はじめに
オブジェクト検出(object detection)アルゴリズムを利用してAWS DeepRacerを検出するモデルを作成したので実際に使ってみました。
本記事では、AWS DeepRacer検出モデルの利用例について説明しています。
その他の内容については、以下の記事をご確認ください。
- AWS DeepRacer検出モデルを作ってみた(データ準備編)
- AWS DeepRacer検出モデルを作ってみた(モデル作成編)
- AWS DeepRacer検出モデルを使ってみた(実践編) ※本記事
注意
以下の内容は 2019 年 9 月 3 日時点のAWS開発者ガイドを元に実施しています。
例: Amazon SageMaker を使用してビデオストリーム内のオブジェクトを識別する
本記事ではアジアパシフィック(東京)リージョンを使用しています。
走行軌跡を可視化する方法
今回は2つの方法で走行軌跡の可視化を試しました。
1. 保存された動画ファイルから可視化
Amazon Rekognition Videoと同じ要領で、カメラでトラック上を撮影し保存した動画ファイルからAWS DeepRacerを検出します。
検出した位置情報は画像にプロットし、走行軌跡を見える化します。
2. 動画ストリームからリアルタイムに可視化
顔認識でラップタイムを計測するシステムを元に、カメラでトラック上を撮影し動画ストリームをAWS上に構築したシステムに送信します。
検出した位置情報は走行しているトラックの画像にプロットし、リアルタイムで走行軌跡を見える化します。
用意するもの
- Apple MacBook Air
- Amazon Kinesis Video プロデューサライブラリ(C++)をインストール
- Webカメラ
- 紙で作ったミニコースとAWS DeepRacer
- まずは小さく扱いやすいもので試してみました。
- コースは9月のバーチャルレースCumulo Carrera Trainingを印刷しました。
- AWS DeepRacerのプロップ(小道具)を用意しました。マグネット式で紙の下から動かせるようになっています。

1. 保存された動画ファイルから可視化
システム構成
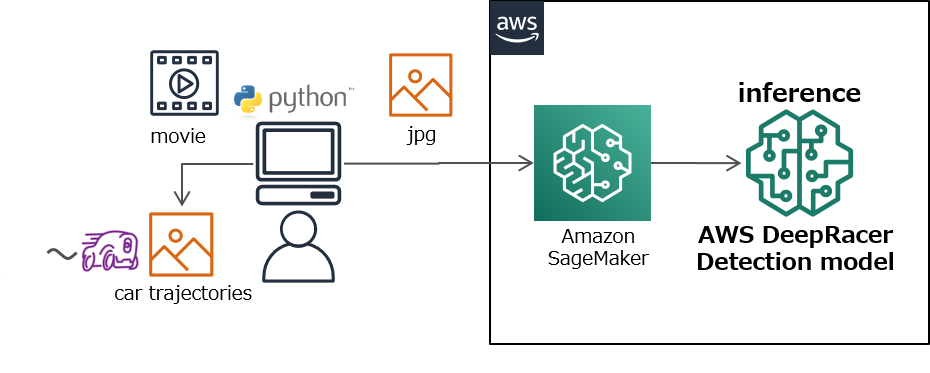
動画ファイルの情報
1080×1920 / 30fps
ローカル環境から以下の処理をするPythonプログラムを実行します。
- OpenCVで動画ファイルから最初のフレームを取得し座標情報をプロットする元になる画像として保存します。
- 動画から100フレームおきに画像ファイルを抽出します。
- 抽出&変換した画像ファイルを、AWS DeepRacer検出モデルにかけ結果の位置情報を元画像にプロットします。
物体検出アルゴリズムのエンドポイント呼び出し方法はこちらです。
import json
import boto3
