はじめに
特に組み込み系開発者なら超絶便利でよく利用するので、ドはまりして必死の調査により理屈を覚えた人も多数いるであろうマルチスレッドプログラミング。今回は本件について出来るだけかみ砕いて説明したいと思います。
記事の主題は以下となります。
- プロセス/スレッドってなに?
- 排他制御ってなんで必要なの?
- その他注意点や排他を減らす手段の紹介
プロセス/スレッドってなに?
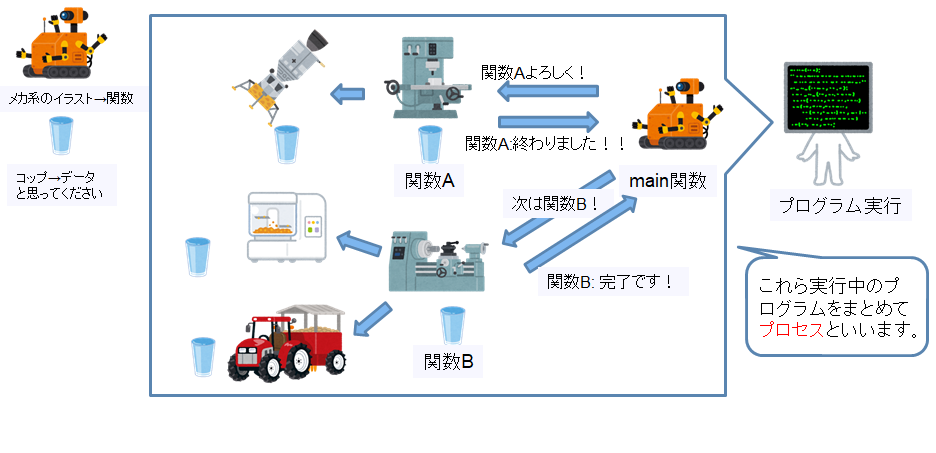
プロセス: main関数で動くプログラム
以前ライブラリの説明をした際に、プログラムはmain関数や使用するデータによって実現すると記載させてもらいました。このプログラムを実行すると、このプログラムの情報が全てメモリ上に展開され、利用されます。この展開された情報をひとまとめにしてプロセスと呼んでいます。
実行されたプログラムのことをプロセスと呼ぶので、例えば同じプログラムを2回実行すると、2つのプロセスが出来ることになります。
Windowsならタスクマネージャーから、Linuxならpsコマンドから今動作しているプロセスが確認出来ます。
スレッド: main関数とは別に自立して動くことの出来る関数
プログラムはmain関数から実行された順番に処理を実現するのですが、これだと少し不自由が生じることがあります。
例えばプログラムの中のとある関数heavy()は処理が完了するまでに1時間がかかるとします。この場合、main関数はheavy()が終了する1時間を待たないと別の処理が実行できないことになります。
1時間ならまだましで、例えば「ユーザーがキー入力するのを待つ」のようないつ動き出すかもわからない処理だととんでもないことになります。こんな時に便利な機能がスレッドです。
スレッドはプロセス内で動作するんですが、main関数の処理順とは関係なく動くことが出来ます。(非同期処理と言ったりします。)
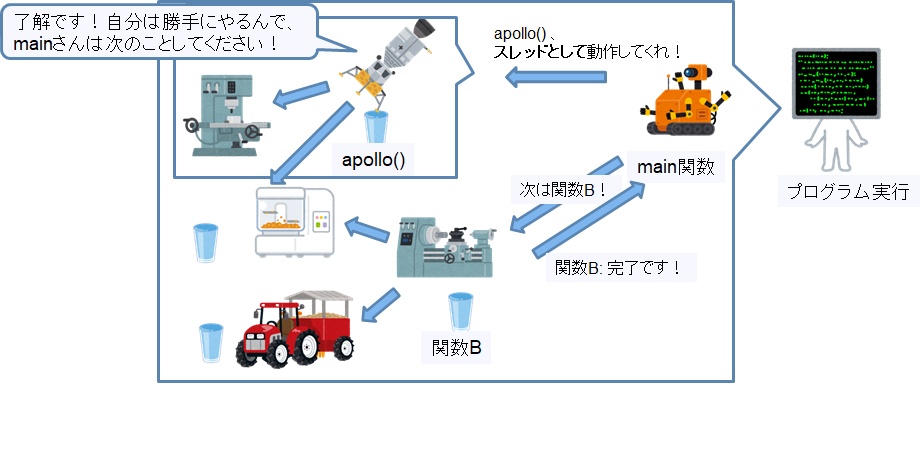
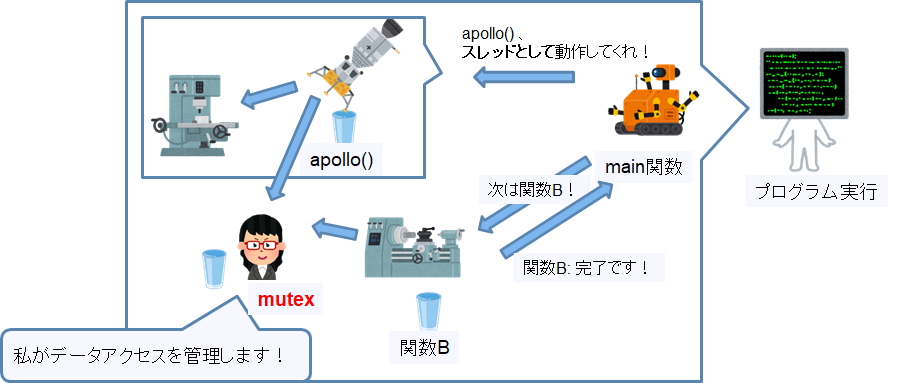
図では関数apollo()をスレッドとして起動しているので、apolloはapolloで処理を実行し、mainはapploの終了に関係なく次の関数を実行することが出来ます。
また、プロセス内で動作するということは、スレッドはプロセスの持つメモリ領域(関数やデータ)を共有することが出来ます。
