はじめに
誰かから「mallocは遅いからメモリをため込んで使いまわした方がはやいよ」という話を聞きました。本当にやるならロックかけないといけないし、そこまでじゃないの?と思いつつ、本当ならラッパーを作っておいてあげた方がよさそう。こういうことは机上の空論を続けててもしょうがないので実際に測ってみましょう!
今回は以下4種類に対してcalloc/freeの繰り返し試験を実施して測定してみます。
callocにしたのは個人的に利用頻度がそちらの方が多いから。mallocの方が純粋な精度が出たなとちょっと後悔
- 普通のcalloc/free
- 自分なりに作ったラッパー
- google先生経由で先人の知恵を借り、上記ボトルネックを解消した更新版
- google製のgperftoolsに含まれる、tc_mallocを利用(こちらの方法で強引に通常のmallocは上書きしないようにします)
※最初は何パターンか測定するまでtc_mallocがLinuxでもmalloc系APIを上書いていることに気付かずぬか喜びしてました。ライブラリリンクだけで上書きされていることはデバッグでも確認。
ライブラリはシンプルに溜め込むメモリの使用量、サイズを決める形にします。
なので、計測前の予想としては、メモリの使用量、サイズ内に収まっていれば2, 3が速く、その範囲外では1とはいい勝負、4にはかなわない
さあどうなるでしょう
ラッパー仕様
init関数を呼んでもらい、そこでメモリリストを作成します。リストには使用/未使用のフラグがあり、calloc時に未使用のメモリを渡してそのデータはリスト最後尾(tail)へ移動します。
そうやって、常に先頭のheadは未使用、tailは使用中のメモリデータがあるようにします。
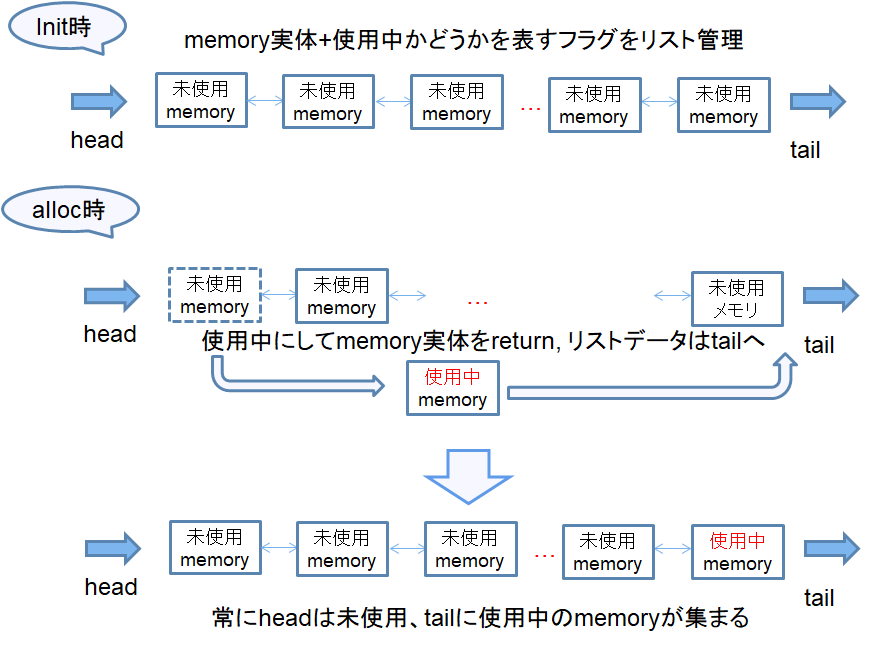
逆にfree時はtailから使用中のメモリデータを検索し、free対象のデータと一致するかを探ります。一致したものはfreeせず、未使用に変えて先頭へ移動します。

head, tailの位置は覚えているようにするので、free時の検索が気になりますが、それ以外は即メモリを渡してあげることが出来ます。いい感じじゃないでしょうか!?