runtime = boto3.Session().client(service_name='sagemaker-runtime')
endpoint_name = 'XXXXXXXX' # 作成した推論エンドポイントの名前
file_name = "XXXXXXXX.jpg" # 入力画像
img = open(file_name, 'rb').read()
response = runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='application/x-image',
Body=bytearray(img)
)
result = response['Body'].read()
result = json.loads(result) # json形式で推論結果が入る
with open(file_name, 'rb') as image:
f = image.read()
b = bytearray(f)
ne = open('n.txt','wb')
ne.write(b)
結果

赤い点は検出したAWS DeepRacerの中心座標です。AWS DeepRacerの走行軌跡がプロットされました。
2. 動画ストリームからリアルタイムに可視化
システム構成
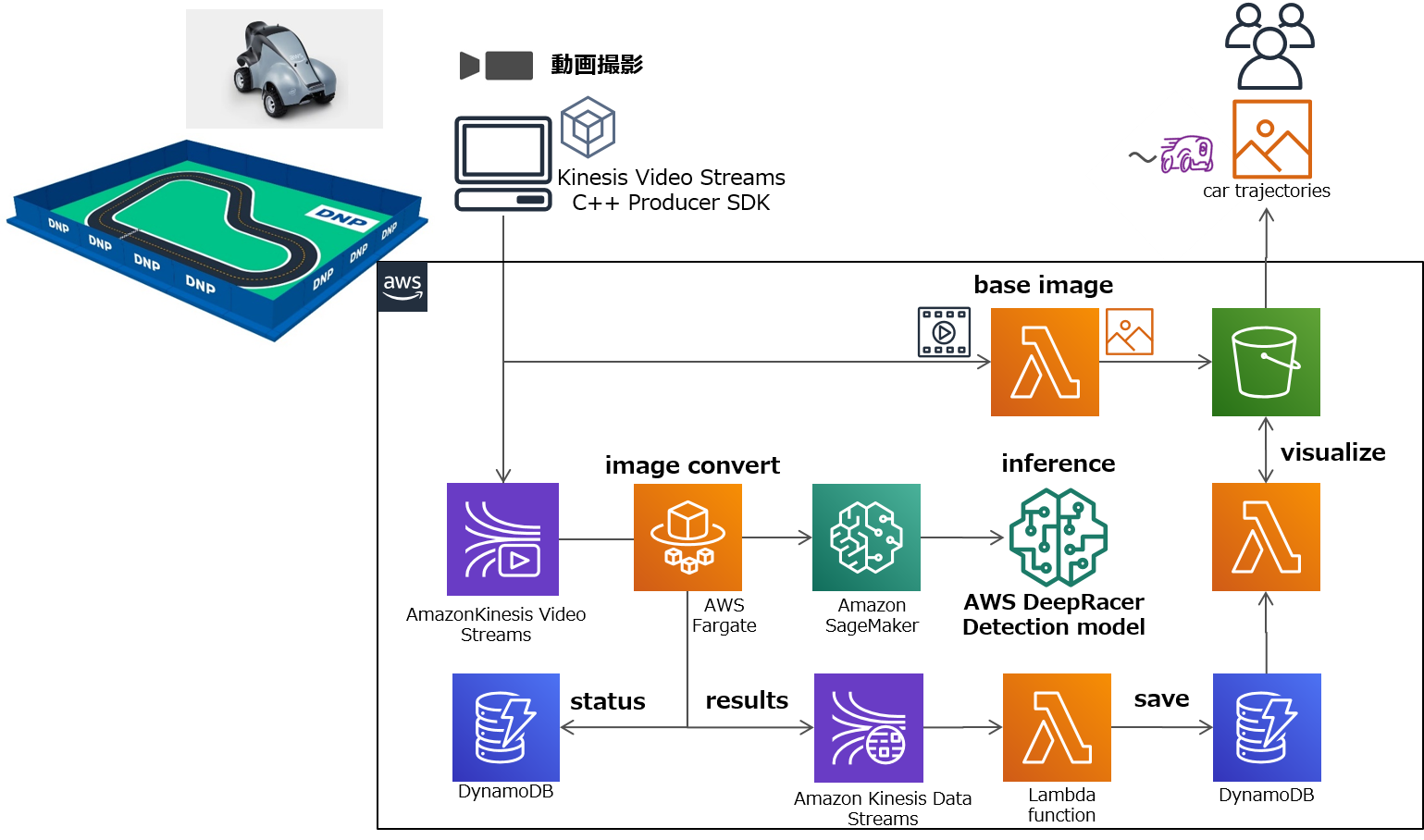
以下の仕組みで構成しています
-
動画ストリームをAWSへ送信するクライアント
Kinesis Video Streamsプロデューサーライブラリを利用し、PCで取り込んだ動画データをAWS上のKinesis Video Streamsにアップロードします。
AWS開発者ガイド Kinesis ビデオストリーム プロデューサーライブラリ -
リアルタイム推論のためのアプリケーションとサービス
AWS Fargateではリアルタイムに分析を行うためのアプリケーションが動いています。
具体的にはストリームからメディアフラグメントを取り出し、解析、抽出、サンプリング後、JPEG/PNG形式などの画像形式に変換を行い、Amazon SageMakerのエンドポイントにリクエストします。
Amazon SageMakerではホストするモデル(ここではAWS DeepRacer検出)の推論を行い、結果はアプリケーションを経由してKinesis Data Streamsへデータが送られます。DynamoDBではチェックポイントや関連状態を管理しています。
これらのサンプルアプリケーションと関連サービスはAWSからCloudFormationで提供されています。
Amazon Web Services ブログ Amazon Kinesis Video Streams および Amazon SageMaker を使用したリアルタイムでのライブビデオの分析
AWS開発者ガイド 例: Amazon SageMaker を使用してビデオストリーム内のオブジェクトを識別する アプリケーションの作成 -