また、スレッドを利用して動作するプログラムをマルチスレッドプログラムと言います。
Linuxでのスレッド起動の例
図だけだとイメージ付かない部分もあると思いますので、プログラムでの例を記載します。pthread_createという関数の3番目の引数で関数を指定しています。また、pthread_joinはスレッドの終了を待つための関数です。
static int data;
int main() {
pthread_t tid;
pthread_create(&tid, NULL, main_thread, NULL);
printf("main:%d\n", data);
///...
pthread_join(tid, NULL);
printf("main end:%d\n", data);
return 0;
}
void * main_thread(void *arg) {
sleep(1);
data=10;
pthread_exit(NULL);
return NULL;
}
普通にmain_thread関数を実行すると、main側のprintf("main:%d\n", data);の時点で関数の処理が終わるのでdataの中身は10に変わりますが、
スレッド起動しているのでmain_threadの処理が独立して動作してくれるので、printf("main:%d\n", data);時点ではdataは0, pthread_joinで終了を待った後は値が書き換わるというわけです。実行結果はこのようになります。
$ ./a.out
main:0
main end:10
ちなみに上記の例、後で説明する排他制御を全く考慮していないコードなので、中々危険だったりします。
子プロセス: main関数から独立して動作する新しいプログラム
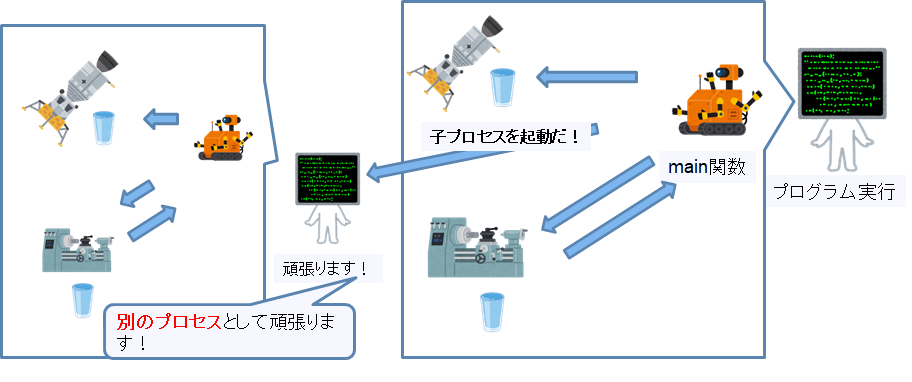
今回の記事のメインはスレッドなんですが、先ほどのスレッドを利用した非同期処理以外にももう一つ非同期処理の実現方法があります。子プロセスを使う方法です。
子プロセスはそのプロセス内の処理として何かをするのではなく、新しいプロセスとして動作することにより、非同期処理を実現します。
当然別プロセスなので、プロセスの持つメモリ領域を共有することは出来ません。
Linuxでの子プロセス起動の例
forkを使った子プロセス作成が有名でしょう(私はpopenくらいでしか使いませんが)。