ボトルネック解消した更新版仕様
2018/08/05 追記 ライブラリにしました。こちらのmempoolです。
上記ラッパーのネックはやはりfree時の挙動。ほぼ全てのメモリデータが使用中となると、ほぼ全てのデータを検索しなければいけません。
これは検索用リスト構造を見直さないといけないかなと思っていたのですが、いい手を発見しました。
こちらのサイト、私の手はダメ回答として紹介されています。笑
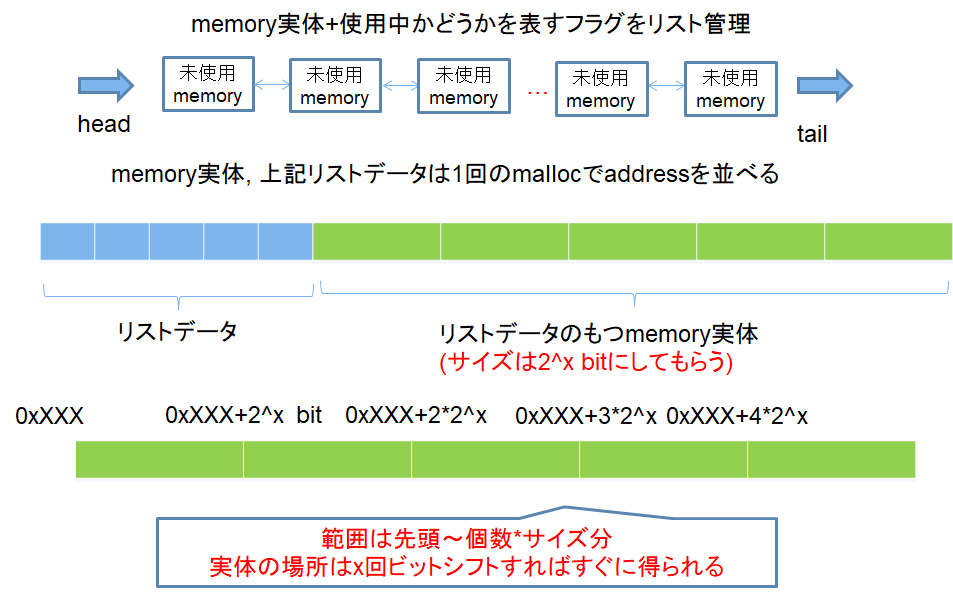
こちらの最後正解の部分、「メモリ領域のサイズは同じで, かつ2の冪乗バイトである。」という条件にしてあげれば、ビット演算でその位置が即座に把握できるんですね。
なるほど素晴らしい!
上記を元にネックとなるラッパーを見直しました。
まずは初期時。リストとメモリ実体は一列に並べてしまいます。加えて、サイズ指定は2の冪乗バイトに制限します。そうすると、こんな感じで2^xの倍数でメモリ実体が並ぶので、free時はx回ビットシフトしてあげればその位置がわかるというわけです。
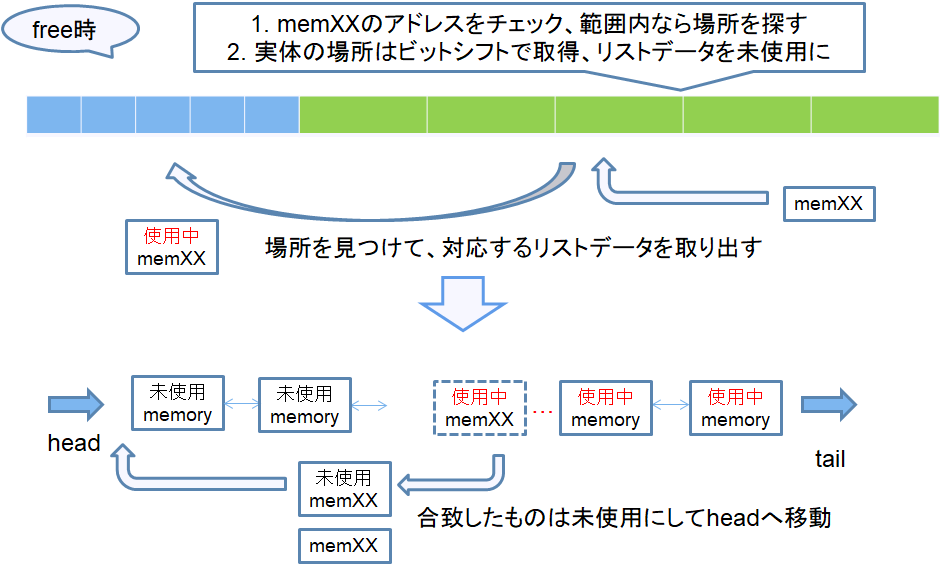
さて、free時はどうなるでしょうか?まずfree対象のメモリ実体が管理内かどうかは最初に作成したメモリ実体のアドレス範囲からわかります。なので最初のラッパーのように毎回全検索をする必要なし。
また、該当した場合は、ビットシフトして位置特定⇒対応するリストデータ実体を取り出してheadに移動すればOK。
検索処理がいらなくなりました。これは速くなるんじゃないですか?
