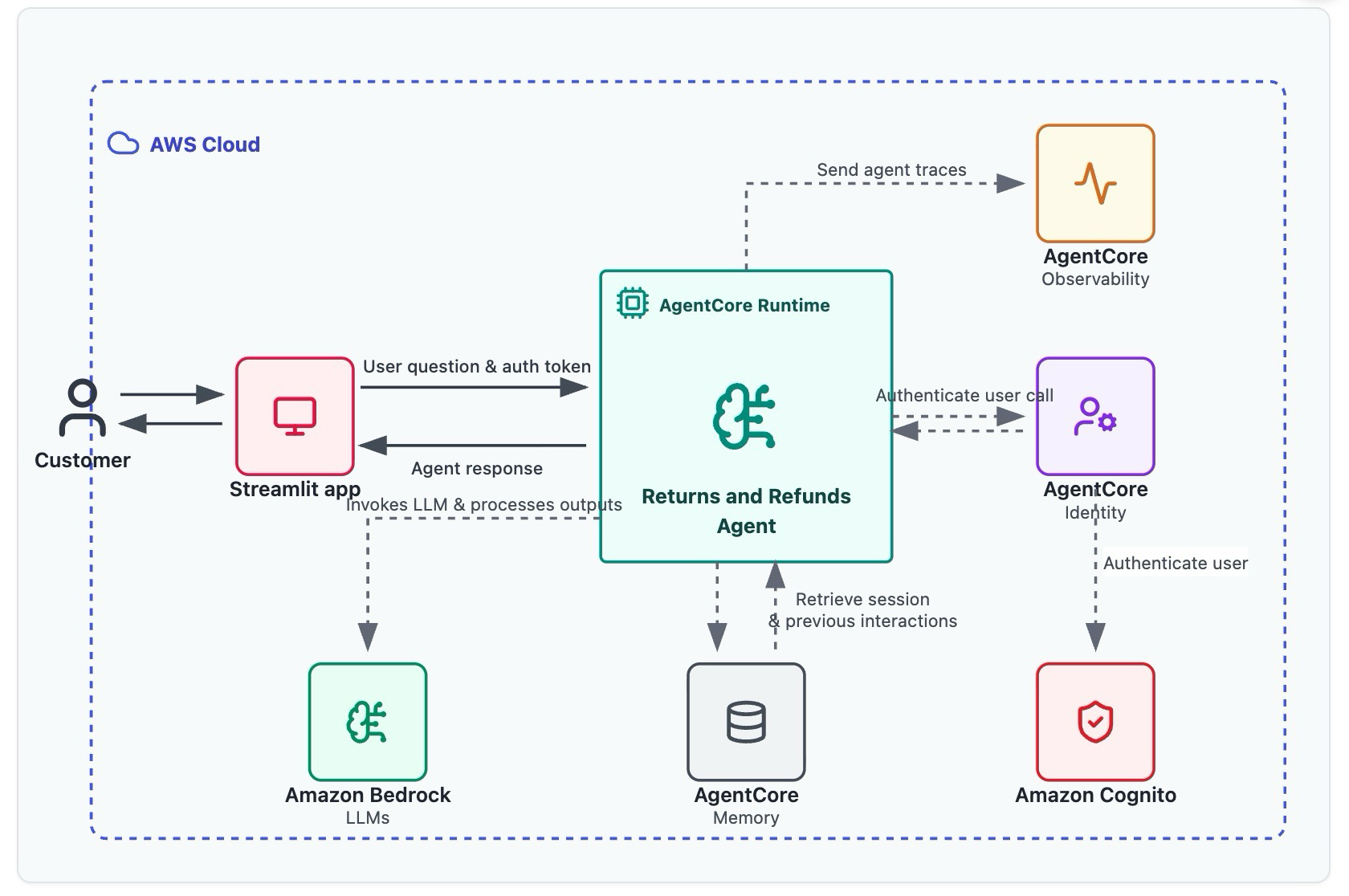
本番環境向け Self-Hosted LLM 基盤の一例:EKS × Karpenter × Ray
EKS 上での Mistral-7B を運用することに関するワークショップです。vLLM と Ray Serve による分散推論、Nvidia ツールでのオブザーバビリティ確保を行います。インフラのオートスケールは Karpenter で、アプリケーションレイヤは Ray でオーケストレーションします。各層のオートスケールツールは、連携したオートスケールはせず、分離された各レイヤにてオートスケールが可能です。
個人的には、実用性が高い構成だと考えています。
2 層のスケーリング戦略
セッションで提示されたのは、インフラ層とアプリケーション層で分離して、分散アーキテクチャを各層で実現するものでした。
-
インフラ層 (Scaling): Karpenter
- Podの要件に基づき、GPUノード(g6e.2xlargeなど)をオンデマンドで動的にプロビジョニング・デプロビジョニングします。これにより、高価なGPUリソースの無駄を極限まで省きます
-
アプリ層 (Orchestration): Ray
-
RayServiceを用いて、複数の GPU ノードにまたがる分散推論ワークロードを管理します
-
-
推論エンジン: vLLM
- PagedAttention 技術によりスループットを最大化します。ローカル開発では Ollama が手軽ですが、サポーターとの議論で 「Ollama はスケーリングできないため、本番の大規模 LLM には vLLM 一択」 という結論に至りました
EKS × Karpenter × Ray のイメージです。
オブザーバビリティの確保
EKS 上でブラックボックスになりがちな GPU の挙動も、以下のスタックで可視化します。
-
AWS Native:
neuron-monitorで AWS Neuron デバイスのメトリクスを収集 - OSS: Prometheus + Grafana + DCGM Exporter で GPU 温度や使用率を監視
-
CloudWatch Logs Insights:
pod_neuroncore_usage_totalなどのクエリを叩き、AWS Neuron Core が効率的に使われているかを監視
Day 2: AWS Trainium 3最新情報とvLLM最適化・SageMaker HyperPod 活用
2日目のスケジュールです。
現地にて Keynote を聴講し、ワークショップを2つ受講しました。

Day2-1. Inference on AWS Trainium and Amazon EKS using vLLM
【エピソード】AWS Trainium 3 は FP4 に対応