forkと実行すると今まで利用したデータを完全にコピーした子プロセスが出来ます。違うのはforkの戻り値。
pid==0となっている方が子プロセス側で、そうでない方が親プロセス側の処理となります。
親プロセスはwaitpidという関数を使って子プロセスの終了を待つことが出来ます。
# include <stdio.h>
# include <stdlib.h>
# include <sys/types.h>
# include <sys/wait.h>
# include <unistd.h>
int main() {
int data=0;
pid_t pid=fork();
if(pid==0) {
//子プロセス側
sleep(1);
data=10;
printf("child:%d\n", data);
exit(0);
} else {
//親プロセス側
printf("parent:%d\n", data);
waitpid(pid, NULL, 0);
printf("parent end:%d\n", data);
}
return 0;
}
親プロセスと子プロセスは変数dataを共有していないので、一方がdataの値を変えてももう一方のデータは変わりません。
$ ./child
parent:0
child:10
parent end:0
プロセス/スレッド/子プロセス まとめ
概要と異なる点をまとめました。全て自立して動作するという点では同じですが、メモリ空間や終了の仕方が違います。
| 名称 | 概要 | 利用するメモリ空間 | 終了の仕方 | 終了の際の注意 |
|---|---|---|---|---|
| プロセス | 実行されたプログラム | 自身のメモリ空間 | 実行者が終了 or プログラム処理の終了 | - |
| スレッド | プロセス内で作成された、独立して動作することの出来る関数 | 親プロセスのメモリ空間 | プロセスによる終了 or 自身で終了 | プロセスと連携して正しく終了しないとメモリリークします |
| 子プロセス | プロセス内で実行された、別プログラム | 自身のメモリ空間 | プロセスによる終了 or 自身で終了 | プロセスと連携して正しく終了しないと子プロセスの残骸(ゾンビプロセスと呼ばれる)が残ります |
スレッドは親プロセスメモリの共有が出来る代わりに、完全に独立して動くことはできません。親の配下です。親とともに効率よく処理を分担するのが上手な使い方でしょう。
