はじめに
最近、GoogleでTensorflowの物体検出APIが公開されました。(http://jp.techcrunch.com/2017/06/17/20170616object-detection-api/)
それ以前からSSD(Single Shot Multibox Detector: 物体検出)の論文は出ていて気にはなっていたのですが、私がやっているUAV制御や画像処理系の研究開発に適合する技術と思い、まずはやってみようということで、会社の昼休みの時間でノートPCのカメラでリアルタイムSSDがどれだけのものになるかやってみました。
SSDについて
SSDは上述しましたがSingle Shot Multibox Detectorの略で、物体検出をするアルゴリズムです。Tensorflowによる学習を含んでおり、学習させた物体を認識し、画像上にその範囲まで表示させることが出来ます。
SSDに関しては多くの記事がQiita内にあります。
SSD:Single Shot Multibox Detector
SSD(Keras/TensorFlow)でディープラーニングによる動画の物体検出を行う
物体検出アルゴリズム(SSD : Single Shot MultiBox Detector)を学習させてみる
情報の少ないSSD(Single Shot MultiBox Detector)を出来るだけ細かく解説してみる ~ VGG編 ~
など
実は2016年の論文を精査中な為、詳しいアルゴリズムについてここではお話しできませんが、まずは動かしてみようという感じでやってみることにします。
条件
・OpenCV、Tensorflowはインストール済みでPython3系にはある程度精通している(SSDアルゴリズムはわからなくても良い)
・Macbook Proのカメラで撮影した画像をリアルタイムにSSD
・会社の昼休みにやる
以上の条件で、MacbookProのカメラで取り込んだ動画をリアルタイムにSSDをかけて物体検出するというシステムを会社の昼休み1時間でできるかやってみます。
SSD-Tensorflow
まず、SSDのプロジェクトですが、githubにあります。
SSD-Tensorflow
こちらをダウンロードしていただき、まずはdemoフォルダ内にある画像を試しに処理してみましょう。
ここでOpenCV、numpy、scipyなど必要なものはインストール済みとします。
notebooksディレクトリ内にあるjupyter notebook形式のファイルを開けばサンプルの実行が可能です。jupyter notebooksはAnacondaインストール時に一緒に入っているはずです。
ここでdemoディレクトリには複数の画像が入っていますが、SSD-Tensorflowプロジェクト内のディレクトリnotebooks内のssd_notebook.ipynb内のコード中で
という部分がありますが、[-5]をいじれば任意で処理する画像を変えられます。またdemoディレクリに自分で探した画像などをいれれば自分で選んだ任意の画像を処理することが出来ます。
ちなみにJupyter Notebook形式ですが、.py形式のファイルにして実行しても同じです。私はなぜかJupyter Notebook上でcv2がインポートできず、.py形式のファイルを作って普通に実行したらできました。
カメラからキャプチャーした画像の処理
さて、本題ですがMacbook Proのカメラで取得した画像を処理する方法です。
が、やることは簡単で、ssd_notebook.ipynbの最後の方にチョチョイっとコードを追加するだけです。
実はmatplotで表示する形式なのですが、その機能は同じnotebooksディレクトリ内にあるvisualization.pyに集約されています。今回は特にクラス分け関数わけなどせず、メインファイルにガリガリ書きたいので、以下のコードをssd_notebook.ipynbの最後に追加とします。
# 動画の読み込み
cap = cv2.VideoCapture(0)
videoCnt=0