ワークショップのセッション中、AWS の独自シリコン「AWS Trainium」について、非常に重要な情報を得ることができました。ワークショップ自体は AWS Trainium 2 ベースでしたが、午前中の Keynote で AWS Trainium 3 が発表されたため、現地のサポーターにスペックを直撃しました。また、このときお会いしたサポーターの方は、ものすごく優秀な方だと感じました。AWS Trainium に AWS 社は人的リソースを割いているのではないかと感じたほどです。
結果、個人的には MXFP4 への対応が良いスペックアップだと思いました。
量子化モデル利用時は 4-bit モデルを使うことが多いためです。
FP4 への対応は、推論(Inference)においてゲームチェンジャーとなります。
モデルのメモリフットプリントを FP16 比で 1/4 に削減できるため、同一のハードウェアにより大きなモデルを載せるか、あるいはスループットを劇的に向上させることが可能です。その他の改善点に興味がある方は、こちら をご確認ください。
| チップ | FP8 対応 | MXFP4 (4-bit) 対応 |
|---|---|---|
| AWS Trainium 2 | ✅ | ❌ |
| AWS Trainium 3 | ✅ | ✅ (New!) |
出典:Amazon.com "Trainium3 Architecture" https://awsdocs-neuron.readthedocs-hosted.com/en/latest/about-neuron/arch/neuron-hardware/trainium3.html#neuroncore-v4 (参照日 2025年12月9日)
必須ツール:VRAM Calculator
モデル選定時のハードウェア要件(KV Cache等を含む)を計算する際、以下のサイトが非常に有用だと教えてもらいました。得たい情報は質問して足で稼ぐべきだと、改めて思いました。
- VRAM Calculator: https://apxml.com/tools/vram-calculator
【セッション内容】
AWS Trainium と EKS 上での vLLM 推論最適化や AWS Neuron ハードウェアによるスループットとコスト効率の最大化を目指すセッションです。生成 AI ワークロードの需要急増に伴い、推論コストの削減とスループットの向上はエンジニアにとっての課題です。AWS Trainium と vLLM を組み合わせることで、高性能な LLM 推論環境を構築できるだけでなく、CloudWatch Container Insights と AWS Neuron Monitor を統合することで、ハードウェアレベルまで踏み込んだ詳細なオブザーバビリティを手に入れることができます。これにより、エンジニアはパフォーマンスのボトルネックを迅速に特定し、推論コストを最適化しながら安定した生成 AI サービスを提供することが可能になります。