逆に子プロセスはメモリが子プロセス作成後にそのまま共有は出来ませんが、気兼ねなく独立して動作します。コマンド実行だけして終わりのような独立した処理なら子プロセスの方が便利ですね。
ちなみにこのスレッドの特徴である「メモリの共有が出来る」という点での注意が次章になります。
排他制御ってなんで必要なの?
マルチスレッドプログラミングをすると一度は聞いたことがあるでしょう、「排他制御」という言葉。これって一体なぜ必要なんでしょうね?具体例を挙げてその必要性を説明します。
マルチスレッドで排他制御をしない場合に起こるケース
スレッドではせっかく同じプロセス内のメモリを共有しているので、グローバルデータを参照したくなりますよね。非同期処理をしているスレッドとmainが同じデータにアクセスするとどうなるのでしょう?
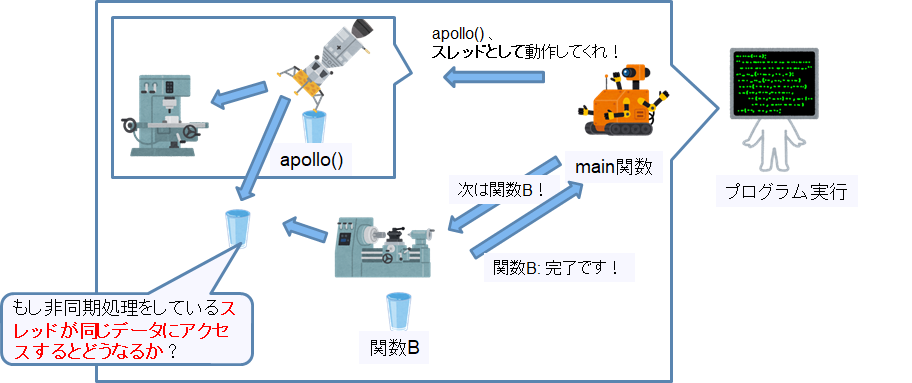
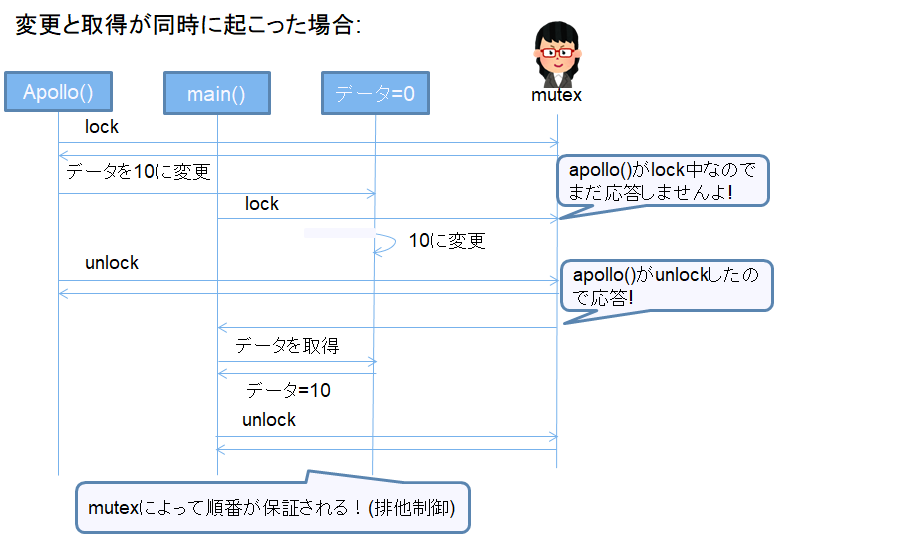
簡単なシーケンスで同時アクセスが起こった場合のケースを表現してみました。上から下に順番に記載されている処理が実行されます。
まずはapolloがデータを変更し、mainがそのデータを取得した場合。apolloのデータ変更が早いように見えるのですが、実際にデータが更新される前にmainのデータ取得が実行されるケースも存在してしまいます。

スレッドでない場合は変更処理が終わってから次に移行するのでケース1しか起こりません。
常に最新の情報を取得する必要のあるシステムだったら、ケース2が起こるのは致命的ですよね。
スレッドのサンプルで書いたコードも、static int data;をmain関数とmain_threadのそれぞれで読み書きしていますが、排他をかけていないので非常に危険ですね。(sleepでタイミングをずらしているので偶然おかしな挙動にはなっていないですが)
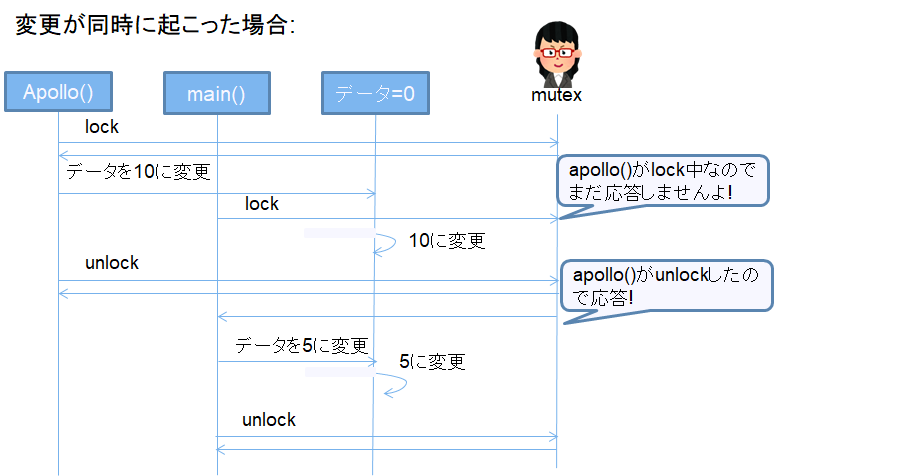
次にapollo, mainが同時にそのデータを変更した場合。完全に同時実行の場合、どちらの処理が優先されるかはわかりません。
なので、シーケンスとしては強引な書き方ですが、ケース2のようにapollo()のデータ変更が後になるケースが存在します。

こちらはもう設定変更が正しく反映されませんと言っているようなものなので、何とかしないとせっかくのメモリ共有というスレッドの利点が生かせません。どうすればいいんでしょう?