figsize=(10,10)
linewidth=1.5
fig = plt.figure(figsize=figsize)
# 動画終了まで繰り返し
while(cap.isOpened()):
# フレームを取得
ret, frame = cap.read()
img = frame
# フレームを表示
cv2.imshow("Flame", frame) #無くてもいい
rclasses, rscores, rbboxes = process_image(img)
#######
plt.imshow(img)
height = img.shape[0]
width = img.shape[1]
colors = dict()
for i in range(rclasses.shape[0]):
cls_id = int(rclasses[i])
if cls_id >= 0:
score = rscores[i]
if cls_id not in colors:
colors[cls_id] = (random.random(), random.random(), random.random())
ymin = int(rbboxes[i, 0] * height)
xmin = int(rbboxes[i, 1] * width)
ymax = int(rbboxes[i, 2] * height)
xmax = int(rbboxes[i, 3] * width)
rect = plt.Rectangle((xmin, ymin), xmax - xmin,
ymax - ymin, fill=False,
edgecolor=colors[cls_id],
linewidth=linewidth)
plt.gca().add_patch(rect)
class_name = str(cls_id)
plt.gca().text(xmin, ymin - 2,
'{:s} | {:.3f}'.format(class_name, score),
bbox=dict(facecolor=colors[cls_id], alpha=0.5),
fontsize=12, color='white')
plt.pause(0.03)
cap.release()
出力結果
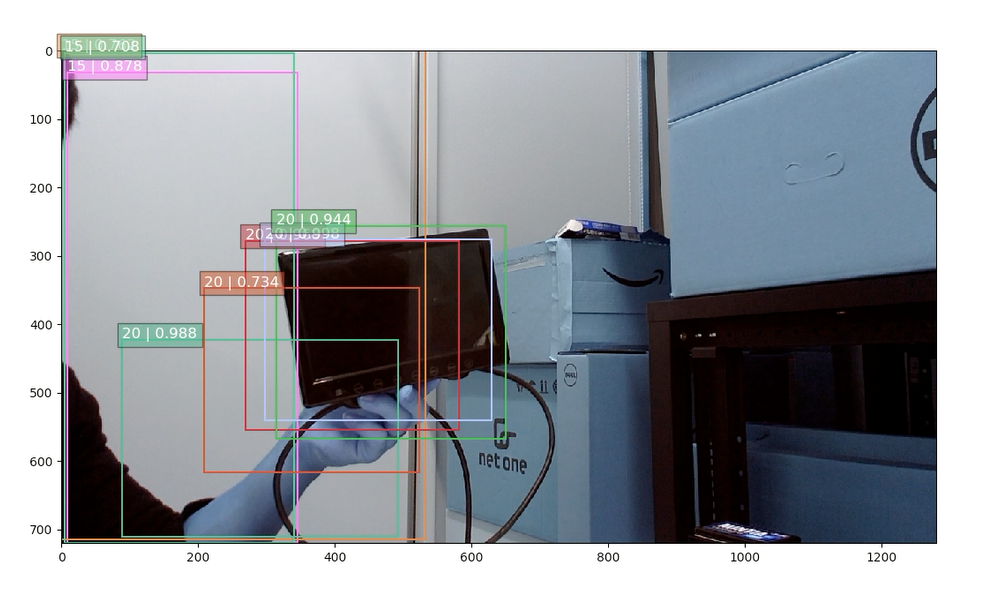
カメラキャプチャした画像はこんな感じです。このSSDで学習させたラベル番号は20がmonitor、15がpersonを指します。手に持った小型モニターをしっかりmonitorと認識し、私の腕をpersonとリアルタイムで認識しています。
動画で見ると1fpsも出せてませんね。。。
Switch Scienceで公開しているRaspberry Pi3 + Movidiusの組み合わせでCNNと画像分類の動作は結構スムーズに動作していたので、もっとカチカチ動くかと思っていたのですが、実際にGPUを使わずかつ現実に使えそうな画像サイズで動作させてみると結構遅くなりますね。
今後の展開
さて、とりあえずリアルタイムでSSDを動かしてみたらどうなるかを試してみました。単純にCNNで画像分類して学習済みの対象データが有るか無いかの判定をするのに比べてSSDはかなり処理を食います。
UAV、ロボット、自動運転などに応用する場合、一工夫必要ですね。
例えば物体認識してあとのトラッキングはこういう論文のアルゴリズムを利用するなど。
ちなみに、このSSDを実行するに当たり学習させたデータは、確認しただけでも17000枚くらいのjpeg画像があります。それぞれサイズは500x375とかです。150x150の画像を200枚程度、クアッドコアのMacbook ProでもまともにCPUだけで学習させると数十分かかったので、17000枚で500x300~400というサイズの画像を学習させると想像を絶します。
そんな事実からも、自分がかかわる研究分野と開発対象でどういう風に特化して学習させて物体検出と追跡をすべきか、今回やってみたことから見えてきた気がします。