【用語集】
- AWS Trainium (Trn1/Trn2):生成 AI モデルのトレーニングと推論に特化した AWS の独自チップ
- vLLM: PagedAttention 技術による効率的なメモリ管理と高スループットを誇るオープンソースの推論エンジン
- Amazon EKS: コンテナ化されたワークロードのオーケストレーション。
- Amazon CloudWatch Container Insights: メトリクスとログの自動収集・可視化を提供するフルマネージドなオブザーバビリティソリューション
vLLM デプロイメントの詳細設定
Deployment マニフェストで、個人的に気になったポイントを抜粋して記載します。
- vllm の実行コマンドは以下
vllm serve /models/Qwen3-1.7B-tp4/ --tensor-parallel-size 4 --max-num-seqs 4 --max-model-len 2048 --override-neuron-config
value: "/models/Qwen3-1.7B-tp4/"
-
Startup Probe: LLM はモデルのロードに時間がかかるため、startupProbe を長めに設定(failureThreshold: 75 * 30s)し、準備ができるまで Kubernetes が Pod を再起動しないように制御
-
事前コンパイル: NEURON_COMPILED_ARTIFACTS を指定することで、実行時のコンパイル時間を排除し、高速な起動を実現
推論ワークロードのオブザーバビリティ
本番環境では、モデルが正常に動作しているか、チップのリソースを効率的に使用できているかを監視することが不可欠です。本ワークショップでは、CloudWatch Container Insights を活用した監視スタックを構築しました。
監視スタックの構成要素
EKS クラスター上の監視エージェントは以下の役割を担います。
- CloudWatch Agent: ノードおよび Pod レベルのメトリクス(CPU, メモリなど)を収集
- Fluent Bit: コンテナログを収集し CloudWatch Logs へ転送
- AWS Neuron Monitor: AWS Trainium/Inferentia ノード上で DaemonSet として稼働し、ハードウェアレベル(AWS Neuron デバイス)のメトリクスを Prometheus 形式(ポート9010)で公開
CloudWatch Container Insights ダッシュボード
CloudWatch コンソールでは、以下の視覚的な監視が可能です。
- クラスター概要: ノード、Pod、サービスの全体的な健全性