排他制御でデータ更新の順番を保証する
ここで登場するのが排他制御です。セマフォやmutexが有名ですかね。こちらを利用して同時アクセスが起きた際の挙動を保証してあげましょう。今回はmutexを例にとり紹介。
使い方は簡単です。自分がデータにアクセスする前にlock、アクセスし終わったらunlockの関数を実行するだけ。
mutexはlock中の人がunlockするまでは次のlock関数を返さないような仕組みとになっているため、同時アクセスでも順番通りの処理が保証されます。
先ほどのシーケンスを例にとり説明。まずはまずはapolloがデータを変更し、mainがそのデータを取得した場合。
mutexのおかげでmainがデータを取得しに行くタイミングが保証されました。
setも同様。これで安心ですね。
つまり、排他制御はマルチスレッドで同時にアクセスされる可能性のあるデータの処理順を保証する為の手段なわけですね。
その他注意点や手段の紹介
注意点
マルチスレッドプログラムを利用する上での注意点を記載します。
デッドロック
排他制御を行う為に2種類のmutexを利用している場合、以下のようなケースが考えられます。
main()はApollo()のunlockを待って身動きが取れず、同じくApollo()もmain()がunlockをしないので身動き取れなくなってしまいました。
このようにお互いのunlockを待って永遠にプログラムが終了しない状態をデッドロックといいます。

こうなるとどうしようもないので、デッドロックをしないようにプログラムを作るしかないですね。個人的に思いつくデッドロック(or アンロック漏れ)を防止する手段としては以下です。
- lock/unlockを使う場合は、可能な限り同じ関数の最初と最後にlock/unlockを実行する。
- データアクセスの為に複数のlockが必要なら、lock順番を統一する。
- (あるなら)一旦lockされているかどうかを確認する関数を実行してみる。(
pthread_mutex_trylock等) - 出来るだけlockの必要ないデータ設計を心がける。
最後については次章でいくつか紹介します。
排他を減らす同期手段の紹介
排他制御にはデッドロックのリスクがあるのと、純粋にスピードが遅くなるんですよね。排他を使いすぎるくらいならマルチスレッドにしない方がはやいこともあるくらい。
なので、排他を減らすことの出来る手段があるなら覚えておきましょう。
socket等メッセージ通信を利用した同期
個人的に一番好きなのはこれ。threadを作りたい時の目的とも合致することが多いです。
グローバルなデータに直接アクセスする代わりに、socketといったスレッドに対してメッセージを送信する仕組みを用意しておき、データを送ってあげる方法。排他をしなくてもデータの送受信により処理順番が保証されます。
必要なデータは全てスレッド作成時に渡してあげて、後はメッセージで変更を教えてあげるようにすれば、スレッドはわざわざグローバルデータを見に行く必要がなくなりますね。socket通信でググると沢山サンプルが転がっているのでここでは省略。Linuxなら**socketpairが便利ですよ**とお伝えしておきます。
ざっくりsocketpairに関する例を紹介。socket通信でググると出てくると思いますが、面倒なbindやlistenといった手番がいりません。
作成はこれだけ。
int sockpair[2];
socketpair(AF_UNIX, SOCK_DGRAM, 0, sockpair);
送受信はこれだけ。0, 1逆でも使えます。超便利。
//送信
write(sockpair[0], msg, sizeof(*msg));
//受信
read(sockpair[1], msg, sizeof(*msg));
変更時だけ排他・取得は排他無しではいけないの?
アクセスするデータの特性によっては、取得には排他をかける必要のないケースもあるのでは?と思うことがあります。実際動かしてみるとそれなりに動いている気がします。
ただ排他の仕組み、正しく理解できていますか?CPUやコンパイラの最適化も含め、どのような状態になっているか自信をもって説明が出来ますか?本記事を書いて心底感じました。私にはその自信はありません。
ということで、**「少しでも説明できない要素があるなら無理せず排他をかけよう」**というのが今の自分の結論です。
今の時代なら、「速度重視でlockかけずに作ってみる。問題が出たらかけた版にアップデートする」なんて思い切った策もありっちゃありかもしれませんね。
ちなみに以前に1度、「排他はいりません、シングルトンパターンで作っているから」と言い、各スレッドでシングルトンを利用して取得したインスタンスのデータをがりがり変更している技術者がいて結構衝撃でした。その時もそうでしたが、よくあるシングルトンの実装はただグローバルのインスタンスを使いまわして渡しているだったりするので、シングルトンだから大丈夫という理由にはなりませんよね。
さいごに
現在やっているlighttpdのマルチスレッド化挑戦でスレッドについてのデザインパターンを導入する必要が出てきたのでパターンを改めて見返したのですが、大体ちゃんとスレッドと排他制御を理解している人なら自然と身についているものだったので、今回はスレッドと排他制御をテーマに記事をまとめました。
過去10年の社会人経験で、スレッド化に対してはしっかり設計実装してるのに排他を全く気にしない技術者に出会うことが多い多い。
そのほとんどが本記事に書いたマルチスレッドで排他制御をしない場合に起こるケースを把握していないことが原因だったように思います。
私の場合は逆に過剰に排他をかけたくなるタイプになってしまったので、速度を意識したプログラムを書くに辺り、どうして排他が必要なのかを一から見直したいというのも今回記事にまとめた理由の一つです。そして勉強不足を痛感する。無知を知るのはいいことです。
システム開発の中の鬼門の一つであるマルチスレッド。少しでもその理解の助けになれば幸いです。
参考
言葉の定義の確認
プロセス
簡単な説明の参考として
デッドロック (deadlock)とは
イラスト素材: いらすとや