また、x回ビットシフトの取得方法はこちらのビット位置を求めるコードを参考にしました。init時にのみ使用するので今回の測定には絡みませんが、こちらも端までビットシフトを頑張る時間がいらなくなり凄いです。
この辺りが自分の限界かなと思ったので計測してみます。
測定
測定ツール、ソースコードは以下に置いてあります。
https://github.com/developer-kikikaikai/speedtest
ビルド後、sample/mallocspeed内のrun.rbを実行すると測定が出来ます。
測定条件1.
作成ライブラリには1024byteのメモリを1024個ため込んでおいてもらいます。
この条件で以下をそれぞれ50回、100回、1024回、10000回の測定を10度実施し、その合計時間を出力します。
- 1024byteのmalloc/free
- 1024byte*2と1024byteのmalloc/free
時間測定はspeedtestのライブラリで行います。(メモリ上に時間付きログをダンプして、終了時に表示させるので、測定によるオーバーヘッドはそこまでないと思います。
測定環境
Linux Ubuntu 18.04
メモリ8GByte
CPU 4個 (VM上)
結果の見方
| 記載 | 意味 |
|---|---|
| Action列 | なんの測定を表すか |
| Total time列 | 合計時間。-3なら0.001(1/10^3)という意味 |
| XXX calloc(calloc/free under initial size) | 1024byteのmalloc/free測定 |
| XXX calloc(calloc/free initial size+over size) | 1024byte*2と1024byteのmalloc/free測定 |
| XXX=normal | 普通のcalloc/free(以下通常と記載) |
| XXX=wrap | 最初のラッパー |
| XXX=hhs_calloc | ボトルネック解消版(以下hhs_callocと記載) |
| XXX=tc_calloc | tc_calloc/tc_free利用(以下tc_callocと記載) |
測定結果
50回×10測定
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.15806e-3 |
| wrap calloc code(calloc/free under initial size) | 0.75032e-4 |
| hhs_calloc(calloc/free under initial size) | 0.135938e-3 |
| tc_calloc(calloc/free under initial size) | 0.186022e-3 |
| normal calloc(calloc/free initial size+over size) | 0.711725e-3 |
| wrap calloc(calloc/free initial size+over size) | 0.487427e-3 |
| hhs_calloc(calloc/free initial size+over size) | 0.443236e-3 |
| tc_calloc(calloc/free initial size+over size) | 0.702283e-3 |
- 1024byteのmalloc/free : 最初のラッパー >> hhs_calloc > 通常 > tc_calloc
- 1024byte*2と1024byteのmalloc/free : hhs_calloc c >最初のラッパー >> tc_calloc > 通常
利用する数が少ないうちは、2つのラッパーがはやいです。特に範囲内のものしかないと最初のラッパーは強い。
また、サイズオーバーも含んだ状態だと、早くもhhs_callocがいい成績。どちらもいいんじゃないですか?