- コンテナマップ (Container Map): リソース間の関係性をトポロジーマップとして視覚化し、リソースのホットスポット(負荷が高い箇所)を直感的に特定可能
- AWS Neuron メトリクス: Node Neuron Core utilization などの用ウィジェットにより、アクセラレータの使用率を確認可能
CloudWatch Logs Insights による詳細分析
CloudWatch Logs Insights を使用してログデータをクエリすることで、より詳細な分析が可能です。
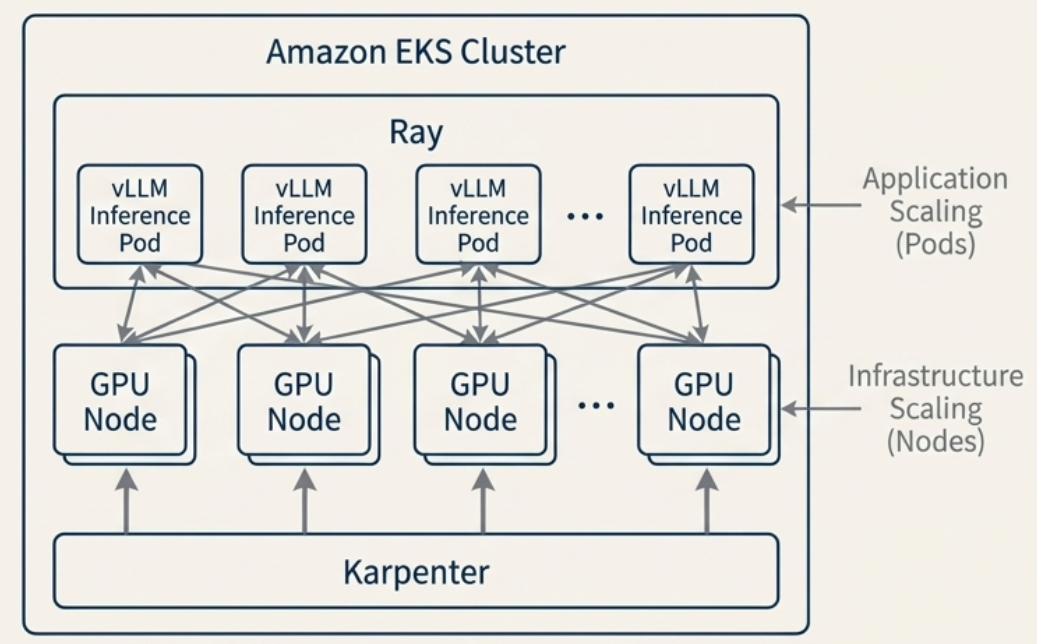
Day2-2. Accelerate AI model fine-tuning and deployment with SageMaker HyperPod
【エピソード】
Fine-Tuning の HyperPod のリソースを上昇させる分、比例して学習時間が短くなるかを質問し、比例して学習時間が短くなると回答をいただきました。踏み込んだ質問はあまり思い付かず、基本的な質問に止まりました。講師陣が他のセッションとは異なり新人感があった印象でした。
【セッション内容】
大規模な学習基盤である SageMaker HyperPod のワークショップでは ml.g5.2xlarge などの高価なリソースをクラスタリングしてファインチューニングを行いました。SageMaker HyperPod を用いてクラスタリングを行い、Qwen 3 モデルのFine-tuning と、EKS でデプロイして推論環境を構築しました。
Day 3: GameDayで感じたAmazon Qの限界とAIセキュリティ(Jam)への挑戦
3 日目は最もハードな日でした。この日は、早朝に 5km run を走り、GameDay 4時間、Jam 3時間、夜 walking と非常に体力を使う日でした。

Day3-1. AWS GameDay: AI-Assisted Developer Experience ft. New Relic
【エピソード】
自社 3 名チーム + 日本人 1 名の 日本人チームで参加しました。5km run のあと 8:00 から開始でした。この会は、4 時間でハンズオンを行いましたが、自身はほとんど 1 問にしか着手できずに終わってしまいました。多くの問題に触れないと得られる物が少ないということが、身にしてみてわかりました。4 時間かけて、Amazon Q は微妙というのが印象に残ってしまいました。Amazon Q で解析してトラブルシューティングをしてもうまく解決できず、結局自身の手で分析して、1 問を8 割方クリアする形となりました。特に再起動しただけでクリアした時は、ライトな LLM で稼働している AI に頼るのではなく、サポートツールとして利用することが重要であると学びました。何の LLM を今使っているのかは、SaaS でブラックボックスになっていたとしても、意識した方が良いと理解できました。複雑なトラブルシューティングにおける AI の限界を痛感しました。