AWS DeepRacer検出モデル
AWS DeepRacer検出モデルを作ってみた(モデル作成編)で作成したモデルを利用します。リアルタイム分析を行う前に、Amazon SageMakerでエンドポイントの生成を行います。
(エンドポイントは時間課金なので、利用後は忘れずに削除しておきましょう) -
走行軌跡を保持、視覚化するアプリケーションとサービス
Kinesis Data Streamsに取り込まれた検出結果を、Lambdaで信頼度の高い必要な情報だけを抜き出してDynamoDBに格納します。
その他、視覚化のベースとなる画像を動画ストリームから1枚抽出するLambdaも作りました。最終的に抽出したベース画像とDynamoDBの情報で、位置情報をプロットした画像を合成しS3に格納します。
結果

リアルタイム検出は様々な問題が発生しました。試行錯誤を繰り返した末、なんとか検出されました。(発生した問題については、このあとで記載しています。)
また、何度も試してみましたが、特定のエリアではAWS DeepRacerの検出はされませんでした。
リアルタイム検出において発生した問題
今回、各機能の単体テストでは紙のAWS DeepRacerも検出されて、位置情報の保存、画像合成も問題なくできていましたが、実際に試してみたところ以下のような問題が発生しました。
-
トラック全体がAWS DeepRacerとして検出されてしまう問題(モデルの課題)

何故か理由はわかりませんが、コースを変えても、一部欠けていてもダメでした。原因がわからなかったので、検出後のアプリケーションで大きすぎる検出範囲は除外するように調整を行いました。 -
作ったAWS DeepRacerの物体が小さくて検出されない問題(機器、環境の課題)
カメラが対応している解像度をプロデューサライブラリで1280×720まで上げて配信してみましたが、コース全体だと小さすぎて検出されませんでした。
また、カメラ位置やピント合わせ、照明の状況によっても検出状況が変わるためセッティングに苦労しました。 -
細かい間隔の推論リクエストに向いていない問題(システムとアプリケーションの課題)
利用したコンテナアプリは、パラメータストアで推論エンドポイントの間隔(inferenceInterval)を短く設定できたのですが、その最小設定よりも早い動きの物体では座標ポイントが飛んでしまい、走行軌跡の可視化には向いていませんでした。
まとめ
- 実際にモデルをどのように使うのか、理解しながら構築することができました。
- 動画ファイル(バッチ)の分析の方が、扱いやすく簡単に可視化をすることができました。
- リアルタイム分析を現実世界で使うにはカメラや配信機器の性能、環境の考慮、アプリケーションカスタマイズやそれなりのスペックのあるシステムも必要であることがわかりました。(amazon goはすごいと思いました。。)