(以下1, 2のタイトルは省略)
100回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.283713e-3 |
| wrap calloc code(calloc/free under initial size) | 0.153599e-3 |
| hhs_calloc(calloc/free under initial size) | 0.272328e-3 |
| tc_calloc(calloc/free under initial size) | 0.293742e-3 |
| normal calloc(calloc/free initial size+over size) | 0.1394836e-2 |
| wrap calloc(calloc/free initial size+over size) | 0.1395083e-2 |
| hhs_calloc(calloc/free initial size+over size) | 0.1244906e-2 |
| tc_calloc(calloc/free initial size+over size) | 0.1337618e-2 |
- 最初のラッパー > hhs_calloc > 通常 > tc_calloc
- hhs_callo c > tc_calloc > 最初のラッパー > 通常
まだ登録最大数の1/10程度ですが、この辺りで既に最初のラッパーは速度が激減しています。この辺りは実行の度に順位が変わるレベルです。
500回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.1453858e-2 |
| wrap calloc code(calloc/free under initial size) | 0.301273e-2 |
| hhs_calloc(calloc/free under initial size) | 0.1291004e-2 |
| tc_calloc(calloc/free under initial size) | 0.13424e-2 |
| normal calloc(calloc/free initial size+over size) | 0.7863012e-2 |
| wrap calloc(calloc/free initial size+over size) | 0.44953204e-1 |
| hhs_calloc(calloc/free initial size+over size) | 0.6339118e-2 |
| tc_calloc(calloc/free initial size+over size) | 0.6493924e-2 |
- hhs_calloc >= tc_calloc > 通常 > >> 最初のラッパー
- hhs_calloc >= tc_calloc > 通常 >> 最初のラッパー
登録最大数の1/2程度で、最初のラッパーがダントツで遅くなりました。思ったより脱落速い(-_-;)
また、この辺りからtc_callocの力が目立ちだします。
1024回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.2824874e-2 |
| wrap calloc code(calloc/free under initial size) | 0.20755398e-1 |
| hhs_calloc(calloc/free under initial size) | 0.2560653e-2 |
| tc_calloc(calloc/free under initial size) | 0.2751811e-2 |
| normal calloc(calloc/free initial size+over size) | 0.16774762e-1 |
| wrap calloc(calloc/free initial size+over size) | 0.54582233e-1 |
| hhs_calloc(calloc/free initial size+over size) | 0.13983322e-1 |
| tc_calloc(calloc/free initial size+over size) | 0.14046191e-1 |
- hhs_calloc > tc_calloc > 通常 >>> 最初のラッパー
- hhs_calloc >= tc_calloc > 通常 >> 最初のラッパー
ちょうど登録最大数に到達。意外と範囲外を混ぜたケースでもhhs_callocが頑張っています。
10000回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.30325826e-1 |
| wrap calloc code(calloc/free under initial size) | 0.5094687e-1 |
| hhs_calloc(calloc/free under initial size) | 0.30124209e-1 |
| tc_calloc(calloc/free under initial size) | 0.26917778e-1 |
| normal calloc(calloc/free initial size+over size) | 0.176232715e0 |
| wrap calloc(calloc/free initial size+over size) | 0.221244686e0 |
| hhs_calloc(calloc/free initial size+over size) | 0.176962985e0 |
| tc_calloc(calloc/free initial size+over size) | 0.146961605e0 |
- tc_calloc > hhs_calloc >= 通常 >>> 最初のラッパー
- tc_calloc > 通常 > hhs_calloc >> 最初のラッパー
ついにtc_callocがトップに。数が増えるほどに力を発揮するタイプのようですね。
ここまでくればhhs_callocは普通のcallocと変わらないので、1024回までの優位性で頑張って逃げてるだけですね。
結果その2: tc_mallocによるmalloc上書きでの結果
こちらの結果が面白かったので載せておきます。もはやtc_mallocの測定実験ですが。
各自calloc/freeはtc_mallocによる上書きとなるため、最初よりも各結果が伸びています。
50回×10測定
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.14662e-3 |
| wrap calloc code(calloc/free under initial size) | 0.7501e-4 |
| hhs_calloc(calloc/free under initial size) | 0.14337e-3 |
| tc_calloc(calloc/free under initial size) | 0.22985e-4 |