【セッション内容】
Gamefied Learning で GameDay のセッションです。取り組んだ課題は、CloudWatch のログを Amazon Q 用いて、トラブルシューティングする演習です。マネジメントコンソール上で Amazon Q で通信テストを行い、SG や ACL などの通信不可となっている原因を特定して、AI の指示通りに修正していく課題です。
Day3-2. AWS Jam: Generative AI - Sponsored by Nvidia
【エピソード】
午前中に GameDay へ初参加するも、Amazon Q がいまいちなことしか学べず収穫が少なかったため、午後の予約セッションを全て(3 つ)リリースし、近しい Jam を受講しました。Jam も日本人チームでの参加となりました。午後は英語で参加する予定でしたが、意外と日本人が多くて自然と日本人チームに加わりました。ご一緒していた方は、端末を 3 台広げて 1 台は Kiro をフル活用していました。残り 2 台を操作して課題を解いていました。Las Vegas まで来られている AWS 職人の凄さを近い距離で見ることができました。個人の成果としては、チームで6問完答し、内 2 問を自身が完答できました。
【セッション内容】
Nvidia 主催の実践的なスキルを試す Security Jam です。
取り組んだ課題は以下 2 点です。
- Kiro を用いたコード脆弱性診断
- PCI DSS 要件(個人情報マスク)
1 つ目は、Kiro を使い、k8s マニフェストやコードの脆弱性診断を行いました。Kiro のセットアップからセキュリティの脆弱性診断を行いレポートを提出しました。2 つ目は、PCI DSS 要件(個人情報のマスキング)を実装するLambda関数を作成しました。Nova Microのような廉価モデルでも、英語の機械的なタスクであれば十分実用的であることが確認できました。
Day 4: AWS Trainium でのモデル蒸留 - 30B から 0.6B へのダウンサイジング
日本からの迷惑電話に起こされ、3 時起床です。時差があるので迷惑電話もきついです。Builder's Session に 1 つ参加し、残りは Expo を回りました。

Day4. Compact yet powerful: Exploring model distillation with AWS Trainium
AWS Trainium と AWS Neuron SDK を用いたモデル蒸留、大規模MoEモデルから小規模モデルへの知識転移(チェス予測)を行いました。
【エピソード】
ビルダーズセッションです。英語に自信がないため、いつでも画面を見せてコミュニケーションが取れるように講師のすぐ横に座りました。蒸留と言えば DeepSeek ショックを思い浮かべますが、その技術を実際に触れるセッションです。10 問以上質問した記憶がありますが、講師は彼自身が作った問題ではないのか、あまり答えられずかなり焦っていた記憶があります。「何 B(ビリオン)パラメータのモデルを教師モデルとしているのか?」「この学習データとなるインプットファイルは、その先生モデルから作った物なのか?」など、質問をしましたが、いずれもすぐ答えられず、他の講師に確認してから回答してくれる形でした。講師・受講者のどちらとも距離が近く、コミュニケーションをとりやすかったのでよかったです。
【セッション内容】
ビルダーズセッションです。ハードウェアだけでなく、モデル自体を小さくするアプローチです。30B の頭脳を 0.6B に移植する「蒸留」を行いました。チェスという特定タスクにおいて、300 億パラメータ(30B)の教師モデルの能力を、わずか 6 億パラメータ(0.6B)の生徒モデルに「蒸留(Distillation)」する実験を行いました。
結果、AWS Neuron インスタンスを活用し、50 分の 1 のサイズで同等の精度を実現できました。用途が限定されている場合、このアプローチはコスト削減に絶大な効果を発揮します。

これは非常にコストパフォーマンスが良いユースケース。
大規模言語モデルの運用コストという課題に対し、蒸留は極めて強力な解決策になりうる。
Day 5: MCP・LangGraph・Auroraを組み合わせた金融マルチエージェント構築
5日目のスケジュールです。
Day5-1. Build a multi-agent financial research assistant with Amazon Bedrock
スーパーバイザーと専門エージェントを組み合わせた、金融リサーチアシスタントの構築
【エピソード】
予め用意されていた UI が洗練されていたため、フロントエンドは Streamlit で作っているのかと確認しました。確認したところ、Kiro で Streamlit を活用して re:Invent のデザインに寄せて UI を作ったそうです。Kiro が Streamlit を使いこなすと、UI もいい感じにできるということがわかりました。また、自身の理解として Lambda による MCP 作成の理解が追いついていないと感じました。Lambda と AgentCore でどう動いているのか再学習が必要です。また、通常、統計学的なテクニカル分析を主体としたデータ分析が主だと思いますが、LLM を活用することで News や SNS の分析を融合させた Financial(金融的)な分析が可能だと感じました。そうなると、金融分野にとにかく賢くて、とにかく速い LLM インフラが求められる世界というのも必要と感じ、もともと金融に特化した DeepSeek などを証券取引所にネットワーク的に近い位置に配置するリッチなユーザがいるユースケースも存在すると想像しました。