| normal calloc(calloc/free initial size+over size) | 0.803501e-3 |
| wrap calloc(calloc/free initial size+over size) | 0.28677e-3 |
| hhs_calloc(calloc/free initial size+over size) | 0.271435e-3 |
| tc_calloc(calloc/free initial size+over size) | 0.117837e-3 |
- tc_calloc > 最初のラッパー >> hhs_calloc > 通常
- tc_calloc > hhs_calloc > 最初のラッパー > 通常
こちら、早くもtc_callocがダントツです。てっきりラップしたcalloc/freeと同じくらいかと思ったのに意外。
100回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.27454e-3 |
| wrap calloc code(calloc/free under initial size) | 0.147085e-3 |
| hhs_calloc(calloc/free under initial size) | 0.270945e-3 |
| tc_calloc(calloc/free under initial size) | 0.43941e-4 |
| normal calloc(calloc/free initial size+over size) | 0.1559897e-2 |
| wrap calloc(calloc/free initial size+over size) | 0.759443e-3 |
| hhs_calloc(calloc/free initial size+over size) | 0.489991e-3 |
| tc_calloc(calloc/free initial size+over size) | 0.255653e-3 |
- tc_calloc > 最初のラッパー > hhs_calloc > 通常
- tc_calloc > hhs_calloc > 最初のラッパー > 通常
tc_callocの速さは衰え知らずです。それ以外は変わらず。
範囲外の速度はcalloc/free上書きの影響で、ラッパーも早くなっています。
500回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.1373838e-2 |
| wrap calloc code(calloc/free under initial size) | 0.1687707e-2 |
| hhs_calloc(calloc/free under initial size) | 0.1296464e-2 |
| tc_calloc(calloc/free under initial size) | 0.262718e-3 |
| normal calloc(calloc/free initial size+over size) | 0.7076653e-2 |
| wrap calloc(calloc/free initial size+over size) | 0.13166146e-1 |
| hhs_calloc(calloc/free initial size+over size) | 0.2556278e-2 |
| tc_calloc(calloc/free initial size+over size) | 0.1392622e-2 |
- tc_calloc > hhs_calloc > 通常 > 最初のラッパー
- tc_calloc > hhs_calloc > 通常 > 最初のラッパー
tc_calloc は言わずもがな。最初の結果から考えると、割と頑張っているhhs_calloc。
1024回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.2763511e-2 |
| wrap calloc code(calloc/free under initial size) | 0.6518494e-2 |
| hhs_calloc(calloc/free under initial size) | 0.2707665e-2 |
| tc_calloc(calloc/free under initial size) | 0.561575e-3 |
| normal calloc(calloc/free initial size+over size) | 0.14081652e-1 |
| wrap calloc(calloc/free initial size+over size) | 0.16251563e-1 |
| hhs_calloc(calloc/free initial size+over size) | 0.4127922e-2 |
| tc_calloc(calloc/free initial size+over size) | 0.3438721e-2 |
- tc_calloc > hhs_calloc > 通常 > 最初のラッパー
- tc_calloc > hhs_calloc > 通常 > 最初のラッパー
ラッパー得意分野なはずの範囲内で差が広がるという。tc_callocも上手にメモリを使いまわしてるんでしょうね。
10000回×10
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.27661637e-1 |
| wrap calloc code(calloc/free under initial size) | 0.18210164e-1 |
| hhs_calloc(calloc/free under initial size) | 0.12308628e-1 |
| tc_calloc(calloc/free under initial size) | 0.9218671e-2 |
| normal calloc(calloc/free initial size+over size) | 0.148160442e0 |
| wrap calloc(calloc/free initial size+over size) | 0.84871154e-1 |
| hhs_calloc(calloc/free initial size+over size) | 0.68569389e-1 |
| tc_calloc(calloc/free initial size+over size) | 0.65872532e-1 |
- tc_calloc > hhs_calloc > 最初のラッパー > 通常
- tc_calloc > hhs_calloc > 最初のラッパー > 通常
自分の用意した分野から外れて速くなるライブラリがあるらしい。作成したおじさんは悲しいです。
測定その2
上記は単純比較だったので、今回は今考えているアプリケーションのユースケースベースでシナリオを組みます。
測定条件.