【セッション内容】
金融系の業務における、審査などを AgentCore や StrandsAgents などを使って、解決しました。良くあるクレカ審査のようなことができるようにします。与信だけではなく、価格を取得して、簡易テクニカル分析もしてくれる、News などのテキスト情報からファンダメンタルズ分析もしてくれるものでした。python で作ったものをランタイムに追加し、AgentCore ゲートウェイにターゲットを追加していき、機能を増やしていきます。

Day5-2. Build a multi-agent AI solution with Amazon Aurora & Bedrock AgentCore
MCPとLangGraph、Aurora PostgreSQLを用いた、レガシーアプリ近代化のための協調型AI構築
【エピソード】
API Gateway 経由のサーバレスでも固定長の回答に特化させたアーキテクチャはレガシーと位置付けられていました。AgentCore でよりフレキシブルに対応できる物が最新となるとは、時代の流れははやいと感じました。ここに来てバリバリとコードを書くワークショップだったため、なかなかハードでした。LangGraph や MCP などを手を動かしつつ理解する演習です。ひとつ前のセッションでも AgentCore を活用しましたが、AgentCore の作り方と使い方が異なりました。python を書いてから、コンテナ化して、ゲートウェイのターゲットに追加するやり方が前のセッションで、今回はコマンドラインのみで完結させていました。GUI で実装するか、CLI で実装するかという差になります。この辺りは復習が必要です。
【セッション内容】
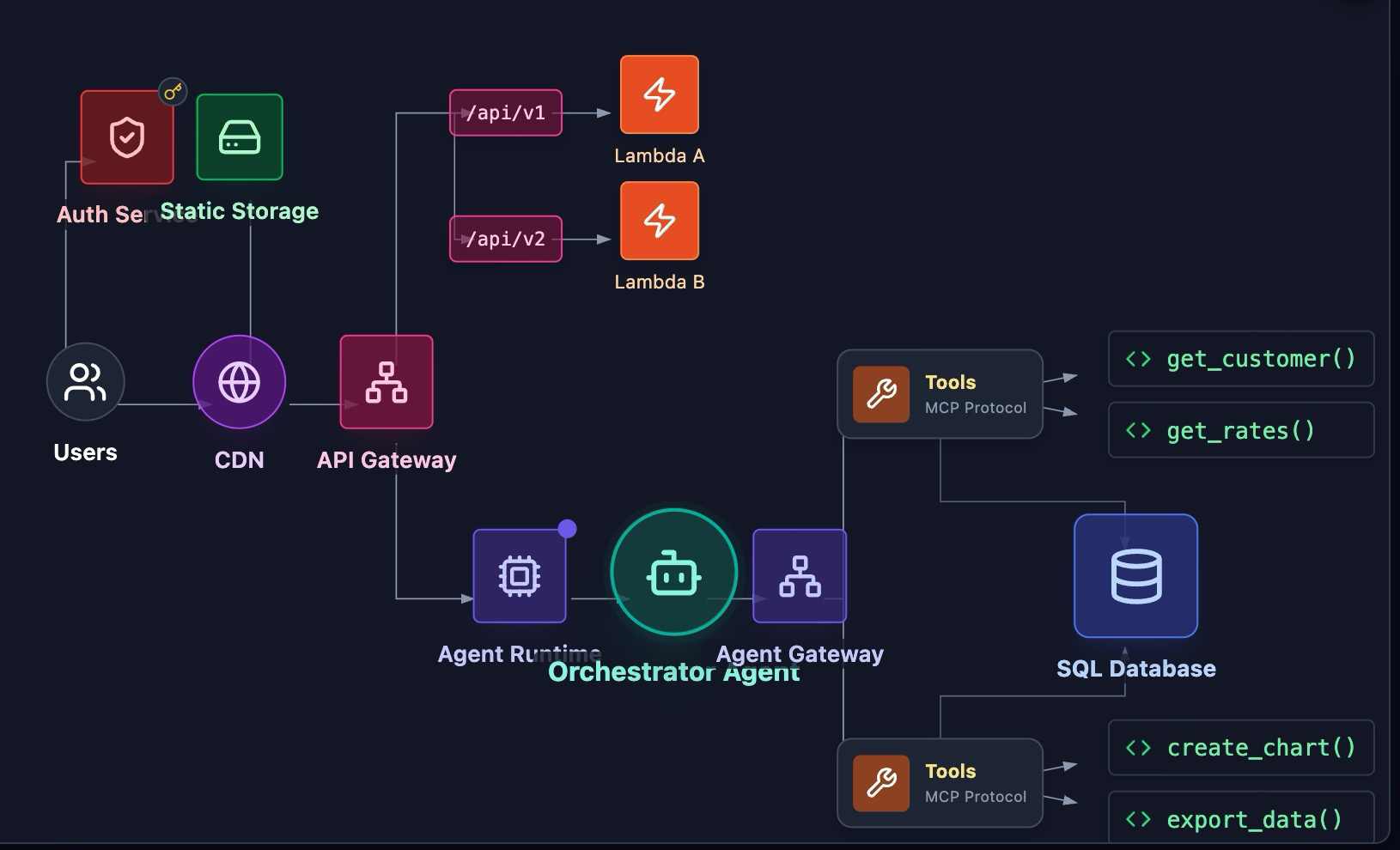
Aurora と Bedrock AgentCore を使用した協調型エージェント AI ソリューションの構築に関する包括的なワークショップです。すでにワークショップの構成はサーバレスですが、AgentCore が登場したため、これを legacy アーキテクチャと呼んでいました。これをさらにAgentで、固定ではなくエージェンティックに動作させることで、チャットで図の作成などができる機能を組み込みこみました。
以下がレガシーアーキテクチャとモダナイズアーキテクチャです。
・レガシーアーキテクチャ

・モダナイズアーキテクチャ
ネットワーキング
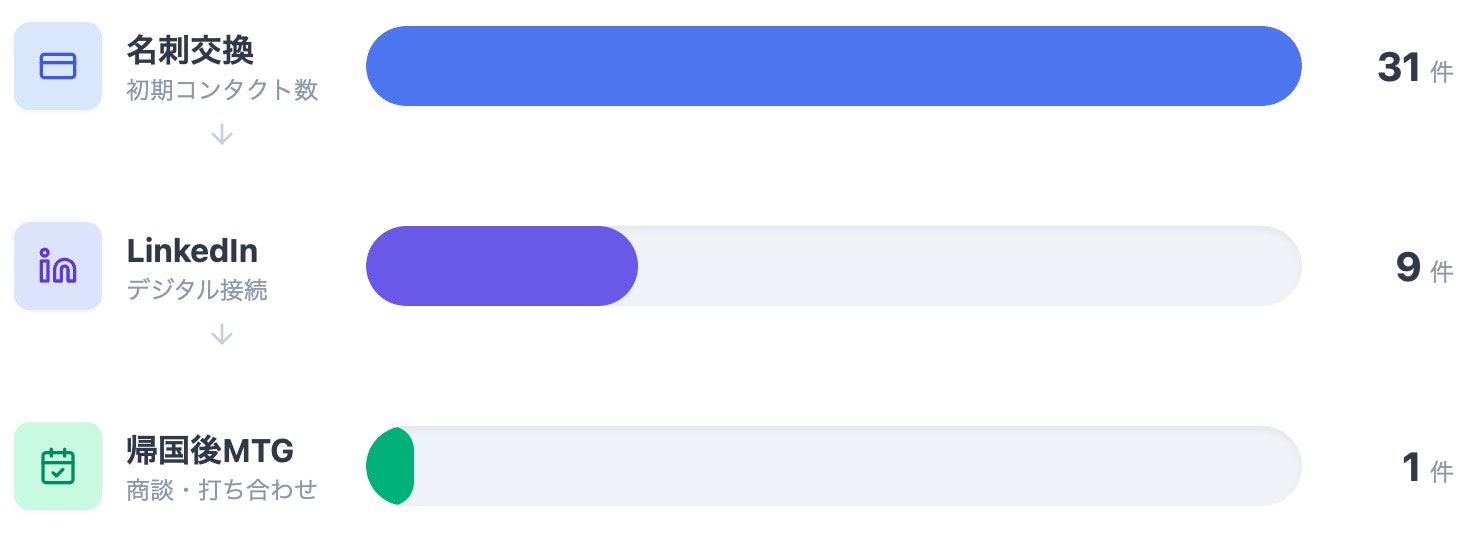
名刺 31 枚、LinkedIn 9件、帰国後 MTG 1 件のネットワーキングができました。
re:Invent 参加後の翌週に、MTG を行い、業務へ直に活かせる繋がりができたことは収穫でした。
その他
The Wizard of Oz at Sphere
Sphere の上映を見ました。スポンサーの 1 つは Google Cloud です。The Wizard of Oz を上映中でした。この作品は、古い作品を AI の技術で 16K へ拡大し、球体の次世代ディスプレイに投影しています。超解像技術のその先の技術を体感できました。旧作品を Google Gemini や Veo などの Google AI プラットフォームでリリースされた、AI による最大級の作品で、没入感もありすごかったです。空や森などの元の作品にはない表現ができています。さらに、圧巻のパフォーマンスで、椅子が揺れたり、葉っぱが飛んだり、リンゴが降ってきたりと、面白い演出もあります。今後も、古い作品を AI で全面的にリニューアルした体験型アトラクションが、流行する可能性が示唆されていると感じました。IP 領域/過去の知的財産の価値向上が期待できると思います。次の画像は、実際に著者が撮影した画像です。

Day 6: 帰国便でのネットワーキングとre:Invent総括
飛行機でたまたま 隣の席 の方とラストセッションをしました。re:Invent 2025 の総復習と Qiita 記事執筆を行いました。貴重な情報交換の場を持てました。ありがとうございました。zoox に乗れると知らなかったので、知っていたら乗っておきたかったですね。

まとめ:次世代AIプラットフォームの姿
re:Invent 2025 を通じて見えたのは、「セルフホスト(Control)」と「マネージド(Agility)」が二者択一ではない未来です。
- Core Inference: パフォーマンスが最重要な推論部分は、AWS Trainium/vLLM on EKS で極限までチューニング
- Agent Layer: その推論機能を MCP 経由でツール化し、AgentCore 上の安全なエージェントから呼び出し

このハイブリッドなアプローチが、現代の「クラウドネイティブな次世代AIプラットフォーム」ではないかと認識できました。わずか 1 週間で「行動力」「英語力」「AWSの高スキル/最新情報キャッチアップ」と、多くのことを経験できました。
最後に、一緒にこのイベントを乗り切った @dsol_saekiさん、@dsol_rsatoさん、本当にありがとうございました。
また、re:Invent 2025 へ参加させていただけたことには、周囲へ感謝しかありません。
本記事で使用している画像は、筆者のメモをもとに Google NotebookLM、Google Gemini を使用して生成・取得したものです(2025年12月15日 時点)。
記載されている会社名、製品名、サービス名は、各社の商標または登録商標です。