対象アプリケーションは「ligttpdのマルチスレッド化」。なので、こんな想定で測定をします。
- 測定数は全接続クライアント(目標100,000)のリクエスト分
- 1リクエスト/レスポンスで必要なメモリを大雑把に見積(4096byte×256個 (1MByte)程度)
- 1度にlighttpd側が捌ききれる(常に抱える)コネクション数も雑把に見積(10個)
ということで、
| 要素 | 条件 |
|---|---|
| メモリプール | 10クライアント⇒4096byte × 256× 10個をプール |
| テストケース | 全クライアント中10クライアントが接続。その分のメモリを確保しては解放の繰り返しを実行。※クライアントの応答を返すタイミングは異なるので、解放順も適当に変えます。 |
| 想定全接続クライアント | 2000 (10,000は時間がかかりそうなので止めます) |
この条件でそれぞれ5度測定実施し、その合計時間を出力します。
測定結果2.
Call 5 times, input is 512000
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.2694234765e1 |
| wrap calloc code(calloc/free under initial size) | 0.27786253728e2 |
| hhs_calloc(calloc/free under initial size) | 0.673090478e0 |
| tc_calloc(calloc/free under initial size) | 0.617789121e0 |
hhs_calloc >= tc_calloc > 通常 > 最初のラッパー
最初の2つは実行タイミングによっては順番が入れ替わるレベル
結果その2: tc_mallocによるmalloc上書きでの結果
Call 5 times, input is 512000
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.593853921e0 |
| wrap calloc code(calloc/free under initial size) | 0.4174470792e1 |
| hhs_calloc(calloc/free under initial size) | 0.6199698e0 |
| tc_calloc(calloc/free under initial size) | 0.592267608e0 |
tc_calloc >= 通常 >= hhs_calloc > 最初のラッパー
前3つは実行の度に順番が入れ替わるレベルでした。
…といいつつこの結果ではhhs_callocにtc_mallocが差し替えたcallocが影響してしまっていますね。tc_mallocのtc_calloc計測だけとして改めて比較。
| Action | Total time |
|---|---|
| normal calloc(calloc/free under initial size) | 0.2694234765e1 |
| wrap calloc code(calloc/free under initial size) | 0.27786253728e2 |
| hhs_calloc(calloc/free under initial size) | 0.673090478e0 |
| tc_calloc(calloc/free under initial size) | 0.592267608e0 |
hhs_calloc > tc_calloc > 通常 > 最初のラッパー
こうやって見ると、うまくチューニングすればhhs_callocでも面白いかもしれません。
2018/06/10 コメントをいただき気になったので、hhs_callocのロックなしも試してみました。tc_calloc結果と並べて比較。
| Action | Total time |
|---|---|
| hhs_calloc(calloc/free under initial size) | 0.589852316e0 |
| tc_calloc(calloc/free under initial size) | 0.592267608e0 |
お~、計測の度に記録が変わりますが、ロックがなければhhs_callocが勝つこともありますね。スレッドを意識して使い分けてあげれば面白い!
結論
- 確かにmalloc/freeは使い方を決めて状況に合わせて上手にラップしてあげると速くなる。ただし、速度を本気で考えて作らないと逆に遅くなる。
- 速さを求めて使うならtc_mallocが速い。使う際は横着せずにtc_に置き換えた方がはやい。
ちなみに、メモリ使用量はみてないです。もしtc_mallocのメモリ使用量が凄い事になるのなら、自作のラッパーを作るのもいいかもしれませんね。
参考
ボトルネック解消の参考
アラインメントの大きなメモリ領域を用いて,高速かつメモリ効率の良い多数の集合を実現する方法
ビットシフトの参考
■[C#] 一番右端の立っているビット位置を求める「ものすごい」コード
測定:結果集計時のruby処理、浮動小数点について勉強用
Rubyによる 小数 と Float と BigDecimalについて...(初心者向け)